aistudio地址:https://aistudio.baidu.com/aistudio/projectdetail/2101637
ipynb地址:javaroom.ipynb
数据集建aistudio
本文收集31962条twitter数据,划分为train、dev,其中情感氛围正向、负向两种。
众所周知,我们前期通过PaddleNLP课程学习了NLP相关知识,情感分析方面,在中文情感数据集进行了大量的联系,在此我再英文twitter上进行情感分析。

- 正向: 表示正面积极的情感,如高兴,幸福,惊喜,期待等。
- 负向: 表示负面消极的情感,如难过,伤心,愤怒,惊恐等。
!pip install --upgrade paddlenlp !tail -n20 data/data96052/Practice-Twitter-Sentiment-Analysis.csv31943,0,this week is flying by #humpday - #wednesday #kamp #ucsd�
31944,0, @user modeling photoshoot this friday yay #model #me #follow #emo
31945,0,"you're surrounded by people who love you (even more than you deserve) and yet, why are so hateful? "
31946,0,feel like... ��� #dog #summer #hot #help #sun #day #more
31947,1,@user omfg i'm offended! i'm a mailbox and i'm proud! #mailboxpride #liberalisme
31948,1,@user @user you don't have the balls to hashtag me as a but you say i am to weasel away.. lumpy tony.. dipshit.
31949,1," makes you ask yourself, who am i? then am i anybody? until ....god . oh thank you god!"
31950,0,hear one of my new songs! don't go - katie ellie #youtube #original #music #song #relationship #songwriter
31951,0," @user you can try to 'tail' us to stop, 'butt' we're just having too good of a time! #goldenretriever #animals "
31952,0,i've just posted a new blog: #secondlife #lonely #neko
31953,0,@user you went too far with @user
31954,0,good morning #instagram #shower #water #berlin #berlincitygirl #girl #newyork #zürich #genf #bern
31955,0,#holiday bull up: you will dominate your bull and you will direct it whatever you want it to do. when you
31956,0,less than 2 weeks ������ @user #ibiza#bringiton#mallorca#holidays#summer
31957,0,off fishing tomorrow @user carnt wait first time in 2 years
31958,0,ate @user isz that youuu?�����������
31959,0, to see nina turner on the airwaves trying to wrap herself in the mantle of a genuine hero like shirley chisolm. #shame #imwithher
31960,0,listening to sad songs on a monday morning otw to work is sad
31961,1,"@user #sikh #temple vandalised in in #calgary, #wso condemns act "
31962,0,thank you @user for you follow
from paddlenlp.datasets import load_dataset
from paddle.io import Dataset, Subset
from paddlenlp.datasets import MapDataset
def read(data_path):
with open(data_path, 'r', encoding='utf-8') as f:
next(f)
for line in f:
a=line.find(',')
b=line.find(',', a+1)
ids = line.strip('\n')[:a]
labels= line.strip('\n')[a+1:b]
sentences = line.strip('\n')[b+1:]
yield {'text': sentences, 'label': labels, 'qid':ids}
# data_path为read()方法的参数
dataset_ds = load_dataset(read, data_path='data/data96052/Practice-Twitter-Sentiment-Analysis.csv',lazy=False)# 在这进行划分
train_ds = Subset(dataset=dataset_ds, indices=[i for i in range(len(dataset_ds)) if i % 5 != 1])
dev_ds = Subset(dataset=dataset_ds, indices=[i for i in range(len(dataset_ds)) if i % 5 == 1])
# 在转换为MapDataset类型
train_ds = MapDataset(train_ds)
dev_ds = MapDataset(dev_ds)
print(len(train_ds))
print(len(dev_ds))25569
6393
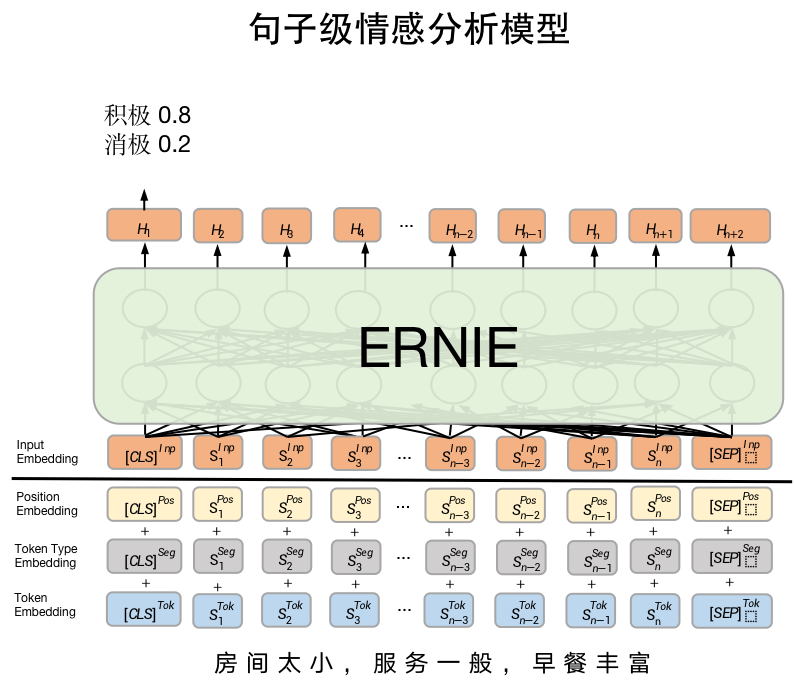
目前该模型有中英文3个预训练模型,选取英文skep_ernie_2.0_large_en预训练模型
"model_state": {
"skep_ernie_1.0_large_ch":
"https://paddlenlp.bj.bcebos.com/models/transformers/skep/skep_ernie_1.0_large_ch.pdparams",
"skep_ernie_2.0_large_en":
"https://paddlenlp.bj.bcebos.com/models/transformers/skep/skep_ernie_2.0_large_en.pdparams",
"skep_roberta_large_en":
"https://paddlenlp.bj.bcebos.com/models/transformers/skep/skep_roberta_large_en.pdparams",
- SkepForSequenceClassification可用于句子级情感分析和目标级情感分析任务。其通过预训练模型SKEP获取输入文本的表示,之后将文本表示进行分类。
- pretrained_model_name_or_path:模型名称。支持"skep_ernie_1.0_large_ch","skep_ernie_2.0_large_en"。
- "skep_ernie_1.0_large_ch":是SKEP模型在预训练ernie_1.0_large_ch基础之上在海量中文数据上继续预训练得到的中文预训练模型;
- "skep_ernie_2.0_large_en":是SKEP模型在预训练ernie_2.0_large_en基础之上在海量英文数据上继续预训练得到的英文预训练模型;
- num_classes: 数据集分类类别数。
关于SKEP模型实现详细信息参考:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/paddlenlp/transformers/skep
from paddlenlp.transformers import SkepForSequenceClassification, SkepTokenizer
# 指定模型名称,一键加载模型
model = SkepForSequenceClassification.from_pretrained(pretrained_model_name_or_path="skep_ernie_2.0_large_en", num_classes=2)
# 同样地,通过指定模型名称一键加载对应的Tokenizer,用于处理文本数据,如切分token,转token_id等。
tokenizer = SkepTokenizer.from_pretrained(pretrained_model_name_or_path="skep_ernie_2.0_large_en")from visualdl import LogWriter
writer = LogWriter("./log")SKEP模型对中文文本处理按照字粒度进行处理,我们可以使用PaddleNLP内置的SkepTokenizer完成一键式处理。
import os
from functools import partial
import numpy as np
import paddle
import paddle.nn.functional as F
from paddlenlp.data import Stack, Tuple, Pad
from utils import create_dataloader
def convert_example(example,
tokenizer,
max_seq_length=512,
is_test=False):
# 将原数据处理成model可读入的格式,enocded_inputs是一个dict,包含input_ids、token_type_ids等字段
encoded_inputs = tokenizer(
text=example["text"], max_seq_len=max_seq_length)
# input_ids:对文本切分token后,在词汇表中对应的token id
input_ids = encoded_inputs["input_ids"]
# token_type_ids:当前token属于句子1还是句子2,即上述图中表达的segment ids
token_type_ids = encoded_inputs["token_type_ids"]
if not is_test:
# label:情感极性类别
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
else:
# qid:每条数据的编号
qid = np.array([example["qid"]], dtype="int64")
return input_ids, token_type_ids, qid# 批量数据大小
batch_size = 64
# 文本序列最大长度
max_seq_length = 128
# 将数据处理成模型可读入的数据格式
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
# 将数据组成批量式数据,如
# 将不同长度的文本序列padding到批量式数据中最大长度
# 将每条数据label堆叠在一起
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack() # labels
): [data for data in fn(samples)]
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
dev_data_loader = create_dataloader(
dev_ds,
mode='dev',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)定义损失函数、优化器以及评价指标后,即可开始训练。
推荐超参设置:
- max_seq_length=256
- batch_size=48
- learning_rate=2e-5
- epochs=10 实际运行时可以根据显存大小调整batch_size和max_seq_length大小。
import time
from utils import evaluate
# 训练轮次
epochs = 3
# 训练过程中保存模型参数的文件夹
ckpt_dir = "skep_ckpt"
# len(train_data_loader)一轮训练所需要的step数
num_training_steps = len(train_data_loader) * epochs
# Adam优化器
optimizer = paddle.optimizer.AdamW(
learning_rate=2e-5,
parameters=model.parameters())
# 交叉熵损失函数
criterion = paddle.nn.loss.CrossEntropyLoss()
# accuracy评价指标
metric = paddle.metric.Accuracy()# 开启训练
global_step = 0
tic_train = time.time()
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch
# 喂数据给model
logits = model(input_ids, token_type_ids)
