lizardfs-uraft failed to start #824
Comments
|
How much memory do you have on master servers ?
Send from my mobile phone
… Wiadomość napisana przez jbarrigafk ***@***.***> w dniu 13.05.2019, o godz. 23:07:
Hi, I'm working with Lizardfs-uraft 3.13.0 & Centos 7.
I have 3 metadata servers, 8 chunkservers and 2 metaloggers.
I had worked well for a while but now I have a problem with millions of files and chunks on my metadata servers.
systemctl start lizardfs-uraft (master1-sv = working)
systemctl start lizardfs-uraft (master2-sv = error)
systemctl start lizardfs-uraft (master3-sv = error)
my metadata.mfs size:
***@***.*** ~]# du -hs /data/mfs/metadata.mfs
23G /data/mfs/metadata.mfs
mfsmaster2-sv LOGS
May 10 17:07:17 mfsmaster2-sv systemd: Started LizardFS master server daemon.
May 10 17:07:17 mfsmaster2-sv mfsmaster[22996]: connected to Master
May 10 17:07:17 mfsmaster2-sv systemd: Started LizardFS uraft high availability daemon.
May 10 17:07:17 mfsmaster2-sv lizardfs-uraft: Lizardfs-uraft initialized properly
May 10 17:07:17 mfsmaster2-sv lizardfs-uraft: Node 'mfsmaster1-sv' is now a leader.
May 10 17:07:17 mfsmaster2-sv lizardfs-uraft: Metadata server is alive
May 10 17:10:01 mfsmaster2-sv systemd: Created slice User Slice of root.
May 10 17:10:01 mfsmaster2-sv systemd: Started Session 15008 of user root.
May 10 17:10:01 mfsmaster2-sv systemd: Removed slice User Slice of root.
May 10 17:12:50 mfsmaster2-sv mfsmaster[22996]: metadata downloaded 23689390616B/333.292241s (71.077 MB/s)
May 10 17:12:54 mfsmaster2-sv mfsmaster[22996]: changelog.mfs.1 downloaded 12138576B/0.183249s (66.241 MB/s)
May 10 17:12:54 mfsmaster2-sv mfsmaster[22996]: changelog.mfs.2 downloaded 60904845B/0.930901s (65.426 MB/s)
May 10 17:12:55 mfsmaster2-sv mfsmaster[22996]: sessions downloaded 2166B/0.001474s (1.469 MB/s)
May 10 17:12:55 mfsmaster2-sv mfsmaster[22996]: opened metadata file /var/lib/mfs/metadata.mfs
May 10 17:12:55 mfsmaster2-sv mfsmaster[22996]: loading objects (files,directories,etc.) from the metadata file
May 10 17:13:58 mfsmaster2-sv mfsmaster[22996]: loading names from the metadata file
May 10 17:20:01 mfsmaster2-sv systemd: Created slice User Slice of root.
May 10 17:20:01 mfsmaster2-sv systemd: Started Session 15009 of user root.
May 10 17:20:01 mfsmaster2-sv systemd: Removed slice User Slice of root.
May 10 17:21:05 mfsmaster2-sv mfsmaster[22996]: loading deletion timestamps from the metadata file
May 10 17:21:05 mfsmaster2-sv mfsmaster[22996]: loading extra attributes (xattr) from the metadata file
May 10 17:21:05 mfsmaster2-sv mfsmaster[22996]: loading access control lists from the metadata file
May 10 17:21:05 mfsmaster2-sv mfsmaster[22996]: loading quota entries from the metadata file
May 10 17:21:05 mfsmaster2-sv mfsmaster[22996]: loading file locks from the metadata file
May 10 17:21:05 mfsmaster2-sv mfsmaster[22996]: loading chunks data from the metadata file
May 10 17:22:23 mfsmaster2-sv mfsmaster[22996]: checking filesystem consistency of the metadata file
May 10 17:22:29 mfsmaster2-sv mfsmaster[22996]: connecting files and chunks
May 10 17:27:51 mfsmaster2-sv mfsmaster[22996]: calculating checksum of the metadata
May 10 17:28:17 mfsmaster2-sv mfsmaster[22996]: metadata file /var/lib/mfs/metadata.mfs read (196985237 inodes including 30975314 directory inodes and 136297216 file inodes, 136301197 chunks)
May 10 17:28:17 mfsmaster2-sv mfsmaster[22996]: running in shadow mode - applying changelogs from /var/lib/mfs
May 10 17:28:18 mfsmaster2-sv mfsmaster[22996]: /var/lib/mfs/changelog.mfs.1: 220353 changes applied (1254452902 to 1254673254), 0 skipped
May 10 17:28:18 mfsmaster2-sv mfsmaster[22996]: /var/lib/mfs/changelog.mfs: 255 changes applied (1254673255 to 1254673509), 269484 skipped
May 10 17:29:24 mfsmaster2-sv systemd: lizardfs-ha-master.service: main process exited, code=killed, status=27/PROF
May 10 17:29:24 mfsmaster2-sv mfsmaster: 05/10/19 17:29:24.278 [warning] [39131:39131] : can't find process to terminate
May 10 17:29:24 mfsmaster2-sv mfsmaster: can't find process to terminate
May 10 17:29:24 mfsmaster2-sv systemd: Unit lizardfs-ha-master.service entered failed state.
