A demonstration of the transactional outbox messaging pattern (+ Log Trailing) with Amazon DynamoDB (+ Streams) written in Go.
For more information about transaction outbox pattern, please read this article.
For more information about log trailing pattern, please read this article.
Requirements
- 2 tables in Amazon DynamoDB (+ table stream).
- 1 serverless function in Amazon Lambda.
- 1 topic in Amazon Simple Notification Service (SNS).
Note: Live infrastructure is ready to deploy using the Terraform application from deployments/aws.
The architecture is very simple as it relies on serverless patterns and services provided by Amazon Web Services. Most of the heavy lifting is done by Amazon itself. Nevertheless, please consider factors such as Amazon Lambda concurrency limits and API calls from/to Amazon services as it could impact both performance and scalability.
Before implementing the solution, please create two Amazon DynamoDB tables. One called students and
the other called outbox.
The students table MUST have a property named student_id as Partition Key and another property
named school_id as Sort Key.
The outbox table MUST have a property named transaction_id as Partition Key and another property
named occurred_at as Sort Key.
All keys MUST be String.
Finally, enable Time-To-Live and Streams on the outbox table.
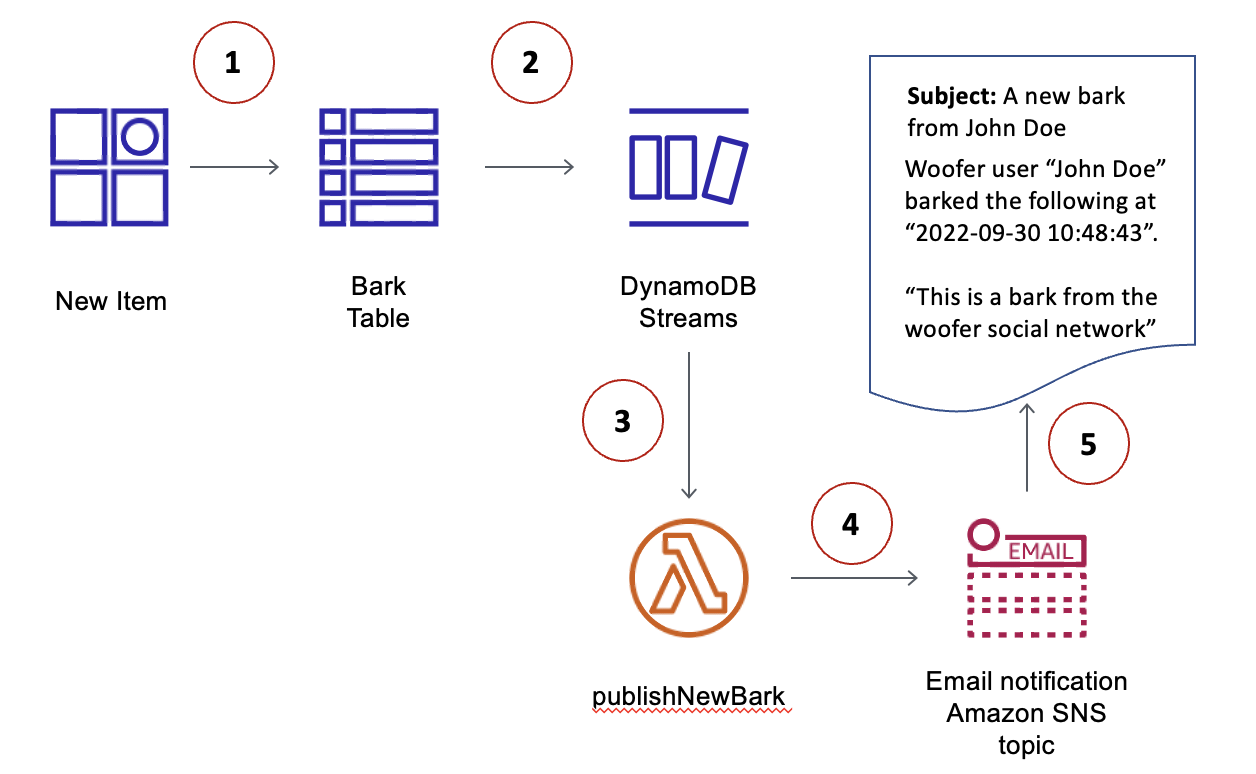
Overall architecture, took from this AWS article
The workflow is also very simple and so is straightforward.
- When writing in the database, the Amazon DynamoDB repository MUST call the
TransactionWriteItems- Add up business operations into the transaction to any tables required.
- Add up the domain events (encoded using JSON) into a single transaction to reduce transaction items and comply
with the 25 ops/per-transaction API limit.
This item MUST be written in the
outbox table.
- The new row will get projected into the
outboxtable stream. - The
outboxtable stream will trigger thelog trailing daemonAmazon Lambda function. - The serverless function will:
- Decode the domain events from the stream message (using JSON).
- Using
Neutrino Gluon, thepublish()function will transform domain events into integration events (Gluon uses CNCF's CloudEvents specification). - Gluon will publish the integration events into the desired event bus using the selected codec. In this specific scenario, messages will be published in Amazon Simple Notification Service (SNS) using Apache Avro codec.
- The event bus (Amazon SNS) will route the message to specific destinations. In event-driven systems, the most common destination are Amazon Simple Queue Service (SQS) queues (one-queue per job). This is called topic-queue chaining pattern.
Using the Time-To-Live (TTL) mechanism, batches of messages stored in the outbox table will get removed after
a specific time defined by the developer (for this example, default is 1 day). If Amazon DynamoDB is not an option,
a TTL mechanism MUST be implemented manually to keep the outbox table lightweight.
An open source alternative is Apache Cassandra which based most of its initial implementation from cloud-native solutions such as Amazon DynamoDB and Google BigQuery. It also has TTL mechanisms out the box.
Furthermore, the defined time for a record to be removed opens the possibility to replay batches of messages generated within transactions.
As the majority of event-driven systems, messages COULD be published without a specific order and additionally, messages COULD be published more than one time (caused by At-least one message delivery).
Thus, event handlers operations MUST be idempotent. More in deep:
- When creating an entity/aggregate:
- If a mutation or deletion arrives first to the system, fail immediately so the process can be retried after a specific time. While this backoff passes by, the create operation might get executed.
- When removing an entity/aggregate:
- If a mutation operation arrives after the removal, the handler MUST return no error and acknowledge the arrival of the message.
- When mutating an entity/aggregate:
- If an old version of the entity/aggregate arrives after, using the
Change-Data-Capture (CDC)
versiondelta orlast_update_timetimestamp, the operation MUST distinct between older versions and skip the actual mutation process and acknowledge the message arrival as it was actually updated. Theversionfield is recommended overlast_update_timeas time precision COULD lead into race conditions (e.g. using seconds while the operations take milliseconds, thus, the field could have basically the same time).
- If an old version of the entity/aggregate arrives after, using the
Change-Data-Capture (CDC)
If processes keep failing after N-times (N defined by the developer team), store poison messages into a Dead-Letter Queue (DLQ) so they can be replayed manually after fixes get deployed. No data should be lost.
Sometimes, a business might require functionality which align perfectly with the nature of events (reacting to change). For example, the product team might require to notify the user when he/she executes a specific operation.
In that scenario, using the techniques described before will not be sufficient to deal with the nature of event-driven systems (duplication and disorder of messages). Nevertheless, they are still solvable as they only require to do a specific action triggered by some event.
In order to solve duplication of processes, a table named inbox (or similar) COULD be used to track message processes
already executed in the system (even if it is a cluster of nodes).
More in deep:
- Message arrives.
- A middleware is called before the actual message process.
- The middleware checks if the message was already processed using the message id as key and the table
inbox.- If message was already processed, stop the process and acknowledge the arrival of the message.
- If not, continue with the message processing normally.
- The middleware checks if the message was already processed using the message id as key and the table
- The message process gets executed.
- The middleware will be called again.
- If the processing was successful, commit the message process as success in the
inboxtable.
- If the processing was successful, commit the message process as success in the
- If processing failed, do not acknowledge the message arrival, so it can be retried.
Finally, one thing to consider while implementing this approach is the necessity of a Time-To-Live (TTL)
mechanism, just as the outbox table, to keep the table lightweight.
Note: This inbox table COULD be implemented anywhere as it does not require transactions or any similar mechanism.
It is recommended to use an external database to reduce computational overhead from the main database used by business
operations. An in-memory database such as Redis (which also has built-in TTL) or even Amazon DynamoDB/Apache Cassandra
(distributed databases) are one of the best choices as they handle massive read operations efficiently.
In the other hand, if disordered processing is a serious problem for the business, the development team might take advantage of the previous described approach for duplication of processes adhering workarounds such as the usage of timestamps or even deltas to distinct the order of the processes. Getting deeper:
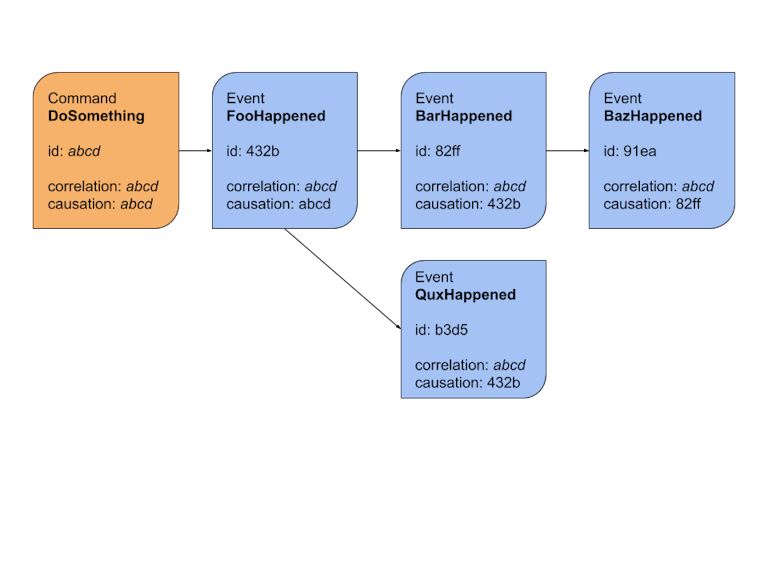
- Message arrives.
- A middleware
duplicationis called before the actual message process.- The middleware checks if the process was already processed.
- If already processed, stop the process and acknowledge the message.
- The middleware checks if the process was already processed.
- A middleware
disorderis called before the actual message process.- The middleware verifies if the previous process was already executed using the
causation_idproperty.- If not, return an error and do not acknowledge the message, so it can be retried again after a backoff.
- If previous process was already executed, continue with the message processing normally.
- The middleware verifies if the previous process was already executed using the
- The message process gets executed.
- The middleware
duplicationwill be called again.- If the processing was successful, commit the message process as success in the
inboxtable.
- If the processing was successful, commit the message process as success in the
- If processing failed, do not acknowledge the message arrival, so it can be retried.
For more information about this last approach, please read this article about correlation and causation IDs.