kubelet crashes with: root container [kubepods] doesn't exist #95488
Comments
|
/sig node |
|
Just got a new crash of one worker node just after update to v1.19.2 from v1.18.6 and changing hyperkube image to plain kubelet. The error from kubelet logs is: All kubepods cgroups seems to be presented (compared to healthy node, all 15 are here): Probably need to investigate deeper the cgroups structure. |
|
Why it might happen after update? |
|
Is the following cgroup a valid cgroup?
It has !two I checked with find on other nodes - seems kubepods appears only once in each cgroup hierarchy: However if I manually remove last |
|
Built kubelet with debug info: brought it to an unhealthy node and run under Delve. I can see unexpected at point Probably the |
|
Seems during parsing of |
|
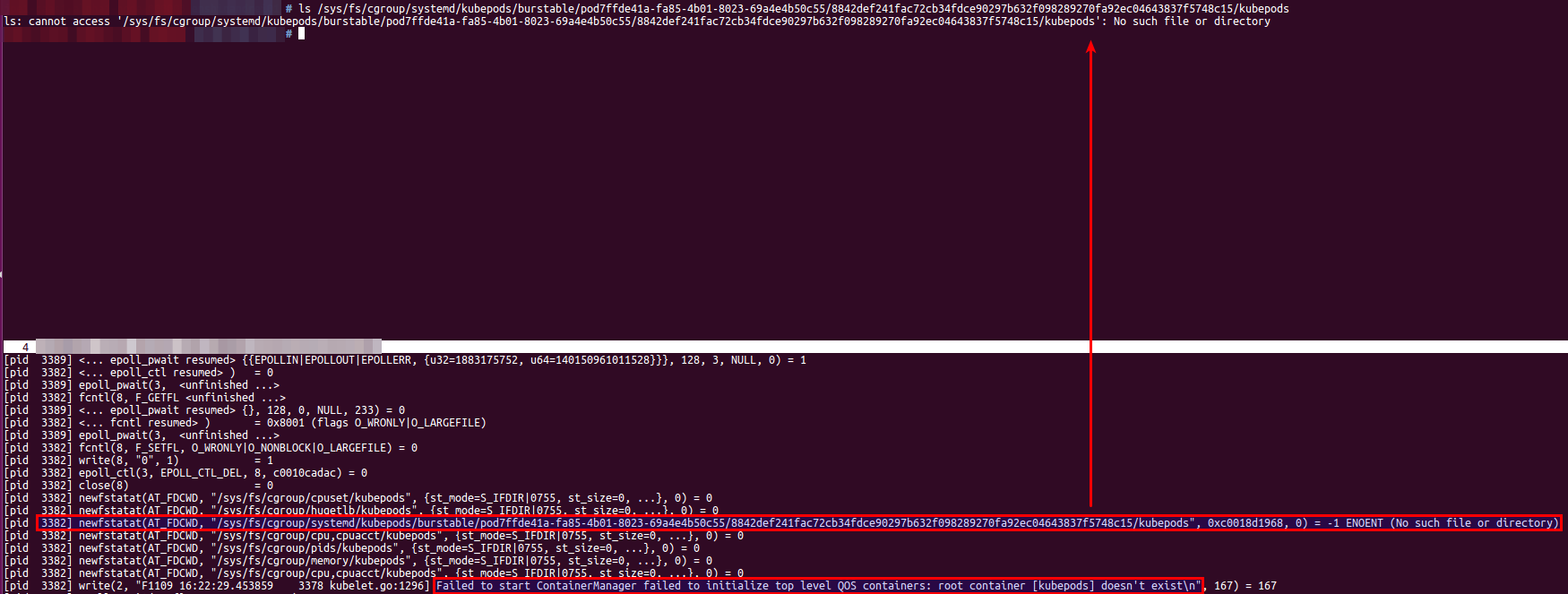
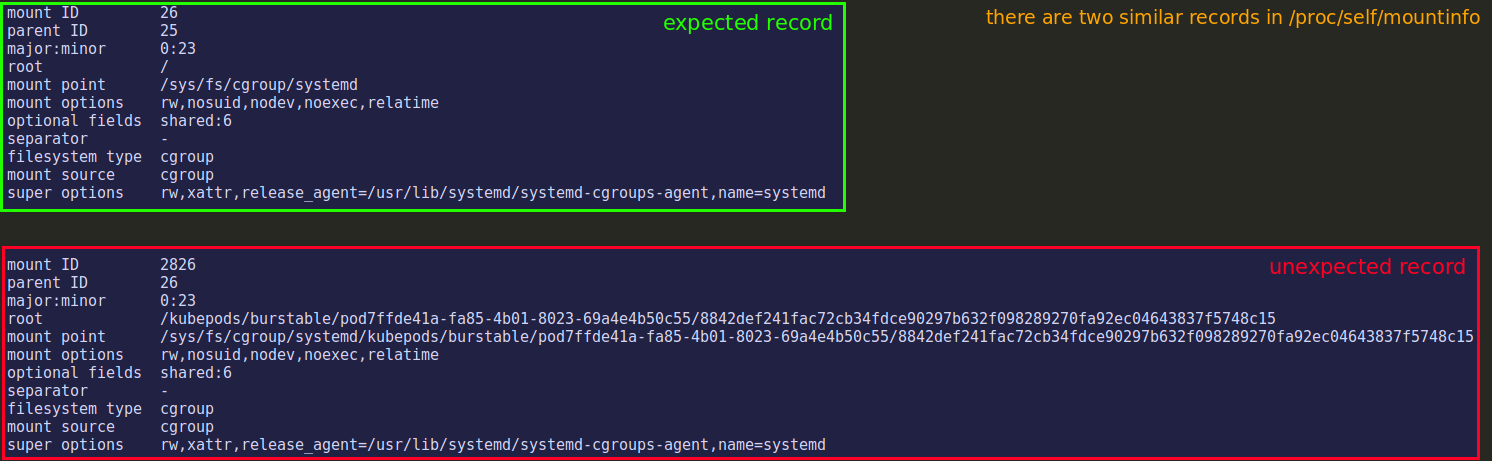
https://man7.org/linux/man-pages/man5/proc.5.html On healthy node: on unhealthy node: Why such "bad" (last one) record might appear? |
|
Seems the kubelet code https://github.com/kubernetes/kubernetes/blob/v1.19.2/pkg/kubelet/cm/helpers_linux.go#L203-L208 squeezes the array of 12 elements into map of 13 elements. But why "squeezes" if the map is bigger than the array?! Because there are few hierarchies which belong to multiple subsystems and only one subsystem - systemd - has two hierarchies, which at the end in kubelet's map will have only one hierarchy. The array returned from runc (important - here are two mount points of systemd subsystem): The map[string] which is made by kubelet from the above array: Probably there is expectation to have only one mount point per subsystem as said in Rule 2 of Red Hat doc.
May I ask, is it by intention or there is unexpected squeeze? |
|
Hmm. Interesting.. I see you are using dockershim, but what cgroup driver is docker and kubelet using? If you use systemd as init you should also use systemd as cgroup driver for both kubelet and the container runtime. Also, do you have any pods with containers running systemd? Maybe that is causing the "double" mount? There is also a preflight warning in kubeadm that says: |
|
@odinuge thank you for the reply!
The kubelet and container runtime (docker) are using and
Yeah, we do consider moving to
That is a good point! I'm not sure but it might be the reason if such container exists and has access to mount namespace of the host, so it can mount named systemd hierarchy. Or there is even no need to have access to host mount namespace?
Unfortunately we do not use kubeadm but our own set of scripts to deploy k8s. Probably we can consider in future to improve kubelet to emit the same warning or even do not run with |
|
Ahh, yeah, running with cgroupfs together with systemd is probably what is causing the problems.
I do not remember what it will require from the top of my head, but it does requite more than just the default values for pods. But it is possible with the right permissions.
