This repository has been archived by the owner on Oct 17, 2023. It is now read-only.
-
Notifications
You must be signed in to change notification settings - Fork 32
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Initial commit move from google code repo
- Loading branch information
Showing
20 changed files
with
1,124 additions
and
4 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,4 +1,27 @@ | ||
| Chrome-Crawler | ||
| ============== | ||
|
|
||
| An extension for google chrome that lets a use crawl a webpage for files and links | ||
| # Chrome Crawler | ||
|
|
||
| Is a web spider extension for Google Chrome. | ||
|
|
||
| ## Description | ||
|
|
||
| 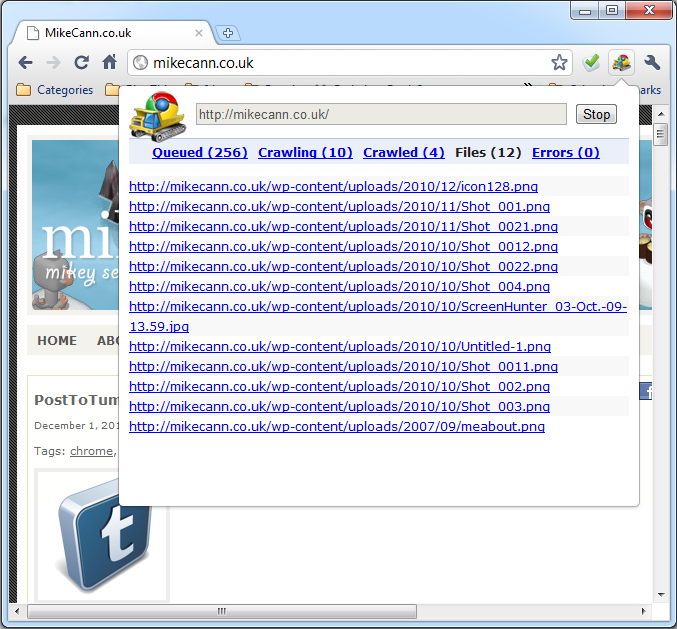 | ||
|
|
||
| The idea is simple really. You just give it a URL, it then goes off and finds all the links on that page then follows them to more pages then gets all the links and follows them and so on and so on. | ||
|
|
||
| Along the way it checks each page to see if there are any ‘interesting’ files linked there, if it finds an interesting link it will flag it for you so you can check it out. | ||
|
|
||
| Theres an options page that lets you customise the way it all works: | ||
|
|
||
| 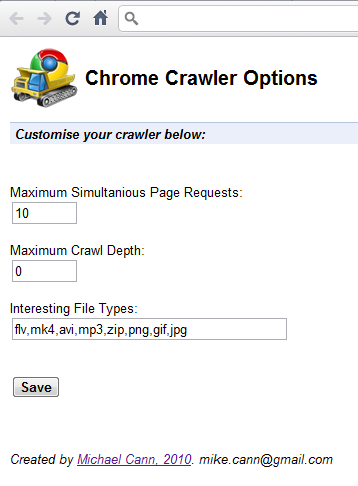 | ||
|
|
||
| ## Get the Extension | ||
|
|
||
| Grab it on the Chrome Web Store: <https://chrome.google.com/webstore/detail/amjiobljggbfblhmiadbhpjbjakbkldd> | ||
|
|
||
| ## Blog | ||
|
|
||
| Find out more on my blog: | ||
|
|
||
| + <http://mikecann.co.uk/personal-project/chrome-crawler-a-web-crawler-written-in-javascript/> | ||
| + <http://mikecann.co.uk/personal-project/chrome-crawler-v0-4-background-crawling-more/> | ||
| + <http://mikecann.co.uk/personal-project/chrome-crawler-v0-5/> |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,4 @@ | ||
| <script src="lib/jquery-1.4.3.min.js"></script> | ||
| <script src="lib/jit-yc.js"></script> | ||
| <script src="helpers.js"></script> | ||
| <script src="chromeCrawlBG.js"></script> |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,177 @@ | ||
| // JavaScript Document | ||
|
|
||
| var tabs = ["Queued","Crawling","Crawled","Files","Errors"]; | ||
| var allPages = {}; | ||
| var crawlStartURL = null; | ||
| var startingHost = ""; | ||
| var startingPage = {}; | ||
| var appState = "stopped"; | ||
| //var maxDepth = parseInt(localStorage["max-crawl-depth"]?localStorage["max-crawl-depth"]:2); | ||
| //var maxSimultaniousCrawls = parseInt(localStorage["max-page-loads"]?localStorage["max-page-loads"]:10); | ||
| //var interestingFileTypes = getInterestingFileTypes(); | ||
|
|
||
| var settings = | ||
| { | ||
| get maxDepth() { return localStorage["max-crawl-depth"]!=null?localStorage["max-crawl-depth"]:2; }, | ||
| set maxDepth(val) { localStorage['max-crawl-depth'] = val; }, | ||
|
|
||
| get maxSimultaniousCrawls() { return localStorage["max-page-loads"]!=null?localStorage["max-page-loads"]:10; }, | ||
| set maxSimultaniousCrawls(val) { localStorage['max-page-loads'] = val; }, | ||
|
|
||
| get pauseOnPopClose() { return localStorage["pause-popup-close"]!=null?localStorage["pause-popup-close"]:1; }, | ||
| set pauseOnPopClose(val) { localStorage['pause-popup-close'] = val; }, | ||
|
|
||
| get interestingFileTypes() | ||
| { | ||
| var types = (localStorage["interesting-file-types"]!=null?localStorage["interesting-file-types"]:"flv,mk4,ogg,swf,avi,mp3,zip,png,gif,jpg").split(","); | ||
| for (var i in types) { types[i] = $.trim(types[i]); } | ||
| return types; | ||
| }, | ||
| set interestingFileTypes(val) { localStorage['interesting-file-types'] = val; } | ||
| } | ||
|
|
||
| function beginCrawl(url) | ||
| { | ||
| reset(); | ||
| appState = "crawling"; | ||
| crawlStartURL = url; | ||
| startingHost = parseUri(url)["protocol"] + "://" + parseUri(url)["host"]; | ||
| allPages[url] = {url:url, state:"queued", depth:0, host:startingHost, parsed:parseUri(url)}; | ||
| startingPage = allPages[url]; | ||
| crawlMore(); | ||