May 10 17:29:24 mfsmaster2-sv systemd: lizardfs-ha-master.service failed.
May 10 17:29:24 mfsmaster2-sv lizardfs-uraft: Metadata server is dead
May 10 17:29:24 mfsmaster2-sv lizardfs-uraft: LizardFS uraft helper script
May 10 17:29:24 mfsmaster2-sv lizardfs-uraft: Available commands:
May 10 17:29:24 mfsmaster2-sv lizardfs-uraft: isalive
May 10 17:29:24 mfsmaster2-sv lizardfs-uraft: metadata-version
May 10 17:29:24 mfsmaster2-sv lizardfs-uraft: quick-stop
May 10 17:29:24 mfsmaster2-sv lizardfs-uraft: promote
May 10 17:29:24 mfsmaster2-sv lizardfs-uraft: demote
May 10 17:29:24 mfsmaster2-sv lizardfs-uraft: assign-ip
May 10 17:29:24 mfsmaster2-sv lizardfs-uraft: drop-ip
Only 1 of the metadata servers works so far, I can not raise the lizardfs-uraft service in my master2-sv or mfsmaster3-sv, both present the same error:
May 10 17:29:24 mfsmaster2-sv systemd: lizardfs-ha-master.service: main process exited, code=killed, status=27/PROF
May 10 17:29:24 mfsmaster2-sv mfsmaster: 05/10/19 17:29:24.278 [warning] [39131:39131] : can't find process to terminate
May 10 17:29:24 mfsmaster2-sv mfsmaster: can't find process to terminate
we currently handle around 130 million files and chunks, maybe that's the problem? I have played with different mfsmaster parameters, but none of them works, I have increased the values of CHUNKS_LOOP_MAX_CPS and METADATA_CHECKSUM_RECALCULATION_SPEED without good results.
mfsmaster1 config.
PERSONALITY = ha-cluster-managed
ADMIN_PASSWORD = SOMEPASS
WORKING_USER = mfs
WORKING_GROUP = mfs
DATA_PATH = /data/mfs
MATOML_LISTEN_HOST = *
MATOML_LISTEN_PORT = 9419
MATOCS_LISTEN_HOST = *
MATOCS_LISTEN_PORT = 9420
MATOCL_LISTEN_HOST = *
MATOCL_LISTEN_PORT = 9421
MATOTS_LISTEN_HOST = *
MATOTS_LISTEN_PORT = 9424
NO_ATIME = 0
MASTER_HOST = mfsmaster
mfsmaster2 config
PERSONALITY = ha-cluster-managed
ADMIN_PASSWORD = SOMEPASS
WORKING_USER = mfs
WORKING_GROUP = mfs
DATA_PATH = /var/lib/mfs
MATOML_LISTEN_HOST = *
MATOML_LISTEN_PORT = 9419
MATOCS_LISTEN_HOST = *
MATOCS_LISTEN_PORT = 9420
MATOCL_LISTEN_HOST = *
MATOCL_LISTEN_PORT = 9421
MATOTS_LISTEN_HOST = *
MATOTS_LISTEN_PORT = 9424
NO_ATIME = 0
MASTER_HOST = mfsmaster
mfsmaster3 config
PERSONALITY = ha-cluster-managed
ADMIN_PASSWORD = SOMEPASS
WORKING_USER = mfs
WORKING_GROUP = mfs
DATA_PATH = /data/mfs
MATOML_LISTEN_HOST = *
MATOML_LISTEN_PORT = 9419
MATOCS_LISTEN_HOST = *
MATOCS_LISTEN_PORT = 9420
MATOCL_LISTEN_HOST = *
MATOCL_LISTEN_PORT = 9421
MATOTS_LISTEN_HOST = *
MATOTS_LISTEN_PORT = 9424
NO_ATIME = 0
MASTER_HOST = mfsmaster
lizardfs-uraft.cfg (master2-sv)
URAFT_NODE_ADDRESS = mfsmaster2-sv
URAFT_NODE_ADDRESS = mfsmaster1-sv
URAFT_NODE_ADDRESS = mfsmaster3-sv
URAFT_ID = 0
URAFT_FLOATING_IP = 10.40.40.140
URAFT_FLOATING_NETMASK = 255.255.255.0
URAFT_FLOATING_IFACE = bond0
lizardfs-uraft.cfg (master1-sv)
URAFT_NODE_ADDRESS = mfsmaster2-sv
URAFT_NODE_ADDRESS = mfsmaster1-sv
URAFT_NODE_ADDRESS = mfsmaster3-sv
URAFT_ID = 1
URAFT_FLOATING_IP = 10.40.40.140
URAFT_FLOATING_NETMASK = 255.255.255.0
URAFT_FLOATING_IFACE = bond0
lizardfs-uraft.cfg (master3-sv)
URAFT_NODE_ADDRESS = mfsmaster2-sv
URAFT_NODE_ADDRESS = mfsmaster1-sv
URAFT_NODE_ADDRESS = mfsmaster3-sv
URAFT_ID = 2
URAFT_FLOATING_IP = 10.40.40.140
URAFT_FLOATING_NETMASK = 255.255.255.0
URAFT_FLOATING_IFACE = bond0
Any suggest???
Thanks
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub, or mute the thread.
|
|
Hello, thanks for answering |
|
yesterday I tried these commands that I saw in another old post in this way the mfsmaster process never died, at least not in the first 20 minutes as it does with systemctl and the PROF signal. I clearly see that I have corrupt files, what I have in mind is to completely erase all the contents of / var / lib / mfs in my master3-sv and re-execute the commands I mentioned previously. Will I still have HA functionalities with lizardfs-uraft? |
