Add messages to node's status card #5050
Conversation
 rawagner
commented
rawagner
commented
Apr 15, 2020
•

fba9b25
to
8578428
Compare
There was a problem hiding this comment.
Looking good!
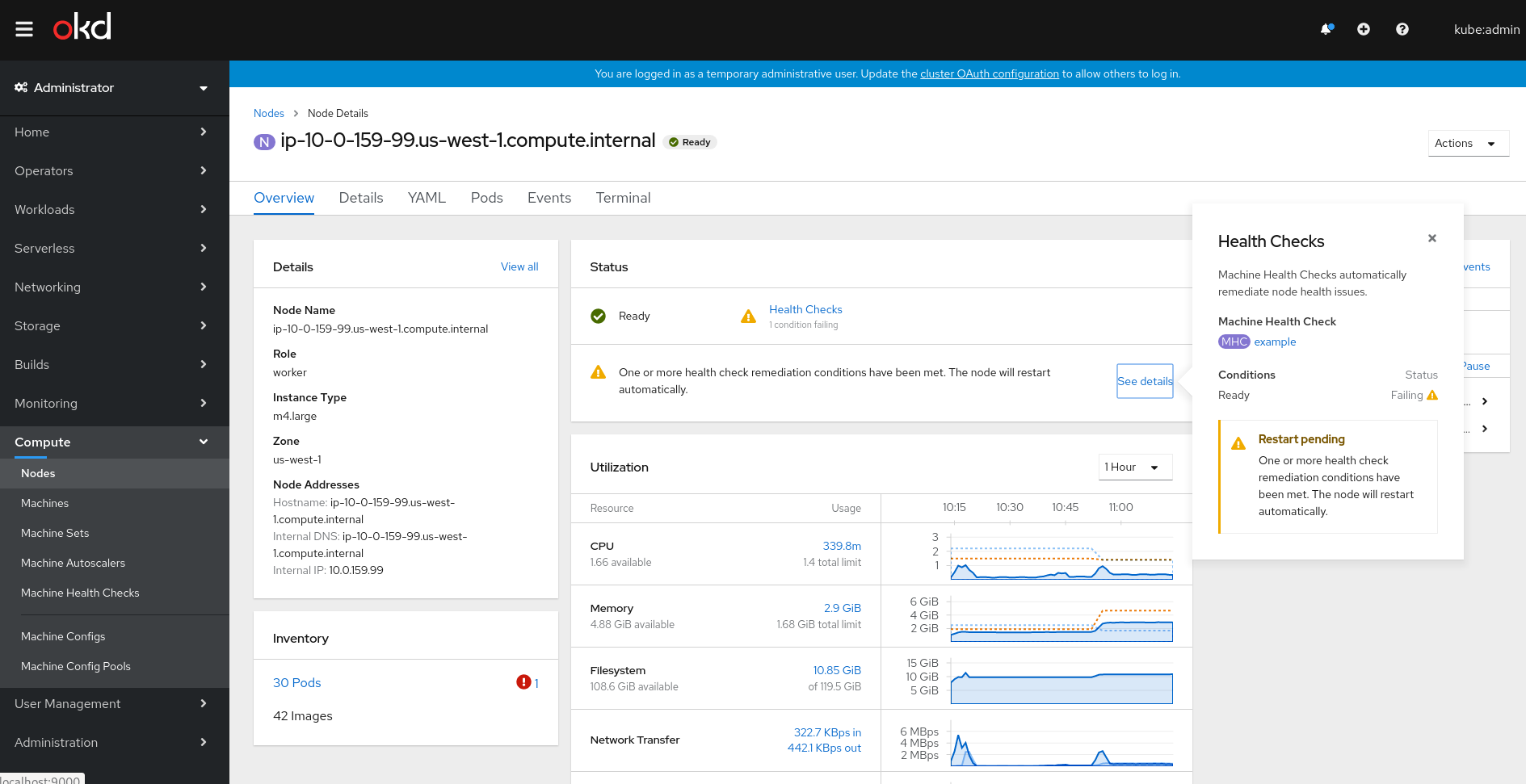
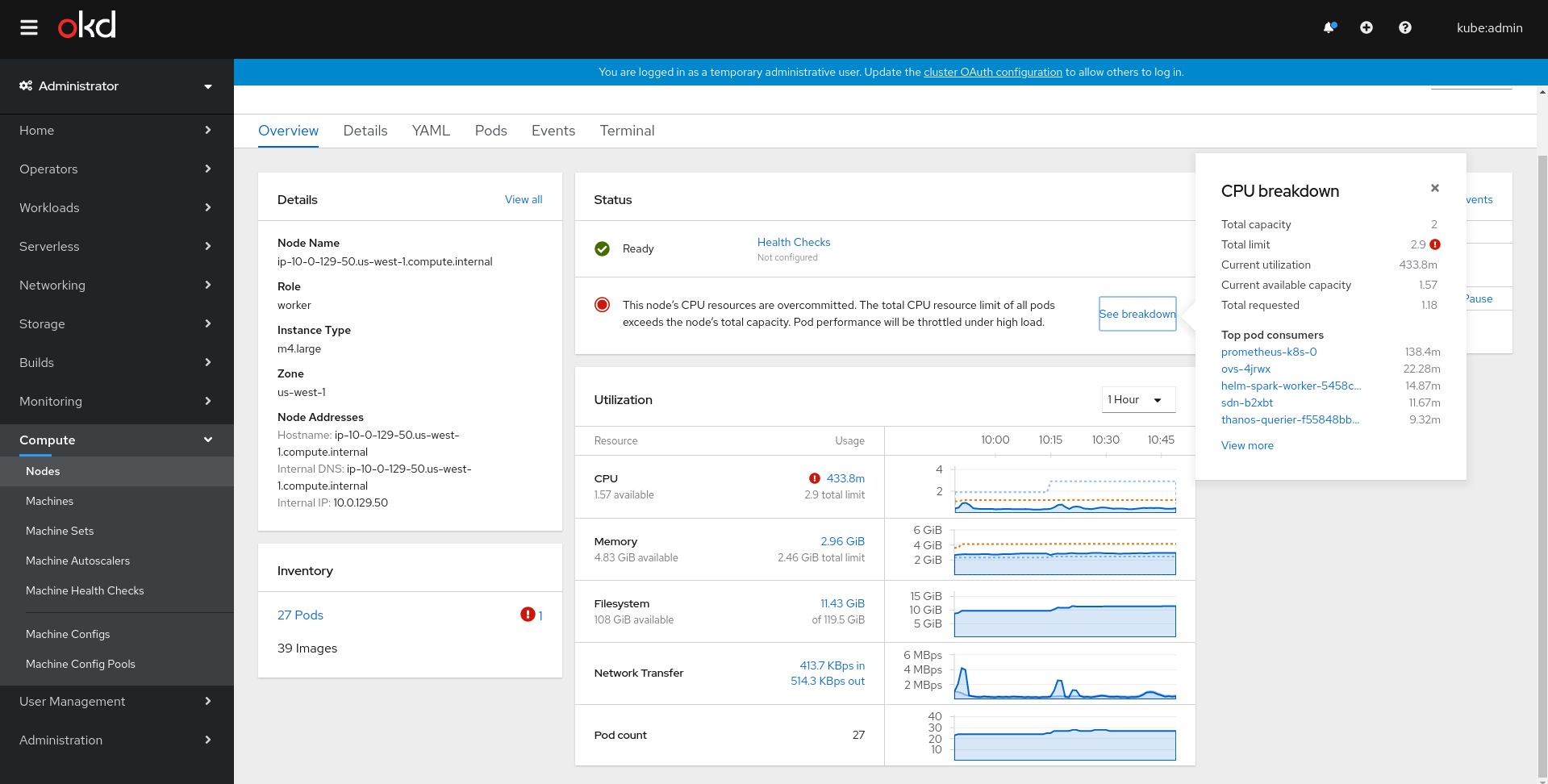
- Could we add unit labels to the top area of the breakdown popover? There could be a mix of
m(millicores) andcoresthere, so writing those units out would be clearer. - The second screenshot shows "total requested" being
5.5(cores), but the node's "total capacity" is only4(cores). Reading the docs, it seems like the pod scheduler wouldn't/shouldn't allow the total requested to go over the total capacity. Is this just dummy data, a UI bug, or maybe I'm misunderstanding? - The second screenshot also has a red state in the Utilization card but a yellow state in the Status card. I think the two should match, and assuming the
5.5requested is just dummy data or a bug, that would mean the Utilization card would be yellow as well (for the total limit being3.9). The third screenshot seems correct though.
| 'The total CPU requested by all pods on this node is approaching the node’s capacity. New pods may not be schedulable on this node.'; | ||
|
|
||
| export const MEM_LIMIT_REQ_ERROR = | ||
| 'This node’s memory resources are overcommitted. The total memory resource limit of all pods exceeds the node’s total capacity. The total memory requested is also approaching the node’s capacity. Pods will be terminated under high load, and new pods may not be schedulable on this node'; |
There was a problem hiding this comment.
| 'This node’s memory resources are overcommitted. The total memory resource limit of all pods exceeds the node’s total capacity. The total memory requested is also approaching the node’s capacity. Pods will be terminated under high load, and new pods may not be schedulable on this node'; | |
| 'This node’s memory resources are overcommitted. The total memory resource limit of all pods exceeds the node’s total capacity. The total memory requested is also approaching the node’s capacity. Pods will be terminated under high load, and new pods may not be schedulable on this node.'; |
I forgot a period, oops. 😄
Would be good to have this implemented console-wide. But we still havent done it. I could take a look but until then I think we should just stick with what console uses now (no units for cores, m for milicores)
@kyoto @openshift/openshift-team-monitoring I see all masters having higher requests than capacity. Not happening on workers though.
No dummy data, will fix that - if requests are over 100% we will show red state in status card too. I think we will need to update the messages if the query is correct and requests can go over 100% |
8578428
to
43f5afe
Compare
|
/hold |
43f5afe
to
41c042b
Compare
41c042b
to
ef1aa8b
Compare
|
/hold cancel |
|
/retest |
Is for sure the wrong query as it includes completed, pending, failed, Pods. This precisely proves my point on the other PR of not reusing queries that have been hardened over the year, but instead re-inventing. |
|
/lgtm |
1a30fc5
to
cd53a3d
Compare
|
After reading kubernetes/kube-state-metrics#1051 I've updated the requests/limits queries based on https://github.com/kubernetes-monitoring/kubernetes-mixin/blob/8e370046348970ac68bd0fcfd5a15184a6cbdf51/rules/apps.libsonnet#L64-L75 and hopefully didnt mess up. @brancz |
cd53a3d
to
f6123f6
Compare
|
/lgtm |
|
[APPROVALNOTIFIER] This PR is APPROVED This pull-request has been approved by: jtomasek, rawagner The full list of commands accepted by this bot can be found here. The pull request process is described here
Needs approval from an approver in each of these files:
Approvers can indicate their approval by writing |
|
/retest |
2 similar comments
|
/retest |
|
/retest |
|
/hold |
|
/hold cancel |