A browser-based abstract syntax tree visualizer.
- Built a Scheme-to-JavaScript compiler and a JavaScript parser using Python.
- Constructed browser-based abstract syntax tree visualizer using JavaScript/jQuery/Ajax/JSON, D3.js, HTML, CSS.
- Set up PostgreSQL database using SQLAlchemy containing example input for visualizer.
Deployed on Heroku: http://visualispy.herokuapp.com/ (Database may take some time to "wake up" on Heroku's server.)
Contents
- Introduction
- File Architecture
- Getting Started
- Scheme Interpreter
- JavaScript Parser
- Abstract Syntax Tree Visualization
- Final Thoughts
I hold a certain aversion to black boxes, always wanting to open them up and take a peek inside. Since I began programming, I wanted to know how a computer understands these languages. Thus, I chose to build a compiler as a Hackbright Academy project for the sake of learning some inner workings of language processing. What is a compiler, even? I struggled with the concept that compilers themselves are written in a computer language, which results in a chicken-and-egg type scenario. Though I didn't understand bootstrapped compilers or metacircular evaluation on a low level, I dove right in to coding a simple interpreter, hoping that I might become enlightened in the process. I only had four weeks to build this--better get started and move fast!
However, a friend and mentor said something quite accurate of me, “You really like the abstract, but you get frustrated if you can’t represent it visually.” As this project is something I would supposedly show to potential employers, how could I present it to others in a visual format? Integrating another desire to better my full-stack development skills, I set off to build VisuaLisPy -- a web-based language interpretation visualizer. I wrote an interpreter for Scheme (a dialect of Lisp) using Python. The interpreter file was modified to trace an input program's interpretation and output this trace data in JSON format. The JSON is then passed to the frontend and rendered visually as an abstract syntax tree in-browser with the aid of D3.js JavaScript library.
In line with my love for open education, I hope VisuaLisPy will be helpful for those who want to better understand computer language.
Furthering the original intent of this endeavor (satisfying my curiosity of what lies underneath high-level languages), I added in a JavaScript parser and am currently working on code generators to compile Scheme into subsets of JavaScript and C. Though I could not complete these compilers within the allotted timeframe of four weeks, I very much consider this an ongoing project that I fondly call "n00b's first compiler(s)" -- everybody starts somewhere.
- database: PostgreSQL (deployment), SQLite (local development and testing)
- images: frontend screenshots
- js_parser: JavaScript parser written in Python
- scheme_interpreter: Scheme interpreter written in Python
- static: CSS styles and JavaScript files
- templates: HTML templates
- tests: TDD files for JavaScript parser
Clone this repository to your local machine. From the VisuaLisPy working directory, set up a virtual environment and install requirements with
VisuaLisPy$ pip install -r requirements.txt
Then, run
VisuaLisPy$ python controller.py
This should hopefully get the web app running.
Coding through Peter Norvig's Lispy was my starting-off point in understanding language interpretation. Once I had obtained a working knowledge, I edited Lispy to trace the interpreter's steps in parsing an input Scheme string.
The first step in parsing is lexical analysis, in which we break up an input string into a sequence of meaningful words -- otherwise known as tokens. In a language like English, the words/tokens are basically separated by spaces, though punctuation characters should probably also be considered and tokenized.
We tokenize our raw Scheme input with the function tokenize. As Scheme's syntax is relatively straightforward (expressions clearly separated with parentheses on a single line, in contrast to JavaScript, which we will later cover), tokenizing an expression is simply a matter of splitting up a string on whitespace. For example, setting the variable n to 6 * 2,
>>> program = "(set! n (* 6 2))"
>>> tokenize(program)
['(', 'set!', 'n', '(', '*', '6', '2', ')', ')']
After tokenizing, we can then call the read_from function on our list of tokens. This function will scan our program and return a list of expression tokens if the program is valid. If it comes across an invalid character, it will raise a syntax error.
>>> read_from(['(', 'set!', 'n', '(', '*', '6', '2', ')', ')'])
['set!', 'n', ['*', 'x', 2]]
Applying lexical analysis followed by syntactic analysis make up the parse method, which takes in a raw input string and returns an abstract syntax tree as a list.