| } | ||
|
|
||
| function crawlPage(page) | ||
| { | ||
|
|
||
| page.state = "crawling"; | ||
| page.parsed = parseUri(page.url); | ||
|
|
||
| console.log("Starting Crawl --> "+JSON.stringify(page)); | ||
| page.request = $.get(page.url, null, function(data, textStatus) | ||
| { | ||
| // Dont forget to remove this reference! | ||
| delete page.request; | ||
|
|
||
| // If no data than it was aborted handle here | ||
| if(!data) { page.state = "queued"; } | ||
| else { onCrawlPageLoaded(page,data) ; } | ||
| }); | ||
| //refreshPage(); | ||
| } | ||
|
|
||
| function onCrawlPageLoaded(page,data) | ||
| { | ||
| // Grab all the links on this page | ||
| var links = getAllLinksOnPage(data); | ||
|
|
||
| // We want to count some of the following | ||
| var counts = {roots:0, scripts:0, badProtocols:0, newValids:0, oldValids:0, interestings:0, domWindows:0} | ||
|
|
||
| // Loop through each | ||
| $(links).each(function() | ||
| { | ||
| var linkURL = this+""; | ||
| var absoluteURL = linkURL; | ||
| var parsed = parseUri(linkURL); | ||
| var protocol = parsed["protocol"]; | ||
|
|
||
| if(linkURL == "[object DOMWindow]") | ||
| { | ||
| counts.domWindows++; | ||
| return true; | ||
| } | ||
| else if(startsWith(linkURL,"/")) | ||
| { | ||
| absoluteURL = page.host+"/"+linkURL; | ||
| counts.roots++; | ||
| } | ||
| else if(protocol=="") | ||
| { | ||
| absoluteURL = page.url+"/../"+linkURL; | ||
| counts.roots++; | ||
| } | ||
| else if(protocol=="javascript") | ||
| { | ||
| //console.log("Not Crawling URL, cannot follow javascript --- "+hrefURL); | ||
| counts.scripts++; | ||
| return true; | ||
| } | ||
| else if(protocol!="http" && protocol!="https") | ||
| { | ||
| //console.log("Not crawling URL, unknown protocol --- "+JSON.stringify({protocol:protocol, url:hrefURL})); | ||
| counts.badProtocols++; | ||
| return true; | ||
| } | ||
|
|
||
| if(!allPages[absoluteURL]) | ||
| { | ||
| // Increment the count | ||
| counts.newValids++; | ||
|
|
||
| // Build the page object | ||
| var o = {}; | ||
| o.depth = page.depth+1; | ||
| o.url = absoluteURL; | ||
| o.state = page.depth==settings.maxDepth?"max_depth":"queued"; | ||
| o.host = parseUri(o.url)["protocol"] + "://" + parseUri(o.url)["host"]; | ||
|
|
||
| // Get the file extension | ||
| var extn = getFileExt(absoluteURL); | ||
|
|
||
| //console.log(JSON.stringify(o)); | ||
|
|
||
| // Is this an interesting extension? | ||
| if(isInArr(settings.interestingFileTypes,extn)) { o.isFile=true; counts.interestings++; } | ||
|
|
||
| // Save the page in our master array | ||
| allPages[absoluteURL] = o; | ||
| } | ||
| else | ||
| { | ||
| counts.oldValids++; | ||
| } | ||
|
|
||
| }); | ||
|
|
||
| // Debugging is good | ||
| console.log("Page Crawled --> "+JSON.stringify({page:page, counts:counts})); | ||
|
|
||
| // This page is crawled | ||
| allPages[page.url].state = "crawled"; | ||
|
|
||
| // Check to see if anything else needs to be crawled | ||
| crawlMore(); | ||
|
|
||
| // Render the changes | ||
| //refreshPage(); | ||
| } | ||
|
|
||
| function crawlMore() | ||
| { | ||
| if(appState!="crawling"){ return; } | ||
| while(getURLsInTab("Crawling").length<settings.maxSimultaniousCrawls && getURLsInTab("Queued").length>0) | ||
| { | ||
| crawlPage(getURLsInTab("Queued")[0]); | ||
| } | ||
| } | ||
|
|
||
| function getURLsInTab(tab) | ||
| { | ||
| var tabUrls = []; | ||
| for(var ref in allPages) | ||
| { | ||
| var o = allPages[ref]; | ||
| if(tab=="Queued" && o.state=="queued" && !o.isFile){ tabUrls.push(o); } | ||
| else if(tab=="Crawling" && o.state=="crawling"){ tabUrls.push(o); } | ||
| else if(tab=="Crawled" && o.state=="crawled"){ tabUrls.push(o); } | ||
| else if(tab=="Files" && o.isFile){ tabUrls.push(o); } | ||
| else if(tab=="Errors" && o.state=="error"){ tabUrls.push(o); } | ||
| }; | ||
| return tabUrls; | ||
| } | ||
|
|
||
| function reset() | ||
| { | ||
| allPages = {}; | ||
| } |
Oops, something went wrong.