Project นี้เป็นส่วนหนึ่งของวิชา CHHD304 การแพทย์แม่นยำเบื้องต้น (Introduction to Precision Medicine) ภาคเรียนที่ 1 ปีการศึกษา 2565 โดยข้อมูลที่ใช้มาจาก kaggle: Personalized Medicine: Redefining Cancer Treatment
- เพื่อศึกษาว่าใน Dataset นี้ แต่ละ Class (ทั้ง 9 class) มีความหมายอย่างไร โดยใช้การทำ Topic Modeling เข้ามาช่วย
เนื่องจากในรายละเอียดของ Dataset นี้ ไม่ได้ระบุไว้ว่าแต่ละ Class มีความหมายอย่างไรเลย ซึ่งการทำความเข้าใจข้อมูลเป็นสิ่งที่สำคัญใน Data Science Process ซึ่งจะทำให้สามารถนำไปวิเคราะห์ต่อได้อย่างมีประสิทธิภาพ
สาเหตุที่กลุ่มพวกเราเลือกทำ Topic Modeling เพราะเป็นสิ่งที่กลุ่มเราไม่เคยลองทำมาก่อนเลย นี่จึงถือเป็นการเรียนรู้สิ่งใหม่ ๆ ไปด้วย และ Dataset นี้เป็นข้อมูล text ที่มีความยาวอย่างมาก จึงมีความน่าสนใจที่จะทำ Topic Modeling นอกจากนี้กลุ่มอื่น ๆ ที่ได้หัวข้อเดียวกับกลุ่มเรา ได้เลือกทำ Classification ไปแล้ว กลุ่มเราเลยตัดสินใจไม่ทำซ้ำจะได้ไม่เกิดข้อเปรียบเทียบขึ้น
- Rujikorn Sangsumrit
- Piyatida Meesatean
- Ornrakorn Mekchaiporn
ข้อมูลที่ใช้มาจาก kaggle: Personalized Medicine: Redefining Cancer Treatment ซึ่งในข้อมูลนี้มีหลายไฟล์มาก แต่ในการทำ Topic Modeling เราจะใช้ไฟล์ training_variants และ training_text ทั้งสองไฟล์มี 3,321 datapoints
- training_variants ประกอบด้วย 4 Columns ดังนี้
- ID = (the id of the row used to link the mutation to the clinical evidence)
- Gene (the gene where this genetic mutation is located)
- Variation (the aminoacid change for this mutations)
- Class (1-9 the class this genetic mutation has been classified on)

ตัวอย่างข้อมูลจากไฟล์ training_variants
- training_text ประกอบด้วย 2 Columns ดังนี้
- ID (the id of the row used to link the clinical evidence to the genetic mutation)
- Text (the clinical evidence used to classify the genetic mutation)

ตัวอย่างข้อมูลจากไฟล์ training_text
- python โดยใช้ library ดังนี้ pandas, nltk, re, PorterStemmer, WordNetLemmatizer, Counter, matplotlib.pyplot, WordCloud, LatentDirichletAllocation, CountVectorizer
- tableau (for Students)
- ความยาวของ Text ในข้อมูล

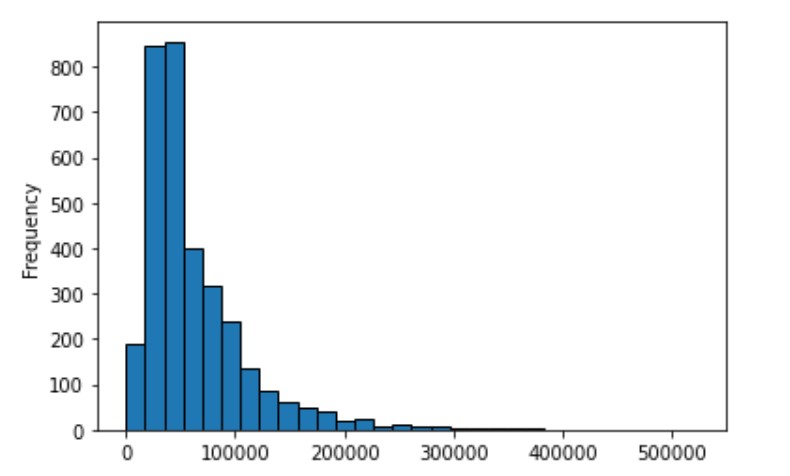
จากทั้งสองกราฟ จะเห็นว่าข้อมูลนี้เป็นข้อมูล text ที่มีความยาวอย่างมาก ส่วนใหญ่จะมีความยาวประมาณ 5000 เลย
เพื่อให้เห็นภาพมากขึ้นเรายกตัวอย่างข้อมูลจาก column TEXT เพียง 1 row โดยมีความยาว (str.len()) อยู่ที่ 39,672