Interpretation involves taking an input expression list and iterating through to evaluate each item using built-in Python functions as well as my own defined arithmetic methods defined within the environmental scope of each expression. The global environment is updated appropriately for user-defined variables.
Complete interpretation involves applying the parse method followed by the eval method. We assign the output value to the variable val.
Though I initially had plans to include visualization of interpretation and scoping in my web application, time constraints and a stronger desire to parse a more challenging language had me drop this from my list of priorities.
Whereas Scheme's grammar is straightforward enough to map input to output with little modification (everything is basically already in the form of a list!), JavaScript is more complex and includes meaningful whitespace, expression blocks spread across multiple lines, among other features. To better understand "real" parsing, I watched several lectures from Udacity's CS262 course, where I learned about language grammars and how to utilize PLY (Python Lex-Yacc) to generate my lexer and parser.
To generate a lexer, PLY takes a set of methods outlining a target language's tokenizing rules. Each token is defined in a method whose identifier begins with "t_" followed by the name of a token in a given list of tokens. The method uses a regular expression to locate tokens in an input string, and optional transforms are applied to this token where necessary, such as altering the datatype from string to float for numbers or stripping quotation marks off of strings. If no further modification is necessary before returning a particular token, the tokenizing rules may be written in shorthand, as demonstrated in lines 90-114. The lexer is generated by calling lex.lex(module=js_tokens).
To generate a parser, PLY intakes parsing methods whose identifiers begin with "p_" followed by a name representing the particular target parsed item), whether the target be a function, if-then-else statement, number, binary operator, etc. We establish precedence rules to ensure certain methods are prioritized -- for example, multiplication is applied before addition in the expression 8 + 9 * 3. The parser is generated by calling yacc.yacc(). From an output file, we can see the grammar rules we defined for our subset of JavaScript. Neat!
Parallel to the Scheme parser, applying lexical analysis followed by syntactic analysis make up the parse method.
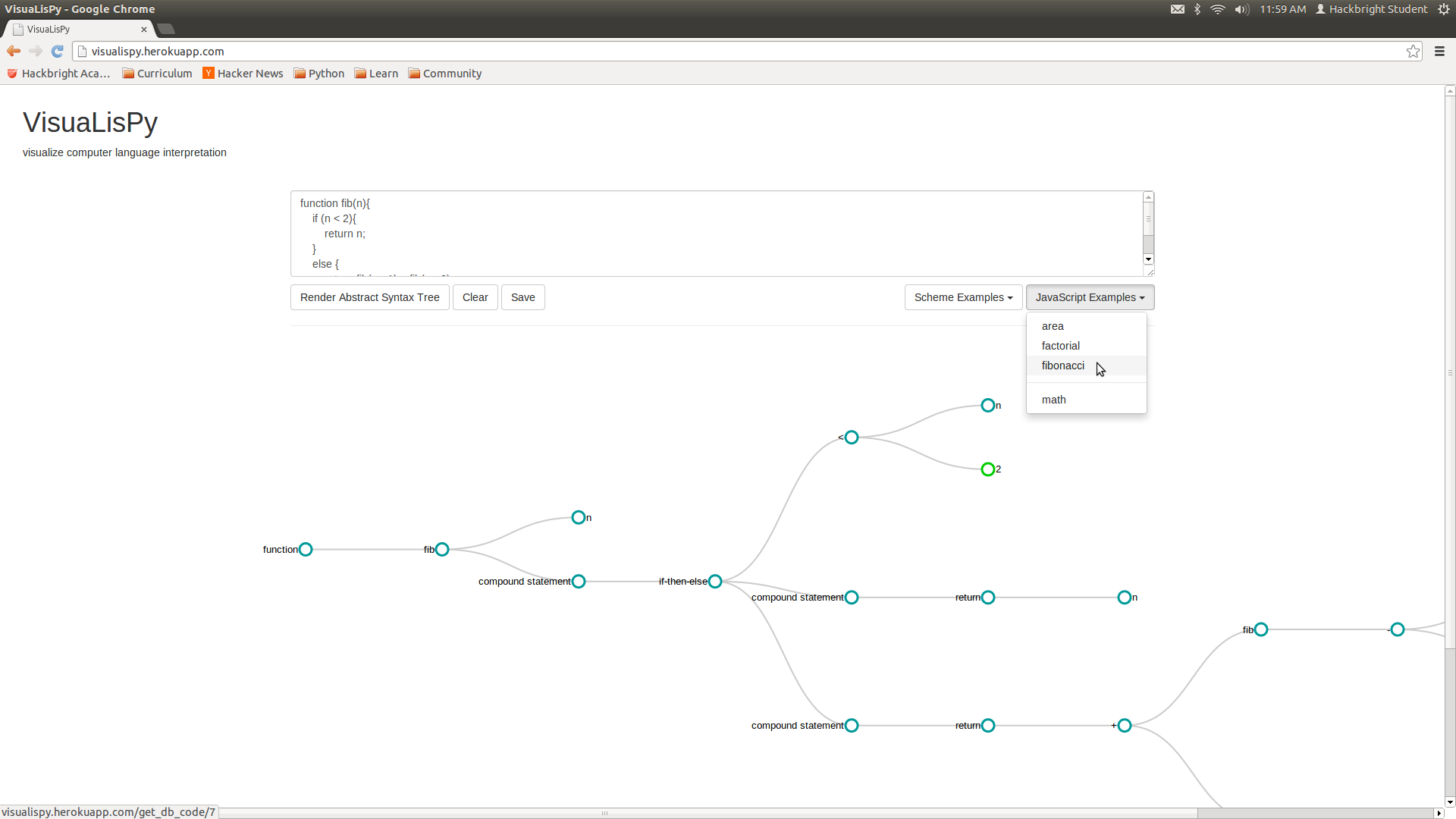
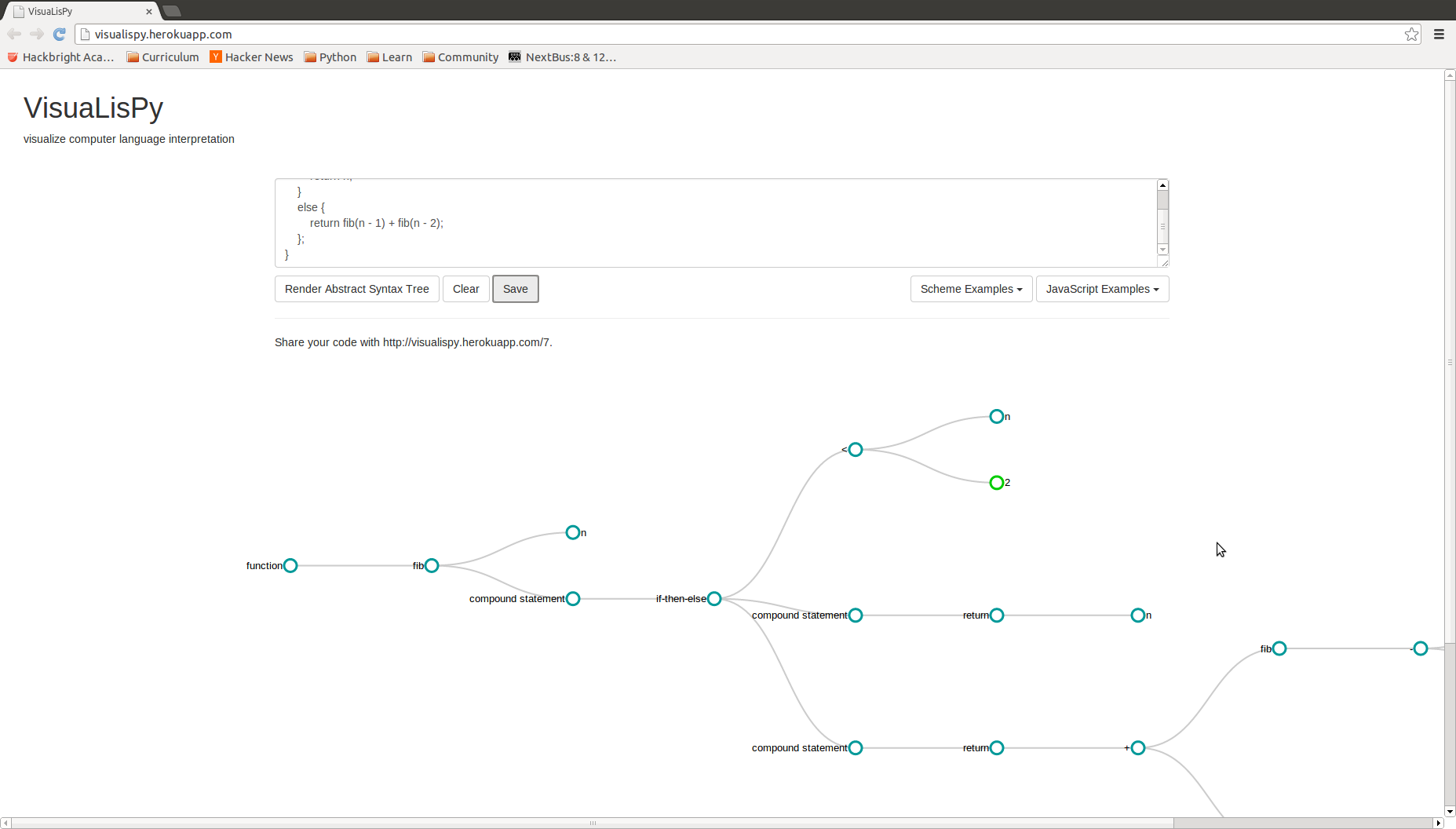
Users input a program in the provided text field. Clicking the "Render Abstract Syntax Tree" button will activate an Ajax POST request to retrieve a JSON object from the backend.
For the user input of defining a Fibonacci function in Scheme,
