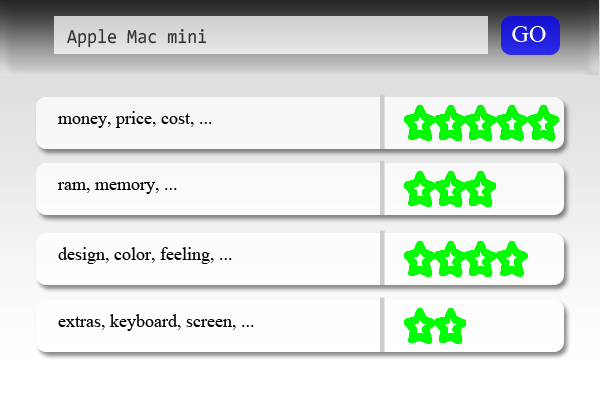
Reviews on review websites like Yelp and Zomato are accompanied by a subjective score which is often not sufficient to understand the review completely. Mining opinions from reviews about specific entities and their aspects can help consumers decide what to purchase and businesses to better monitor their reputation and understand the needs of the market. Our work aims to provide a framework to decompose the review score into various aspects and as- sign them individual scores, for which we aim to use a CNN model (from the ACL'18 paper") with some modifications followed by clustering and sentiment analysis.
To come up with such an aspect-sentiment table for a product:
{kind=link}
{kind=link}
Our model is implemented in two stages:
- Aspect Extraction
- Aspect Categorization and Sentiment Analysis
Given a review, we summarize it by outputting polarities of particular fixed aspects. For example, for this review:
It’s a nice place to relax and have conversation..But the food was okay, nothing great,
the model should output
{AMBIENCE: Positive, FOOD: Negative, SER- VICE: Neutral}
All code are tested under python 3.6.2 + pytorch 0.2.0_4
Step 1: Download general embeddings (GloVe: http://nlp.stanford.edu/data/glove.840B.300d.zip ), save it in data/embedding/gen.vec
Step 2: Download Domain Embeddings (You can find the link under this paper's title in https://www.cs.uic.edu/~hxu/ ), save them in data/embedding
Step 3: Download and install fastText (https://github.com/facebookresearch/fastText) to fastText/
Step 4: Download official datasets to data/official_data/
Download official evaluation scripts to script/
We assume the following file names:
SemEval 2014 Laptop (http://alt.qcri.org/semeval2014/task4/):
data/official_data/Laptops_Test_Data_PhaseA.xml
data/official_data/Laptops_Test_Gold.xml
SemEval 2016 Restaurant (http://alt.qcri.org/semeval2016/task5/)
data/official_data/EN_REST_SB1_TEST.xml.A
data/official_data/EN_REST_SB1_TEST.xml.gold
-
To improve quality of embeddings
- Using ELMO trained on the in-domain data to improve fastText embeddings
-
Architectural Changes
- Using LSTMs in the penultimate layer
- Loss decreasing, but f-1 score also decreasing
- Using GRU in final layer
- Similar results as the baseline model
- Using CRF instead of softmax
- Slightly worse performance
- Tried various pooling functions in the baseline CNN model
- Using LSTMs in the penultimate layer
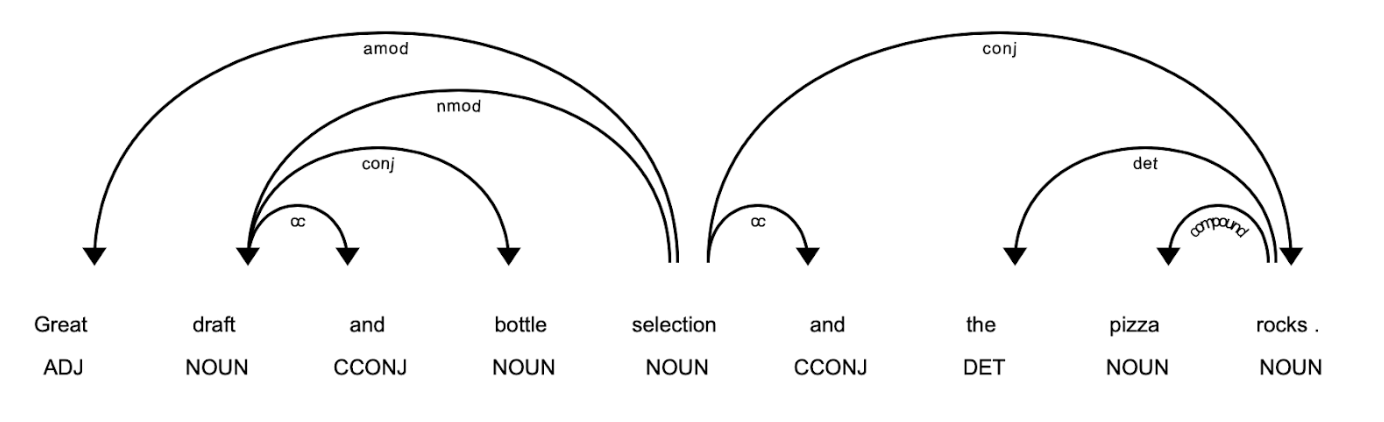
- Aspect words - no inherent sentiment (e.g. pizza)
- Have to look for the correct modifier words / sentence chunks (not always adjectival)
- Came up with a rule-based system based on dependency parse trees
- Used vader sentiment
- Outputs a polarity score for sentence as a whole
- Eg: The pizza was good but the paneer sucked.
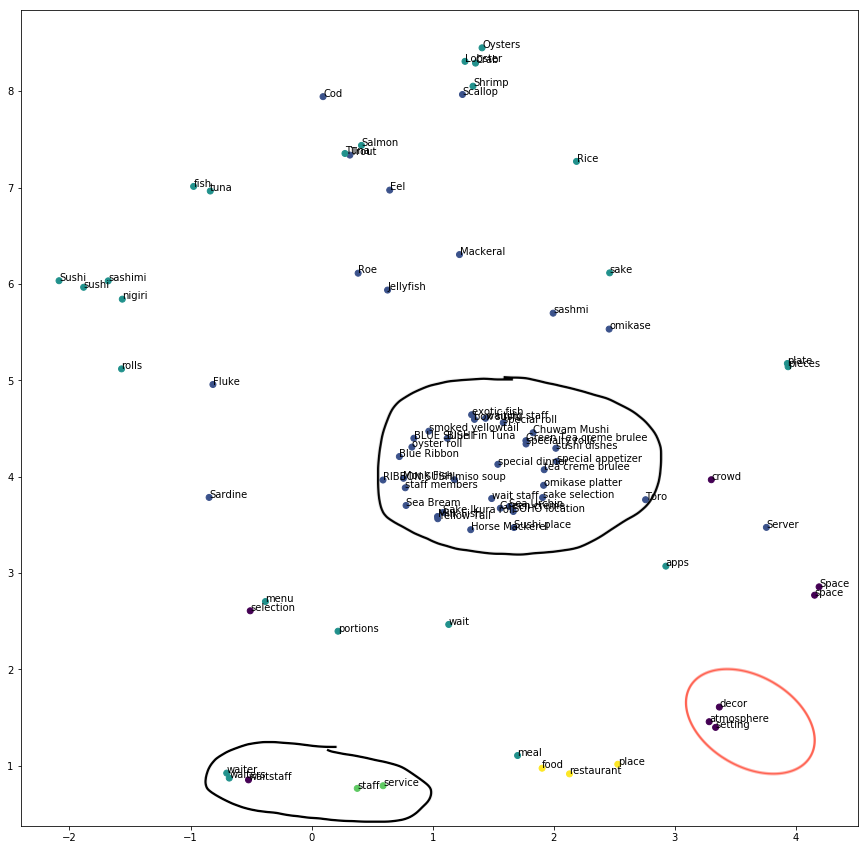
- We used a concatenation of general-purpose and domain-specific embeddings and tried to cluster them using kmeans, dbscan, optics
- Tried semi-supervised clustering by providing seeds to kmeans
- For aspects that were phrases:
- Tried max, sum, avg of constituent word vectors
- Tried normalizing the word vectors
Evaluation Metric: Qualitative observation of the clusters
Observations:
- Sum -> caused clustering together of longer aspects
- Avg -> reduced cluster quality
- Normalizing and element-wise max of embeddings improved cluster quality
author = {Xu, Hu and Liu, Bing and Shu, Lei and Yu, Philip S.},
title = {Double Embeddings and CNN-based Sequence Labeling for Aspect Extraction},
booktitle = {Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics},
publisher = {Association for Computational Linguistics},
year = {2018}
}```