| author | title | semester | footer | license |
|---|---|---|---|---|
Claire Le Goues and Christian Kaestner |
MLiP: Summary & Reflection |
Spring 2024 |
Machine Learning in Production/AI Engineering • Claire Le Goues & Christian Kaestner, Carnegie Mellon University • Spring 2024 |
Creative Commons Attribution 4.0 International (CC BY 4.0) |
(1)
Looking back at the semester
(400 slides in 40 min)
(2)
Discussion of future of ML in Production
(3)
Feedback for future semesters
- Understand how ML components are parts of larger systems
- Illustrate the challenges in engineering an ML-enabled system beyond accuracy
- Explain the role of specifications and their lack in machine learning and the relationship to deductive and inductive reasoning
- Summarize the respective goals and challenges of software engineers vs data scientists
- Explain the concept and relevance of "T-shaped people"

As a group, think about challenges that the team will likely focus when turning their research into a product:
- One machine-learning challenge
- One engineering challenge in building the product
- One challenge from operating and updating the product
- One team or management challenge
- One business challenge
- One safety or ethics challenge
Post answer to #lecture on Slack and tag all group members


By Steven Geringer, via Ryan Orban. Bridging the Gap Between Data Science & Engineer: Building High-Performance Teams. 2016
Broad-range generalist + Deep expertise

Figure: Jason Yip. Why T-shaped people?. 2018
17-445/17-645/17-745, Fall 2022, 12 units
Monday/Wednesdays 1:25-2:45pm
Recitation Fridays 10:10-11:00am / 1:25-2:45pm

Specification grading, based in adult learning theory
Giving you choices in what to work on or how to prioritize your work
We are making every effort to be clear about expectations (specifications), will clarify if you have questions
Assignments broken down into expectations with point values, each graded pass/fail
Opportunities to resubmit work until last day of class

Note: Source: https://www.aiweirdness.com/do-neural-nets-dream-of-electric-18-03-02/
/**
Return the text spoken within the audio file
????
*/
String transcribe(File audioFile);We routinely build:
- Safe software with unreliable components
- Cyberphysical systems
- Non-ML big data systems, cloud systems
- "Good enough" and "fit for purpose" not "correct"
ML intensifies our challenges

- Understand how ML components are a (small or large) part of a larger system
- Explain how machine learning fits into the larger picture of building and maintaining production systems
- Define system goals and map them to goals for ML components
- Describe the typical components relating to AI in an AI-enabled system and typical design decisions to be made


Focus: building models from given data, evaluating accuracy

Focus: experimenting, deploying, scaling training and serving, model monitoring and updating

Interaction of ML and non-ML components, system requirements, user interactions, safety, collaboration, delivering products

Based on the excellent paper: Passi, S., & Sengers, P. (2020). Making data science systems work. Big Data & Society, 7(2).
Note: Screenshots for illustration purposes, not the actual system studied
- 2012(!) essay lamenting focus on algorithmic improvements and benchmarks
- focus on standard benchmark sets, not engaging with problem: Iris classification, digit recognition, ...
- focus on abstract metrics, not measuring real-world impact: accuracy, ROC
- distant from real-world concerns
- lack of follow-through, no deployment, no impact
- Failure to reproduce and productionize paper contributions common
- Ignoring design choices in how to collect data, what problem to solve, how to design human-AI interface, measuring impact, ...
- Argues: Should focus on making impact -- requires building systems
Wagstaff, Kiri. "Machine learning that matters." In Proceedings of the 29 th International Conference on Machine Learning, (2012).
- Organizational objectives: Innate/overall goals of the organization
- System goals: Goals of the software system/feature to be built
- User outcomes: How well the system is serving its users, from the user's perspective
- Model properties: Quality of the model used in a system, from the model's perspective
- Leading indicators: Short-term proxies for long-term measures, typically for organizational objectives
Ideally, these goals should be aligned with each other

What are different types of goals behind automating admissions decisions to a Master's program?
As a group post answer to #lecture tagging all group members using template:
Organizational goals: ...
Leading indicators: ...
System goals: ...
User goals: ...
Model goals: ...


Automate: Take action on user's behalf
Prompt: Ask the user if an action should be taken
Organize/Annotate/Augment: Add information to a display
Hybrids of these
- Code/models are not unsafe, cannot harm people
- Systems can interact with the environment in ways that are unsafe

In the model
- Ensure maximum toasting time
- Use heat sensor and past outputs for prediction
- Hard to make guarantees
Outside the model (e.g., "guardrails")
- Simple code check for max toasting time
- Non-ML rule to shut down if too hot
- Hardware solution: thermal fuse
 (Image CC BY-SA 4.0, C J Cowie)
(Image CC BY-SA 4.0, C J Cowie)
Design for telemetry


In enterprise ML teams:
- Data scientists often focus on modeling in local environment, model-centric workflow
- Rarely robust infrastructure, often monolithic and tangled
- Challenges in deploying systems and integration with monitoring, streams etc
Shifting to pipeline-centric workflow challenging
- Requires writing robust programs, slower, less exploratory
- Standardized, modular infrastructure
- Big conceptual leap, major hurdle to adoption
O'Leary, Katie, and Makoto Uchida. "Common problems with Creating Machine Learning Pipelines from Existing Code." Proc. Third Conference on Machine Learning and Systems (MLSys) (2020).

- Understand the role of requirements in ML-based systems and their failures
- Understand the distinction between the world and the machine
- Understand the importance of environmental assumptions in establishing system requirements
- Understand the challenges in and techniques for gathering, validating, and negotiating requirements

Q. What went wrong? What is the root cause of the failure?

Q. What went wrong? What is the root cause of the failure?


- Shared phenomena: Interface between the environment & software
- Input: Lidar, camera, pressure sensors, GPS
- Output: Signals generated & sent to the engine or brake control
- Software can influence the environment only through the shared interface
- Unshared parts of the environment are beyond software’s control
- We can only assume how these parts will behave

REQ: The vehicle must be prevented from veering off the lane.
SPEC: Lane detector accurately identifies lane markings in the input image; the controller generates correct steering commands
Discuss with your neighbor to come up with 2-3 assumptions

CC BY-SA 3.0 Anynobody

As a group, post answer to #lecture and tag group members:
Requirement: ...
Assumptions: ...
Specification: ...
What can go wrong: ...
- Customers don't know what they want until they see it
- Customers change their mind ("no, not like that")
- Descriptions are vague
- It is easy to ignore important requirements (privacy, fairness)
- Focused too narrowly on needs of few users
- Engineers think they already know the requirements
- Engineers are overly influenced by technical capability
- Engineers prefer elegant abstractions
Examples?
See also 🗎 Jackson, Michael. "The world and the machine." In Proceedings of the International Conference on Software Engineering. IEEE, 1995.


Note: In a wizard of oz experiment a human fills in for the ML model that is to be developed. For example a human might write the replies in the chatbot.

Dashcam system
- Consider ML models as unreliable components
- Use safety engineering techniques FTA, FMEA, and HAZOP to anticipate and analyze possible mistakes
- Design strategies for mitigating the risks of failures due to ML mistakes



No model is ever "correct"
Some mistakes are unavoidable
Anticipate the eventual mistake
- Make the system safe despite mistakes
- Consider the rest of the system (software + environment)
- Example: Thermal fuse in smart toaster
ML model = unreliable component

- REQ: The train shall not collide with obstacles
- REQ: The train shall not depart until all doors are closed
- REQ: The train shall not trap people between the doors
- ...
Note: The Docklands Light Railway system in London has operated trains without a driver since 1987. Many modern public transportation systems use increasingly sophisticated automation, including the Paris Métro Line 14 and the Copenhagen Metro
- Email response suggestions

- Fall detection smartwatch
- Safe browsing

- Override thermostat setting
- Undo slide design suggestions
- Automated shipment + offering free return shipment
- Appeal process for banned "spammers" or "bots"
- Easy to repair bumpers on autonomous vehicles?
Recall: Thermal fuse in smart toaster
- maximum toasting time + extra heat sensor
Independent mechanism to detect problems (in the real world)
Example: Gyrosensor to detect a train taking a turn too fast

- Goal: When a component failure is detected, achieve system safety by reducing functionality and performance
- Switches operating mode when failure detected (e.g., slower, conservative)

- Combine data from a wide range of sensors
- Provides partial information even when some sensor is faulty
- A critical part of modern self-driving vehicles
What design strategies would you consider to mitigate ML mistakes:
- Credit card fraud detection
- Image captioning for accessibility in photo sharing site
- Speed limiter for cars (with vision system to detect traffic signs)
Consider: Human in the loop, Undoable actions, Guardrails, Mistake detection and recovery (monitoring, doer-checker, fail-over, redundancy), Containment and isolation
As a group, post one design idea for each scenario to #lecture and tag all group members.

Likely? Toby Ord predicts existential risk from GAI at 10% within 100 years: Toby Ord, "The Precipice: Existential Risk and the Future of Humanity", 2020
Note: Discussion on existential risk. Toby Ord, Oxford philosopher predicts
What can possibly go wrong in my system, and what are potential impacts on system requirements?
Risk = Likelihood * Impact
A number of methods:
- Failure mode & effects analysis (FMEA)
- Hazard analysis
- Why-because analysis
- Fault tree analysis (FTA)
- ...