จะเห็นว่า TEXT มันยาวมาก ๆ หากลองมองดู(มองยากนิดนึง)จะเหมือนกับ paper งานวิจัยนึงเลยมีทั้ง fig table และ citation
- จำนวนแต่ละ Class ในข้อมูล
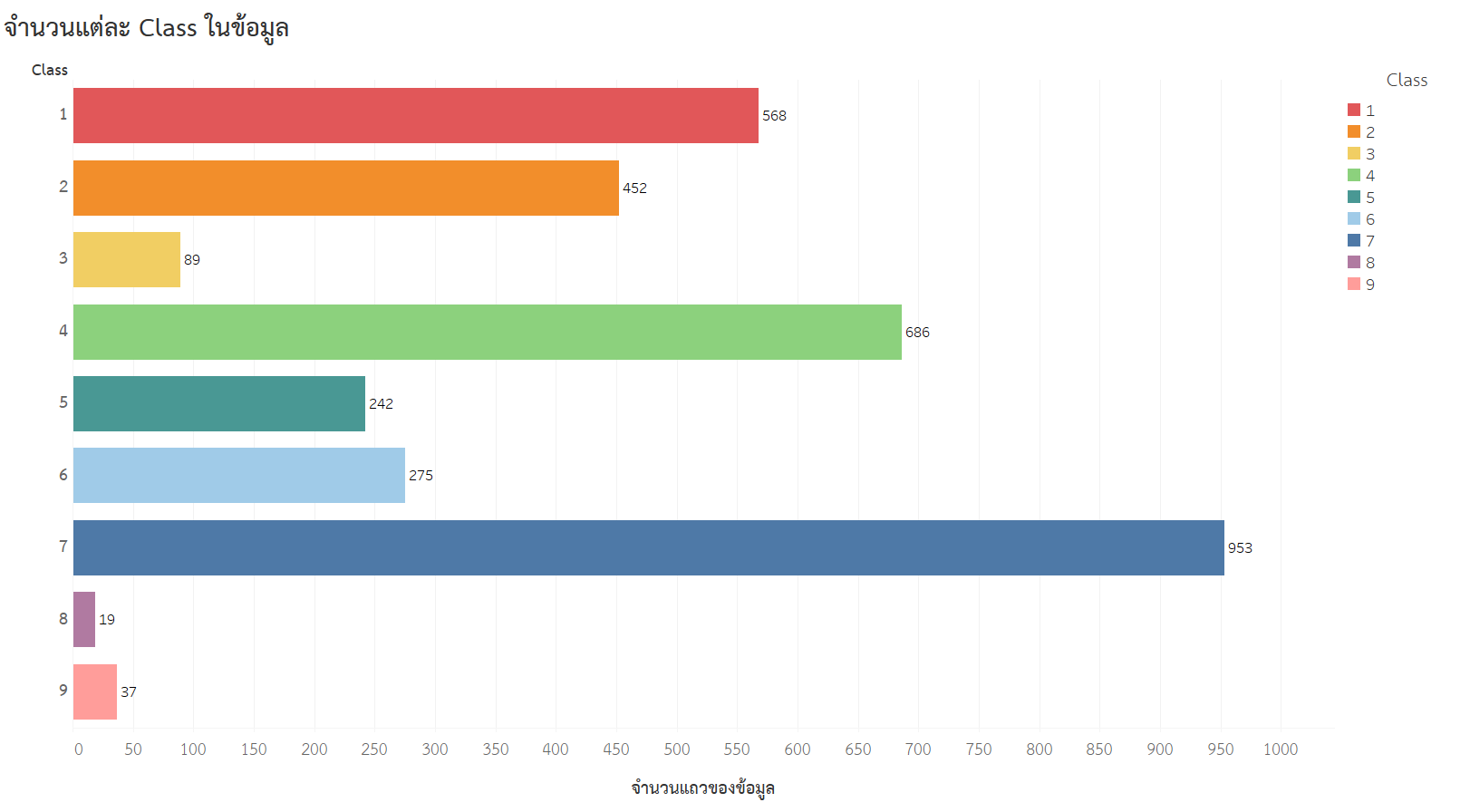
จากกราฟจะเห็นว่ามีทั้งหมด 9 Class แต่ละ Class มีจำนวนที่ต่างกันมาก ๆ โดย Class ที่มีจำนวนมากที่สุดคือ Class ที่ 7 ซึ่งมีจำนวน 953 rows และ Class ที่มีจำนวนน้อยที่สุดคือ Class ที่ 8 ซึ่งมีจำนวนเพียง 19 rows
- จำนวน Gene ที่พบมาก 10 อันดับ
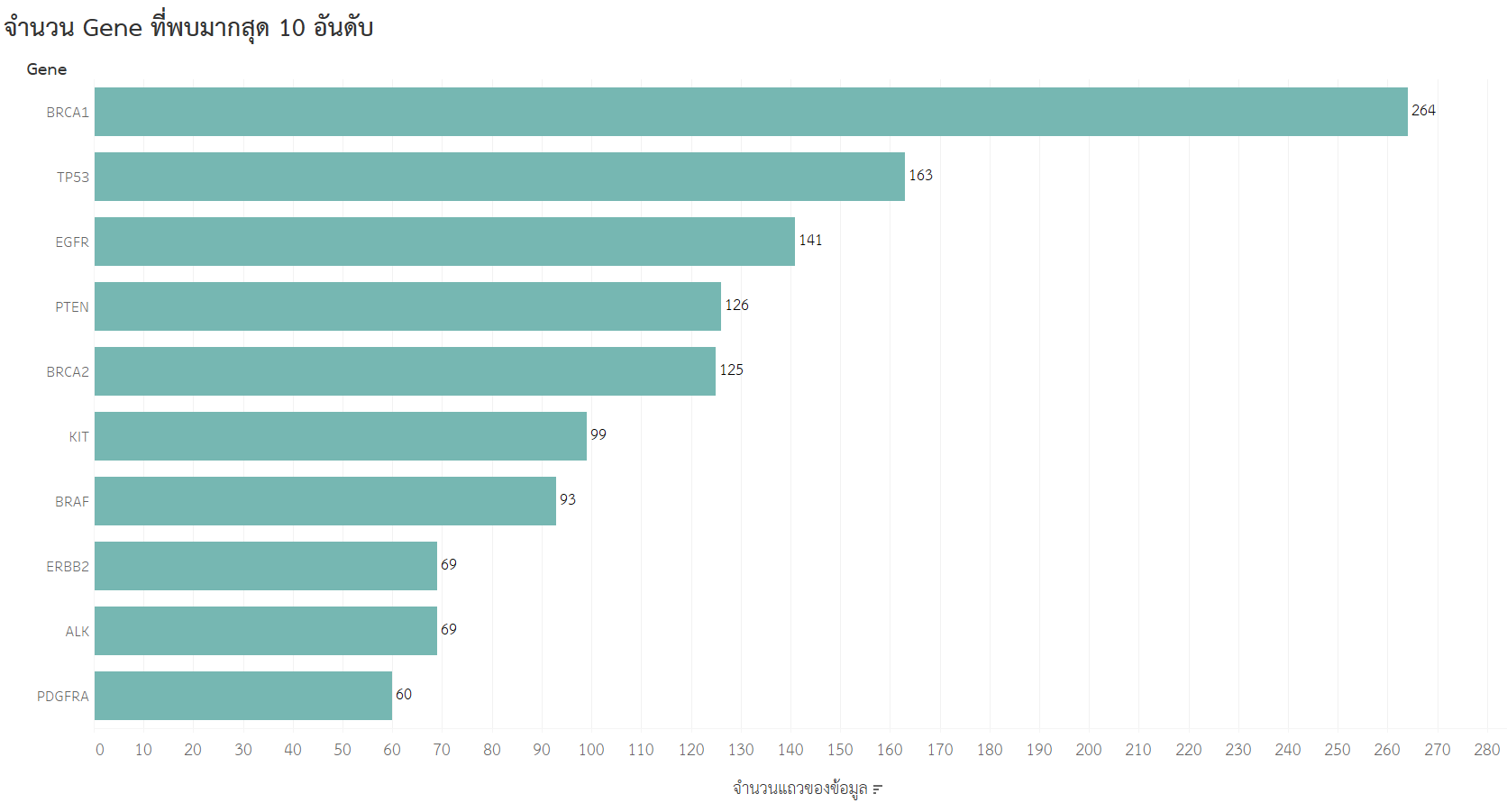
จากกราฟจะเห็นว่า BRCA1 เป็น Gene ที่พบมากเป็นอันดับหนึ่ง มีจำนวน 264 rows ซึ่ง BRCA1 เป็นยีนในมนุษย์ ที่ช่วยซ่อมแซม DNA ที่เสียหายและชะลอการแบ่งตัวของเซลล์ แต่ถ้ายีนนี้เกิดการกลายพันธุ์ก็มีความเสี่ยงต่อการเกิดโรคในกลุ่มมะเร็งเต้านมและมะเร็งรังไข่ได้ (2)
และ PDGFRA เป็น Gene ที่พบมากเป็นอันดับสิบ เป็นยีนที่เข้ารหัสโปรตีนที่เรียกว่า "platelet-derived growth factor receptor alpha" (PDGFRA) ซึ่งเป็นส่วนหนึ่งของตระกูลของโปรตีนที่เรียกว่า "receptor tyrosine kinases" (RTKs) ซึ่งเป็นตัวรับสารสื่อกระตุ้นการเจริญเติบโตบนผิวเซลล์ (3)
- จำนวน Variation ที่พบมาก 10 อันดับ

