InferSharp: A Scalable Code Analytics Tool for .NET
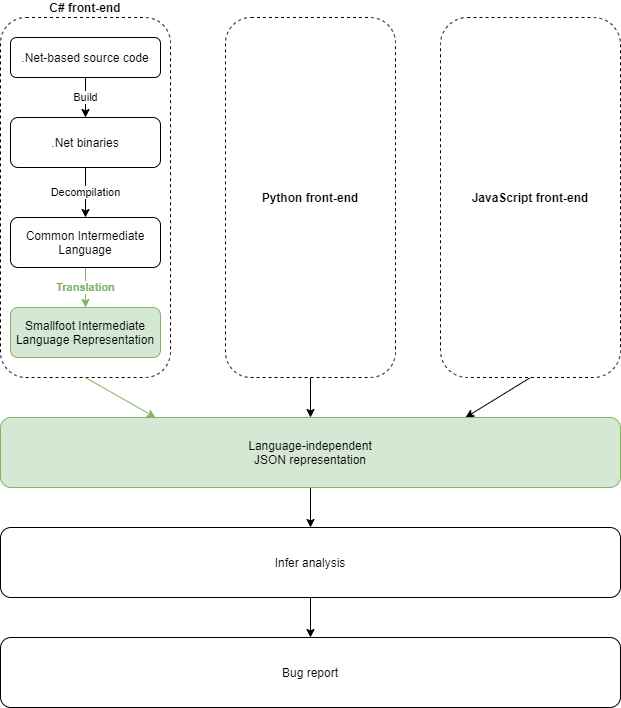
InferSharp brings the scalable, automated, and interprocedural memory safety analytics of Infer to the .NET platform. There are two key intellectual components of this work, highlighted in green in the diagram below.
- Support for scalable, interprocedural memory safety analytics of .NET code
- Language-independent interface for representing the SIL (Smallfoot Intermediate Language), the representation of code Infer uses to produce its analysis.
Much of the work in .NET memory safety analysis available on the market today is intraprocedural (the analysis is limited to a single method's context) or dependent on developer annotations. For example, PreFast detects some instances of null derereference exceptions and memory leaks, but its analysis is purely intraprocedural. Meanwhile, JetBrains Resharper heavily relies on developer annotations for its memory safety validation.
By contrast, an interprocedural analyzer like Infer considers context across different methods and can thereby detect more subtle issues. Moreover, it's automated (it does not rely on developer annotations), and scales effectively on large production codebases by analyzing incremental changes. It uses Separation Logic, a program logic for reasoning about manipulations to computer memory, to prove certain memory safety conditions. To do so, it leverages the Smallfoot predicate framework, which is represented in the Smallfoot Intermediate Language (SIL).
The core problem of enabling Infer to analyze .NET source code is that of translating it to the SIL, the language which Infer analyzes. To do this, source language constructs need to be represented in OCaml. InferSharp simplifies this task by introducing an intermediate language-agnostic layer, which relaxes language-dependent challenges present in other translation approaches.
In the C-language translation pipeline, the abstract syntax tree (AST) is exported to a JSON format, from which type definitions are extracted via the atdgen library and translated in OCaml. In the Java pipeline, an OCaml library known as Javalib is used to extract Java bytecode type definitions. These type definitions are then translated in OCaml. This approach presents the following key drawbacks:
-
It introduces language-specific library dependencies which can potentially be complex to surmount.
-
OCaml is a relatively non-mainstream language, making it difficult to find cross-language parsing libraries even for popular languages such as C# (or any other .NET language), Python or JavaScript.
-
Atdgen and other functionally similar libraries lack support for .NET, which prevents us from leveraging any of the prior approaches used in the Java/C-language pipelines to surmount the OCaml language barrier.
For these reasons, we introduce a language-agnostic JSON serialization of the SIL, coupled with a deserialization package which extracts the SIL data structures in OCaml. The output is then directly consumed by Infer's backend analysis.
The advantages of working from a low-level representation of the source code are twofold: first, the CIL underlies all .NET languages (such as Visual Basic and F# in addition to the most common C#), and therefore InferSharp supports all .NET languages this way, and second, the CIL is stripped of any syntactic sugar, which reduces the language content needed to translate and thereby simplifies the translation.
The primary components of this representation are the type environment and the control-flow graph (CFG). For an example illustrating these components, please see Example Translation.
We now discuss the implementation of the pipeline in greater detail. .NET binaries are first decompiled into the CIL using the Mono.Cecil library, from which we then retrieve the available type definition and method instructions. Type definition information includes:
- The full name of the type.
- The namespace associated with the type.
- The classes from which the type inherits.
- The instance fields of the type.
- The static fields of the type.
This information is retrieved for all types which appear in the software project, as well as for all the classes from which those types inherit. Each type is stored as an entry in a JSON file, which we call the type environment.
The second component is the control flow graph. For each procedure within the software project, the pipeline produces a procedure description, which is comprised of method information (full name, parameters, return type, and local variables) as a well as a list of the nodes (which contain successor/predecessor edge information) composing the procedure. These nodes are produced by the translation pipeline. It iterates over each instruction and parses it into its corresponding SIL instruction(s). These translated instructions are added to a CFG node, which in turn is added to the CFG node list. The resulting procedure description comprised of a list of node IDs as well as procedure metadata is then stored as an entry in the CFG JSON.
In other words, the control flow graph is formed from three conceptual components:
- Procedures: A list of all procedures that are available in the source code to be analyzed. Each procedure also includes the metadata associated with the method, such as name, parameters, return type, and local variables.
- Nodes/Edges: The nodes of a procedure contain the SIL instructions which comprise it; the edges connecting these nodes denote execution flow of the program.
- Priority Set: The order in which the procedures should be analyzed. If left empty, the analysis backend will decide on the order.
In this section we present an example of how the translation pipeline operates. In this example, we consider the source code depicted below:
public void InitializeInstanceObjectField(bool initializeToNull)
=> InstanceObjectField = initializeToNull ? null : new TestClass();Its corresponding bytecode is:
.method public hidebysig instance void
InitializeInstanceObjectField(bool initializeToNull) cil managed
{
// Code size 18 (0x12)
.maxstack 8
IL_0000: ldarg.0
IL_0001: ldarg.1
IL_0002: brtrue.s IL_000b
IL_0004: newobj instance void Cilsil.Test.Assets.TestClass::.ctor()
IL_0009: br.s IL_000c
IL_000b: ldnull
IL_000c: stfld class Cilsil.Test.Assets.TestClass Cilsil.Test.Assets.TestClass::InstanceObjectField
IL_0011: ret
} // end of method TestClass::InitializeInstanceObjectFieldA portion of the type environment JSON produced by the pipeline is illustrated below. It describes the class TestClass, which includes a description of its instance and static fields. In this case, the fields are also objects; this is indicated by the fact that they are identified as pointer types ("Tptr") to structured data types ("Tstruct").
{
"type_name": {
"csu_kind": "Class",
"name": "Cilsil.Test.Assets.TestClass",
"type_name_kind": "CsuTypeName"
},
"type_struct": {
"instance_fields": [
{
"field_name": "Cilsil.Test.Assets.TestClass.InstanceObjectField",
"type": {
"kind": "Pk_pointer",
"type": {
"struct_name": "Cilsil.Test.Assets.TestClass",
"type_kind": "Tstruct"
},
"type_kind": "Tptr"
},
"annotation": {
"annotations": []
}
},
{
"field_name": "Cilsil.Test.Assets.TestClass.InstanceArrayField",
"type": {
"kind": "Pk_pointer",
"type": {
"content_type": {
"kind": "Pk_pointer",
"type": {
"struct_name": "Cilsil.Test.Assets.TestClass",
"type_kind": "Tstruct"
},
"type_kind": "Tptr"
},
"type_kind": "Tarray"
},
"type_kind": "Tptr"
},
"annotation": {
"annotations": []
}
}
],
"static_fields": [
{
"field_name": "Cilsil.Test.Assets.TestClass.StaticObjectField",
"type": {
"kind": "Pk_pointer",
"type": {
"struct_name": "Cilsil.Test.Assets.TestClass",
"type_kind": "Tstruct"
},
"type_kind": "Tptr"
},
"annotation": {
"annotations": []
}
},The translation of the bytecode into the CFG operates as follows:
- The CFG always contains a start node which acts as the source node, and an exit node which acts as the sink node. The nodes which contain the instructions associated with the body of the method body are mostly identified with the MethodBody type, though nodes containing invocations to other methods are identified as Call nodes.
- ldarg.0 refers to pushing the first argument (in this case, 'this', as InitializeInstanceObjectField is an instance method) onto the program stack, and is translated to the translated SIL Load instruction n$0=this:Cilsil.Test.Assets.TestClass, which indicates that the VarExpression n$0 refers to the value of "this", which is of type Cilsil.Test.Assets.TestClass*.
- ldarg.1 refers to pushing the second argument, the boolean initializeToNull, onto the program stack, and is translated to the SIL Load instruction n$1=*initializeToNull:bool, which indicates that the VarExpression n$1 refers to the value of initializeToNull, which is of type bool.
- brtrue.s IL_000c pops the item at the top of the program stack (which is the value of initializeToNull in this particular case), and if it evaluates to true, control transfers to instruction IL_000c. This translates to the SIL Prune instruction, which branches on the value of n$1. If it is true, then the ldnull instruction causes null to be pushed onto the program stack; if it is false, then an instantiated TestClass object is pushed onto the program stack (via the newobj instruction) and control is passed to instruction IL_000c (br.s IL_000c).
- stfld translates to the pop of the field owner (in this case, n$0) as well as the value to be stored (in this case, either null or an instantiated object) off of the program stack. In the SIL, this becomes a Store SIL instruction of null or the instantiated object into n$0.InstanceObjectField.
- ret refers to removing the value off the top of the stack (in this case, there is none -- the method has a void return type) and returning it.
The CFG we produce is depicted below. Within any given CFG, a node is associated with an integer identifier, a list of predecessor node identifiers ("preds"), a list of successor node identifiers ("succs"), and a list of exception node identifiers ("exn").
n$0 denotes the value of the TestClass pointer "this" and n$1 denotes the value of the boolean variable initializeToNull. Similar to C's syntax, the expression *n$0.Cilsil.Test.Assets.TestClass.InstanceObjectField indicates that null is being stored at n$0's InstanceObjectField.
The PRUNE nodes indicate control flow depending on the truth value of n$1.
The instructions of node16586 are associated with object allocation; first, memory of size TestClass is allocated and identified by n$2. Then, the constructor for TestClass is invoked on the allocated memory. Finally, this newly-allocated object's pointer is assigned as the value of n$0's InstanceObjectField.
node16583 preds: 16580 succs: 16584 16585 exn: 16582 MethodBody
n$0=*&this:Cilsil.Test.Assets.TestClass* [Line 41];
n$1=*&initializeToNull:bool [Line 41];
node16584 preds: 16583 succs: 16581 exn: 16582 MethodBody
PRUNE (n$1, True) [Line 41];
*n$0.Cilsil.Test.Assets.TestClass.InstanceObjectField:Cilsil.Test.Assets.TestClass:Cilsil.Test.Assets.TestClass=null [Line 41];
node16585 preds: 16583 succs: 16586 exn: 16582 MethodBody
PRUNE (!(n$1):, False) [Line 41];
node16586 preds: 16585 succs: 16581 exn: 16582 Call
n$2:Cilsil.Test.Assets.TestClass*=_fun static BuiltIn.__new() (sizeof(Cilsil.Test.Assets.TestClass, exact):Cilsil.Test.Assets.TestClass*) [Line 41];
n$3:void=_fun System.Void Cilsil.Test.Assets.TestClass..ctor() (n$2:Cilsil.Test.Assets.TestClass*) [Line 41];
*n$0.Cilsil.Test.Assets.TestClass.InstanceObjectField:Cilsil.Test.Assets.TestClass:Cilsil.Test.Assets.TestClass=n$2 [Line 41];
The CFG is then analyzed via Infer to produce a bug report. For example, in the following piece of code referencing the method above:
public void TestMethod()
{
TestClass Tc;
Tc = new TestClass();
Tc.InitializeInstanceObjectField(true);
_ = Tc.InstanceObjectField.GetHashCode();
}Infer finally interprocedurally detects that that Tc.InstanceObjectField is null, a dereference of which constitutes an error:
Assets/TestCode.cs:14: error: NULL_DEREFERENCE (biabduction/Rearrange.ml:1622:55-62:)
[B5] pointer `%0->Cilsil.Test.Assets.TestClass.InstanceObjectField` could be null and is dereferenced at line 14, column 1.
12. Tc = new TestClass();
13. Tc.InitializeInstanceObjectField(true);
14. > _ = Tc.InstanceObjectField.GetHashCode();