(define fib (lambda (n) (if (< n 2) n (+ (fib (- n 1)) (fib (- n 2))))))
the Scheme interpreter will output a JSON object in the following format via the format_json method.
{
"code": [
"(define fib (lambda (n) (if (< n 2) n (+ (fib (- n 1)) (fib (- n 2))))))"
],
"trace": [
{
"global_env": {
"equal?": "<built-in function eq>",
"list?": "<function <lambda> at 0x15dc050>",
"cons": "<function <lambda> at 0x15d6de8>",
">=": "<built-in function ge>",
"<=": "<built-in function le>",
"cdr": "<function <lambda> at 0x15d6ed8>",
"append": "<built-in function add>",
"null?": "<function <lambda> at 0x15dc0c8>",
"+": "<function add at 0x15d6c08>",
"*": "<function mul at 0x15d6cf8>",
"-": "<function sub at 0x15d6c80>",
"/": "<function div at 0x15d6d70>",
"fib": "<function <lambda> at 0x7f63200de9b0>",
"=": "<built-in function eq>",
"<": "<built-in function lt>",
">": "<built-in function gt>",
"not": "<built-in function not_>",
"symbol?": "<function <lambda> at 0x15dc140>",
"eq?": "<built-in function is_>",
"car": "<function <lambda> at 0x15d6e60>",
"list": "<function <lambda> at 0x15d6f50>",
"length": "<built-in function len>",
}
},
{
"expression_trace": [
{
"define": [
"define",
"fib",
[
"lambda",
[
"n"
],
[
"if",
[
"<",
"n",
2
],
"n",
[
"+",
[
"fib",
[
"-",
"n",
1
]
],
[
"fib",
[
"-",
"n",
2
]
]
]
]
]
]
}
]
}
]
}
Similarly, the JavaScript parser's format_json method outputs the program trace as a JSON object.
After a successful Ajax request, we call the drawTree method which first differentiates whether the user input was JavaScript or Scheme, then reformats the received JSON to align with D3.js's tree data structure. The AST renders with the aid of the D3.js JavaScript library utilized by our collapsible_tree.js file, which implements the Reingold-Tilford algorithm for efficient, tidy arrangement of layered nodes. For Scheme programs, nodes representing procedures are colored green with the editTree method, defined in edit_tree_post_rendering.js
Users can see visualization of the AST and collapse children nodes by clicking on parent nodes.
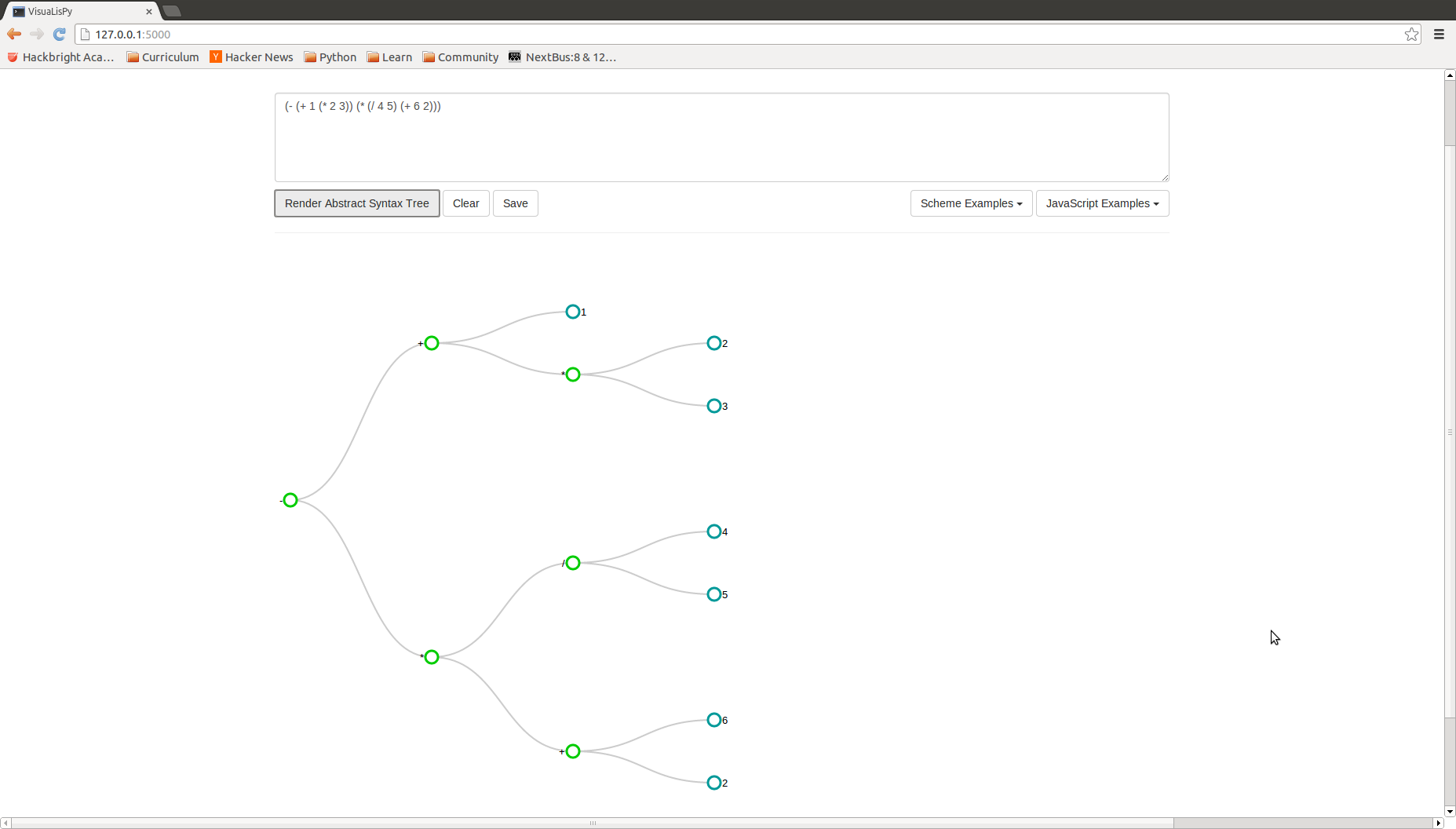
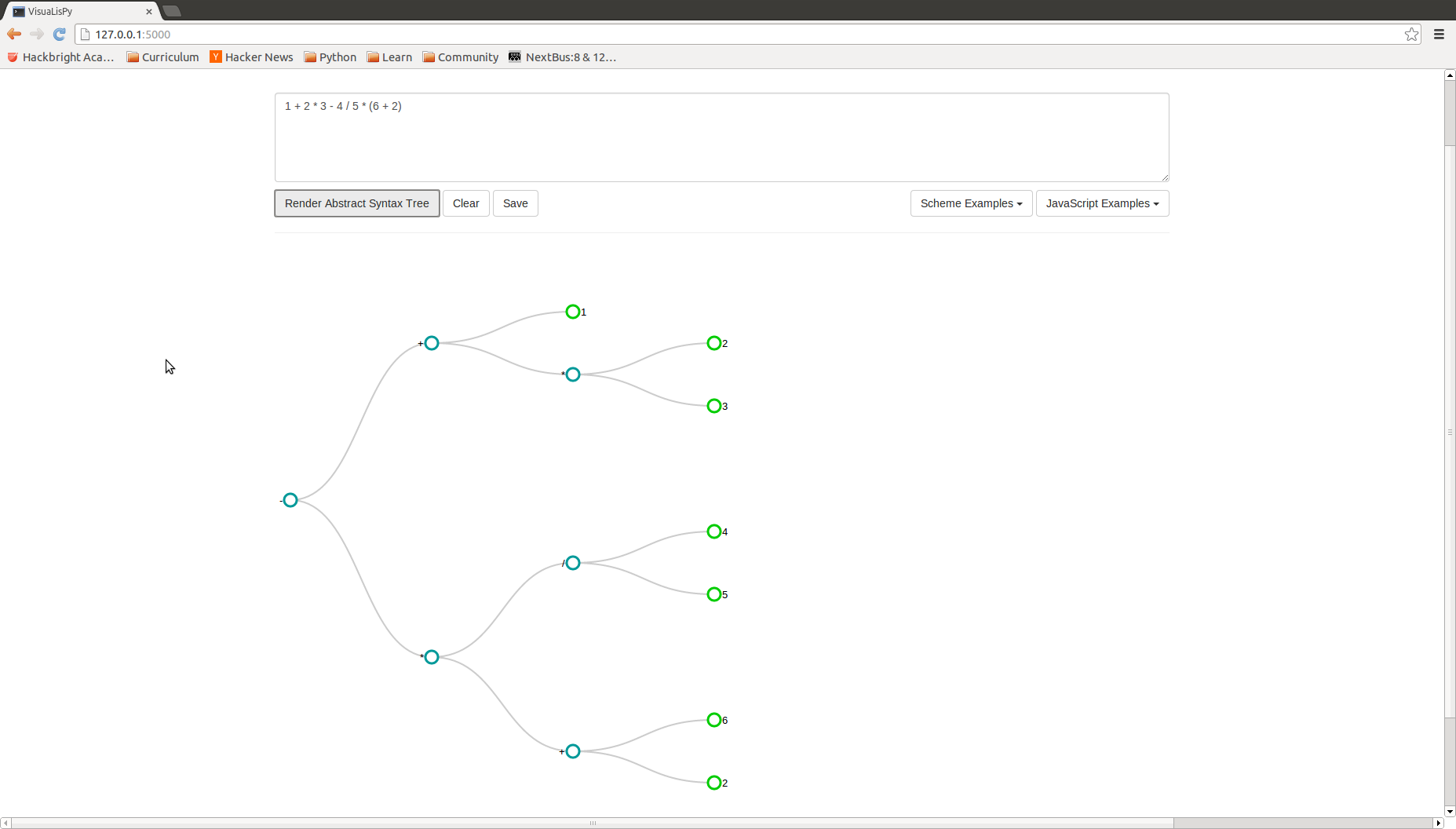
A clear illustration of the parsing difference between Scheme and JavaScript is the mathematical expression
- (- (+ 1 (* 2 3)) (* (/ 4 5) (+ 6 2))) in Scheme
- 1 + 2 * 3 - 4 / 5 * (6 + 2) in JavaScript
Though the syntax of JavaScript does not explicitly outline an order of operations, precedence rules included in the parse code produces the same AST for both languages.
The database of examples and user-submitted code started off in SQLite and later, to support potential deployment, migrated to PostgreSQL. I interacted with the database mostly through SQLAlchemy. The database was first seeded with example code. Through the web app, users are able to save their own input code to VisuaLisPy's database and share their input via a given URL.
###Future Goals Furthering my project, I wrote a simple code generator to compile Scheme into a subset of JavaScript. This was a relatively straight-forward process of translating the AST to fit the template of JavaScript's language structure. I plan to program a code generator to target C, which will involve type-casting and other presently unforeseen challenges, I'm sure. Perhaps I will one day make it to assembly...
###Lessons Learned
- Many particulars in parsing raw input with regex, keeping in mind precedence, prioritization, maximal munch.
- Computers can't deal with ambiguity, so syntactic ambiguity in code must be resolved somehow. An illustrative example of ambiguity in English is, "Time flies like an arrow; fruit flies like a banana." On a slight tangent, remember that grammatical/syntactical correctness does not imply proper semantics. Quintessential English example -- "Colorless green ideas sleep furiously." Currently, my Scheme interpreter checks for semantics during the evaluation phase, but my JavaScript parser lacks this feature.
- In order to optimize parsing, Udacity's CS262 course touched upon memoization and dynamic programming -- techniques I would like to revisit and learn more about.
- Also from the Udacity course, one can do some cool stuff with regex! Antivirus scanners use regex to detect potential viruses' machine code. Virus definitions that are periodically updated are simply a list of tokens with regex corresponding to a virus's payload (the part of malware that performs a malicious action). Outside of typical tech fields, there are also regex applications for detecting particular DNA or RNA protein sequences.
- Integrating with somebody else's code (D3.js), without documentation, may prove challenging. Along this line, I should document my own code as I am writing it and not simply all at the end. What is obvious to me at one point may no longer be obvious several weeks from now.
- Deployment is another beast entirely, as I learned firsthand. So, that's why DevOps/release management is its own department.
- Compilers and the existence of programming languages aren't so magical anymore. Compilers are translators from one language to another, basically, and I concretely see how one could go about creating an original language to fit whatever desired purpose. For example, Skyrim is scripted in a language called Papyrus -- which was created just for Skyrim. It's apparently a very quest-friendly language. :) tl;dr, computer languages are made-up, and you too can make one up yourself.
The more I learned, the more I realized how much more I want to learn.
#####Known bugs and limitations JavaScript parser
- (n - 1) must have spaces, else reads as '-1'. Will edit tokenizing rules and establish precedence for subtraction over negative numbers.
- if-then-else statement must end with semicolon (shouldn't be necessary).
Frontend
- Display more helpful error messages to users if input is incorrect (missing semicolons!).
Other
- For raw user input, differentiating between Scheme and JavaScript simply by checking to see whether the program begins with a '(' is not a robust method. No.
- Currently, there are no security features. User may be able to drop tables from my database or otherwise hack into the backend.
- Heroku tends to lag when the application is accessed for the first time after a period of no access. I may be able to remedy this by setting up a program to ping the app every so often to keep it constantly up and ready.
#####Additional features Backend
- parse JavaScript lists and loops. id followed by square brackets (indexing) will have higher precedence than list data type.
Frontend
- for mathematical expressions, display answers as nodes retract
- visualize environment/program interpretation.
- integrate CodeMirror and step through code blocks to visualize separate trees for multi-block intput program.