Ahh, makes sense. Hmm. I guess we can fail kubelet on startup (as we do with swap), but that would might end up with upgrades failing. Log entries with a warning would probably not help that much, but I guess that is possible. |
|
@odinuge I've tried two scenarios:
Unfortunately was not able to reproduce. Maybe there is some other way to escape the mount namespace and be able to make mount on the host machine like
or more detailed: What I tried so far in details run privileged pod with systemd on boardThe way I run: On the node I've checked some runc arguments: and and From container: run container on the same host via dockerThe way I run: On the node I've checked some runc arguments: and and From container: Seems runc has many arguments for bind: I think all which supported by https://man7.org/linux/man-pages/man2/mount.2.html One therory is - there is ability to pass such set of argumetns that runc will create such mount on a host: |
|
Hey! Did some testing again and found some things; If i run: I do actually end up with these mounts, and I guess it is possible to do the same in kubernetes as well (with some combination of cri and pod config): I guess it isn't smart to do this, but it certainly looks like it is possible.. Also, if the node with the problem you are reffering to are still running, it would be nice if you could see what pod and container that "owns" that mount. Something like |
|
@odinuge thank you! Interestingly the mount is still there even after container is stopped and deleted: It means we almost can reproduce such state with docker!
Yeah, the node is still running but seems there is no such container anymore. The However searching on filesystem gives me some result with systemd-nspawn: There are two machines running on each node by systemd: Interesting, how |
|
Hmm, interesting. Thanks for your detailed feedback!
No, I don't think it will give any more insight into what you have already uncovered.
Interesting! Not familiar with Overall it looks like the most viable solution is to switch to |
|
/assign |
|
/unassign |
|
I've updated cluster to systemd cgroup driver and caught a crash with such mount on host: |
|
Issues go stale after 90d of inactivity. If this issue is safe to close now please do so with Send feedback to sig-contributor-experience at kubernetes/community. |
|
Stale issues rot after 30d of inactivity. If this issue is safe to close now please do so with Send feedback to sig-contributor-experience at kubernetes/community. |
|
/remove-lifecycle rotten |
|
/area kubelet |
|
Everything was fine with my cluster until I upgrade kubelet from 1.21.1 to 1.21.2, and now they fails to start with this error. I'm using cgroup2 and systemd. Passing the 2 flags mentioned as workaround make the problem disappear, but this is not a satisfying solution. |
|
I found my issue is #102676 |
|
The Kubernetes project currently lacks enough contributors to adequately respond to all issues and PRs. This bot triages issues and PRs according to the following rules:
You can:
Please send feedback to sig-contributor-experience at kubernetes/community. /lifecycle stale |
|
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs. This bot triages issues and PRs according to the following rules:
You can:
Please send feedback to sig-contributor-experience at kubernetes/community. /lifecycle rotten |
|
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs. This bot triages issues and PRs according to the following rules:
You can:
Please send feedback to sig-contributor-experience at kubernetes/community. /close |
|
@k8s-triage-robot: Closing this issue. In response to this:
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository. |
|
@odinuge the magic mounts very similar with what we can see here : ) |
What happened:
kubelet became unhealthy after a while, in few days after healthy run
Only two ways to bring it back:
What you expected to happen:
How to reproduce it (as minimally and precisely as possible):
Run plain kubelet binary on CoreOS 2135.6.0 node. Before we run it as hyperkube image.
I know, CoreOS in it’s End Of Life state now, however still need to find root cause and fix it if possible. Or use workaround with full understanding of current situation.
Anything else we need to know?:
error message:
Failed to start ContainerManager failed to initialize top level QOS containers: root container [kubepods] doesn't existEnvironment:
kubectl version):v1.19.2 (latest as of now)
bare metal node
cat /etc/os-release):uname -a):4.19.56-coreos-r1manually crafted systemd unit file:
Other:
On my node I can see such hierarchy under
/sys/fs/cgroup/memory/kubepods/:Do I understand right, since the
--cgroups-per-qosby default is true, in each cgroup hierarchy - e.g. memory, cpu,cpuacct, etc - kubelet creates directrykubepodswhich callsroot container?Also in
kubepodsin each hierarchy the kubelet creates subdirectory only for two qos - besteffort, burstable - but how does kubelet utilize these two subdirectories in each hierarchy? (I was able to find only a setting of minShares)Would be good to know the root cause of the issue and understanding of what is
kubepod,root container, how node allocatable and cgroups per qos relate to it.The text was updated successfully, but these errors were encountered: