Enhance autogptq backend to support VL models #1860
Conversation
✅ Deploy Preview for localai canceled.
|
|
I've no idea what is the difference between autogptq.yml and transformers-*.yml in common-env folder. If autogptq shares the same dependencies with transformers, does that mean no need to create a separate autogptq conda env? |
|
How to retrigger the test build? |
|
@mudler Below code snippet shows that images in payload are converted to base64 StringImage. I think that's the reason why calling the models kept failing. if pp.Type == "image_url" {
// Detect if pp.ImageURL is an URL, if it is download the image and encode it in base64:
base64, err := getBase64Image(pp.ImageURL.URL)
if err == nil {
input.Messages[i].StringImages = append(input.Messages[i].StringImages, base64) // TODO: make sure that we only return base64 stuff
// set a placeholder for each image
input.Messages[i].StringContent = fmt.Sprintf("[img-%d]", index) + input.Messages[i].StringContent
index++
}I found a relevant question in Qwen-VL issues, this answer QwenLM/Qwen-VL#112 (comment) reveals that qwen-vl doesn't support base64 as image input. It supports only URL or image file path.
Please share your thoughts. |
The option 1 would be what I'd try first, however might be more complex to achieve. You need to be careful to keep a consistent logic between the golang API and the llama.cpp grpc-server. If you are not much into put your hands on C++ that might be more complex to explore The option 2 sounds more easy to do. In the llama.cpp backend we do: //
for (int i = 0; i < predict->images_size(); i++) {
data["image_data"].push_back(json
{
{"id", i},
{"data", predict->images(i)},
});
}
because Images inside the request is an array, and each entry contains the base64 encoded images (see here for the golang counter-part). Each |
|
@mudler I have finally implemented this feature for Qwen-vl model. Please review. I tested this feature with below configuration.
# Model name.
# The model name is used to identify the model in the API calls.
- name: gpt-4-vision-preview
# Default model parameters.
# These options can also be specified in the API calls
parameters:
model: /opt/models/qwen-vl-chat-int4
temperature: 0.7
top_k: 85
top_p: 0.7
# Default context size
context_size: 4096
# Default number of threads
threads: 16
backend: autogptq
# define chat roles
roles:
user: "user:"
assistant: "assistant:"
system: "system:"
template:
chat: &template |
{{.Input}}
completion: *template
# Enable F16 if backend supports it
f16: true
embeddings: false
# Enable debugging
debug: true
# GPU Layers (only used when built with cublas)
gpu_layers: -1
# Diffusers/transformers
cuda: true
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d \
'{"model": "gpt-4-vision-preview", "messages": [{"role": "user", \
"content": [{"type":"text", "text": "Describe the image?"}, {"type": "image_url", "image_url": {"url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg" }}], "temperature": 0.2}]}'
{
"created": 1711430450,
"object": "chat.completion",
"id": "23add6fd-009e-43b4-a361-341cb2386672",
"model": "gpt-4-vision-preview",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "A woman sitting on a beach with a dog and giving it a high five."
}
}
],
"usage": {
"prompt_tokens": 0,
"completion_tokens": 0,
"total_tokens": 0
}
} |
|
@mudler I just found that this feature doesn't work if there are multiple rounds conversation. Below is the error message: This relevant code snippet: t = pipeline(compiled_prompt)[0]["generated_text"]
print(f"generated_text: {t}", file=sys.stderr)
if compiled_prompt in t:
t = t.replace(compiled_prompt, "")
# house keeping. Remove the image files from /tmp folder
for img_path in prompt_images[1]:
try:
os.remove(img_path)
except Exception as e:
print(f"Error removing image file: {img_path}, {e}", file=sys.stderr)
return backend_pb2.Result(message=bytes(t, encoding='utf-8'))According to the code structure and the error message, I suspect the error was thrown from the |
…2.1 by renovate (#20490) This PR contains the following updates: | Package | Update | Change | |---|---|---| | [docker.io/localai/localai](https://togithub.com/mudler/LocalAI) | minor | `v2.11.0-cublas-cuda11-ffmpeg-core` -> `v2.12.1-cublas-cuda11-ffmpeg-core` | | [docker.io/localai/localai](https://togithub.com/mudler/LocalAI) | minor | `v2.11.0-cublas-cuda11-core` -> `v2.12.1-cublas-cuda11-core` | | [docker.io/localai/localai](https://togithub.com/mudler/LocalAI) | minor | `v2.11.0-cublas-cuda12-ffmpeg-core` -> `v2.12.1-cublas-cuda12-ffmpeg-core` | | [docker.io/localai/localai](https://togithub.com/mudler/LocalAI) | minor | `v2.11.0-cublas-cuda12-core` -> `v2.12.1-cublas-cuda12-core` | | [docker.io/localai/localai](https://togithub.com/mudler/LocalAI) | minor | `v2.11.0-ffmpeg-core` -> `v2.12.1-ffmpeg-core` | | [docker.io/localai/localai](https://togithub.com/mudler/LocalAI) | minor | `v2.11.0` -> `v2.12.1` | --- > [!WARNING] > Some dependencies could not be looked up. Check the Dependency Dashboard for more information. --- ### Release Notes <details> <summary>mudler/LocalAI (docker.io/localai/localai)</summary> ### [`v2.12.1`](https://togithub.com/mudler/LocalAI/releases/tag/v2.12.1) [Compare Source](https://togithub.com/mudler/LocalAI/compare/v2.12.0...v2.12.1) I'm happy to announce the v2.12.1 LocalAI release is out! ##### 🌠 Landing page and Swagger Ever wondered what to do after LocalAI is up and running? Integration with a simple web interface has been started, and you can see now a landing page when hitting the LocalAI front page: 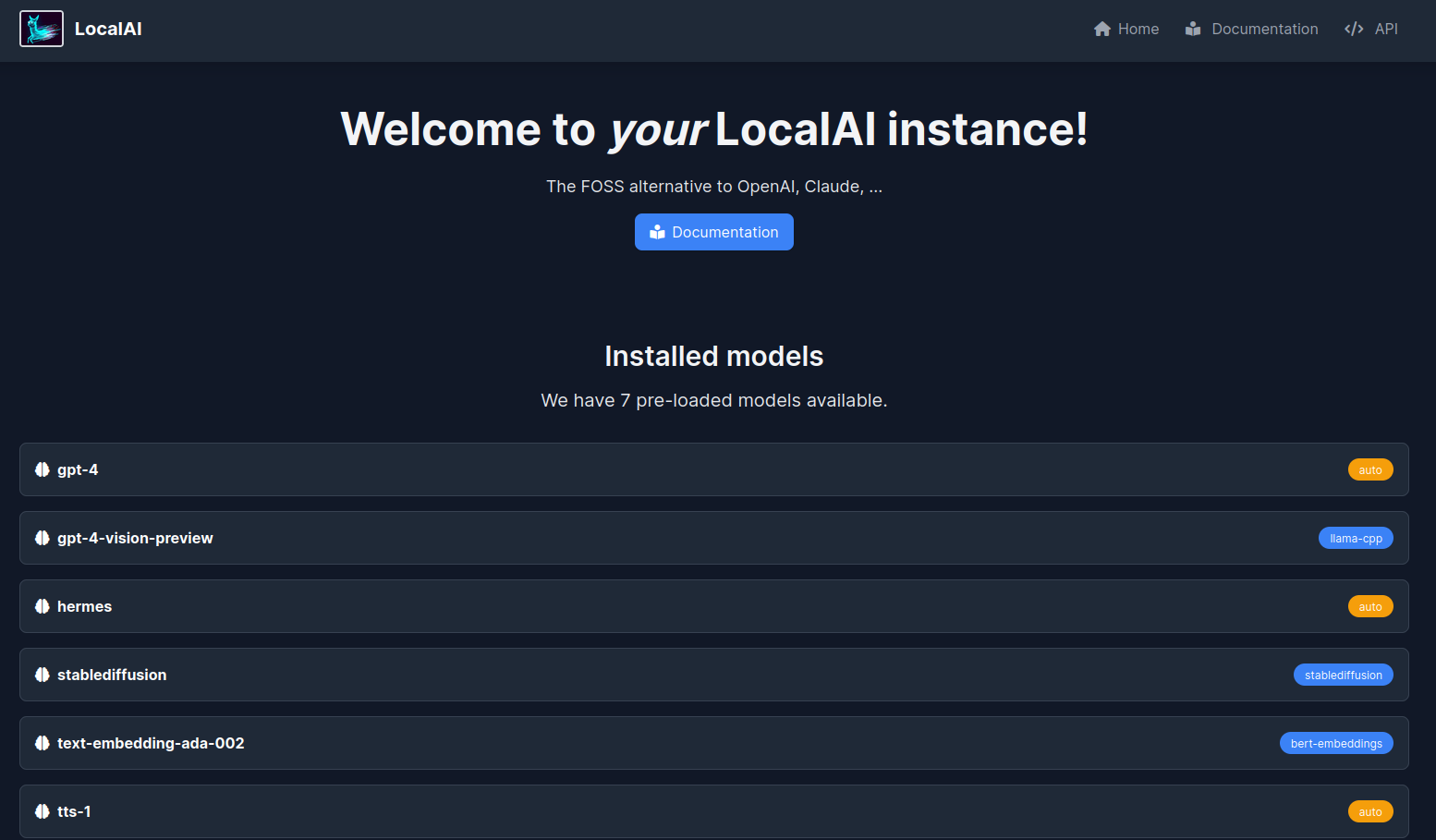 You can also now enjoy Swagger to try out the API calls directly: 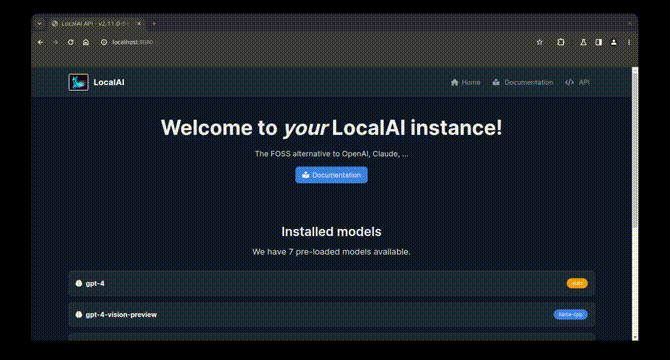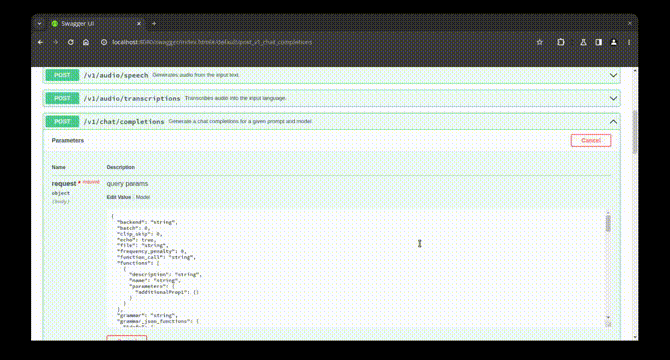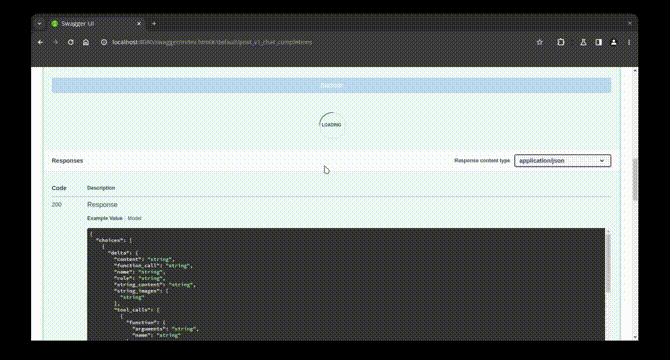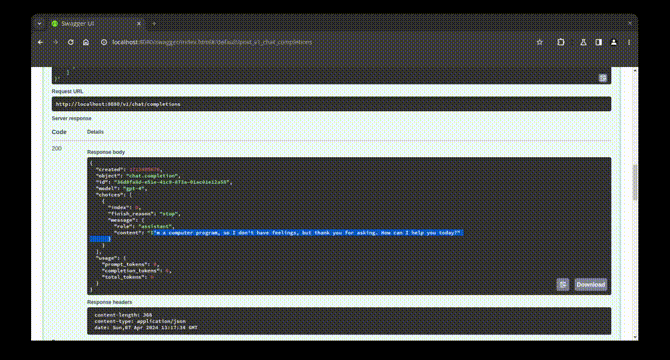 ##### 🌈 AIO images changes Now the default model for CPU images is https://huggingface.co/NousResearch/Hermes-2-Pro-Mistral-7B-GGUF - pre-configured for functions and tools API support! If you are an Intel-GPU owner, the Intel profile for AIO images is now available too! ##### 🚀 OpenVINO and transformers enhancements Now there is support for OpenVINO and transformers got token streaming support now thanks to [@​fakezeta](https://togithub.com/fakezeta)! To try OpenVINO, you can use the example available in the documentation: https://localai.io/features/text-generation/#examples ##### 🎈 Lot of small improvements behind the scenes! Thanks for our outstanding community, we have enhanced several areas: - The build time of LocalAI was speed up significantly! thanks to [@​cryptk](https://togithub.com/cryptk) for the efforts in enhancing the build system - [@​thiner](https://togithub.com/thiner) worked hardly to get Vision support for AutoGPTQ - ... and much more! see down below for a full list, be sure to star LocalAI and give it a try! ##### 📣 Spread the word! First off, a massive thank you (again!) to each and every one of you who've chipped in to squash bugs and suggest cool new features for LocalAI. Your help, kind words, and brilliant ideas are truly appreciated - more than words can say! And to those of you who've been heros, giving up your own time to help out fellow users on Discord and in our repo, you're absolutely amazing. We couldn't have asked for a better community. Just so you know, LocalAI doesn't have the luxury of big corporate sponsors behind it. It's all us, folks. So, if you've found value in what we're building together and want to keep the momentum going, consider showing your support. A little shoutout on your favorite social platforms using @​LocalAI_OSS and @​mudler_it or joining our sponsors can make a big difference. Also, if you haven't yet joined our Discord, come on over! Here's the link: https://discord.gg/uJAeKSAGDy Every bit of support, every mention, and every star adds up and helps us keep this ship sailing. Let's keep making LocalAI awesome together! Thanks a ton, and here's to more exciting times ahead with LocalAI! ##### What's Changed ##### Bug fixes 🐛 - fix: downgrade torch by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1902 - fix(aio): correctly detect intel systems by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1931 - fix(swagger): do not specify a host by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1930 - fix(tools): correctly render tools response in templates by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1932 - fix(grammar): respect JSONmode and grammar from user input by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1935 - fix(hermes-2-pro-mistral): add stopword for toolcall by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1939 - fix(functions): respect when selected from string by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1940 - fix: use exec in entrypoint scripts to fix signal handling by [@​cryptk](https://togithub.com/cryptk) in [mudler/LocalAI#1943 - fix(hermes-2-pro-mistral): correct stopwords by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1947 - fix(welcome): stable model list by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1949 - fix(ci): manually tag latest images by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1948 - fix(seed): generate random seed per-request if -1 is set by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1952 - fix regression [#​1971](https://togithub.com/mudler/LocalAI/issues/1971) by [@​fakezeta](https://togithub.com/fakezeta) in [mudler/LocalAI#1972 ##### Exciting New Features 🎉 - feat(aio): add intel profile by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1901 - Enhance autogptq backend to support VL models by [@​thiner](https://togithub.com/thiner) in [mudler/LocalAI#1860 - feat(assistant): Assistant and AssistantFiles api by [@​christ66](https://togithub.com/christ66) in [mudler/LocalAI#1803 - feat: Openvino runtime for transformer backend and streaming support for Openvino and CUDA by [@​fakezeta](https://togithub.com/fakezeta) in [mudler/LocalAI#1892 - feat: Token Stream support for Transformer, fix: missing package for OpenVINO by [@​fakezeta](https://togithub.com/fakezeta) in [mudler/LocalAI#1908 - feat(welcome): add simple welcome page by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1912 - fix(build): better CI logging and correct some build failure modes in Makefile by [@​cryptk](https://togithub.com/cryptk) in [mudler/LocalAI#1899 - feat(webui): add partials, show backends associated to models by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1922 - feat(swagger): Add swagger API doc by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1926 - feat(build): adjust number of parallel make jobs by [@​cryptk](https://togithub.com/cryptk) in [mudler/LocalAI#1915 - feat(swagger): update by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1929 - feat: first pass at improving logging by [@​cryptk](https://togithub.com/cryptk) in [mudler/LocalAI#1956 - fix(llama.cpp): set better defaults for llama.cpp by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1961 ##### 📖 Documentation and examples - docs(aio-usage): update docs to show examples by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1921 ##### 👒 Dependencies - ⬆️ Update docs version mudler/LocalAI by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1903 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1904 - ⬆️ Update M0Rf30/go-tiny-dream by [@​M0Rf30](https://togithub.com/M0Rf30) in [mudler/LocalAI#1911 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1913 - ⬆️ Update ggerganov/whisper.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1914 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1923 - ⬆️ Update ggerganov/whisper.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1924 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1928 - ⬆️ Update ggerganov/whisper.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1933 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1934 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1937 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1941 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1953 - ⬆️ Update ggerganov/whisper.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1958 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1959 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1964 ##### Other Changes - ⬆️ Update ggerganov/whisper.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1927 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1960 - fix(hermes-2-pro-mistral): correct dashes in template to suppress newlines by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1966 - ⬆️ Update ggerganov/whisper.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1969 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1970 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1973 ##### New Contributors - [@​thiner](https://togithub.com/thiner) made their first contribution in [mudler/LocalAI#1860 **Full Changelog**: mudler/LocalAI@v2.11.0...v2.12.1 ### [`v2.12.0`](https://togithub.com/mudler/LocalAI/releases/tag/v2.12.0) [Compare Source](https://togithub.com/mudler/LocalAI/compare/v2.11.0...v2.12.0) I'm happy to announce the v2.12.0 LocalAI release is out! ##### 🌠 Landing page and Swagger Ever wondered what to do after LocalAI is up and running? Integration with a simple web interface has been started, and you can see now a landing page when hitting the LocalAI front page:  You can also now enjoy Swagger to try out the API calls directly:  ##### 🌈 AIO images changes Now the default model for CPU images is https://huggingface.co/NousResearch/Hermes-2-Pro-Mistral-7B-GGUF - pre-configured for functions and tools API support! If you are an Intel-GPU owner, the Intel profile for AIO images is now available too! ##### 🚀 OpenVINO and transformers enhancements Now there is support for OpenVINO and transformers got token streaming support now thanks to [@​fakezeta](https://togithub.com/fakezeta)! To try OpenVINO, you can use the example available in the documentation: https://localai.io/features/text-generation/#examples ##### 🎈 Lot of small improvements behind the scenes! Thanks for our outstanding community, we have enhanced several areas: - The build time of LocalAI was speed up significantly! thanks to [@​cryptk](https://togithub.com/cryptk) for the efforts in enhancing the build system - [@​thiner](https://togithub.com/thiner) worked hardly to get Vision support for AutoGPTQ - ... and much more! see down below for a full list, be sure to star LocalAI and give it a try! ##### 📣 Spread the word! First off, a massive thank you (again!) to each and every one of you who've chipped in to squash bugs and suggest cool new features for LocalAI. Your help, kind words, and brilliant ideas are truly appreciated - more than words can say! And to those of you who've been heros, giving up your own time to help out fellow users on Discord and in our repo, you're absolutely amazing. We couldn't have asked for a better community. Just so you know, LocalAI doesn't have the luxury of big corporate sponsors behind it. It's all us, folks. So, if you've found value in what we're building together and want to keep the momentum going, consider showing your support. A little shoutout on your favorite social platforms using @​LocalAI_OSS and @​mudler_it or joining our sponsors can make a big difference. Also, if you haven't yet joined our Discord, come on over! Here's the link: https://discord.gg/uJAeKSAGDy Every bit of support, every mention, and every star adds up and helps us keep this ship sailing. Let's keep making LocalAI awesome together! Thanks a ton, and here's to more exciting times ahead with LocalAI! ##### What's Changed ##### Bug fixes 🐛 - fix: downgrade torch by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1902 - fix(aio): correctly detect intel systems by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1931 - fix(swagger): do not specify a host by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1930 - fix(tools): correctly render tools response in templates by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1932 - fix(grammar): respect JSONmode and grammar from user input by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1935 - fix(hermes-2-pro-mistral): add stopword for toolcall by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1939 - fix(functions): respect when selected from string by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1940 - fix: use exec in entrypoint scripts to fix signal handling by [@​cryptk](https://togithub.com/cryptk) in [mudler/LocalAI#1943 - fix(hermes-2-pro-mistral): correct stopwords by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1947 - fix(welcome): stable model list by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1949 - fix(ci): manually tag latest images by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1948 - fix(seed): generate random seed per-request if -1 is set by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1952 - fix regression [#​1971](https://togithub.com/mudler/LocalAI/issues/1971) by [@​fakezeta](https://togithub.com/fakezeta) in [mudler/LocalAI#1972 ##### Exciting New Features 🎉 - feat(aio): add intel profile by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1901 - Enhance autogptq backend to support VL models by [@​thiner](https://togithub.com/thiner) in [mudler/LocalAI#1860 - feat(assistant): Assistant and AssistantFiles api by [@​christ66](https://togithub.com/christ66) in [mudler/LocalAI#1803 - feat: Openvino runtime for transformer backend and streaming support for Openvino and CUDA by [@​fakezeta](https://togithub.com/fakezeta) in [mudler/LocalAI#1892 - feat: Token Stream support for Transformer, fix: missing package for OpenVINO by [@​fakezeta](https://togithub.com/fakezeta) in [mudler/LocalAI#1908 - feat(welcome): add simple welcome page by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1912 - fix(build): better CI logging and correct some build failure modes in Makefile by [@​cryptk](https://togithub.com/cryptk) in [mudler/LocalAI#1899 - feat(webui): add partials, show backends associated to models by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1922 - feat(swagger): Add swagger API doc by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1926 - feat(build): adjust number of parallel make jobs by [@​cryptk](https://togithub.com/cryptk) in [mudler/LocalAI#1915 - feat(swagger): update by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1929 - feat: first pass at improving logging by [@​cryptk](https://togithub.com/cryptk) in [mudler/LocalAI#1956 - fix(llama.cpp): set better defaults for llama.cpp by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1961 ##### 📖 Documentation and examples - docs(aio-usage): update docs to show examples by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1921 ##### 👒 Dependencies - ⬆️ Update docs version mudler/LocalAI by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1903 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1904 - ⬆️ Update M0Rf30/go-tiny-dream by [@​M0Rf30](https://togithub.com/M0Rf30) in [mudler/LocalAI#1911 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1913 - ⬆️ Update ggerganov/whisper.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1914 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1923 - ⬆️ Update ggerganov/whisper.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1924 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1928 - ⬆️ Update ggerganov/whisper.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1933 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1934 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1937 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1941 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1953 - ⬆️ Update ggerganov/whisper.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1958 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1959 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1964 ##### Other Changes - ⬆️ Update ggerganov/whisper.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1927 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1960 - fix(hermes-2-pro-mistral): correct dashes in template to suppress newlines by [@​mudler](https://togithub.com/mudler) in [mudler/LocalAI#1966 - ⬆️ Update ggerganov/whisper.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1969 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1970 - ⬆️ Update ggerganov/llama.cpp by [@​localai-bot](https://togithub.com/localai-bot) in [mudler/LocalAI#1973 ##### New Contributors - [@​thiner](https://togithub.com/thiner) made their first contribution in [mudler/LocalAI#1860 **Full Changelog**: mudler/LocalAI@v2.11.0...v2.12.0 </details> --- ### Configuration 📅 **Schedule**: Branch creation - At any time (no schedule defined), Automerge - At any time (no schedule defined). 🚦 **Automerge**: Enabled. ♻ **Rebasing**: Whenever PR becomes conflicted, or you tick the rebase/retry checkbox. 🔕 **Ignore**: Close this PR and you won't be reminded about these updates again. --- - [ ] <!-- rebase-check -->If you want to rebase/retry this PR, check this box --- This PR has been generated by [Renovate Bot](https://togithub.com/renovatebot/renovate). <!--renovate-debug:eyJjcmVhdGVkSW5WZXIiOiIzNy4yODEuMiIsInVwZGF0ZWRJblZlciI6IjM3LjI4MS4yIiwidGFyZ2V0QnJhbmNoIjoibWFzdGVyIiwibGFiZWxzIjpbImF1dG9tZXJnZSIsInVwZGF0ZS9kb2NrZXIvZ2VuZXJhbC9ub24tbWFqb3IiXX0=-->
Description
Due to prompt template incompatible with current prompt processing flow, I removed support for
internlm/internlm-xcomposer2-vl-7b-4bitin this PR. I may add the support in a separate PR.This PR fixes #1812, and enhanced AutoGPTQ to support
Qwen/Qwen-VL-Chat-Int4andmodels.internlm/internlm-xcomposer2-vl-7b-4bitThe AutoGPTQ version is updated tov0.7.1, and enablesuse_marlinflag forinternlm/internlm-xcomposer2-vl-7b-4bitby default. Please make sure you have the correct model in place. Ref: https://github.com/IST-DASLab/marlinNotes for Reviewers
Signed commits