- Remove basic events with mitigations
- Increase the size of cut sets with mitigations

- Select a suitable metric to evaluate prediction accuracy of a model and to compare multiple models
- Select a suitable baseline when evaluating model accuracy
- Know and avoid common pitfalls in evaluating model accuracy
- Explain how software testing differs from measuring prediction accuracy of a model
First Part: Measuring Prediction Accuracy
- the data scientist's perspective
Second Part: What is Correctness Anyway?
- the role and lack of specifications, validation vs verification
Third Part: Learning from Software Testing
- unit testing, test case curation, invariants, simulation (next lecture)
Later: Testing in Production
- monitoring, A/B testing, canary releases (in 2 weeks)
| Actually Grade 5 Cancer | Actually Grade 3 Cancer | Actually Benign | |
|---|---|---|---|
| Model predicts Grade 5 Cancer | 10 | 6 | 2 |
| Model predicts Grade 3 Cancer | 3 | 24 | 10 |
| Model predicts Benign | 5 | 22 | 82 |
Example's accuracy
=
def accuracy(model, xs, ys):
count = length(xs)
countCorrect = 0
for i in 1..count:
predicted = model(xs[i])
if predicted == ys[i]:
countCorrect += 1
return countCorrect / countMeasurement is the empirical, objective assignment of numbers, according to a rule derived from a model or theory, to attributes of objects or events with the intent of describing them. – Craner, Bond, “Software Engineering Metrics: What Do They Measure and How Do We Know?"
A quantitatively expressed reduction of uncertainty based on one or more observations. – Hubbard, “How to Measure Anything …"
Make measurement clear and unambiguous. Ideally, third party can measure independently based on description.
Three steps:
- Measure: What do we try to capture?
- Data collection: What data is collected and how?
- Operationalization: How is the measure computed from the data?
(Possible to repeat recursively when composing measures)


Notes: Widely shared story, authenticity not clear: AI research team tried to train image recognition to identify tanks hidden in forests, trained on images of tanks in forests and images of same or similar forests without tanks. The model could clearly separate the learned pictures, but would perform poorly on other pictures.
Turns out the pictures with tanks were taken on a sunny day whereas the other pictures were taken on a cloudy day. The model picked up on the brightness of the picture rather than the presence of a tank, which worked great for the training set, but did not generalize.
Pictures: https://pixabay.com/photos/lost-places-panzer-wreck-metal-3907364/, https://pixabay.com/photos/forest-dark-woods-trail-path-1031022/
Often neither training nor test data representative of production data


Figure from: Geirhos, Robert, et al. "Shortcut learning in deep neural networks." Nature Machine Intelligence 2, no. 11 (2020): 665-673.
Note: (From figure caption) Toy example of shortcut learning in neural networks. When trained on a simple dataset of stars and moons (top row), a standard neural network (three layers, fully connected) can easily categorise novel similar exemplars (mathematically termed i.i.d. test set, defined later in Section 3). However, testing it on a slightly different dataset (o.o.d. test set, bottom row) reveals a shortcut strategy: The network has learned to associate object location with a category. During training, stars were always shown in the top right or bottom left of an image; moons in the top left or bottom right. This pattern is still present in samples from the i.i.d. test set (middle row) but not in o.o.d. test images (bottom row), exposing the shortcut.
wordsVectorizer = CountVectorizer().fit(text)
wordsVector = wordsVectorizer.transform(text)
invTransformer = TfidfTransformer().fit(wordsVector)
invFreqOfWords = invTransformer.transform(wordsVector)
X = pd.DataFrame(invFreqOfWords.toarray())
train, test, spamLabelTrain, spamLabelTest =
train_test_split(X, y, test_size = 0.5)
predictAndReport(train = train, test = test)specifications, bugs, fit
Given a specification, do outputs match inputs?
/**
* compute deductions based on provided adjusted
* gross income and expenses in customer data.
*
* see tax code 26 U.S. Code A.1.B, PART VI
*/
float computeDeductions(float agi, Expenses expenses);Each mismatch is considered a bug, should to be fixed.†


Use ML precisely because no specifications (too complex, rules unknown)
- No specification that could tell us for any input whether the output is correct
- Intuitions, ideas, goals, examples, "implicit specifications", but nothing we can write down as rules!
- We are usually okay with some wrong predictions
// detects cancer in an image
boolean hasCancer(Image scan);
@Test
void testPatient1() {
assertEquals(loadImage("patient1.jpg"), false);
}
@Test
void testPatient2() {
assertEquals(loadImage("patient2.jpg"), false);
}All models are approximations. Assumptions, whether implied or clearly stated, are never exactly true. All models are wrong, but some models are useful. So the question you need to ask is not "Is the model true?" (it never is) but "Is the model good enough for this particular application?" -- George Box
See also https://en.wikipedia.org/wiki/All_models_are_wrong

(Daniel Miessler, CC SA 2.0)
- A model is learned from given data in given procedure
- The learning process is typically not a correctness concern
- The model itself is generated, typically no implementation issues
- Is the data representative? Sufficient? High quality?
- Does the model "learn" meaningful concepts?
- Is the model useful for a problem? Does it fit?
- Do model predictions usually fit the users' expectations?
- Is the model consistent with other requirements? (e.g., fairness, robustness)
- Find your team number
- Find a seat in the range for your team
- Introduce yourself to the other team members
- Move to table with your team number
- Say hi, introduce yourself: Name? SE or ML background? Favorite movie? Fun fact?
- Find time for first team meeting in next few days
- Agree on primary communication until team meeting
- Pick a movie-related team name, post team name and tag all group members on slack in
#social
- Projects too large to build for a single person (division of work)
- Projects too large to fully comprehend by a single person (divide and conquer)
- Projects need too many skills for a single person to master (division of expertise)



- "M. was very pleasant and would contribute while in meetings. Outside of them, he did not complete the work he said he would and did not reach out to provide an update that he was unable to. When asked, on the night the assignment was due, he completed a portion of the task he said he would after I had completed the rest of it."
- "Procrastinated with the work till the last minute - otherwise ok."
- "He is not doing his work on time. And didnt check his own responsibilities. Left work undone for the next time."
- "D. failed to catch the latest 2 meetings. Along the commit history, he merely committed 4 and the 3 earliest commits are some setups. And the latest one commits is to add his name on the meeting log, for which we almost finished when he joined."
- "Unprepared with his deliverables, very unresponsive on WhatsApp recently, and just overall being a bad team player."
- "Consistently failed to meet deadlines. Communication improved over the course of the milestone but needed repeated prompts to get things done. Did not ask for help despite multiple offers."
- Priority differences ("10-601 is killing me, I need to work on that first", "I have dance class tonight")
- Ambition differences ("a B- is enough for graduating")
- Ability differences ("incompetent" students on teams)
- Working style differences (deadline driven vs planner)
- Communication preferences differences (avoid distraction vs always on)
- In-team competition around grades (outdoing each other, adversarial peer grading)
Based on research and years of own experience
One team member has very little technical experience and is struggling with basic Python scripts and the Unix shell. It is faster for other team members to take over the task rather than helping them.
Pick one or two of the scenarios (or another one team member faced in the past) and openly discuss proactive/reactive solutions
As a team, tagging team members, post to #lecture:
- Brief problem description
- How to prevent in the first place
- What to do when it occurs anyway
Teams can set their own priorities and policies – do what works for you, experiment
- Not everybody will contribute equally to every assignment – that's okay
- Team members have different strength and weaknesses – that's good
We will intervene in team citizenship issues!
Golden rule: Try to do what you agreed to do by the time you agreed to. If you cannot, seek help and communicate clearly and early.
(Model building, model comparison, measurements, first deployment, teamwork documents)
(Slicing, Capabilities, Invariants, Simulation, ...)
- Curate validation datasets for assessing model quality, covering subpopulations and capabilities as needed
- Explain the oracle problem and how it challenges testing of software and models
- Use invariants to check partial model properties with automated testing
- Select and deploy automated infrastructure to evaluate and monitor model quality

Opportunistic/exploratory testing: Add some unit tests, without much planning
Specification-based testing ("black box"): Derive test cases from specifications
- Boundary value analysis
- Equivalence classes
- Combinatorial testing
- Random testing
Structural testing ("white box"): Derive test cases to cover implementation paths
- Line coverage, branch coverage
- Control-flow, data-flow testing, MCDC, ...
Test execution usually automated, but can be manual too; automated generation from specifications or code possible

"Call mom" "What's the weather tomorrow?" "Add asafetida to my shopping list"

Input divided by movie age. Notice low accuracy, but also low support (i.e., little validation data), for old movies.

Input divided by genre, rating, and length. Accuracy differs, but also amount of test data used ("support") differs, highlighting low confidence areas.
Source: Barash, Guy, et al. "Bridging the gap between ML solutions and their business requirements using feature interactions." In Proc. FSE, 2019.

Further reading: Christian Kaestner. Rediscovering Unit Testing: Testing Capabilities of ML Models. Toward Data Science, 2021.

From: Ribeiro, Marco Tulio, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. "Beyond Accuracy: Behavioral Testing of NLP Models with CheckList." In Proceedings ACL, p. 4902–4912. (2020).
Idea 1: Domain-specific generators
Testing negation in sentiment analysis with template:
I {NEGATION} {POS_VERB} the {THING}.
Testing texture vs shape priority with artificial generated images:

Figure from Geirhos, Robert, Patricia Rubisch, Claudio Michaelis, Matthias Bethge, Felix A. Wichmann, and Wieland Brendel. “ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness.” In Proc. International Conference on Learning Representations (ICLR), (2019).
Idea 3: Crowd-sourcing test creation
Testing sarcasm in sentiment analysis: Ask humans to minimally change text to flip sentiment with sarcasm
Testing background in object detection: Ask humans to take pictures of specific objects with unusual backgrounds

Figure from: Kaushik, Divyansh, Eduard Hovy, and Zachary C. Lipton. “Learning the difference that makes a difference with counterfactually-augmented data.” In Proc. International Conference on Learning Representations (ICLR), (2020).
(if it wasn't for that darn oracle problem)


How do we know the expected output of a test?
assertEquals(??, factorPrime(15485863));- Credit rating should not depend on gender:
$\forall x. f(x[\text{gender} \leftarrow \text{male}]) = f(x[\text{gender} \leftarrow \text{female}])$
- Synonyms should not change the sentiment of text:
$\forall x. f(x) = f(\texttt{replace}(x, \text{"is not", "isn't"}))$
- Negation should swap meaning:
$\forall x \in \text{"X is Y"}. f(x) = 1-f(\texttt{replace}(x, \text{" is ", " is not "}))$
- Robustness around training data:
$\forall x \in \text{training data}. \forall y \in \text{mutate}(x, \delta). f(x) = f(y)$
- Low credit scores should never get a loan (sufficient conditions for classification, "anchors"):
$\forall x. x.\text{score} < 649 \Rightarrow \neg f(x)$
Identifying invariants requires domain knowledge of the problem!



- Describe the role of architecture and design between requirements and implementation
- Identify the different ML components and organize and prioritize their quality concerns for a given project
- Explain they key ideas behind decision trees and random forests and analyze consequences for various qualities
- Demonstrate an understanding of the key ideas of deep learning and how it drives qualities
- Plan and execute an evaluation of the qualities of alternative AI components for a given purpose
- ML components for transcription model, pipeline to train the model, monitoring infrastructure...
- Non-ML components for data storage, user interface, payment processing, ...
- User requirements and assumptions
- System quality vs model quality
- System requirements vs model requirements


Note: Source and additional reading: Raffi. New Tweets per second record, and how! Twitter Blog, 2013
Architectural decisions affect entire systems, not only individual modules
Abstract, different abstractions for different scenarios
Reason about quality attributes early
Make architectural decisions explicit
Question: Did the original architect make poor decisions?
Identify components and their responsibilities
Establishes interfaces and team boundaries
Decomposition enables scaling teams
Each team works on a component
Need to coordinate on interfaces, but implementations remain hidden
Interface descriptions are crutial
- Who is responsible for what
- Component requirements (specifications), behavioral and quality
- Especially consider nonlocal qualities: e.g., safety, privacy
Interfaces rarely fully specified in practice, source of conflicts
- Model inference service: Uses model to make predictions for input data
- ML pipeline: Infrastructure to train/update the model
- Monitoring: Observe model and system
- Data sources: Manual/crowdsourcing/logs/telemetry/...
- Data management: Storage and processing of data, often at scale
- Feature store: Reusable feature engineering code, cached feature computations
Separating concerns, understanding interdependencies
- e.g., anticipating/breaking feedback loops, conflicting needs of components
Facilitating experimentation, updates with confidence
Separating training and inference and closing the loop
- e.g., collecting telemetry to learn from user interactions
Learn, serve, and observe at scale or with resource limits
- e.g., cloud deployment, embedded devices
Scenario: Component for detecting credit card frauds, as a service for banks

Note: Very high volume of transactions, low cost per transaction, frequent updates
Incrementality
| Consumption | CO2 (lbs) |
|---|---|
| Air travel, 1 passenger, NY↔SF | 1984 |
| Human life, avg, 1 year | 11,023 |
| American life, avg, 1 year | 36,156 |
| Car, avg incl. fuel, 1 lifetime | 126,000 |
| Training one model (GPU) | CO2 (lbs) |
|---|---|
| NLP pipeline (parsing, SRL) | 39 |
| w/ tuning & experimentation | 78,468 |
| Transformer (big) | 192 |
| w/ neural architecture search | 626,155 |
Strubell, Emma, Ananya Ganesh, and Andrew McCallum. "Energy and Policy Considerations for Deep Learning in NLP." In Proc. ACL, pp. 3645-3650. 2019.
Constraints define the space of attributes for valid design solutions

Note: Design space exploration: The space of all possible designs (dotted rectangle) is reduced by several constraints on qualities of the system, leaving only a subset of designs for further consideration (highlighted center area).

"We evaluated some of the new methods offline but the additional accuracy gains that we measured did not seem to justify the engineering effort needed to bring them into a production environment.”
Amatriain & Basilico. Netflix Recommendations: Beyond the 5 stars, Netflix Technology Blog (2012)
Consider two scenarios:
- Credit card fraud detection
- Pedestrian detection in sidewalk robot
As a group, post to #lecture tagging all group members:
- Qualities of interests: ??
- Constraints: ??
- ML algorithm(s) to use: ??
- Understand important quality considerations when deploying ML components
- Follow a design process to explicitly reason about alternative designs and their quality tradeoffs
- Gather data to make informed decisions about what ML technique to use and where and how to deploy it
- Understand the power of design patterns for codifying design knowledge
- Create architectural models to reason about relevant characteristics
- Critique the decision of where an AI model lives (e.g., cloud vs edge vs hybrid), considering the relevant tradeoffs
- Deploy models locally and to the cloud
- Document model inference services
Model inference component as a service
from flask import Flask, escape, request
app = Flask(__name__)
app.config['UPLOAD_FOLDER'] = '/tmp/uploads'
detector_model = … # load model…
# inference API that returns JSON with classes
# found in an image
@app.route('/get_objects', methods=['POST'])
def pred():
uploaded_img = request.files["images"]
coverted_img = … # feature encoding of uploaded img
result = detector_model(converted_img)
return jsonify({"response":
result['detection_class_entities']})Offline use?
Deployment at scale?
Hardware needs and operating cost?
Frequent updates?
Integration of the model into a system?
Meeting system requirements?
Every system is different!
 Notes: Cycling map of Pittsburgh. Abstraction for navigation with bikes and walking.
Notes: Cycling map of Pittsburgh. Abstraction for navigation with bikes and walking.

Peng, Zi, Jinqiu Yang, Tse-Hsun Chen, and Lei Ma. "A first look at the integration of machine learning models in complex autonomous driving systems: a case study on Apollo." In Proc. FSE, 2020.

Notes: Consider you want to implement an instant translation service similar toGoogle translate, but run it on embedded hardware in glasses as an augmented reality service.

Cloud? Phone? Glasses?
What qualities are relevant for the decision?
Notes: Trigger initial discussion
- Estimate latency and bandwidth requirements between components
- Discuss tradeoffs among different deployment models
As a group, post in #lecture tagging group members:
- Recommended deployment for OCR (with justification):
- Recommended deployment for Translation (with justification):
Notes: Identify at least OCR and Translation service as two AI components in a larger system. Discuss which system components are worth modeling (e.g., rendering, database, support forum). Discuss how to get good estimates for latency and bandwidth.
Some data: 200ms latency is noticable as speech pause; 20ms is perceivable as video delay, 10ms as haptic delay; 5ms referenced as cybersickness threshold for virtual reality 20ms latency might be acceptable
bluetooth latency around 40ms to 200ms
bluetooth bandwidth up to 3mbit, wifi 54mbit, video stream depending on quality 4 to 10mbit for low to medium quality
google glasses had 5 megapixel camera, 640x360 pixel screen, 1 or 2gb ram, 16gb storage

Avoid training–serving skew
<iframe width="1200" height="600" src="https://www.youtube.com/embed/u_L_V2HQ_nQ" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>

Based on: Yokoyama, Haruki. "Machine learning system architectural pattern for improving operational stability." In Int'l Conf. Software Architecture Companion, pp. 267-274. IEEE, 2019.
{
"mid": string,
"languageCode": string,
"name": string,
"score": number,
"boundingPoly": {
object (BoundingPoly)
}
}From Google’s public object detection API.
- Big Ass Script Architecture
- Dead Experimental Code Paths
- Glue code
- Multiple Language Smell
- Pipeline Jungles
- Plain-Old Datatype Smell
- Undeclared Consumers
See also: Washizaki, Hironori, Hiromu Uchida, Foutse Khomh, and Yann-Gaël Guéhéneuc. "Machine Learning Architecture and Design Patterns." Draft, 2019; 🗎 Sculley, et al. "Hidden technical debt in machine learning systems." In NeurIPS, 2015.
- Design telemetry for evaluation in practice
- Understand the rationale for beta tests and chaos experiments
- Plan and execute experiments (chaos, A/B, shadow releases, ...) in production
- Conduct and evaluate multiple concurrent A/B tests in a system
- Perform canary releases
- Examine experimental results with statistical rigor
- Support data scientists with monitoring platforms providing insights from production data

Note: Early release to select users, asking them to send feedback or report issues. No telemetry in early days.

Note: With internet availability, send crash reports home to identify problems "in production". Most ML-based systems are online in some form and allow telemetry.

Notes: Usage observable online, telemetry allows testing in production. Picture source: https://www.designforfounders.com/ab-testing-examples/


Notes: Expect only sparse feedback and expect negative feedback over-proportionally

Notes: Can just wait 7 days to see actual outcome for all predictions
- Usual 3 steps: (1) Metric, (2) data collection (telemetry), (3) operationalization
- Telemetry can provide insights for correctness
- sometimes very accurate labels for real unseen data
- sometimes only mistakes
- sometimes delayed
- often just samples
- often just weak proxies for correctness
- Often sufficient to approximate precision/recall or other model-quality measures
- Mismatch to (static) evaluation set may indicate stale or unrepresentative data
- Trend analysis can provide insights even for inaccurate proxy measures
Discuss how to collect telemetry, the metric to monitor, and how to operationalize
Scenarios:
- Front-left: Amazon: Shopping app detects the shoe brand from photos
- Front-right: Google: Tagging uploaded photos with friends' names
- Back-left: Spotify: Recommended personalized playlists
- Back-right: Wordpress: Profanity filter to moderate blog posts
As a group post to #lecture and tag team members:
- Quality metric:
- Data to collect:
- Operationalization:


Image source: Joel Thomas and Clemens Mewald. Productionizing Machine Learning: From Deployment to Drift Detection. Databricks Blog, 2019


Bernardi, Lucas, et al. "150 successful machine learning models: 6 lessons learned at Booking.com." In Proc. Int'l Conf. Knowledge Discovery & Data Mining, 2019.