จากกราฟจะเห็นว่า Truncating mutations เป็น Variation ที่พบมากเป็นอันดับหนึ่ง มีจำนวน 93 rows Truncating mutations มีอีกชื่อคือ Nonsense Mutations ซึ่งเป็นหนึ่งใน point mutations โดยเมื่อมีการเปลี่ยนแปลงในระดับ DNA แล้ว ก็จะเกิด stop codon ทำให้ได้สาย RNA สั้นลง ซึ่งอาจนำไปใช้ต่อได้หรือไม่ได้ ถ้าสามารถนำไปใช้ได้อาจเกิดโรคได้ แต่ถ้าไม่เกิดอะไรเลย ก็อาจถูกทำลายไปในกระบวนการการทำลาย RNA ที่ผิดปกติในร่างกาย
ส่วน T58, Q61R, Q61L และ Q61H มีจำนวนอย่างละ 3 rows เป็นรหัสที่เกี่ยวข้องกับการเปลี่ยนแปลงในกรดอะมิโนในโปรตีน
- Wordcloud
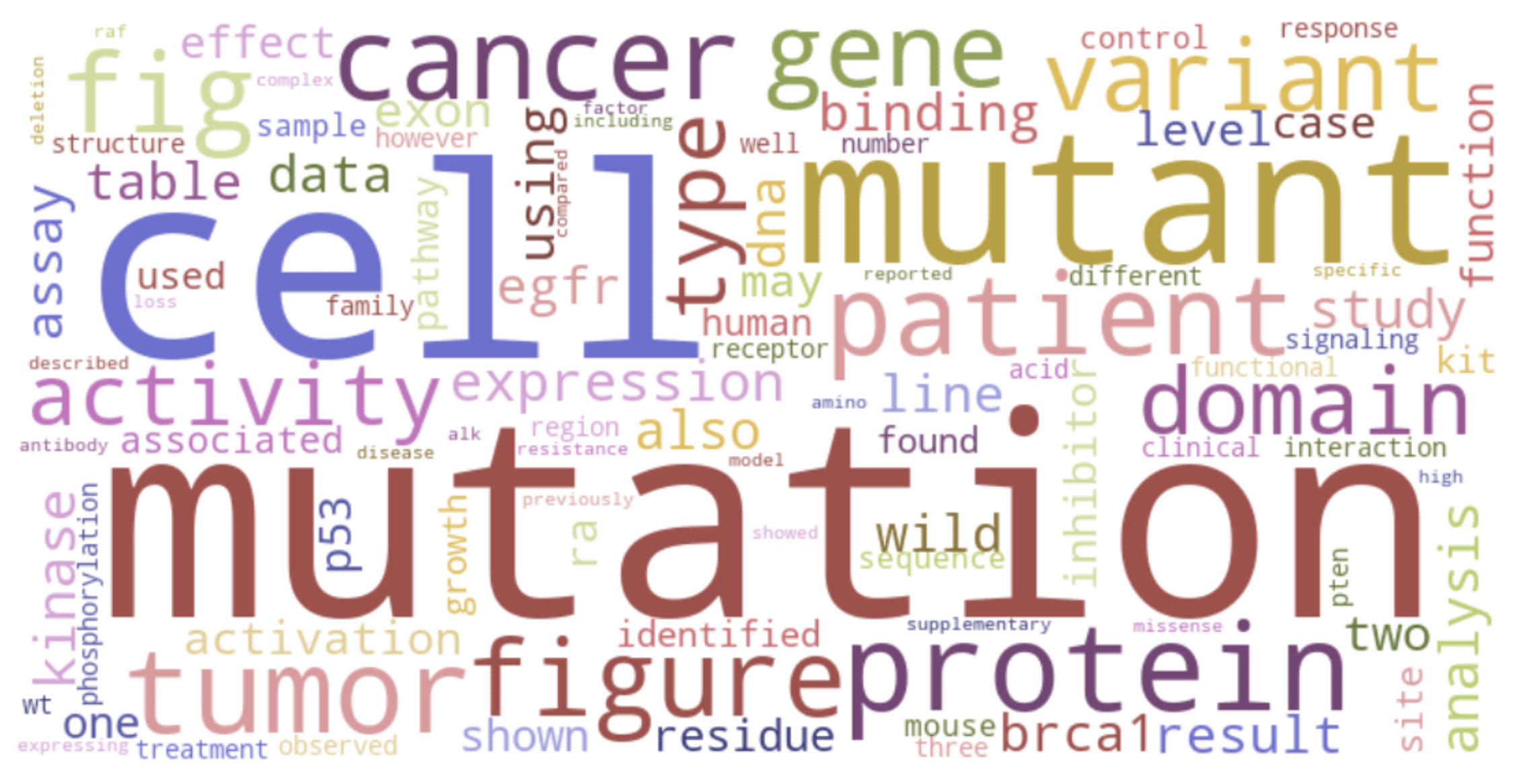
จากภาพ Wordcloud จะเห็นว่า mutation และ cell เป็นคำที่มีขนาดใหญ่พอ ๆ กัน และพบมากที่สุด รองลงมาเป็น mutant จากนั้น cancer, tumor, figure, protein, patient, gene, variant เป็นต้น
📍note that: การทำ Wordcloud เราได้ทำ Data Preparation ดังภาพด้านล่างนี้

