Cryptonight variant 4 aka CryptonightR #5126
Conversation
|
Has this been compared for pros/cons with the claimed "FPGA-proof" CN-GPU algo? I have 0 clue how they compare and lack the technical know-how to compare the two, but figured this would be a good place to discuss them to be sure we get the best of all available PoW algorithms: Hadn't seen the merits/issues of it discussed elsewhere by people who know these things. |
|
I hope CN-GPU will never be implemented as PoW on Monero, I want to be able to mine on CPU. |
|
That's exactly what I was hoping to hear. I had no idea it was GPU-only, as there is no documentation around it. Thanks 👍 |
|
@SChernykh How are the instruction frequencies calculated? I remember it used to be 3/8 for multiplication and 1/8 for the rest. Regarding "CN-GPU", it replaces the AES encryption in the initialization loop with keccak and then the main loop is replaced with just a lot of floating point math (single precision multiplication and addition). That's why it's power hungry. It will be most likely compute-bound on CPUs and possibly also on some GPUs. |
Yes, it is like you say initially (except ROR/ROL are less frequent (1/16) in favor of XOR (1/4)): But it changes during code generation because code generator adjusts some sequences to avoid possible ASIC optimizations. You can read comments in variant4_random_math.h starting from line 263: The instruction frequencies in the table are average from first 10,000,000 random programs. |
| // Generates as many random math operations as possible with given latency and ALU restrictions | ||
| static inline int v4_random_math_init(struct V4_Instruction* code, const uint64_t height) | ||
| { | ||
| // MUL is 3 cycles, 3-way addition and rotations are 2 cycles, SUB/XOR are 1 cycle |
There was a problem hiding this comment.
Not sure if it makes a big difference, but the real latency of ROL/ROR on Intel is ~1 cycle (reference). 2 cycle latency is only for flags dependence.
There was a problem hiding this comment.
These are worst case numbers, so they are conservative. I ran a lot of tests before and found that a few random seeds produce slower than usual code when it has a lot of rotations. This is why I set it to 2 cycles for rotations and reduced rotations frequency.
These rules make sense since there is just one 'program' per block. |
src/crypto/variant4_random_math.h
Outdated
| { | ||
| check_data(&data_index, 1, data, sizeof(data)); | ||
|
|
||
| struct V4_InstructionCompact op = ((struct V4_InstructionCompact*)data)[data_index++]; |
There was a problem hiding this comment.
This code seems to be deterministic based on the height, so we can know know what the program for height 2e6 will be way in advance. I saw the rationale for height seed, so a GPU can get precompiled code in advance. However, using the previous block's hash also accomplishes this, while keeping everything unknown till shortly before the time. Would this be better ? It's unclear whether knowing all this in advance could be exploited somehow.
There was a problem hiding this comment.
What's the risk to seeding off of a previous blocks hash in the event of a re-org? I'm trying to think of the ways that can go wrong, but I'm not sure I can come up with anything.
There was a problem hiding this comment.
Previous block hash makes pre-compilation impossible because it's unknown until new block arrives, so GPUs will be halted every time. Knowing programs in advance won't help ASICs much because there are just too many different programs (one for each block). They'll be able to precompile too, but it won't give more than 5% speedup (see first post).
Plus, using the block height makes it possible to just check the code generator for all future block heights and guarantee that it doesn't crash/freze etc. and produces working random programs. I think it's better to play safe here.
There was a problem hiding this comment.
What about an ASIC strategy in which the design was intended only to work with certain block heights? I'm not yet familiar enough with this proposal to know whether this is viable.
There was a problem hiding this comment.
Generated random programs are quite similar and each program has all possible instructions in it, so if ASIC can run one of them, it can run all.
There was a problem hiding this comment.
"Previous block hash makes pre-compilation impossible" does not apply if the hash is the one two steps back.
There was a problem hiding this comment.
Yes, but it'll require bigger refactoring because it's not available in cn_slow_hash (and functions calling it) now. Pool software will also require refactoring to support it. Block height is convenient because it's readily available with existing code both in monerod and in pool software.
| // MUL = opcodes 0-2 | ||
| // ADD = opcode 3 | ||
| // SUB = opcode 4 | ||
| // ROR/ROL = opcode 5, shift direction is selected randomly |
There was a problem hiding this comment.
Since the shift count is the full size of the register in V4_EXEC, ROL and ROR are really the same thing (or, rol eax, 28 is the same as ror eax, 4).
There was a problem hiding this comment.
Yes, but it still adds a bit more logic to ASIC. This also why I only use one opcode for them.
There was a problem hiding this comment.
Just a 6 bit sub AFAICT. Something like sal/sar instead would at least change the op a bit. Or bswap also looks to be simple and latency 1. Anyway, you're the expert here so I won't say more.
There was a problem hiding this comment.
What additional logic needs to be added for the other rotate? Wouldn't the additional logic only need to be in the prepping stage? Which brings me to the next point - why not drop one of the rotates in the execution switch to compress the logic? Seems like it would really be tough for the compiler to optimize that one.
| hash_extra_blake(data, sizeof(data), data); | ||
| *data_index = 0; | ||
| } | ||
| } |
There was a problem hiding this comment.
I suspect most runs require the the same amount of calls, as the data needed seems fairly predictable. I kinda expect this code building part is not really time sensitive though, is it ?
There was a problem hiding this comment.
Code generator generates first 10,000,000 random programs in 30 seconds, so it's really fast - 3 microseconds on average.
| // Don't do the same instruction (except MUL) with the same source value twice because all other cases can be optimized: | ||
| // 2xADD(a, b, C) = ADD(a, b*2, C1+C2), same for SUB and rotations | ||
| // 2xXOR(a, b) = NOP | ||
| if ((opcode != MUL) && ((inst_data[a] & 0xFFFF00) == (opcode << 8) + ((inst_data[b] & 255) << 16))) |
There was a problem hiding this comment.
You probably also want ADD a,b then SUB a,b and vice versa.
I also don't quite understand this. you seem to be storing only 8 bits of the source register here, is that because you don't care about false positives ?
There was a problem hiding this comment.
I store "register data revision" (change counter) here, so it can't be more than 256 because programs don't have that many instructions.
|
[We are asicmakers (but not interested in secret Monero mining)] Is it possible to use data from the blockchain itself in the PoW algo? block data? The problem with PoW in our view is that it's isolated from the block data. Inclusion of block data would force asicmakers to make chips that could be more useful later. |
|
Some chains do that. At least Boolberry. Not sure if you asked "can it be sensibly done", or "please consider doing it" :) |
| } | ||
|
|
||
| // Don't do the same instruction (except MUL) with the same source value twice because all other cases can be optimized: | ||
| // 2xADD(a, b, C) = ADD(a, b*2, C1+C2), same for SUB and rotations |
There was a problem hiding this comment.
Is this why a constant is used in addition? To prevent a ADD, SUB case which results in a NOP? Doesn't this happen in the case where the constant is zero? And even when the constant is non-zero, couldn't such a sequence be optimized further? i.e. ADD(A, B, 10), SUB(A, B) -> ADD(A, 10).
There was a problem hiding this comment.
Random constant is used to fix zero bits that accumulate after multiplications. The case when add -> sub can be optimized to single add is quite rare, it's not worth additional complexity of the code generator. We're talking about reducing possible 5% speedup from optimizing compiler if we fix all thinkable cases here, not just this one. 5% is not much already.
There was a problem hiding this comment.
Presumably you meant 5% speedup in this portion, and not the entire algorithm (which should be dominated by cache/memory accesses)?
I don't quite like this argument, the CPU is pegged (more power) while custom designs might be able to save further power by having the same latencies with less silicon. Although any JIT-like approach with LLVM should do the trick here too.
There was a problem hiding this comment.
5% speedup was in my tests where I had only random math in the loop and compared optimizing C++ compiler with direct translation to x86 code. The actual Cryptonight loop doesn't get any speedup from optimizing compiler on CPU because it's still dominated by the main memory-hard loop.
Custom designs will of course will have random math as limiting factor and will have optimizing compiler to assist them whenever possible.
I don't say in the description that ASIC is impossible. It's possible and can be still be 3-4 times more efficient per watt. But this algorithm is not the final code, it's only for the next 6 months.
| // MUL = opcodes 0-2 | ||
| // ADD = opcode 3 | ||
| // SUB = opcode 4 | ||
| // ROR/ROL = opcode 5, shift direction is selected randomly |
There was a problem hiding this comment.
What additional logic needs to be added for the other rotate? Wouldn't the additional logic only need to be in the prepping stage? Which brings me to the next point - why not drop one of the rotates in the execution switch to compress the logic? Seems like it would really be tough for the compiler to optimize that one.
|
@vtnerd I've fixed pointer aliasing issues, can you check that I didn't miss anything? |
|
FYI, I tested the code generation routine for all the block heights starting from the current height till |
|
@vtnerd @moneromooo-monero
How it would affect existing ASIC designs (if there are any which I doubt):
Effect on CPU/GPU: my tests show absolutely no changes to their performance/power usage. |
|
Looks good here. Waiting for vtnerd's now. |
d0ff6dd
to
b92eb0a
Compare
It introduces random integer math into the main loop.
214fc8f
to
f51397b
Compare
Co-Authored-By: Lee Clagett <vtnerd@users.noreply.github.com>
| do if (variant >= 4) \ | ||
| { \ | ||
| for (int i = 0; i < 4; ++i) \ | ||
| V4_REG_LOAD(r + i, (uint8_t*)(state.hs.w + 12) + sizeof(v4_reg) * i); \ |
There was a problem hiding this comment.
It won't change anything. This pointer is passed to memcpy which is declared as void * memcpy ( void * destination, const void * source, size_t num );, so pointer type doesn't matter here.
|
Is the algorithm for the next fork already final? |
|
Yes, it's already merged into release-0.13 branch (the one Monero will use for the fork). |
Same as CNv2.
I already told you why it's not true. GPUs are limited by memory bandwidth, not computation. CNv2 ASICs use on-chip SRAM, they're not limited by memory bandwidth/latency, but they're limited by computation. This is why they'll get slower while GPU won't. Are you really a hardware engineer? |
Here I have got the result for these two logic synthesize result: The period of clock is 0.62ns(with a frequency around 1.623GHz) with a little slack. |

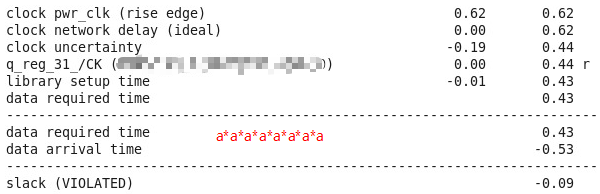
|
@Leochains Ok, a few questions:
Take a look at sample program one more time: https://github.com/SChernykh/CryptonightR/blob/master/CryptonightR/random_math.inl There are no cases where you can do 3 consecutive multiplications without dependencies from other registers - if you look at dependency chain for each register individually. So the last question: how fast something like stripped down Amber design could run to execute random math in CryptonightR? |
Hardware can implement 23 small units with each one do 3 consecutive ops and use many mux to switch, each unit followed with DFF running at a clock rate around 1.4GHz(double of memory access frequency).
Latches can be used for the middle state registers to buffer the values or directly unroll those 3 ops.
I need some time. |
It means that DIV+SQRT in CNv2 can be done in 1.5 ns (3+2 multiplications) + 2 ns (2 reads from ROM): 3 clock cycles at 800 MHz, or 6 clock cycles at 1600 MHz. Much faster than in your estimations.
Why 23? There are 6 ops, 3 consecutive ops can be any of 216 combinations. |
Sorry I got some misunderstanding description. Different ops just need different switches and muxs, 23 means 23 cycles at 1.4GHz clock (considering the max 69 instructions, every cycle do 3 instructions). The total cycles at 1.4GHz are 69/3, which corresponding to 23/2=12 cycles at 700MHz(memory access frequency). |
23 cycles at 1.4 GHz clock is ~16.5 ns. Don't forget that the next iteration can't start before random math is calculated - there is a data dependency for that, so this ASIC could do ~18 ns/iteration which is basically the same number as CPU - AMD Ryzen @ 4 GHz does 20 ns/iteration. CNv2 ASICs are much faster. |
|
Is there a testpool for the new monero pow available |
The hardware can use latches instead of DFFs to break the dependence. you can understand that ASICs can split one cycle as 3 or more by different phas.
Don't forget that if with 16MB memory, an ASIC can reach to 8 times of CPU, and if they put 320 chips on one box like the current box, that means one box can get a 320 * 8 times rate than CPU. So I suggest that the only way to assist ASICs is to enlarge memory requirement like ETH or Grin. Otherwise, no matter how the calculation algorithm modified ASICs box can still easier and cheaper to get a huge number times of hashrate than CPU/GPU. Or if the CNV4 need to use many times of memory than CNV2, such as 16MB or 32MB, then an ASIC box can not get a huge number times rate than CPU/GPU, that is the second best way for current statement to anti ASIC I suppose. |
How can they break the dependency if they just don't know the address in scratchpad to read from until calculation is done?
This will slow down CPU and GPU proportionally. CNv4 is a temporary solution, but RandomX will use 4 GB memory.
Current box has 320 chips but it's 320x1, not 320x8, because each of 320 chips scans nonces linearly. If it had 8 independent scratchpads, it wouldn't scan nonces this way. Each chip does 400 h/s, 128 kh/s in total. Similar configuration for CNv4 would be (assuming 18 n/s per iteration) 320*106 h/s = 34 kh/s. |
It can have multiple scratchpads and still scan linearly within a single chip. Assuming an 8 MB chip, which seems most likely, it will run nonces 0, 1, 2, 3 in the first batch, then 4, 5, 6, 7 etc. This is possible since it's a pipelined design and the whole batch is finished at the same time. The independent nonce sequences of different chips are used to avoid inter-chip synchronization, which would be problematic especially if the miner has multiple boards that are not connected together. |
|
@tevador It's possible but not very logical. They separate each of 320 chips nonce ranges by 2^22, why would they implement such interleaving within each chip? It would make more sense to split each range in 8 parts in this case. |
Latches (different phase enable controlled) can do that.
The current CNV2 access memory with 512 bit width but only calculate with 128 every time, at least the new algorithm can using a 8MB memory, that might have no influence on CPU/GPU.
Why 8 independent scratchpads can not get the linearly scans? I think the 320 chips can divide a nonce with equal distribution and it's possible for every scratchpads do the same in one chip. On the other way, if you are a ASIC designer, integrated 18MB memory is already a general product proven method on LTC, would you just only integrate 2MB in one chip with a expensive package, testing, PCB and other cost? |
Can do what? Something theoretically impossible - reading from memory when address is still not known?
They can, but they don't. We clearly see 320 distinct ranges on the nonce graph. They maybe configured as 40x8 or 20x16, I also don't think they are indeed 320 separate chips. |
Yes, that's right, this is a general way in hardware. |
You can treat latches as DFF which controlled by gating enable, they are triggered by enable signal level instead of clock edge. The FPGA have no gating as the logic are already fixed. But LATCH are standard cell on ASIC which generally using together with clock gating cells and the similar logic control. |
We don't know, but having 320 chips is not far fetched considering Innosilicon A8 has 160 chips. I think they have to use more than 320 scratchpads since 400 H/s per scratchpad would require operating frequency of around 2.4 GHz per the table posted above.
This still doesn't explain how an ASIC can load from memory before the address is calculated. |
Table posted above overestimates numbers for CNv2. You showed yourself that 3 multiplications can be done in 0.75 ns. DIV requires 3 multiplications, SQRT requires 2 multiplications, so 400 h/s (4.76 ns/iteration) is quite possible. |
|
@SChernykh The Open-CryptoNight-ASIC does ~235 H/s per scratchpad in CNv0 at 800 MHz, so it would require 1.4 GHz to reach 400 H/s. CNv2 must be slower than that due to higher div+sqrt latency. |
But 16MB memory will get a double hashrate. |
Load data from memory twice every 12 clock cycles in one round, using a slow clock. Here just talking about how 3 instruction ops can be done in one cycle, have nothing to do with memory access. |
The problem is that div+sqrt latency turned out to be not higher for efficient implementation. It can also fit in 5 ns (4 cycles at 800 MHz). |
Added support for CryptoNightR (Variant 4) utilizing the code from: monero-project/monero#5126
This is a proposal for the next Monero PoW algorithm. Please read original discussion before posting here.
Random integer math modification
Division and square root are replaced with a sequence of random integer instructions:
Program size is between 60 and 69 instructions, 63 instructions on average.
There are 9 registers named R0-R8. Registers R0-R3 are variable, registers R4-R8 are constant and can only be used as source register in each instruction. Registers R4-R8 are initialized with values from main loop registers on every main loop iteration.
All registers are 32 bit to enable efficient GPU implementation. It's possible to make registers 64 bit though - it's supported in miners below.
The random sequence changes every block. Block height is used as a seed for random number generator. This allows CPU/GPU miners to precompile optimized code for each block. It also allows to verify optimized code for all future blocks against reference implementation, so it'll be guaranteed safe to use in Monero daemon/wallet software.
An example of generated random math:
Optimized CPU miner:
Optimized GPU miner:
Pool software:
Design choices
Instruction set is chosen from instructions that are efficient on CPUs/GPUs compared to ASIC: all of them except XOR are complex operations at logic circuit level and require O(logN) gate delay. These operations have been studied extensively for decades and modern CPUs/GPUs already have the best implementations.
SUB, XOR are never executed with the same operands to prevent degradation to zero. ADD is defined as a 3-way operation with random 32-bit constant to fix trailing zero bits that tend to accumulate after multiplications.
Code generator ensures that minimal required latency for ASIC to execute random math is at least 2.5 times higher than what was needed for DIV+SQRT in CryptonightV2: current settings ensure latency equivalent to a chain of 15 multiplications while optimal ASIC implementation of DIV+SQRT has latency equivalent to a chain of 6 multiplications.
It also accounts for super-scalar and out of order CPUs which can execute more than 1 instruction per clock cycle. If ASIC implements random math circuit as simple in-order pipeline, it'll be hit with further up to 1.5x slowdown.
A number of simple checks is implemented to prevent algorithmic optimizations of the generated code. Current instruction mix also helps to prevent algebraic optimizations of the code. My tests show that generated C++ code compiled with all optimizations on is only 5% faster on average than direct translation to x86 machine code - this is synthetic test with just random math in the loop, but the actual Cryptonight loop is still dominated by memory access, so this number is needed to estimate the limits of possible gains for ASIC.
Performance on CPU/GPU and ASIC
CryptonightR parameters were chosen to:
Actual numbers (hashrate and power consumption for different CPUs and GPUs) are available here.
ASIC will have to implement some simple and minimalistic instruction decoder and execution pipeline. While it's not impossible, it's much harder to create efficient out of order pipeline which can track all data dependencies and do more than 1 instruction per cycle. It will also have to use fixed clock cycle length, just like CPU, so for example XOR (single logic gate) won't be much faster anymore.
ASIC with external memory will have the same performance as they did on CryptonightV2, but they will require much more chip area to implement multiple CPU-like execution pipelines.
ASIC with on-chip memory will get 2.5-3.75 times slower due to increased math latency and randomness and they will also require more chip area.