Architecture
This section describes the internal architecture of OpenCGA and the main ideas about how it has been implemented. If you want to collaborate with the project, this is the place to start reading! :)
For a data file (containing variants or alignments) to be submitted, it must be accompanied by a metadata/configuration file. In order to keep memory under control, the data file entries are read in batches of a few thousand lines. The flowchart below represents how a variants file is processed.
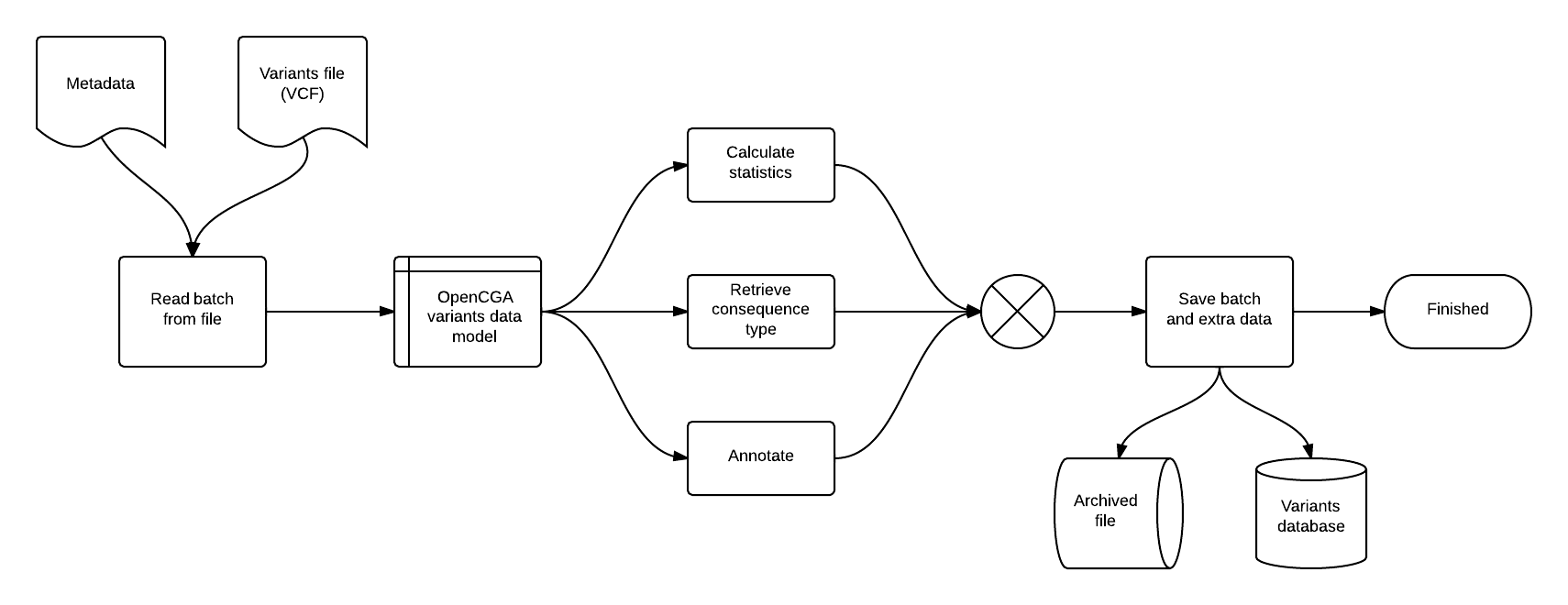
After reading a batch of lines, these are transformed into our file-format agnostic data model. Then variants can be annotated with their consequence type, gene name or some statistics. This information is added to the data model and saved to the corresponding database.
In order to keep memory usage under control, input files are processed and stored in batches of some thousands of variants. Since the process can fail in any batch, a mechanism for fault tolerance and rollback is necessary.
Failures can occur both while inserting raw data in HBase and creating "indexes" in Mongo. When the insertion of a variant fails the system will retry (note: there could be an argument for configuring this feature).
If the system can't recover from the failure after several tries, the whole operation must be rollbacked. It is necessary to know which registers have been inserted up to that moment, so an entry must be written to a log file every time a register is successfully stored in the database.