# 计算损失函数值
loss = criterion(logits, labels)
# 预测分类概率值
probs = F.softmax(logits, axis=1)
# 计算acc
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 10 == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %.5f, accu: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, acc,
10 / (time.time() - tic_train)))
tic_train = time.time()
# 反向梯度回传,更新参数
loss.backward()
optimizer.step()
optimizer.clear_grad()
if global_step % 100 == 0:
save_dir = os.path.join(ckpt_dir, "model_%d" % global_step)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 评估当前训练的模型
evaluate(model, criterion, metric, dev_data_loader)
# 保存当前模型参数等
model.save_pretrained(save_dir)
# 保存tokenizer的词表等
tokenizer.save_pretrained(save_dir)global step 1110, epoch: 3, batch: 310, loss: 0.12702, accu: 0.99219, speed: 0.26 step/s
global step 1120, epoch: 3, batch: 320, loss: 0.05266, accu: 0.99297, speed: 1.89 step/s
global step 1130, epoch: 3, batch: 330, loss: 0.02344, accu: 0.99323, speed: 1.77 step/s
global step 1140, epoch: 3, batch: 340, loss: 0.00321, accu: 0.99375, speed: 1.86 step/s
global step 1150, epoch: 3, batch: 350, loss: 0.12621, accu: 0.99344, speed: 1.92 step/s
global step 1160, epoch: 3, batch: 360, loss: 0.00110, accu: 0.99349, speed: 1.89 step/s
global step 1170, epoch: 3, batch: 370, loss: 0.00077, accu: 0.99353, speed: 1.92 step/s
global step 1180, epoch: 3, batch: 380, loss: 0.01631, accu: 0.99336, speed: 1.89 step/s
global step 1190, epoch: 3, batch: 390, loss: 0.02353, accu: 0.99306, speed: 1.68 step/s
global step 1200, epoch: 3, batch: 400, loss: 0.03405, accu: 0.99309, speed: 1.92 step/s
eval loss: 0.07968, accu: 0.97794
# 在这进行划分
test_ds = Subset(dataset=dataset_ds, indices=[i for i in range(len(dataset_ds)) if i % 50 == 1])
# 在转换为MapDataset类型
test_ds = MapDataset(test_ds)
print(len(test_ds))640
import numpy as np
import paddle
# 处理测试集数据
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
is_test=True)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment
Stack() # qid
): [data for data in fn(samples)]
test_data_loader = create_dataloader(
test_ds,
mode='test',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)# 根据实际运行情况,更换加载的参数路径
params_path = 'skep_ckpt/model_1200/model_state.pdparams'
if params_path and os.path.isfile(params_path):
# 加载模型参数
state_dict = paddle.load(params_path)
model.set_dict(state_dict)
print("Loaded parameters from %s" % params_path)Loaded parameters from skep_ckpt/model_1200/model_state.pdparams
label_map = {0: '0', 1: '1'}
results = []
# 切换model模型为评估模式,关闭dropout等随机因素
model.eval()
for batch in test_data_loader:
input_ids, token_type_ids, qids = batch
# 喂数据给模型
logits = model(input_ids, token_type_ids)
# 预测分类
probs = F.softmax(logits, axis=-1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
labels = [label_map[i] for i in idx]
qids = qids.numpy().tolist()
results.extend(zip(qids, labels))res_dir = "./results"
if not os.path.exists(res_dir):
os.makedirs(res_dir)
# 写入预测结果
with open(os.path.join(res_dir, "Twitter.tsv"), 'w', encoding="utf8") as f:
f.write("index\tprediction\n")
for qid, label in results:
f.write(str(qid[0])+"\t"+label+"\n")!head results/Twitter.tsvindex prediction
2 0
52 0
102 0
152 1
202 0
252 0
302 0
352 0
402 0