- Experiment: Ad Display at Bing
- Suggestion prioritzed low
- Not implemented for 6 month
- Ran A/B test in production
- Within 2h revenue-too-high alarm triggered suggesting serious bug (e.g., double billing)
- Revenue increase by 12% - $100M anually in US
- Did not hurt user-experience metrics
From: Kohavi, Ron, Diane Tang, and Ya Xu. "Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing." 2020.
if (features.enabled(userId, "one_click_checkout")) {
// new one click checkout function
} else {
// old checkout functionality
}- Good practices: tracked explicitly, documented, keep them localized and independent
- External mapping of flags to customers, who should see what configuration
- e.g., 1% of users sees
one_click_checkout, but always the same users; or 50% of beta-users and 90% of developers and 0.1% of all users
- e.g., 1% of users sees
def isEnabled(user): Boolean = (hash(user.id) % 100) < 10
Source: https://conversionsciences.com/ab-testing-statistics/
Release new version to small percentage of population (like A/B testing)
Automatically roll back if quality measures degrade
Automatically and incrementally increase deployment to 100% otherwise


- Distinguish precision and accuracy; understanding the better models vs more data tradeoffs
- Use schema languages to enforce data schemas
- Design and implement automated quality assurance steps that check data schema conformance and distributions
- Devise infrastructure for detecting data drift and schema violations
- Consider data quality as part of a system; design an organization that values data quality
Data cleaning and repairing account for about 60% of the work of data scientists.
Own experience?
Quote: Gil Press. “Cleaning Big Data: Most Time-Consuming, Least Enjoyable Data Science Task, Survey Says.” Forbes Magazine, 2016.

<style>#mermaid1 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid1 .error-icon{fill:#552222;}#mermaid1 .error-text{fill:#552222;stroke:#552222;}#mermaid1 .edge-thickness-normal{stroke-width:2px;}#mermaid1 .edge-thickness-thick{stroke-width:3.5px;}#mermaid1 .edge-pattern-solid{stroke-dasharray:0;}#mermaid1 .edge-pattern-dashed{stroke-dasharray:3;}#mermaid1 .edge-pattern-dotted{stroke-dasharray:2;}#mermaid1 .marker{fill:#333333;stroke:#333333;}#mermaid1 .marker.cross{stroke:#333333;}#mermaid1 svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid1 .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid1 .cluster-label text{fill:#333;}#mermaid1 .cluster-label span{color:#333;}#mermaid1 .label text,#mermaid1 span{fill:#333;color:#333;}#mermaid1 .node rect,#mermaid1 .node circle,#mermaid1 .node ellipse,#mermaid1 .node polygon,#mermaid1 .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid1 .node .label{text-align:center;}#mermaid1 .node.clickable{cursor:pointer;}#mermaid1 .arrowheadPath{fill:#333333;}#mermaid1 .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid1 .flowchart-link{stroke:#333333;fill:none;}#mermaid1 .edgeLabel{background-color:#e8e8e8;text-align:center;}#mermaid1 .edgeLabel rect{opacity:0.5;background-color:#e8e8e8;fill:#e8e8e8;}#mermaid1 .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid1 .cluster text{fill:#333;}#mermaid1 .cluster span{color:#333;}#mermaid1 div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid1 :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;}</style>
sources of different reliability and quality

Recommended Reading: Gitelman, Lisa, Virginia Jackson, Daniel Rosenberg, Travis D. Williams, Kevin R. Brine, Mary Poovey, Matthew Stanley et al. "Data bite man: The work of sustaining a long-term study." In "Raw Data" Is an Oxymoron, (2013), MIT Press: 147-166.
Accuracy: Reported values (on average) represent real value
Precision: Repeated measurements yield the same result
Accurate, but imprecise: Average over multiple measurements
Inaccurate, but precise: ?

(CC-BY-4.0 by Arbeck)

Detection almost always delayed! Expensive rework. Difficult to detect in offline evaluation.
Sambasivan, N., et al. (2021, May). “Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI. In Proc. CHI (pp. 1-15).
CREATE TABLE employees (
emp_no INT NOT NULL,
birth_date DATE NOT NULL,
name VARCHAR(30) NOT NULL,
PRIMARY KEY (emp_no));
CREATE TABLE departments (
dept_no CHAR(4) NOT NULL,
dept_name VARCHAR(40) NOT NULL,
PRIMARY KEY (dept_no), UNIQUE KEY (dept_name));
CREATE TABLE dept_manager (
dept_no CHAR(4) NOT NULL,
emp_no INT NOT NULL,
FOREIGN KEY (emp_no) REFERENCES employees (emp_no),
FOREIGN KEY (dept_no) REFERENCES departments (dept_no),
PRIMARY KEY (emp_no,dept_no)); 
- User provides rules as integrity constraints (e.g., "two entries with the same name can't have different city")
- Detect violations of the rules in the data; also detect statistical outliers
- Automatically generate repair candidates (with probabilities)
Image source: Theo Rekatsinas, Ihab Ilyas, and Chris Ré, “HoloClean - Weakly Supervised Data Repairing.” Blog, 2017.
Concept drift (or concept shift)
- properties to predict change over time (e.g., what is credit card fraud)
- model has not learned the relevant concepts
- over time: different expected outputs for same inputs
Data drift (or covariate shift, distribution shift, or population drift)
- characteristics of input data changes (e.g., customers with face masks)
- input data differs from training data
- over time: predictions less confident, further from training data
Upstream data changes
- external changes in data pipeline (e.g., format changes in weather service)
- model interprets input data incorrectly
- over time: abrupt changes due to faulty inputs
How do we fix these drifts?
What kind of drift might be expected?
As a group, tagging members, write plausible examples in #lecture:
- Concept Drift:
- Data Drift:
- Upstream data changes:

Image source and further readings: Detect data drift (preview) on models deployed to Azure Kubernetes Service (AKS)
"Everyone wants to do the model work, not the data work"
Sambasivan, N., Kapania, S., Highfill, H., Akrong, D., Paritosh, P., & Aroyo, L. M. (2021, May). “Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (pp. 1-15).
Teams rarely document expectations of data quantity or quality
Data quality tests are rare, but some teams adopt defensive monitoring
- Local tests about assumed structure and distribution of data
- Identify drift early and reach out to producing teams
Several ideas for documenting distributions, including Datasheets and Dataset Nutrition Label
- Mostly focused on static datasets, describing origin, consideration, labeling procedure, and distributions; Example
🗎 Gebru, Timnit, et al. "Datasheets for datasets." Communications of the ACM 64, no. 12 (2021).
🗎 Nahar, Nadia, et al. “Collaboration Challenges in Building ML-Enabled Systems: Communication, Documentation, Engineering, and Process.” In Pro. ICSE, 2022.
- Decompose an ML pipeline into testable functions
- Implement and automate tests for all parts of the ML pipeline
- Understand testing opportunities beyond functional correctness
- Describe the different testing levels and testing opportunities at each level
- Automate test execution with continuous integration
All steps to create (and deploy) the model

Parameterize and use nbconvert?
Danger of "silent" mistakes in many phases
Examples?
def encode_day_of_week(df):
if 'datetime' not in df.columns: raise ValueError("Column datetime missing")
if df.datetime.dtype != 'object': raise ValueError("Invalid type for column datetime")
df['dayofweek']= pd.to_datetime(df['datetime']).dt.day_name()
df = pd.get_dummies(df, columns = ['dayofweek'])
return df
# ...
def prepare_data(df):
df = clean_data(df)
df = encode_day_of_week(df)
df = encode_month(df)
df = encode_weather(df)
df.drop(['datetime'], axis=1, inplace=True)
return (df.drop(['delivery_count'], axis=1),
encode_count(pd.Series(df['delivery_count'])))
def learn(X, y):
lr = LinearRegression()
lr.fit(X, y)
return lr
def pipeline():
train = pd.read_csv('train.csv', parse_dates=True)
test = pd.read_csv('test.csv', parse_dates=True)
X_train, y_train = prepare_data(train)
X_test, y_test = prepare_data(test)
model = learn(X_train, y_train)
accuracy = eval(model, X_test, y_test)
return model, accuracydef encode_day_of_week(df):
if 'datetime' not in df.columns: raise ValueError("Column datetime missing")
if df.datetime.dtype != 'object': raise ValueError("Invalid type for column datetime")
df['dayofweek']= pd.to_datetime(df['datetime']).dt.day_name()
df = pd.get_dummies(df, columns = ['dayofweek'])
return dfdef test_day_of_week_encoding():
df = pd.DataFrame({'datetime': ['2020-01-01','2020-01-02','2020-01-08'], 'delivery_count': [1, 2, 3]})
encoded = encode_day_of_week(df)
assert "dayofweek_Wednesday" in encoded.columns
assert (encoded["dayofweek_Wednesday"] == [1, 0, 1]).all()
# more tests...df['Join_year'] = df.Joined.dropna().map(
lambda x: x.split(',')[1].split(' ')[1])df.loc[idx_nan_age,'Age'].loc[idx_nan_age] =
df['Title'].loc[idx_nan_age].map(map_means)df["Weight"].astype(str).astype(int)Automate all build, analysis, test, and deployment steps from a command line call
Ensure all dependencies and configurations are defined
Ideally reproducible and incremental
Distribute work for large jobs
Track results
Key CI benefit: Tests are regularly executed, part of process

Source: Eric Breck, Shanqing Cai, Eric Nielsen, Michael Salib, D. Sculley. The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction. Proceedings of IEEE Big Data (2017)
<iframe width="90%" height="500" src="https://www.youtube.com/embed/e62ZL3dCQWM?start=42" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
(from S20 midterm; assume cloud or hybrid deployment)

(Mocking frameworks provide infrastructure for expressing such tests compactly.)


Automatic detection of problematic patterns based on code structure
if (user.jobTitle = "manager") {
...
}function fn() {
x = 1;
return x;
x = 3;
}(VisionPro Meditation)
(online and offline evaluation, data quality, pipeline testing, continuous integrations, pull requests)
- Organize different data management solutions and their tradeoffs
- Understand the scalability challenges involved in large-scale machine learning and specifically deep learning
- Explain the tradeoffs between batch processing and stream processing and the lambda architecture
- Recommend and justify a design and corresponding technologies for a given system

Notes:
- Discuss possible architecture and when to predict (and update)
- in may 2017: 500M users, uploading 1.2billion photos per day (14k/sec)
- in Jun 2019 1 billion users
<iframe src="https://giphy.com/embed/3oz8xtBx06mcZWoNJm" width="480" height="362" frameBorder="0" class="giphy-embed" allowFullScreen></iframe>
Stories of catastrophic success?
Distributed data cleaning
Distributed feature extraction
Distributed learning
Distributed large prediction tasks
Incremental predictions
Distributed logging and telemetry

Photos:
| photo_id | user_id | path | upload_date | size | camera_id | camera_setting |
|---|---|---|---|---|---|---|
| 133422131 | 54351 | /st/u211/1U6uFl47Fy.jpg | 2021-12-03T09:18:32.124Z | 5.7 | 663 | ƒ/1.8; 1/120; 4.44mm; ISO271 |
| 133422132 | 13221 | /st/u11b/MFxlL1FY8V.jpg | 2021-12-03T09:18:32.129Z | 3.1 | 1844 | ƒ/2, 1/15, 3.64mm, ISO1250 |
| 133422133 | 54351 | /st/x81/ITzhcSmv9s.jpg | 2021-12-03T09:18:32.131Z | 4.8 | 663 | ƒ/1.8; 1/120; 4.44mm; ISO48 |
Users:
| user_id | account_name | photos_total | last_login |
|---|---|---|---|
| 54351 | ckaestne | 5124 | 2021-12-08T12:27:48.497Z |
| 13221 | eva.burk | 3 | 2021-12-21T01:51:54.713Z |
Cameras:
| camera_id | manufacturer | print_name |
|---|---|---|
| 663 | Google Pixel 5 | |
| 1844 | Motorola | Motorola MotoG3 |
select p.photo_id, p.path, u.photos_total
from photos p, users u
where u.user_id=p.user_id and u.account_name = "ckaestne"{
"_id": 133422131,
"path": "/st/u211/1U6uFl47Fy.jpg",
"upload_date": "2021-12-03T09:18:32.124Z",
"user": {
"account_name": "ckaestne",
"account_id": "a/54351"
},
"size": "5.7",
"camera": {
"manufacturer": "Google",
"print_name": "Google Pixel 5",
"settings": "ƒ/1.8; 1/120; 4.44mm; ISO271"
}
}db.getCollection('photos').find( { "user.account_name": "ckaestne"})02:49:12 127.0.0.1 GET /img13.jpg 200
02:49:35 127.0.0.1 GET /img27.jpg 200
03:52:36 127.0.0.1 GET /main.css 200
04:17:03 127.0.0.1 GET /img13.jpg 200
05:04:54 127.0.0.1 GET /img34.jpg 200
05:38:07 127.0.0.1 GET /img27.jpg 200
05:44:24 127.0.0.1 GET /img13.jpg 200
06:08:19 127.0.0.1 GET /img13.jpg 200
Divide data:
- Horizontal partitioning: Different rows in different tables; e.g., movies by decade, hashing often used
- Vertical partitioning: Different columns in different tables; e.g., movie title vs. all actors
Tradeoffs?



Figure based on Christopher Meiklejohn. Dynamic Reduction: Optimizing Service-level Fault Injection Testing With Service Encapsulation. Blog Post 2021

Moving Computation is Cheaper than Moving Data -- Hadoop Documentation
Data often large and distributed, code small
Avoid transfering large amounts of data
Perform computation where data is stored (distributed)
Transfer only results as needed
"The map reduce way"

Like shell programs: Read from stream, produce output in other stream. -> loose coupling

- Append only databases
- Record edit events, never mutate data
- Compute current state from all past events, can reconstruct old state
- For efficiency, take state snapshots
- Similar to traditional database logs, but persistent
addPhoto(id=133422131, user=54351, path="/st/u211/1U6uFl47Fy.jpg", date="2021-12-03T09:18:32.124Z")
updatePhotoData(id=133422131, user=54351, title="Sunset")
replacePhoto(id=133422131, user=54351, path="/st/x594/vipxBMFlLF.jpg", operation="/filter/palma")
deletePhoto(id=133422131, user=54351)

- Learn accurate model in batch job
- Learn incremental model in stream processor
Trend to store all events in raw form (no consistent schema)
May be useful later
Data storage is comparably cheap
Bet: Yet unknown future value of data is greater than storage costs
As a group, discuss and post in #lecture, tagging group members:
- How to distribute storage:
- How to design scalable copy-right protection solution:
- How to design scalable analytics (views, ratings, ...):

- Deploy a service for models using container infrastructure
- Automate common configuration management tasks
- Devise a monitoring strategy and suggest suitable components for implementing it
- Diagnose common operations problems
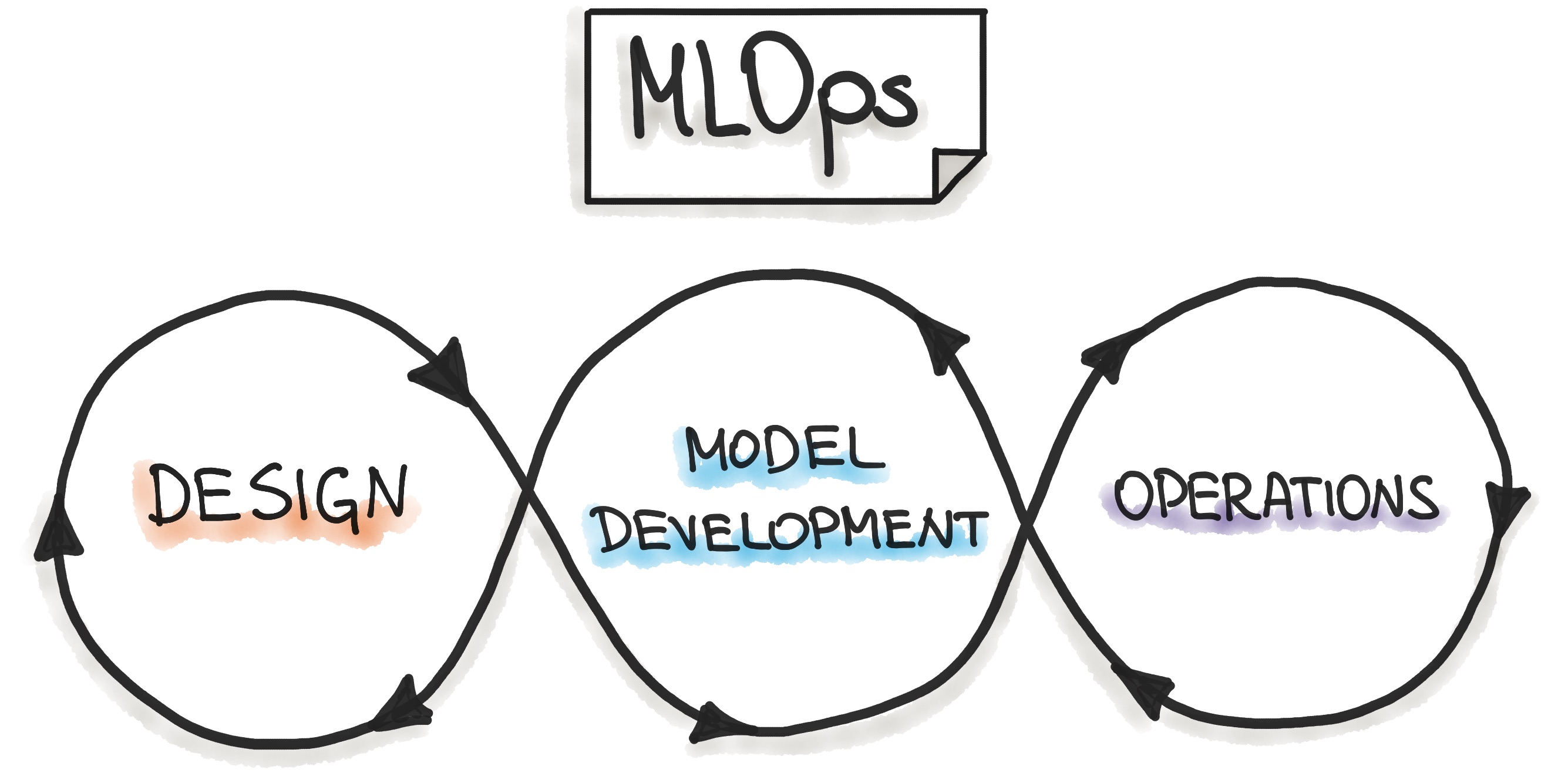
- Understand the typical concerns and concepts of MLOps
Provision and monitor the system in production, respond to problems
Avoid downtime, scale with users, manage operating costs
Heavy focus on infrastructure
Traditionally sysadmin and hardware skills

Quality requirements in operations, such as
- maximum latency
- minimum system throughput
- targeted availability/error rate
- time to deploy an update
- durability for storage
Each with typical measures
For the system as a whole or individual services

- Missing dependencies
- Different compiler versions or library versions
- Different local utilities (e.g. unix grep vs mac grep)
- Database problems
- OS differences
- Too slow in real settings
- Difficult to roll back changes
- Source from many different repositories
- Obscure hardware? Cloud? Enough memory?

All configurations in version control
Test and deploy in containers
Automated testing, testing, testing, ...
Monitoring, orchestration, and automated actions in practice
Microservice architectures
Release frequently


- Lightweight virtual machine
- Contains entire runnable software, incl. all dependencies and configurations
- Used in development and production
- Sub-second launch time
- Explicit control over shared disks and network connections
![]()

CC BY-SA 4.0 Khtan66
- Consider the entire process and tool chain holistically
- Automation, automation, automation
- Elastic infrastructure
- Document, test, and version everything
- Iterate and release frequently
- Emphasize observability
- Shared goals and responsibilities
- Model registry, versioning and metadata: MLFlow, Neptune, ModelDB, WandB, ...
- Model monitoring: Fiddler, Hydrosphere
- Data pipeline automation and workflows: DVC, Kubeflow, Airflow
- Model packaging and deployment: BentoML, Cortex
- Distributed learning and deployment: Dask, Ray, ...
- Feature store: Feast, Tecton
- Integrated platforms: Sagemaker, Valohai, ...
- Data validation: Cerberus, Great Expectations, ...
Long list: https://github.com/kelvins/awesome-mlops
For the blog spam filter scenario, consider DevOps and MLOps infrastructure (CI, CD, containers, config. mgmt, monitoring, model registry, pipeline automation, feature store, data validation, ...)
As a group, tagging group members, post to #lecture:
- Which DevOps or MLOps goals to prioritize?
- Which tools to try?
- Provide contact channel for problem reports
- Have expert on call
- Design process for anticipated problems, e.g., rollback, reboot, takedown
- Prepare for recovery
- Proactively collect telemetry
- Investigate incidents
- Plan public communication (responsibilities)

“this is how we always did things”
Implicit and explicit assumptions and rules guiding behavior
Often grounded in history, very difficult to change
Examples:
- Move fast and break things
- Privacy first
- Development opportunities for all employees

Source: Bonkers World
Changing organizational culture is very difficult
Top down: espoused values, management buy in, incentives
Bottom up: activism, show value, spread
Examples of success of failure stories?
- Judge the importance of data provenance, reproducibility and explainability for a given system
- Create documentation for data dependencies and provenance in a given system
- Propose versioning strategies for data and models
- Design and test systems for reproducibility

Assume you are receiving complains that a child gets many recommendations about R-rated movies
In a group, discuss how you could address this in your own system and post to #lecture, tagging team members:
- How could you identify the problematic recommendation(s)?
- How could you identify the model that caused the prediction?
- How could you identify the training code and data that learned the model?
- How could you identify what training data or infrastructure code "caused" the recommendations?
K.G Orphanides. Children's YouTube is still churning out blood, suicide and cannibalism. Wired UK, 2018; Kristie Bertucci. 16 NSFW Movies Streaming on Netflix. Gadget Reviews, 2020
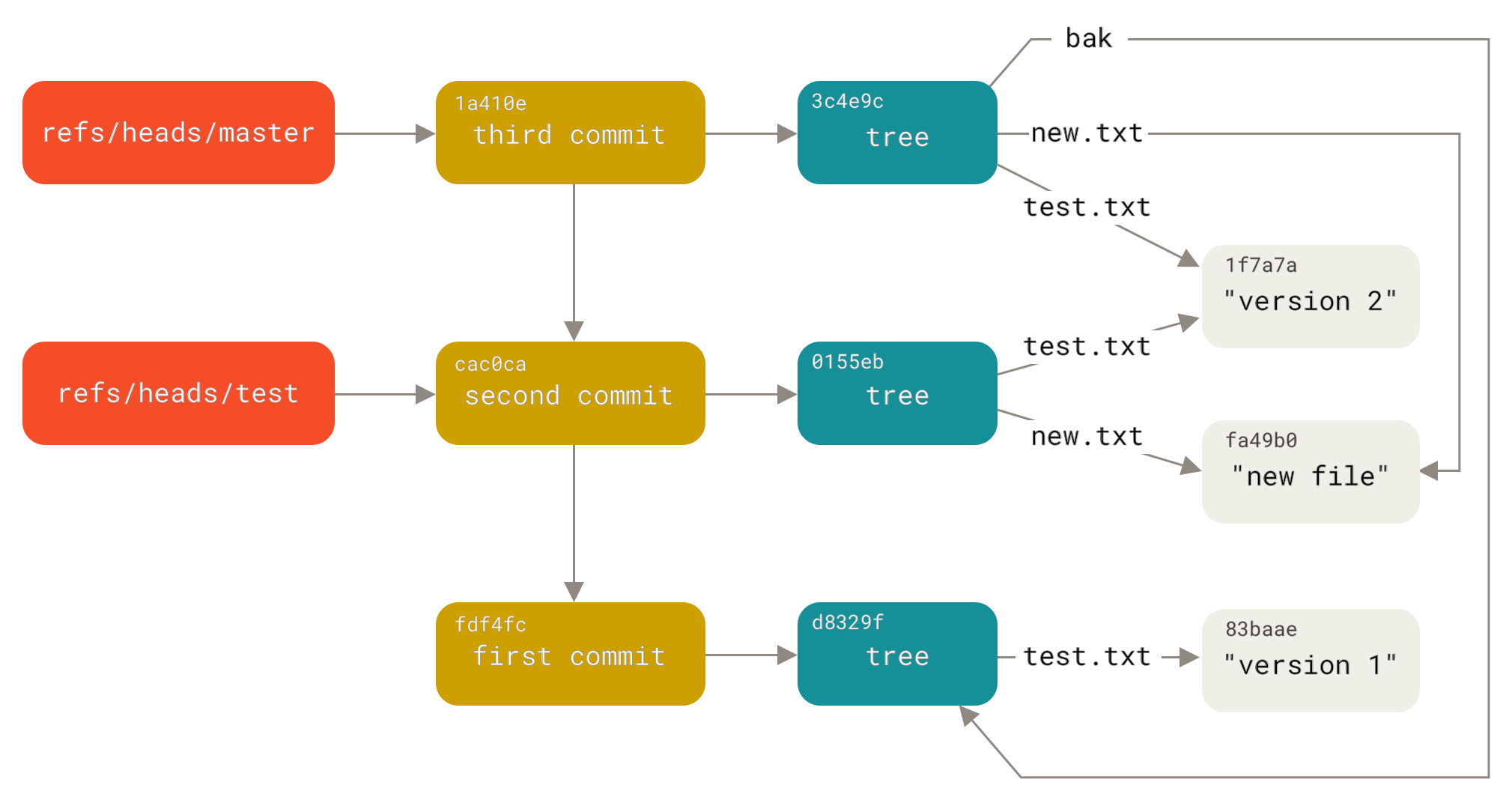
- Track origin of all data
- Collected where?
- Modified by whom, when, why?
- Extracted from what other data or model or algorithm?
- ML models often based on data drived from many sources through many steps, including other models
- Store copies of entire datasets (like Git), identify by checksum
- Store deltas between datasets (like Mercurial)
- Offsets in append-only database (like Kafka), identify by offset
- History of individual database records (e.g. S3 bucket versions)
- some databases specifically track provenance (who has changed what entry when and how)
- specialized data science tools eg Hangar for tensor data
- Version pipeline to recreate derived datasets ("views", different formats)
- e.g. version data before or after cleaning?
{kind=link}
{kind=link}
{kind=link}
Scott Chacon and Ben Straub. Pro Git. 2014
dvc add images
dvc run -d images -o model.p cnn.py
dvc remote add myrepo s3://mybucket
dvc push- Tracks models and datasets, built on Git
- Splits learning into steps, incrementalization
- Orchestrates learning in cloud resources
Key goal: If a customer complains about an interaction, can we reproduce the prediction with the right model? Can we debug the model's pipeline and data? Can we reproduce the model?
- Version everything
- Record every model evaluation with model version
- Append only, backed up
<date>,<model>,<model version>,<feature inputs>,<output>
<date>,<model>,<model version>,<feature inputs>,<output>
<date>,<model>,<model version>,<feature inputs>,<output>
(Containers, Monitoring, A/B Testing, Provenance, Updates, Availability)
- Overview of common data science workflows (e.g., CRISP-DM)
- Importance of iteration and experimentation
- Role of computational notebooks in supporting data science workflows
- Overview of software engineering processes and lifecycles: costs and benefits of process, common process models, role of iteration and experimentation
- Contrasting data science and software engineering processes, goals and conflicts
- Integrating data science and software engineering workflows in process model for engineering AI-enabled systems with ML and non-ML components; contrasting different kinds of AI-enabled systems with data science trajectories
- Overview of technical debt as metaphor for process management; common sources of technical debt in AI-enabled systems


Martínez-Plumed et al. "CRISP-DM Twenty Years Later: From Data Mining Processes to Data Science Trajectories." IEEE Transactions on Knowledge and Data Engineering (2019).
- Origins in "literate programming", interleaving text and code, treating programs as literature (Knuth'84)
- First notebook in Wolfram Mathematica 1.0 in 1988
- Document with text and code cells, showing execution results under cells
- Code of cells is executed, per cell, in a kernel
- Many notebook implementations and supported languages, Python + Jupyter currently most popular

Notes:
- See also https://en.wikipedia.org/wiki/Literate_programming
- Demo with public notebook, e.g., https://colab.research.google.com/notebooks/mlcc/intro_to_pandas.ipynb

Notes: Real experience if little attention is payed to process: increasingly complicated, increasing rework; attempts to rescue by introducing process
taming chaos, understand req., plan before coding, remember testing
Notes: Although dated, the key idea is still essential -- think and plan before implementing. Not all requirements and design can be made upfront, but planning is usually helpful.

incremental prototypes, starting with most risky components

working with customers, constant replanning
(Image CC BY-SA 4.0, Lakeworks)

(CC BY-SA 4.0, Lakeworks)



Source: Martin Fowler 2009, https://martinfowler.com/bliki/TechnicalDebtQuadrant.html
As a group in #lecture, tagging members: Post two plausible examples technical debt in housing price prediction system:
- Deliberate, prudent:
- Reckless, inadvertent:
Sculley, David, et al. Hidden technical debt in machine learning systems. Advances in Neural Information Processing Systems. 2015.
(Intro to Ethics and Fairness)

In 2015, Shkreli received widespread criticism [...] obtained the manufacturing license for the antiparasitic drug Daraprim and raised its price from USD 13.5 to 750 per pill [...] referred to by the media as "the most hated man in America" and "Pharma Bro". -- Wikipedia
"I could have raised it higher and made more profits for our shareholders. Which is my primary duty." -- Martin Shkreli
Note: Image source: https://en.wikipedia.org/wiki/Martin_Shkreli#/media/File:Martin_Shkreli_2016.jpg
{kind=link}

What is the (real) organizational objective of the company?
- 35% of US teenagers with low social-emotional well-being have been bullied on social media.
- 70% of teens feel excluded when using social media.
https://leftronic.com/social-media-addiction-statistics
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Note: Software companies have usually gotten away with claiming no liability for their products
- Race (Civil Rights Act of 1964)
- Religion (Civil Rights Act of 1964)
- National origin (Civil Rights Act of 1964)
- Sex, sexual orientation, and gender identity (Equal Pay Act of 1963, Civil Rights Act of 1964, and Bostock v. Clayton)
- Age (40 and over, Age Discrimination in Employment Act of 1967)
- Pregnancy (Pregnancy Discrimination Act of 1978)
- Familial status (preference for or against having children, Civil Rights Act of 1968)
- Disability status (Rehabilitation Act of 1973; Americans with Disabilities Act of 1990)
- Veteran status (Vietnam Era Veterans’ Readjustment Assistance Act of 1974; Uniformed Services Employment and Reemployment Rights Act of 1994)
- Genetic information (Genetic Information Nondiscrimination Act of 2008)
https://en.wikipedia.org/wiki/Protected_group
- Equal slices for everybody
- Bigger slices for active bakers
- Bigger slices for inexperienced/new members (e.g., children)
- Bigger slices for hungry people
- More pie for everybody, bake more
(Not everybody contributed equally during baking, not everybody is equally hungry)

- Withhold opportunities or resources
- Poor quality of service, degraded user experience for certain groups

Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification, Buolamwini & Gebru, ACM FAT* (2018).
- Over/under-representation of certain groups in organizations
- Reinforcement of stereotypes

Discrimination in Online Ad Delivery, Latanya Sweeney, SSRN (2013).
Data reflects past biases, not intended outcomes

Should the algorithm reflect the reality?
Note: "An example of this type of bias can be found in a 2018 image search result where searching for women CEOs ultimately resulted in fewer female CEO images due to the fact that only 5% of Fortune 500 CEOs were woman—which would cause the search results to be biased towards male CEOs. These search results were of course reflecting the reality, but whether or not the search algorithms should reflect this reality is an issue worth considering."
Bias in dataset labels assigned (directly or indirectly) by humans

Example: Hiring decision dataset -- labels assigned by (possibly biased) experts or derived from past (possibly biased) hiring decisions
Bias in how and what data is collected

Crime prediction: Where to analyze crime? What is considered crime? Actually a random/representative sample?
Recall: Raw data is an oxymoron
Features correlate with protected attribute, remain after removal

- Example: Neighborhood as a proxy for race
- Extracurricular activities as proxy for gender and social class (e.g., “cheerleading”, “peer-mentor for ...”, “sailing team”, “classical music”)
"Big Data processes codify the past. They do not invent the future. Doing that requires moral imagination, and that’s something only humans can provide. " -- Cathy O'Neil in Weapons of Math Destruction
Scenario: Evaluate applications & identify students who are likely to succeed
Features: GPA, GRE/SAT, gender, race, undergrad institute, alumni connections, household income, hometown, transcript, etc.
As a group, post to #lecture tagging members:
- Possible harms: Allocation of resources? Quality of service? Stereotyping? Denigration? Over-/Under-representation?
- Sources of bias: Skewed sample? Tainted labels? Historical bias? Limited features? Sample size disparity? Proxies?
- Understand different definitions of fairness
- Discuss methods for measuring fairness
- Outline interventions to improve fairness at the model level

Source: Federal Reserve’s Survey of Consumer Finances

- Also called fairness through blindness or fairness through unawareness
- Ignore certain sensitive attributes when making a decision
- Example: Remove gender and race from mortgage model
- Easy to implement, but any limitations?
Key idea: Compare outcomes across two groups
- Similar rates of accepted loans across racial/gender groups?
- Similar chance of being hired/promoted between gender groups?
- Similar rates of (predicted) recidivism across racial groups?
Outcomes matter, not accuracy!
Key idea: Focus on accuracy (not outcomes) across two groups
- Similar default rates on accepted loans across racial/gender groups?
- Similar rate of "bad hires" and "missed stars" between gender groups?
- Similar accuracy of predicted recidivism vs actual recidivism across racial groups?
Accuracy matters, not outcomes!

In groups, post to #lecture tagging members:
- Does the model meet anti-classification fairness wrt. sex?
- Does the model meet group fairness?
- Does the model meet equalized odds?
- Is the model fair enough to use?
Research on what post people perceive as fair/just (psychology)
When rewards depend on inputs and participants can chose contributions: Most people find it fair to split rewards proportional to inputs
- Which fairness measure does this relate to?
Most people agree that for a decision to be fair, personal characteristics that do not influence the reward, such as sex or age, should not be considered when dividing the rewards.
- Which fairness measure does this relate to?


🕮 Ian Foster, Rayid Ghani, Ron S. Jarmin, Frauke Kreuter and Julia Lane. Big Data and Social Science: Data Science Methods and Tools for Research and Practice. Chapter 11, 2nd ed, 2020
Strong legal precedents
Very limited scope of affirmative action
Most forms of group fairness likely illegal
In practice: Anti-classification
In all pipeline stages:
- Data collection
- Data cleaning, processing
- Training
- Inference
- Evaluation and auditing


- Understand the role of requirements engineering in selecting ML fairness criteria
- Understand the process of constructing datasets for fairness
- Document models and datasets to communicate fairness concerns
- Consider the potential impact of feedback loops on AI-based systems and need for continuous monitoring
- Consider achieving fairness in AI-based systems as an activity throughout the entire development cycle

Fairness-aware Machine Learning, Bennett et al., WSDM Tutorial (2019).
- Requirements engineering challenges: How to identify fairness concerns, fairness metric, design data collection and labeling
- Human-computer-interaction design challenges: How to present results to users, fairly collect data from users, design mitigations
- Quality assurance challenges: Evaluate the entire system for fairness, continuously assure in production
- Process integration challenges: Incoprorate fairness work in development process
- Education and documentation challenges: Create awareness, foster interdisciplinary collaboration
Equality or equity? Equalized odds? ...
Cannot satisfy all. People have conflicting preferences...
Treating everybody equally in a meritocracy will reinforce existing inequalities whereas uplifting disadvantaged communities can be seen as giving unfair advantages to people who contributed less, making it harder to succeed in the advantaged group merely due to group status.

We should stop training radiologists now. It’s just completely obvious that within five years, deep learning is going to do better than radiologists. -- Geoffrey Hinton, 2016
Within organizations usually little institutional support for fairness work, few activists
Fairness issues often raised by communities affected, after harm occurred
Affected groups may need to organize to affect change
Do we place the cost of unfair systems on those already marginalized and disadvantaged?

Assume most universities want to automate admissions decisions.
As a group in #lecture, tagging group members:
What good or bad societal implications can you anticipate, beyond a single product? Should we do something about it?

"Doctor/nurse applying blood pressure monitor" -> "Healthcare worker applying blood pressure monitor"

How to fix?

TV subtitles: Humans check transcripts, especially with heavy dialects
Carefully review data collection procedures, sampling biases, what data is collected, how trustworthy labels are, etc.
Can address most sources of bias: tainted labels, skewed samples, limited features, sample size disparity, proxies:
- deliberate what data to collect
- collect more data, oversample where needed
- extra effort in unbiased labels
-> Requirements engineering, system engineering
-> World vs machine, data quality, data cascades
- Rarely an organizational priority, mostly reactive (media pressure, regulators)
- Limited resources for proactive work
- Fairness work rarely required as deliverable, low priority, ignorable
- No accountability for actually completing fairness work, unclear responsibilities
What to do?
Buy-in from management is crucial
Show that fairness work is taken seriously through action (funding, hiring, audits, policies), not just lofty mission statements
Reported success strategies:
- Frame fairness work as financial profitable, avoiding rework and reputation cost
- Demonstrate concrete, quantified evidence of benefits of fairness work
- Continuous internal activism and education initiatives
- External pressure from customers and regulators
Recall: Model cards

Mitchell, Margaret, et al. "Model cards for model reporting." In Proc. FAccT, 220-229. 2019.

Excerpt from a “Data Card” for Google’s Open Images Extended dataset (full data card)
- Understand the importance of and use cases for interpretability
- Explain the tradeoffs between inherently interpretable models and post-hoc explanations
- Measure interpretability of a model
- Select and apply techniques to debug/provide explanations for data, models and model predictions
- Eventuate when to use interpretable models rather than ex-post explanations

Image: Gong, Yuan, and Christian Poellabauer. "An overview of vulnerabilities of voice controlled systems." arXiv preprint arXiv:1803.09156 (2018).

Goyal, Raman, Gabriel Ferreira, Christian Kästner, and James Herbsleb. "Identifying unusual commits on GitHub." Journal of Software: Evolution and Process 30, no. 1 (2018): e1893.
IF age between 18–20 and sex is male THEN
predict arrest
ELSE IF age between 21–23 and 2–3 prior offenses THEN
predict arrest
ELSE IF more than three priors THEN
predict arrest
ELSE
predict no arrestRudin, Cynthia. "Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead." Nature Machine Intelligence 1, no. 5 (2019): 206-215.

Image source (CC BY-NC-ND 4.0): Christin, Angèle. (2017). Algorithms in practice: Comparing web journalism and criminal justice. Big Data & Society. 4.

- Why did the system make a wrong prediction in this case?
- What does it actually learn?
- What data makes it better?
- How reliable/robust is it?
- How much does second model rely on outputs of first?
- Understanding edge cases

Debugging is the most common use in practice (Bhatt et al. "Explainable machine learning in deployment." In Proc. FAccT. 2020.)
Levels of explanations:
- Understanding a model
- Explaining a prediction
- Understanding the data
Truthful explanations, easy to understand for humans
Easy to derive contrastive explanation and feature importance
Requires feature selection/regularization to minimize to few important features (e.g. Lasso); possibly restricting possible parameter values

- Select dataset X (previous training set or new dataset from same distribution)
- Collect model predictions for every value:
$y_i=f(x_i)$ - Train inherently interpretable model
$g$ on (X,Y) - Interpret surrogate model
$g$
Can measure how well
Advantages? Disadvantages?
Notes:
Flexible, intuitive, easy approach, easy to compare quality of surrogate model with validation data (

Source: Christoph Molnar. "Interpretable Machine Learning." 2019

Source: Christoph Molnar. "Interpretable Machine Learning." 2019
Note: bike rental data in DC
Derive key influence factors or decisions from model parameters
Derive contrastive counterfacturals from models
Examples: Predict arrest for 18 year old male with 1 prior:
IF age between 18–20 and sex is male THEN predict arrest
ELSE IF age between 21–23 and 2–3 prior offenses THEN predict arrest
ELSE IF more than three priors THEN predict arrest
ELSE predict no arrestWhich features were most influential for a specific prediction?

Source: https://github.com/marcotcr/lime

Source: https://github.com/marcotcr/lime
Often long or multiple explanations
Your loan application has been declined. If your savings account ...
Your loan application has been declined. If your lived in ...
Report all or select "best" (e.g. shortest, most actionable, likely values)
(Rashomon effect)

- Prototype is a data instance that is representative of all the data
- Criticism is a data instance not well represented by the prototypes

Source: Christoph Molnar. "Interpretable Machine Learning." 2019
Data debugging: What data most influenced the training?

Source: Christoph Molnar. "Interpretable Machine Learning." 2019
In groups, discuss which explainability approaches may help and why. Tagging group members, write to #lecture.
Algorithm bad at recognizing some signs in some conditions:

Graduate appl. system seems to rank applicants from HBCUs low:

Left Image: CC BY-SA 4.0, Adrian Rosebrock
- Past attempts often not successful at bringing tools into production. Radiologists do not trust them. Why?
- Wizard of oz study to elicit requirements
Users are less likely to question the model when explanations provided
- Even if explanations are unreliable
- Even if explanations are nonsensical/incomprehensible
Danger of overtrust and intentional manipulation
Stumpf, Simone, Adrian Bussone, and Dympna O’sullivan. "Explanations considered harmful? user interactions with machine learning systems." In Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems (CHI). 2016.

(a) Rationale, (b) Stating the prediction, (c) Numerical internal values
Observation: Both experts and non-experts overtrust numerical explanations, even when inscrutable.
Ehsan, Upol, Samir Passi, Q. Vera Liao, Larry Chan, I. Lee, Michael Muller, and Mark O. Riedl. "The who in explainable AI: how AI background shapes perceptions of AI explanations." arXiv preprint arXiv:2107.13509 (2021).
Hypotheses:
- It is a myth that there is necessarily a trade-off between accuracy and interpretability (when having meaningful features)
- Explainable ML methods provide explanations that are not faithful to what the original model computes
- Explanations often do not make sense, or do not provide enough detail to understand what the black box is doing
- Black box models are often not compatible with situations where information outside the database needs to be combined with a risk assessment
- Black box models with explanations can lead to an overly complicated decision pathway that is ripe for human error
Rudin, Cynthia. "Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead." Nature Machine Intelligence 1.5 (2019): 206-215. (Preprint)
- Explain key concepts of transparency and trust
- Discuss whether and when transparency can be abused to game the system
- Design a system to include human oversight
- Understand common concepts and discussions of accountability/culpability
- Critique regulation and self-regulation approaches in ethical machine learning

Eslami, Motahhare, et al. I always assumed that I wasn't really that close to [her]: Reasoning about Invisible Algorithms in News Feeds. In Proc. CHI, 2015.
Does providing an explanation allow customers to 'hack' the system?
- Loan applications?
- Apple FaceID?
- Recidivism?
- Auto grading?
- Cancer diagnosis?
- Spam detection?
- Unavoidable that ML models will make mistakes
- Users knowing about the model may not be comforting
- Inability to appeal a decision can be deeply frustrating
"Just a bug, things happen, nothing we could have done"
- But system was designed by humans
- But humans did not anticipate possible mistakes, did not design to mitigate mistakes
- But humans made decisions about what quality was good enough
- But humans designed/ignored the development process
- But humans gave/sold poor quality software to other humans
- But humans used the software without understanding it
- ...

Results from the 2018 StackOverflow Survey

- Understand safety concerns in traditional and AI-enabled systems
- Apply hazard analysis to identify risks and requirements and understand their limitations
- Discuss ways to design systems to be safe against potential failures
- Suggest safety assurance strategies for a specific project
- Describe the typical processes for safety evaluations and their limitations
Amodei, Dario, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. "Concrete problems in AI safety." arXiv preprint arXiv:1606.06565 (2016).
Does the model goal align with the system goal? Does the system goal align with the user's goals?
- Profits (max. accuracy) vs fairness
- Engagement (ad sales) vs enjoyment, mental health
- Accuracy vs operating costs
Test model and system quality in production
(see requirements engineering and architecture lectures)
Two main strategies:
- Evidence of safe behavior in the field
- Extensive field trials
- Usually expensive
- Evidence of responsible (safety) engineering process
- Process with hazard analysis, testing mitigations, etc
- Not sufficient to assure safety
Most standards require both

- Does the model reliably detect stop signs?
- Also in poor lighting? In fog? With a tilted camera? Sensor noise?
- With stickers taped to the sign? (adversarial attacks)

Image: David Silver. Adversarial Traffic Signs. Blog post, 2017
- Every useful model has at least one decision boundary
- Predictions near that boundary are not (and should not) be robust

Scenario: Medical use of transcription service, dictate diagnoses and prescriptions
As a group, tagging members, post to #lecture:
- What safety concerns can you anticipate?
- What notion of robustness are you concerned about (i.e., what distance function)?
- How could you use robustness to improve the product (i.e., when/how to check robustness)?
- Explain key concerns in security (in general and with regard to ML models)
- Identify security requirements with threat modeling
- Analyze a system with regard to attacker goals, attack surface, attacker capabilities
- Describe common attacks against ML models, including poisoning and evasion attacks
- Understand design opportunities to address security threats at the system level
- Apply key design principles for secure system design

Attack at inference time
- Add noise to an existing sample & cause misclassification
- Possible with and without access to model internals
Accessorize to a Crime: Real and Stealthy Attacks on State-of-the-Art Face Recognition, Sharif et al. (2016).

From Goodfellow et al (2018). Making machine learning robust against adversarial inputs. Communications of the ACM, 61(7), 56-66.
Note: Exploiting inaccurate model boundary and shortcuts
- Decision boundary: Ground truth; often unknown and not specifiable
- Model boundary: What is learned; an approximation of decision boundary
Inject mislabeled training data to damage model quality
- 3% poisoning => 11% decrease in accuracy (Steinhardt, 2017)
Attacker must have some access to the public or private training set
Example: Anti-virus (AV) scanner: AV company (allegedly) poisoned competitor's model by submitting fake viruses

Insert training data with seemingly correct labels

More targeted than availability attack, cause specific misclassification
Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks, Shafahi et al. (2018)

Singel. Google Catches Bing Copying; Microsoft Says 'So What?'. Wired 2011.
Given a model output (e.g., name of a person), infer the corresponding, potentially sensitive input (facial image of the person)
- e.g., gradient descent on input space

Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures, M. Fredrikson et al. in CCS (2015).
Recall: Dashcam system from I2/I3
As a group, tagging members, post in #lecture:
- Security requirements
- Possible (ML) attacks on the system
- Possible mitigations against these attacks



A systematic approach to identifying threats (i.e., attacker actions)
- Construct an architectural diagram with components & connections
- Designate the trust boundary
- For each untrusted component/connection, identify threats
- For each potential threat, devise a mitigation strategy

Andew Pole, who heads a 60-person team at Target that studies customer behavior, boasted at a conference in 2010 about a proprietary program that could identify women - based on their purchases and demographic profile - who were pregnant.
Lipka. "What Target knows about you". Reuters, 2014

Who has access?

- Understand different roles in projects for AI-enabled systems
- Plan development activities in an inclusive fashion for participants in different roles
- Diagnose and address common teamwork issues
- Describe agile techniques to address common process and communication issues

- Software Engineer
- Data Engineer
- Data Scientist
- Applied Scientist
- Research Scientist
Talk: Ryan Orban. Bridging the Gap Between Data Science & Engineer: Building High-Performance Teams. 2016

n(n − 1) / 2 communication links within a team

Structural congruence, Geographical congruence, Task congruence, IRC communication congruence
In groups, tagging team members, discuss and post in #lecture:
- How to decompose the work into teams?
- What roles to recruit for the teams




(1)
Looking back at the semester
(400 slides in 40 min)
(2)
Discussion of future of ML in Production
(3)
Feedback for future semesters
(closing remarks)
see also Andrej Karpathy. Software 2.0. Blog, 2017
Note: Andrej Karpathy is the director of AI at Tesla and coined the term Software 2.0

Ryohei Fujimaki. AutoML 2.0: Is The Data Scientist Obsolete? Forbes, 2020
However, AutoML does not spell the end of data scientists, as it doesn’t “AutoSelect” a business problem to solve, it doesn’t AutoSelect indicative data, it doesn’t AutoAlign stakeholders, it doesn’t provide AutoEthics in the face of potential bias, it doesn’t provide AutoIntegration with the rest of your product, and it doesn’t provide AutoMarketing after the fact. -- Frederik Bussler
Frederik Bussler. Will AutoML Be the End of Data Scientists?, Blog 2020





This is an education problem, more than a research problem.
Interdisciplinary teams, mutual awareness and understanding
Software engineers and data scientists will each play an essential role
Joint responsibilities, joint processes, joint tools, joint vocabulary
As a group, think about challenges that the team will likely focus when turning their research into a product and what you would do about it:
- One machine-learning challenge
- One engineering challenge in building the product
- One challenge from operating and updating the product
- One team or management challenge
- One business challenge
- One safety or ethics challenge
Post answer to #lecture on Slack and tag all group members
- Recitations -> labs (required and graded)
- Labs all focused on tooling
- Teamwork meetings with TAs
- Allowing generative AI
- In-class interactions and breakouts with 140+ students
- Clear specifications for homework, pass/fail grading, allow resubmission
- Credit for social activities in teams
- Slack for coordination and questions
See link on Slack