|
In a testing environment, do the following: everything is synchronized correctly, but when the lizardfs service is stopped in the primary master (master1), the rest fails, none shadow is promoted as primary. So this is not a solution |
|
my master cpu usage is always 100% when lizardfs-uraft starts, i think PROF signal appears by a long cpu usage. How can i handle cpu usage then? I change default value of CHUNKS_LOOP_MAX_CPU = 60 to 30 and nothing changes |
|
yum install cplimit I limited the use of cpu to 75% for the mfsmaster process and even after about 20 minutes, it died by |
I can see After you get core dump install |
thanks for your answer, segfault appeared when executing lizardfs with the following command:
I've tried several things, I've tried servers with higher CPU speeds and the problems are the same. I do not know where else I should look |
|
we decided to remove the uraft function and only work with master / shadow, even so, only one of the metadata servers is the one that starts correctly, the other presents the same problems. |
|
It would be nice it you were able to reliably reproduce the problem on some minimal working example (MWE), so that I was able to reproduce the problem (see this guideline). If you are not able to create MWE, then it would be nice if you could provide core dump of the |
|
an apology for a delayed answer. I tried to play the segfault in another test environment using the same metadata.mfs of my productive masters. Enable coredump in my test masters, but, only the coredump is generated for some signals, example: signal 11 In my case, the signal that ends the process of lizardfs is 27 SIGPROF which is of type "term"
etc signal 27 SIGPROF does not generate any coredump that can analyze however, install gdb and the debug package of lizardfs for centos 7 I keep investigating how to use gdb to try to debugge the lizardfs process In my testing environment, the sigprof signal continues to appear and the lizardfs process ends. |
|
Any update for this case @jbarrigafk ? |
|
@kaitoan2000 |
When this option is set (equals 1) master will try to recover metadata |
|
You should be able to change it to 1, but as I understand it it's deliberately 0, because when a crash occurs you probably want to look at it yourself rather than letting it be handled automatically. |
@jbarrigafk Please give me a way to remove uraft HA, It's terrible with me now. |
|
@kaitoan2000 and maybe you should do a tar.gz of your metadata from /var/lib/mfs Choose your last active metadata master from URAFT and change this values: mfsmaster.cfg Here, choose any of both last metadata servers or both Shadowchunkserversmfschunkserver.cfg metaloggersmfsmetalogger.cfg Just be sure all your cluster knows mfsmaster metadata master IP (/etc/hosts resolution) systemctl start lizardfs-master on master and after shadow |
|
trap -- '' SIGPROF ; trap -- '' SIGVTALRM; /usr/sbin/mfsmaster -c /etc/mfs/mfsmaster.cfg -d Good, back to this topic. I add here the debug records, the process takes about 3 hours to complete (without systemctl) When I start the lizardfs service with systemctl, systemd kills the process after approximately 30 minutes, in the logs it can be seen that the master.fs.checksum.changin_not_recalculated_chunk processes take a long time to complete |
@kaitoan2000 |
Hi, I have change out master server to stronger server with 128GB RAM and Higher CPU. It's seem OK now. |
|