- จำนวน Text ที่พบมาก 10 อันดับ
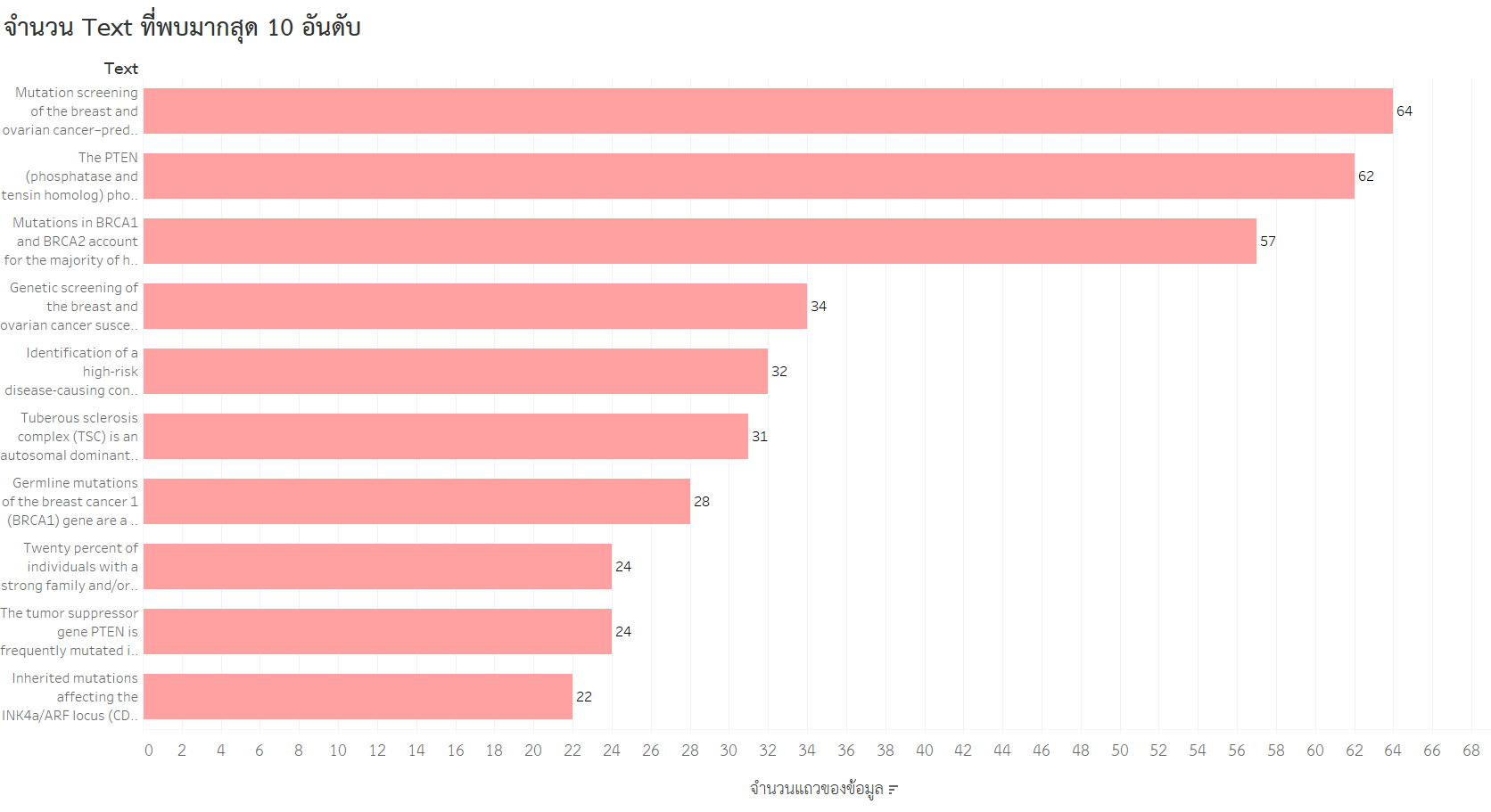
- มี Text ที่เหมือนกัน แต่อยู่คนละ Class
พวกเราเกิดความสงสัยต่อว่า Text ที่ซ้ำกันทั้ง 10 อันดับ ไปปรากฏใน class ไหนบ้าง ซึ่งได้ผลดังกราฟด้านล่างนี้
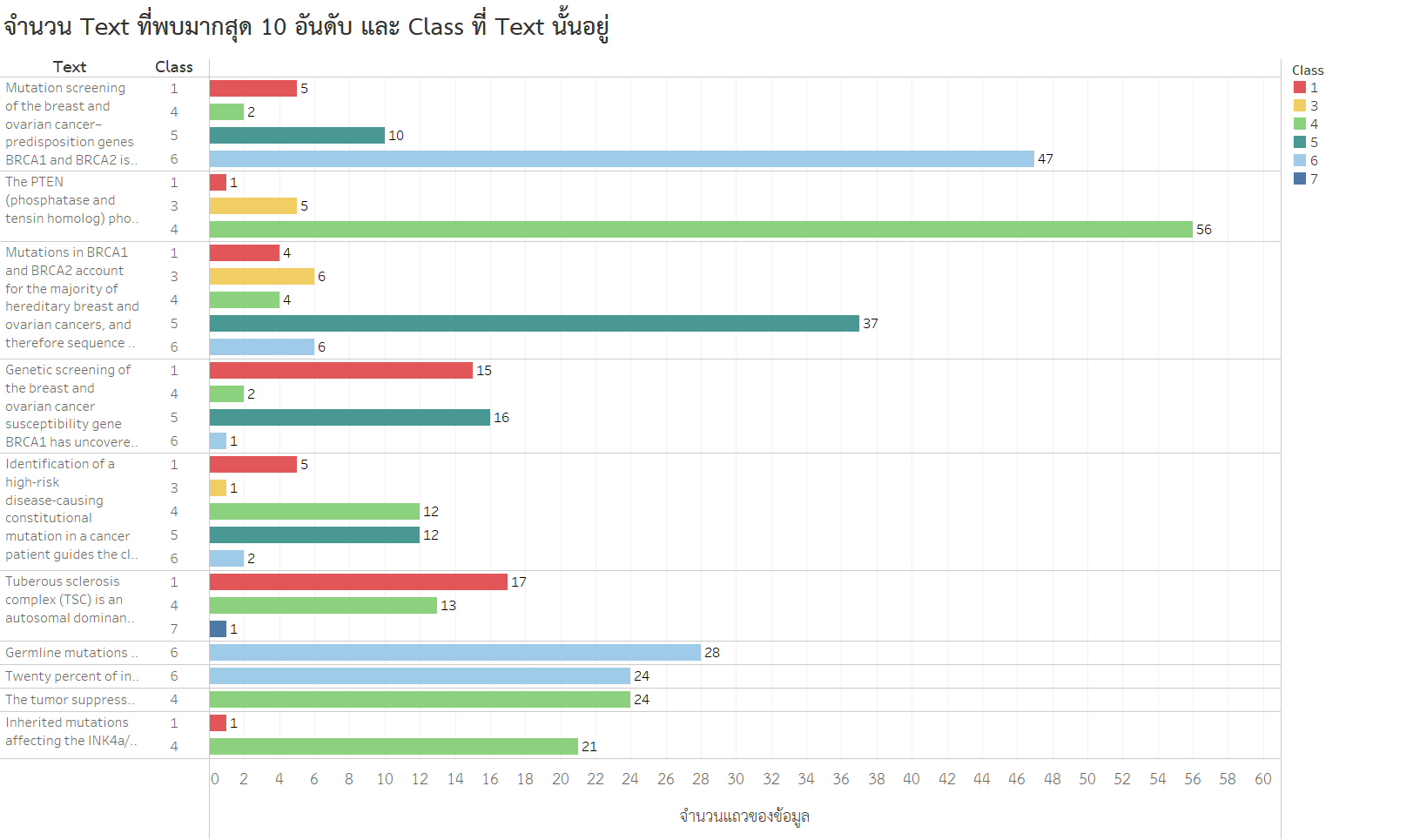
จะเห็นว่า Text หลายอันไปปรากฏใน class ที่แตกต่างกัน อย่าง Text อันดับที่ 1 ไปปรากฏใน class ที่ 1, 4, 5 และ 6 เลย

นอกจากนี้ Text อันดับที่ 1 ที่ไปปรากฏใน class ที่ 1, 4, 5 และ 6 มี gene เดียวกันคือ BRCA2 แต่มี Variation ที่แตกต่างกัน (ภาพอาจดูยากหน่อยนะคะ)
- สรุปสิ่งที่ได้จากการทำ EDA
- จำนวนข้อมูลในแต่ละ Class ของข้อมูล train มีไม่เท่ากัน
- ข้อมูลในบาง Class มีจำนวนน้อยเกินไป
- column text ในบาง row เหมือนกันทั้งหมด
- ความหมายของ Class ไม่ชัดเจน
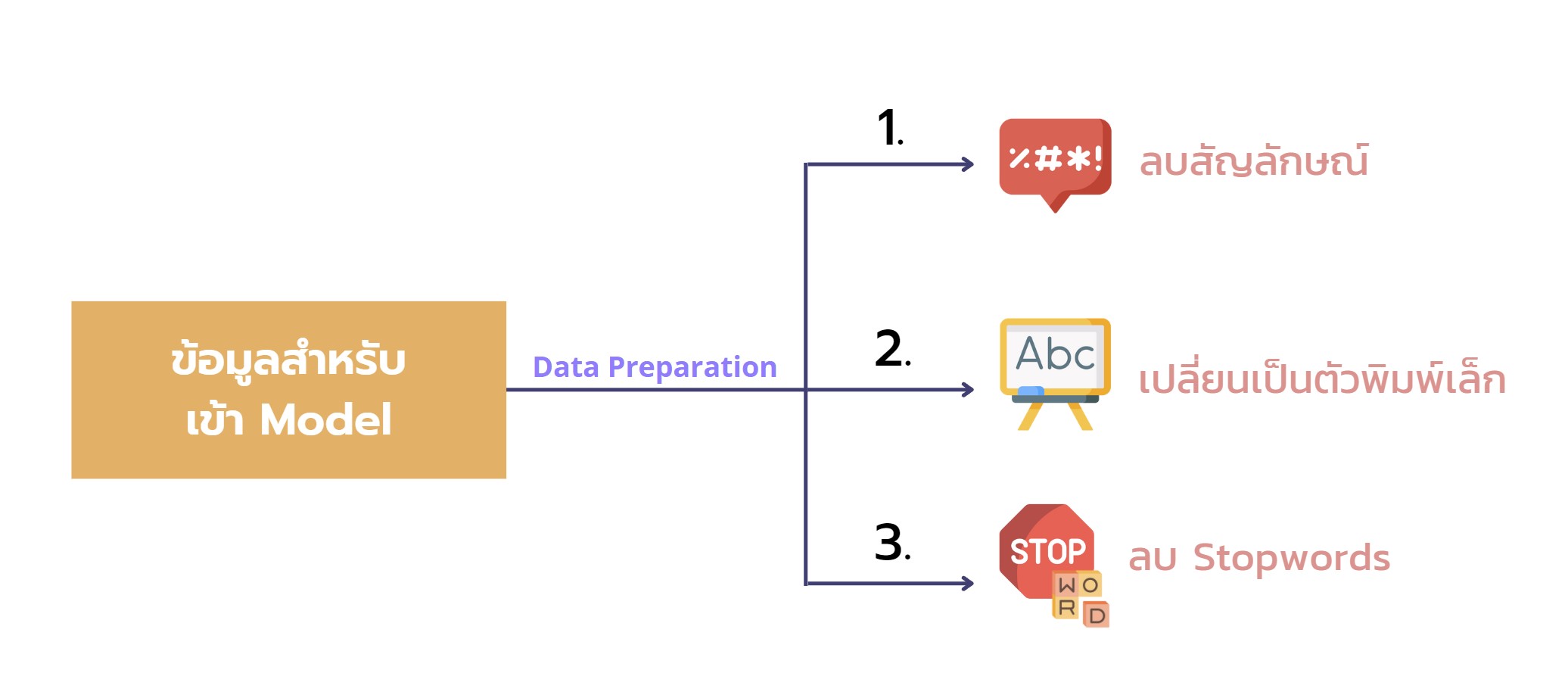
📍note that: รายละเอียดการทำ Data Preparation สามารถดูได้เพิ่มได้ใน Code นะคะ ซึ่งจะมีการจัดการกับ na ในข้อมูล, merge ทั้งสองไฟล์เข้าด้วยกัน, ลบสัญลักษณ์, เปลี่ยนเป็นตัวพิมพ์เล็ก, และลบ Stopwords
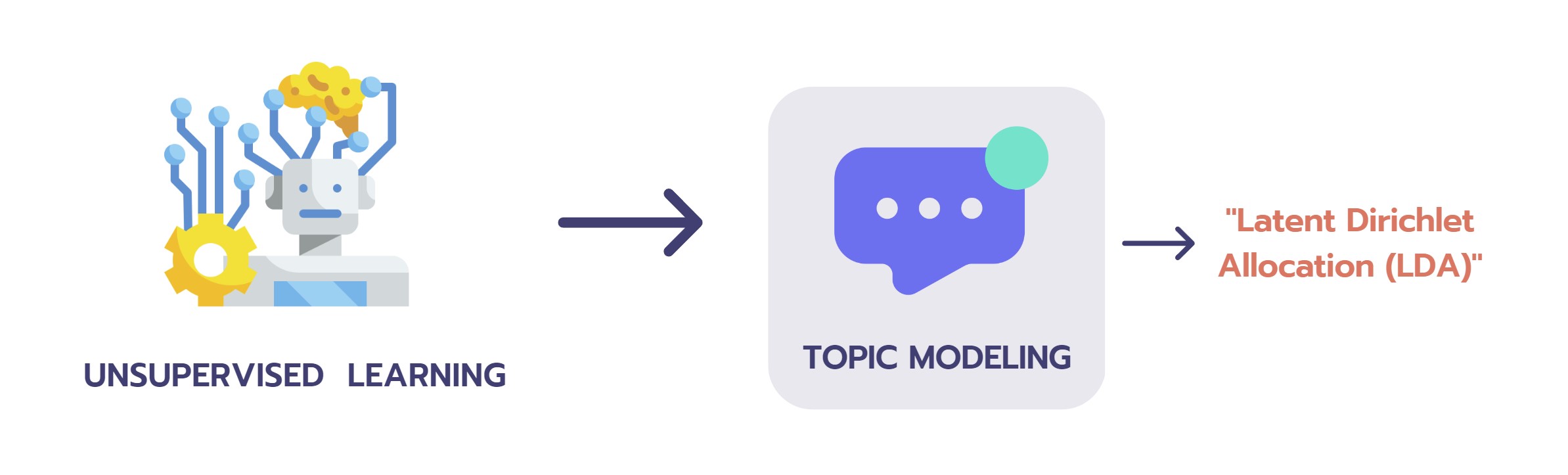
ในการทำ Topic Modeling จะใช้ Latent Dirichlet Allocation (LDA) โดยลักษณะของโมเดลเป็น Unsupervised learning (1)
ผลที่ได้ดังต่อไปนี้พวกเราลองไฮไลท์คำที่น่าสนใจดู เพื่อจะได้สังเกตได้ง่ายกว่าเดิม
- Class ที่ 1

- Class ที่ 2

- Class ที่ 3

- Class ที่ 4

- Class ที่ 5

- Class ที่ 6

- Class ที่ 7

- Class ที่ 8

- Class ที่ 9

จากการทำ Topic Modeling พวกเรา พบว่า
- หลาย ๆ Class มีเนื้อหาที่ใกล้เคียงกัน
- แต่ในบาง Class มีเนื้อหาไปในทิศทางเดียวกัน เช่น Class 9 พูดถึง sf3b1 ชัดเจน และ sf3b1 ก็ไม่ค่อยไปปรากฏใน class อื่น ๆ เลย ต่างกัน brca1 และ brca2 ที่ปรากฏในหลาย class
- ยังต้องอาศัยความรู้ในการตีความ Topic ค่อนข้างมาก
- ด้วยเวลาที่จำกัดทำให้พวกเราไม่สามารถตีความทีละ Topic ได้
สาเหตุที่หลาย ๆ Class มีเนื้อหาที่ใกล้เคียงกันอาจเป็นเพราะ ข้อมูลชุดนี้ไม่สะอาด ซึ่งหมายถึง text ซ้ำกันเยอะมาก ทำให้ไม่สามารถหาความแตกต่างในแต่ละ Class ได้อย่างชัดเจน
จากคำแนะนำของอาจารย์ประจำวิชาและ TA ได้แนะนำเพิ่มเติมว่า การแบ่ง class ของข้อมูลชุดนี้อาจแบ่งตามการรักษา และอยากให้พวกเราทำความเข้าใจข้อมูลให้ละเอียดมากขึ้น อาจลอง Group รวมข้อมูลจะได้วิเคราะห์เห็นอะไรจากข้อมูลมากขึ้น
ในการศึกษาครั้งหน้าพวกเราจึงอยาก
- ทำความเข้าใจข้อมูลให้ละเอียดมากขึ้น เช่น หาหน้าที่และความเกี่ยวข้องกันของ Gene หรือ Variation ในแต่ละ Class
- ลองทำ Wordcloud แยกแต่ละ class
- ลองใช้ grid search กับ LDA
- ลองนำข้อมูลที่ทำ Lemmatisation เข้า model ดู
- ลองใช้ Model อื่น ๆ ในการทำ Topic Modeling
-
ปียวรรณ ทองพลอย. การวิเคราะห์ข้อความภาษาไทยเกี่ยวกับการตั้งครรภ์ด้วยวิธีการสร้างแบบจำลองหัวข้อ (TOPIC MODELING) [อินเทอร์เน็ต]. 2563. [เข้าถึงเมื่อ 22 พ.ย. 65]. เข้าถึงได้จาก: http://ir-ithesis.swu.ac.th/dspace/bitstream/123456789/1243/1/gs621130237.pdf
-
สถาบันวิจัยระบบสาธารณสุข (สวรส.). ยีน BRCA1 และ BRCA2 คืออะไร ? เกี่ยวข้องกับมะเร็งเต้านม อย่างไร ? [อินเทอร์เน็ต]. [เข้าถึงเมื่อ 22 พ.ย. 65]. เข้าถึงได้จาก: https://www.hsri.or.th/people/media/infographic/detail/14120
-
National Library of Medicine. PDGFRA platelet derived growth factor receptor alpha [ Homo sapiens (human) ] [อินเทอร์เน็ต] . [เข้าถึงเมื่อ 22 พ.ย. 65]. เข้าถึงได้จาก: https://www.ncbi.nlm.nih.gov/gene/5156