In our productive environment we still can't connect shadow with the master. I'm still waiting, the messages that appear are the following: |
Hi, |
|
@kaitoan2000 the cpu remains between 60 and 70% with master.fs.checksum.changing_not_recalculated_chunk process. until today, we are still working only with 1 master and a couple of metaloggers, but it is not safe for us, we need at least 1 synchronized shadow |
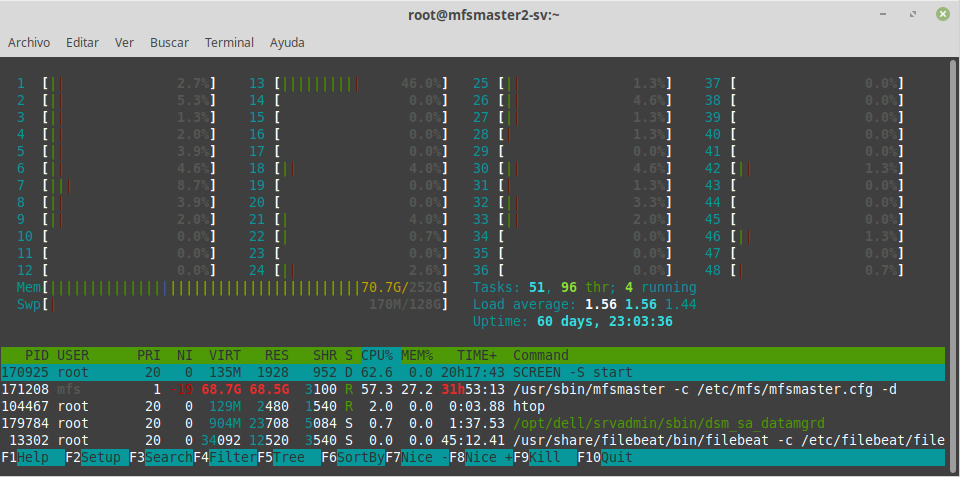
|
@jbarrigafk I feel quite confused – you started this issue because of |
|
@pbeza Let me create a test environment again with URAFT to reproduce this problem, I anticipate that this problem has arisen in Centos 7 and Lizardfs 3.13.0 from lizardfs-bundle-CentOS-7.5.1804.tar when trying to load/synchronize my shadow a file metadata.mfs of 26GB which are around 130 million small files (Only active master works). maybe I can share my metadata.mfs file |
|
Aug 6 15:24:32 hostname mfsmaster[5312]: running in shadow mode - applying changelogs from /var/lib/mfs Still unloading :( |
|
Please check value of BACK_META_KEEP_PREVIOUS in you mfsmaster.cfg file. |
grep BACK_META_KEEP_PREVIOUS mfsmaster.cfg
|

|
set 1 and your problem with unloading metadata by uraft will disappear. |
I have editted BACK_META_KEEP_PREVIOUS to default (1), but not luck. In master : |
|
@pbeza Download lizardfs bundle on masters, chunkservers and clients Config on metadata servers chunkserver Client #Create a test file and split file to have millions of small files inside lizardfs. #It may not be the best way to reproduce the problem but it was how I succeeded. Millions of small files and many directory trees must be created within lizardfs, until there comes a point where lizardfs can no longer load metadata my metadata server throw 27 SIGPROF on my lizardfs cluster with: chunkserver 44 GB Space used (single chunkserver for test) |

@blink69 with systemctl start lizardfs-uraft I get SIGPROF |
|
@pbeza https://drive.google.com/open?id=1OTkHOhO3h_nhxCjB_fNcJ9mZBKSkE1yK |
|
Hi there, it's OK after 4 hours to try loading all filesystem. |
@kaitoan2000 Yes, that is what I take in my test environment without having writes or readings in my lizardfs storage cluster. But in my productive environment with a lot of writing and reading it takes about 2 or 3 days and I don't finish synchronizing If you already have your metadata server synchronized after 4 hours, I suggest you try the uraft HA, try turning off nodes and verify that the hearbeat ip works on the different nodes of your cluster. |
|
@pbeza hi, did you reproduce my issue? im still with a single master on my cluster |
|
@jbarrigafk Does your metaserver also has 128GB memory? It seems lizardfs require more memory then what the manual says: |
|
Sorry for late response @jbarrigafk but currently I have issues with servers that will be used to test your use case, so you must stay patient. :( |
@bash99 Hi thanks for your response In my productive environment it was: my primary was always master1 and my shadows were master2 and master3 which could never synchronize the metadata of master1. Since I could never make this work, I had to stop the entire cluster and start master2 as primary and single node in my cluster because it was my node that had more available ram (256GB) I never had trouble starting my nodes with the role of Master/Primary, the problem really is in the Shadows, they neves sync to master... :/ Im looking for more info about memory requirements by fs objects, but i cant find nothing. If u can share some link to read it, I would appreciate it |
@pbeza |
|
I got this error today with both shadow run as lizardfs-uraft and mfsmaster with shadow mode.
|

Is it OK till now bro? |
|
Hi @phamthanhnhan14 Yes. My cluster of only 1 master still works but I had to remove it from production, we still have it working but only to make readings. |
|
Greetings to all, I return again to try to solve this problem together with all of you. I have started to carry out some tests, having the same scheme: 1x metadata master / 256 RAM Im trying to start my Shadow server with default config but it fails.
This is the only thread related to this message. feel free to ask me for any information to try to solve this problem |

|
hello everyone. Since I realized that my server already had 90 GB ram in use without having any active service and that is why systemd sent: since my server did not have enough memory to complete the lizardfs process. I thought that now everything would be fine, but I started to monitor the consumption of the ram memory of my shadow server and it was growing at a really fast rate, however, the lizardfs process still continued as it should be, the logs showed progress correctly, until I saw that my server reached its maximum ram memory in use and the following log appeared: If I only had a little more ram, my shadow would complete the sync process with the master, but why does it need twice the ram memory of the master? My master node has 100 GiB of ram in use. I have another cluster where the master node has 41 GiB in use and the shadow has 23 GiB, I still cannot find the reason for the high ram consumption to synchronize my shadow. This is my shadow server process and consumption I will continue investigating, but now with issues related to memory |

|
I don't believe the mfsmaster process releases memory. So when files are
deleted, that memory space is kept.
What happens to the memory footprint on your shadow server if you restart
mfsmaster?
… |
@jkiebzak hi, thanks for giving signs of life in this thread Therefore, lock logs appeared: In this process, RAM increase from 43 GB to 76 GB In this process, RAM increase from 76 GB to 112 GB In this process, RAM increase from 112 GB to 141 GB In this process, RAM increase from 141 GB to 155 GB In this process, RAM increase from 155 GB to 176 GB In this process, RAM increase from 176 GB to 185 GB after 5 minutes, the ram went down from 185 GB to 111 GB and the process started again |
|
indeed, lizard does not free the memory with a restart, it stays in some kind of cache perhaps? Even so, my cluster has 100GB of ram in use and my shadow cannot synchronize with 188GB, I also observe that the swap memory is not used, the server has the default value of swapiness in 60 |
Maybe it's some shm memory in use? |
Nothing with ipcs -m the mfsmaster service has been running for 15 days, but it continues to unload, it does not finish synchronizing with the master
|

Hi, I'm working with Lizardfs-uraft 3.13.0 & Centos 7.
I have 3 metadata servers, 8 chunkservers and 2 metaloggers.
I had worked well for a while but now I have a problem with millions of files and chunks on my metadata servers.
systemctl start lizardfs-uraft (master1-sv = working)
systemctl start lizardfs-uraft (master2-sv = error)
systemctl start lizardfs-uraft (master3-sv = error)
my metadata.mfs size:
[root@mfsmaster1-sv ~]# du -hs /data/mfs/metadata.mfs
23G /data/mfs/metadata.mfs
mfsmaster2-sv LOGS
Only 1 of the metadata servers works so far, I can not raise the lizardfs-uraft service in my master2-sv or mfsmaster3-sv, both present the same error:
we currently handle around 130 million files and chunks, maybe that's the problem? I have played with different mfsmaster parameters, but none of them works, I have increased the values of CHUNKS_LOOP_MAX_CPS and METADATA_CHECKSUM_RECALCULATION_SPEED without good results.
mfsmaster1 config.
mfsmaster2 config
mfsmaster3 config
lizardfs-uraft.cfg (master2-sv)
lizardfs-uraft.cfg (master1-sv)
lizardfs-uraft.cfg (master3-sv)
Any suggest???
Thanks
The text was updated successfully, but these errors were encountered: