Releases: openzipkin/zipkin
Zipkin 2.22.1
Zipkin 2.22.1 starts publishing multi-architecture Docker images, also to GitHub Container Registry.
Most of this effort is to help end users avoid Docker Hub pull rate limits that apply November 1st.
If you want to change your build or deployment process to use a non rate-limited image, it is as easy as this:
-docker run -d -p 9411:9411 openzipkin/zipkin-slim
+docker run -d -p 9411:9411 ghcr.io/openzipkin/zipkin-slimOpenZipkin are a volunteer team. The work done here came in service to you and traded off days, evenings and weekends to deliver on time. If you are happy with the help you've had these last over 5 years, please ensure you've starred our repo or drop by to say thanks on gitter.
If you have time to help us continue to serve others, please stop by on gitter with a suggestion of what you'd like to help with or a request for what might be a neat way to start. Our community has grown a lot over the years, but it is always in need of more hands!
Multi-architecture Docker images
Zipkin's Docker image is now available for arm64 architecture. This eases Raspberry Pi (RPI) K8s deployment and Amazon EKS on AWS Graviton2 as you no longer have to build your own image. This also enables users who use Zipkin in their build pipeline to be unblocked from switching to arm64.
Zipkin's server is written in Java, and hosts web assets run in a client's browser. White there are a few optional native optimizations at the Netty (I/O) layer, it has no operating system or architecture restrictions. That said, a significant amount of our user base use our Docker images. These users are restricted to our OS and architecture choices, as manifest in the Docker build. To allow arm64 was a bigger change than it seemed. We use Alpine Linux and our JDK distribution had to change because Zulu (or former choice) didn't support arm64. Also, publishing multi-architecture seems simple, but it is definitely more complicated, especially on developer laptops. We had to perform significant build work, including use of buildx and qemu to emulate arm64 when not running it. Many thanks to the lead @adrianfcole and advice by @dmfrey, @odidev and @anuraaga.
While users can now use arm64, our job isn't quite over. We also want to run our own build on Arm64! This allows us to do integration tests. While we surmounted some hurdles running our NPM build on Alpine, but @odidev noticed a blocker on [Cassandra](https://issues.apache.org/jira/browse/CASSANDRA-16212#]. After that, we'd still need to update our GitHub actions and Travis jobs to use the arch (ex for pull requests). If you are interested in this and can lend a hand, please say so on this issue.
We now publish our Docker images to both Docker Hub and GitHub Container Registry
Zipkin is a technology often integrated into other stacks. We've always been conscious about our impacts here. Apart from optional storage and messaging transports, we've never required a multi-image deployment even when Zipkin is run in different roles. This has helped you download (docker pull) less often.
We also made the lower overhead "openzipkin/zipkin-slim" image, as well test Kafka and storage images which share layers. Our base layer uses a custom "jlinked" JRE image which is less than 100MB. We almost famously guard any changes to the server that would bloat anything. We aren't done, but our volunteers have put immense effort on your behalf to keep you pulling less and less often.
Many open source developers were nervous for good reason about Docker Hub's usage policy starting November 1st. This implies three things for open source developers using Docker Hub (ex. docker pull openzipkin/zipkin).
- you likely have to authenticate now
- you are restricted to 200 pulls per 6hrs
- images you make that aren't pulled in 6 months will (eventually) be purged
The first point impacts people's pipelines. In any open community authenticating can be a pain. Using personal credentials for community work can feel conflicted. The second point is more dire. Many are simply not aware how often the pull from Docker Hub!
For example, OpenZipkin community defines "latest", the default tag, as "latest release" meaning that if you run docker pull openzipkin/zipkin, it will only consume your pull request quota if you are rebuilding your image cache, or we released a new version. While we release new versions somewhat often, it isn't enough to worry about. However, many projects treat "latest" as every commit. This means depending on what image you depend on, it could change more than once per hour. To run tests in some projects require pulling such images. To amplify this, some developers volunteer time on many projects. The amplification of these factors means that a volunteer making no money at all can become forced into a subscription to pay for the privilege to do that.
The final point on retention is also tricky. Many expect images to never disappear. While we always want people to upgrade, we don't want people to be surprised that something they've cached in house for a while cannot be rebuilt.
OpenZipkin is and will always be free in spirit and practice. We will not force our volunteers or end users into any subscription. To address this issue quickly, we decided to publish images also to GitHub Container Registry. This is currently free and not rate-limited on consumption. If that changes, we will publish issues also to another registry :P
For those reading this and wondering what this means, it means the following. Our primary source of images is now here. The top-level images, including our server and test backends are also pushed to Docker Hub for convenience.
If you want to change your build or deployment process to use a non rate-limited image, it is as easy as this:
-docker run -d -p 9411:9411 openzipkin/zipkin-slim
+docker run -d -p 9411:9411 ghcr.io/openzipkin/zipkin-slimThe full impact of this required a lot of change to our build process, even if GitHub Container Registry is pretty easy. For example, to set descriptions there, we had to add some standard labels to our images. While we were at it, we added more labels:
docker inspect --format='{{json .Config.Labels}}' ghcr.io/openzipkin/zipkin-slim|jq
{
"alpine-version": "3.12.1",
"java-version": "15.0.1_p9",
"maintainer": "OpenZipkin https://gitter.im/openzipkin/zipkin",
"org.opencontainers.image.authors": "OpenZipkin https://gitter.im/openzipkin/zipkin",
"org.opencontainers.image.description": "Zipkin slim distribution on OpenJDK and Alpine Linux",
"org.opencontainers.image.source": "https://github.com/openzipkin/zipkin",
"org.opencontainers.image.version": "2.22.1",
"zipkin-version": "2.22.1"
}This process was a lot of work and we thank @adriancole for the bulk of it. However, it was not possible without team input, particularly credential management and other knowledge sharing to make practice sustainable. Thanks also to @anuraaga @jorgheymans @jcchavezs and @abesto for inputs and review.
Zipkin 2.22
Zipkin 2.22 includes major improvements to the UI and Cassandra storage. It deprecates the v1 "cassandra" storage type, for the more modern "cassandra3" used for the last 2 years.
Before we dive into features, we'd like to thank folks who are less often thanked. People whose impacts aren't always spectacular new features, but without which nothing would really work well.
Features deliver while others need support. Our MVP @jorgheymans closed out over 60 issues since last release, while also doing a great amount of support on gitter. In cases change wasn't appropriate, you've noticed personal and thoughtful summaries. Jorg's work is a great example of community championship and we are grateful for his help.
Features also require attention. Code review makes contributors feel less alone and the resulting change better. @anuraaga has reviewed over 80 pull requests since our last minor release. Especially UI code can feel alone sometimes, and Rag's thoughtful feedback on code has clearly helped @tacigar deliver more of it.
Features need partnership. Zipkin's server, Elasticsearch and Stackdriver implementations are written in Armeria and @minwoox is our Armeria MVP. Min-Woo owned migration of Zipkin to Armeria 1.0 and again to 1.2, including glitches and experience improvements. Often these changes requires several rounds to polish and releases to coordinate. The only way this all worked was Min-Woo's ownership in both Armeria and our use of it.
Features need good advice. We'd finally like to thank @xeraa from Elasticsearch, @adutra and @olim7t from Datastax, and @jeqo from Confluent. We've updated quite a lot of code that required expert insight into how backends work, or our use of their drivers, and roadmap items. Jorge has been particularly applied in this, developing features in Kafka that would allow better storage implementation. All these folks are excellent stewards and gave heaps of advice to help keep us on the right path, which in turn keeps implementations relevant for you.
Let's now get on to some notable features in Zipkin 2.22
UI improvements
@tacigar led another great round of visible and invisible improvements to Zipkin's UI, Lens.
The first thing you will notice is a renovated sidebar and header design. Controls and links moved to the top of the display, revealing significantly more white space below. Brighter text and a while underline hints subtly which screen you are on, leaving your attention for the results below it:

The search controls are redesigned for effortless transitions between mouse and keyboard, or no mouse at all. Here's a search sequence using only the keyboard to execute a search.

Settings such as how far to look back and the time range have been tucked away neatly to reserve space. Don't worry though, all features are still around!

Those interested in underneath will appreciate the migration to TypeScript, redux and react-use, which reduced the code involved and increased the quality. There are more features in store, such as how to better render span counts. Please help Igarashi-san and the team by providing your feedback. It matters and makes UI development less lonely!
Cassandra
Over two years ago @michaelsembwever designed and @llinder co-implemented the "cassandra3" storage type. This writes data natively in Zipkin v2 format, reducing translation overhead and improving CQL experience. This requires a minimum version of Cassandra 3.11.3, released over two years ago. We deprecated the "cassandra" storage type, otherwise known as "Cassandra v1", for removal in Zipkin 2.23.
We hope you understand that limited resource means making hard decisions, and we don't take this lightly. However, we do feel two years is enough time to settle and please do contact us if you have concerns on gitter.
Meanwhile we've overhauled the code so that we can use the more modern Datastax Driver v4. This came with thanks to @adutra and @olim7t who gave months of advice during the process. The good news is this puts us in a good place to focus on new features as Cassandra 4 readies for prime time.
Docker
All Zipkin images now have HEALTHCHECK instructions, which can be used in Docker natively or in readiness probes. We switched from Distroless back to Alpine to reduce image heft further. Zipkin 2.22 images run on the very latest: JRE 15 patch 1. We overhauled our docker-compose examples as well added a new repository of Java based examples. If you'd like to perform similar for other languages, please volunteer on gitter!
Other news
There are too many changes to detail all the last six months, but here's a summary of impactful ones to end users:
- @ccharnkij added support for ES 7.8 composeable templates (with support by @xeraa!)
- @fredy-virguez-adl made the UI show multi-line tags
- @ronniekk corrected our docker health check
- @anuraaga added Dev Tools instructions for UI development.
- @jorgheymans added instructions on how to enable TLS on the server.
- @jorgheymans added docs on Elasticsearch data retention
- @jorgheymans and @jeqo added Kafka operational notes
- @uckyk completed the chinese translation of our UI
- @jeqo upgraded our Kafka drivers to latest version
- @hanahmily made
ES_CREDENTIALS_FILEwork on the slim distribution - @adriancole added
ES_SSL_NO_VERIFYfor test environments
Zipkin 2.21
Zipkin 2.21 Adds an archive trace feature to the UI and dynamic Elasticsearch credentials support
Archive Trace
Sites like Yelp have multiple tiers of storage. One tier includes 100% traces at a short (an hour or less) TTL. Later are normal sampling, either via a rate limit or low percentage. Some sites even have a tier that never expires. In such setups, there is tension. For example, the 100% tier is great for customer support as they can always see traces. However, the traces can expire in the middle of the incident! who wants a dead link?! Even normal trace storage is typically bounded by 3-7 day TTL. This becomes troublesome in issue trackers like Jira as the link is again, not permanent.
This problem is not as simple as it sounds. For example, it might seem correct to add tiering server-side. However, not all storage even support a TTL concept! Plus, multi-tiered storage is significantly more complex to reason with at the code abstraction vs the HTTP abstraction. @drolando from Yelp detailed these pros and cons, as well false starts here.
The ultimate solution by Daniele, and adopted by the Zipkin team in general, was to leverage HTTP as opposed to bind to specific implementation code. In other words, everything is handled in the browser. This allows the archive target to not only be Zipkin, but anything that speaks its format including clones and vendors.
You can now set the following properties to add an "Archive Trace" button"
ZIPKIN_UI_ARCHIVE_POST_URL=https://longterm/api/v2/spans
ZIPKIN_UI_ARCHIVE_URL=https://longterm/zipkin/trace/{traceId}
These are intentionally different as some vendors have a different read back expression than zipkin, even when their POST endpoint is the same.
When you click archive, you'll see a message like below confirming where the trace went, in case you want to copy/paste it into your favorite issue tracker.

Many thanks to @drolando for making this feature a reality, as well @anuraaga @jcchavezs @jeqo @shakuzen and @tacigar who gave feedback that led to the polished end state.
Dynamic Elasticsearch Credentials
Our Elasticsearch storage component has supported properties based changes to credentials since inception. While few knew about it, this didn't imply env variables, as file based always worked. Even with this flexibility, those running a non-buffered transport (like Kafka) would drop data when there's a password change event. This is incidentally routinely the case as HTTP and gRPC are quite common span transports. @basvanbeek noticed that even though the server restarts quickly (seconds or less), this drop is a bad experience. It is becoming commonplace for file-based updates to push out through services like Vault, and the restart gap could be tightened.
@hanahmily stepped in to make reading passwords more dynamic, something pretty incredible to do for a first-time committer! At the end of 2 weeks of revisions, Gao landed a very simple option that covers the requirements, closing the auth-fail gap to under a second.
- ES_CREDENTIALS_FILE: An absolute path of the file.
- ES_CREDENTIALS_REFRESH_INTERVAL: Refresh interval in seconds.
Thanks very much to @anuraaga and @jorgheymans for all the feedback and teamwork to get this together.
Minor changes
- @jorgheymans added instructions for running lens behind a reverse proxy
- @tacigar @anuraaga @drolando fixed a few UI glitches
ES_ENSURE_TEMPLATES=falseis now available for sites who manage Elasticsearch schema offlineZIPKIN_UI_DEPENDENCY_ENABLED=falseis now available for sites who will never run zipkin-dependencies
Zipkin 2.20
Zipkin 2.20 is our first big release of 2020.
Most notably, the Lens UI is now default, retiring the classic UI. This is a big deal for many sites, and your continued feedback is especially important now. Please send any praise, concern or questions to Gitter and add issues as appropriate.
First, let's thank @eirslett and @zeagord for leading the last incarnation of the classic UI. Since @eirslett rewrote the former scala+javascript UI into a single-page, pure javascript 5 years ago, we had 38 contributors. @eirslett set the architecture in place for an order of magnitude more people to become involved, and for a new leader @zeagord to emerge. The classic UI had deceptively simple features, in so far as they are hard to replicate. This is evidenced by so few efforts managing to come close to feature parity, even with a lot of full time staff allocated to the task. Suffice to say, zipkin-classic is a very very good product and has a special place in the history of open source distributed tracing, especially volunteer open source.
Next, let's thank LINE for contributing a new codebase to the project, and further the time of @tacigar to move mountains to push UX forward while simultaneously reaching for feature parity. Along the way, @drolando played MVP of testing, finding all the edge cases in practice at Yelp. Finally, we owe as a community a great thanks to @anuraaga who single-handedly filled all the remaining feature gaps to ensure this release would have the least disruption to you. The last year and a half has not been easy, but we think it has been worth it, as you can now reach a new UI without the trouble of a platform switch.
While we noted MVPs, it is ultimately you, the end users and sites who have been with us years or only days. Please do engage if you have suggestions or contributions to offer. We're only a chat away!
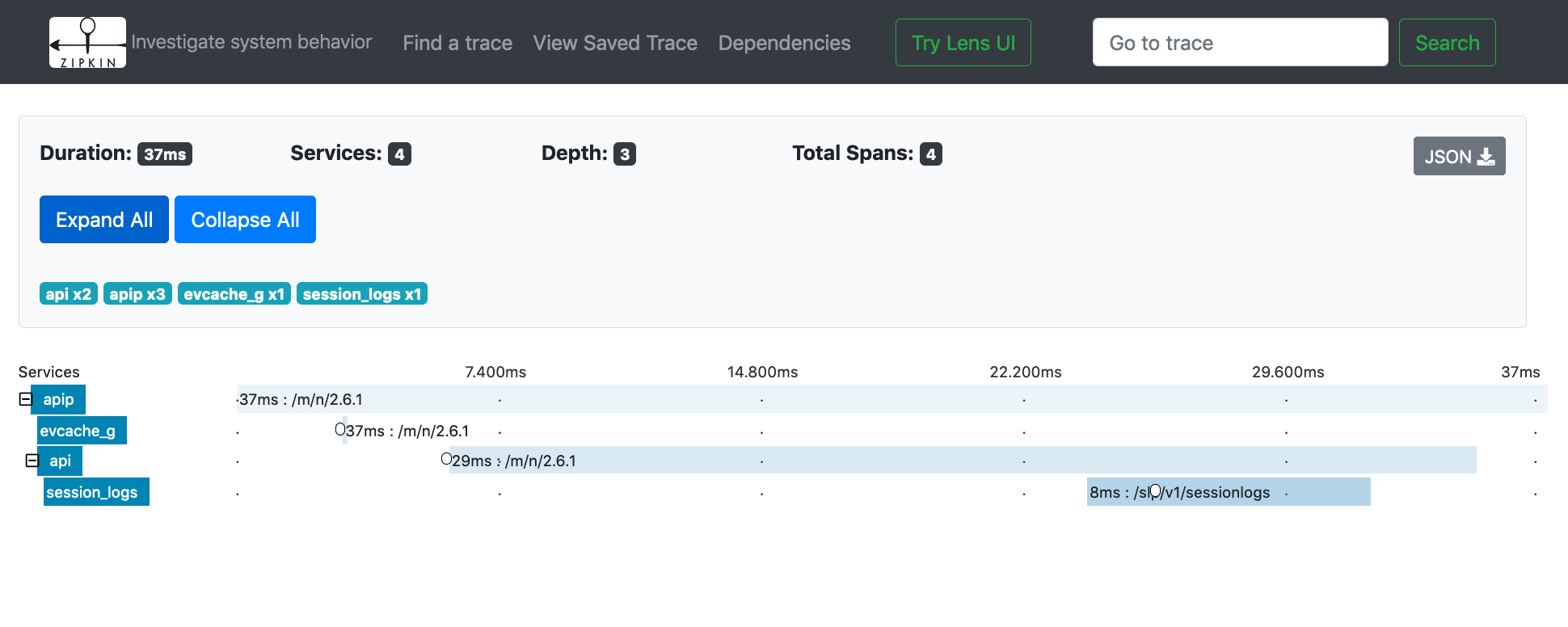
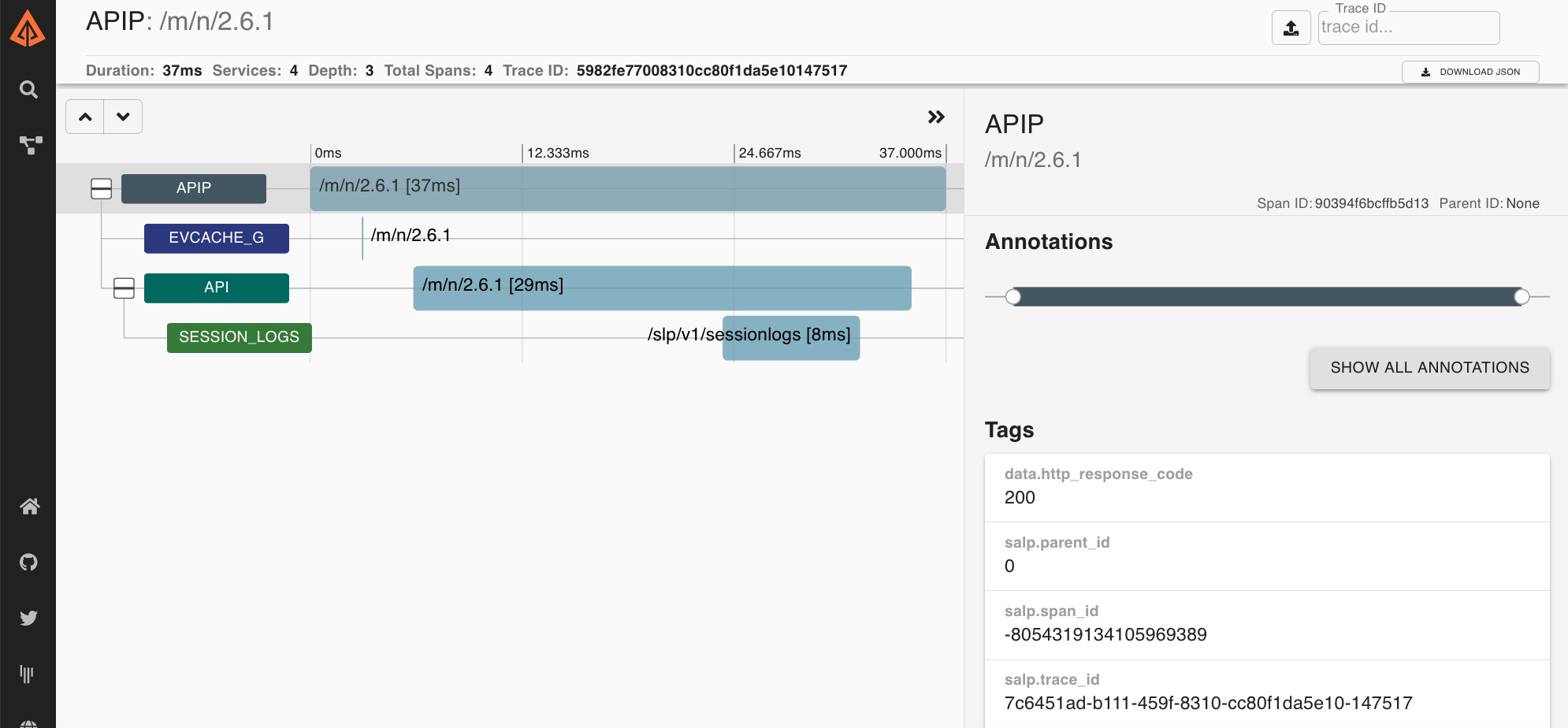
As a finale, let's look at a trace from Netflix from the last version of the classic UI and our new UI Lens. We think you'll agree, they are both good products. Here's to another 5 years!
Classic


Lens


Zipkin 2.19.2
This is a patch release that fixes a regression in handling of certain span names and adds a feature to control server timeout of queries.
Bugfixes
- JSON API response that includes whitespace in names (such as service names) correctly escapes strings #2915
New Features
- The
QUERY_TIMEOUTenvironment variable can be set to a duration string to control how long the server will wait while serving a query (e.g., search for traces) before failing with a timeout. For example, when increasing the client timeout of Elasticsearch withES_TIMEOUTit is often helpful to increaseQUERY_TIMEOUTto a larger number so the server waits longer than the Elasticsearch client. #2809
Zipkin 2.19
Zipkin 2.19 completely revamps the "Lens" UI to help with large traces and large service graphs. This was a large effort with many thanks to @tacigar @bulicekj for coding, @anuraaga @dvkndn and @imballinst reviewing and @drolando on Q/A and prod testing!
Let's dive right in, using test data from SmartThings you can try yourself!
After doing a search, you'll see a result of an elaborate trace. Notice our new logo is here now!

By clicking on this, you can scroll to the span of interest. Notice the annotation and tag details are on a collapsible panel on the right.
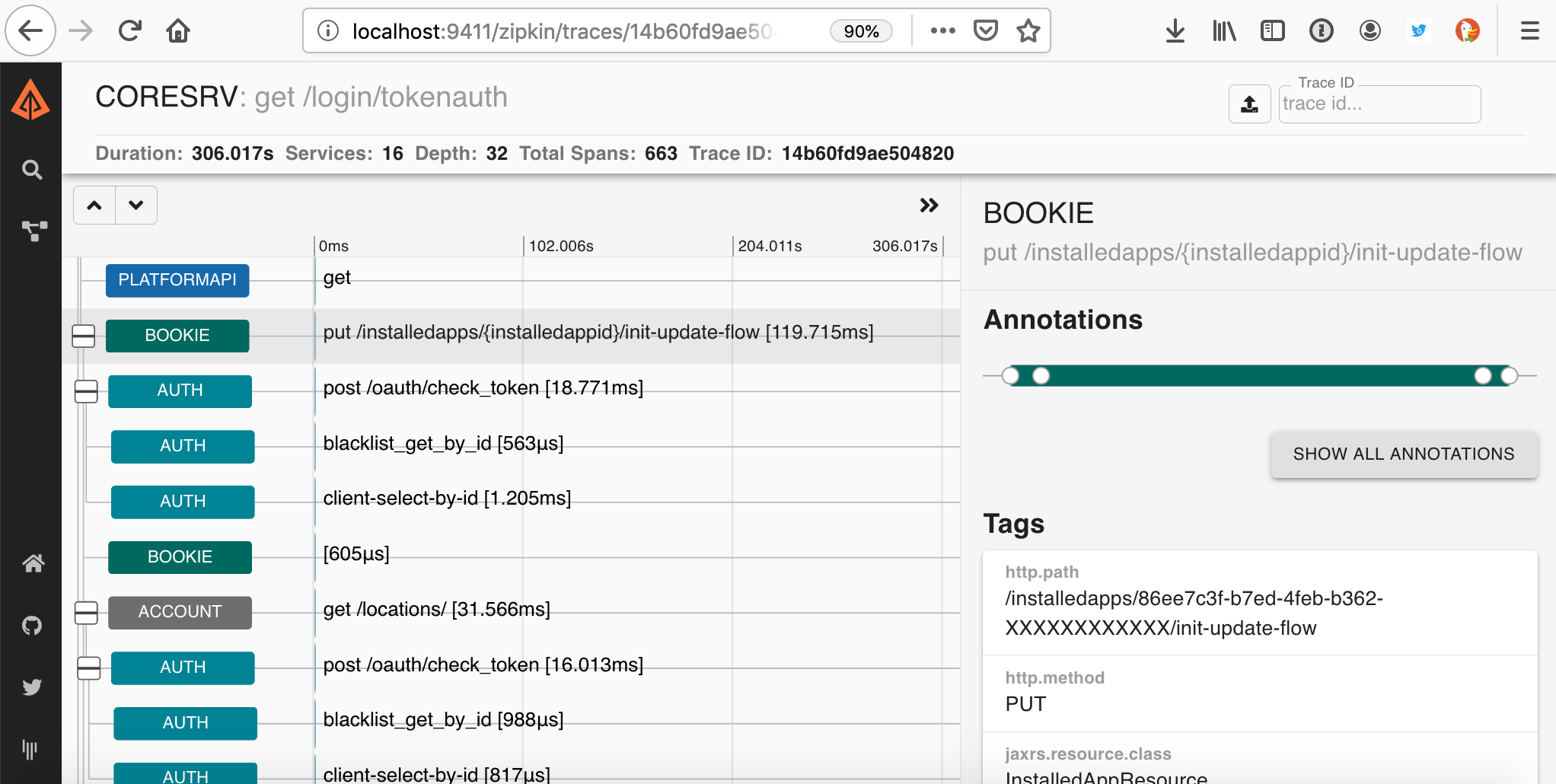
Notice, we've removed the mini-map, as we have a better way to get to a relevant place in the trace. In a large trace like this, causal relationships are not easy to see even if you can get to the right place quickly. Instead, we've implemented a "re-root" feature which allows you to pretend a large trace begins at a span of interest. Double-clicking the Bookie span now looks as if it was a smaller trace, much easier to understand. Double-clicking will reset back.

We've also cleaned up the dependencies screen. The normal search looks similar though a lot of refactoring has taken place under the covers.

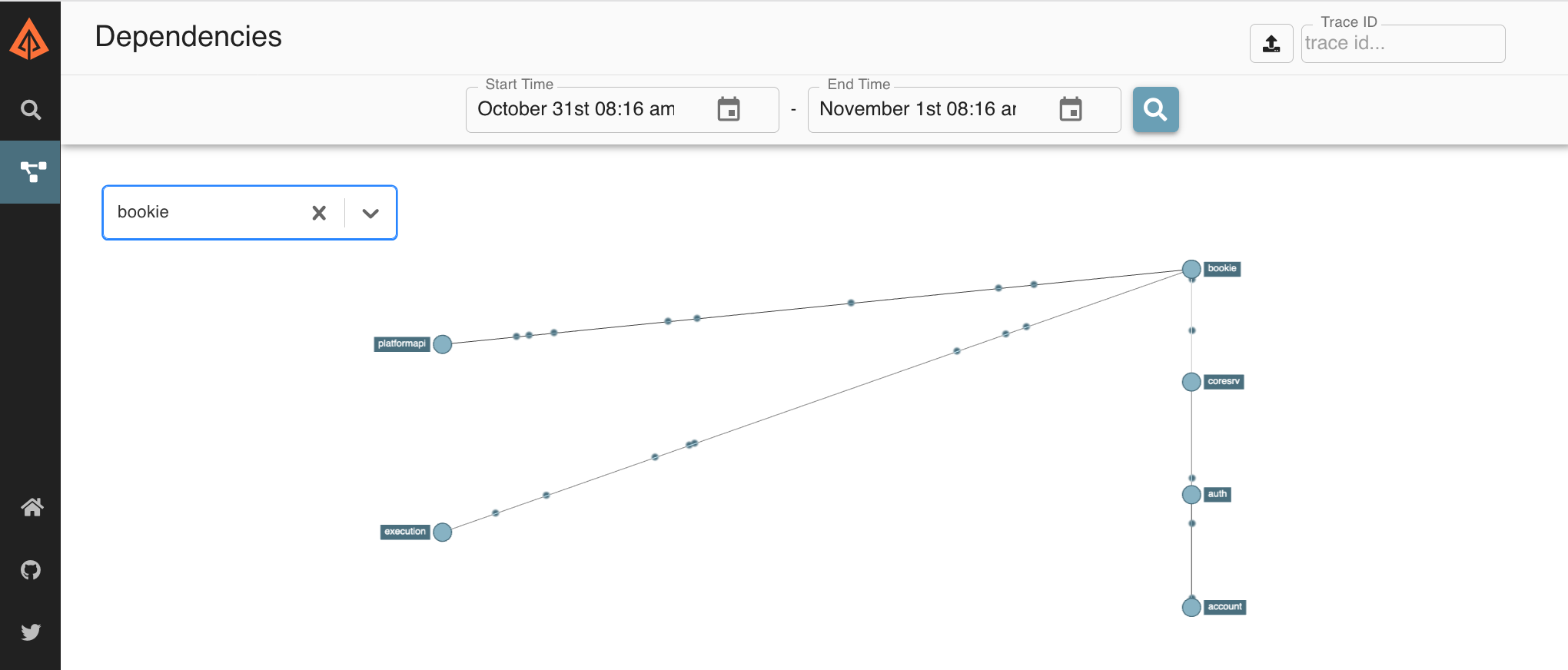
As before, if you hovered over the "bookie" service, you can see connected relationships, as unconnected ones are greyed out

This may be a fine view for a graph of only a dozen services, but if there are hundreds or more, we have a similar problem to the trace screen. We're lucky that @bulicekj contributed an idea from the haystack-ui. Basically, with a filter list, we can perform a similar optimization on the dependencies screen as we do in the re-root screen. In this case, we also search for "bookie"
As mentioned above, this was a large effort, demanding a lot of code, review time, and practice from sites. If you enjoy this, star our repo or stop by and say thanks on gitter. Gitter is also a good place to suggest how we can improve, so that your ideas are the next to release!
Minor updates
We've had some minor updates worth mentioning also. For example, you can set ZIPKIN_UI_USE_LENS=true to always use Lens until it is default.
- @jeqo fixed where we accidentally stopped publishing JVM metrics
- @adriangonz updated our zipkin-junit base dependency from OkHttp 3.x to 4.x
- @anuraaga implemented credential redaction when Elasticsearch logging is on
- @jeqo updated to latest Armeria, adjusting for new blocking annotations
- @drolando contributed a test trace from Yelp
- @drolando upped the hard limit of cassandra span names from 1-10k.
Zipkin 2.18
Zipkin 2.18 refactors and migrates our docker images into the main repository and introduces the "zipkin-slim" distribution.
openzipkin/docker-zipkin attic'd
The openzipkin/docker-zipkin repository is no longer used after @anuraaga completed migration to publication in this repository. This simplifies step count for maintainers, employing DockerHub hooks as a part of an automated deployment flow. This also allows us to have better CI of our images
zipkin-slim
The slim build of Zipkin is smaller and starts faster. It supports in-memory and Elasticsearch storage, but doesn't support messaging transports like Kafka or RabbitMQ. If these constraints match your needs, you can try slim like below:
Running via Java:
curl -sSL https://zipkin.io/quickstart.sh | bash -s io.zipkin:zipkin-server:LATEST:slim zipkin.jar
java -jar zipkin.jarRunning via Docker:
docker run -d -p 9411:9411 openzipkin/zipkin-slimThis build is with thanks to a lot of help and review under the covers by @anuraaga and @jorgheymans. For example, Jorg helped reduce the size by changing from log4j2 to slf4j (log4j2's dependency size is quite large). Rag performed a lot of code work and review to apply shortcuts mentioned in @dsyer's spring boot startup bench project: https://github.com/dsyer/spring-boot-startup-bench. We had review help and troubleshooting also from @jeqo and @devinsba. It was truly a team effort. We also had a lot of work on the docker side by @anuraaga, who helped cut our image layer tremendously (~100M).
Here is are stats on the version before we started bootstrap work (v 2.16.2). This is the "JVM running for" time best in 10 on the same host. Your mileage may vary.
Type | Invocation | Startup | Size
-------------------------------------------
zipkin | Java | 3.4s | 55.4M
zipkin | Docker | 5.9s | 253M
Here are the results using the latest version of Zipkin, also connecting to Elasticsearch storage.
Type | Invocation | Startup | Size
-------------------------------------------
zipkin | Java | 2.6s | 52.3M
zipkin | Docker | 4.1s | 154M
zipkin-slim | Java | 2.0s | 21.6M
zipkin-slim | Docker | 3.1s | 122MB
We hope you enjoy the snappier times. If you'd like to talk more about this, please jump on Gitter.
Zipkin 2.17
Zipkin 2.17 publishes a "master" Docker tag, adds a traceMany endpoint, and improves startup performance.
Before we get into these features, let's talk about logo :) You'll notice our website has been sporting a new logo designed by LINE recently. Thanks to @making, you can see this when booting zipkin, too!
Publishing a "master" docker tag
We've been doing docker images since 2015. One thing missing for a long time was test images. For example, if you wanted to verify Zipkin before a release in Docker, you'd have to build the image yourself. @anuraaga sorted that out by setting up automatic publication of the master branch as the tag "master" in docker.
Ex. "latest" is the last release, "master" is the last commit.
$ docker pull openzipkin/zipkin:masterProbably more interesting to some is how he used this. With significant advice from @bsideup, @anuraaga setup integrated benchmarks of integrated zipkin servers. This allows soak tests without the usual environment volatility.
A keen eye will notice that these benchmarks literally run our sleuth example! This is really amazing work, so let's all thank Rag!
Api for getting many traces by ID
While the primary consumer of our api is the Lens UI, we know there are multiple 3rd party consumers. Many of these prefer external discovery of trace IDs and just need an api to grab the corresponding json.
Here are some use cases:
- out-of-band aggregations, such histograms with attached representative IDs
- trace comparison views
- decoupled indexing and retrieval (Ex lucene over a blob store)
- 3rd party apis that offer stable pagination (via a cursor over trace IDs).
of the api was made to me like other endpoints in the same namespace, and be easy to discover. We have a rationale document if you are interested in details.
Thanks much for the code work from @zeagord and @llinder and api design review by @jcarres-mdsol @jeqo @devinsba and @jcchavezs!
Quicker startup
After hearing some complaints, we did a lot of digging in the last release to find ways to reduce startup time. For example, we found some folks were experiencing nearly 10 second delays booting up an instance of Zipkin, eventhough many were in the 3.5s range. Among many things, we turned off configuration not in use and deleted some dependencies we didn't need. Next, we directly implemented our supported admin endpoints with Armeria. Here are those endpoints in case you didn't read our README
- /health - Returns 200 status if OK
- /info - Provides the version of the running instance
- /metrics - Includes collector metrics broken down by transport type
- /prometheus - Prometheus scrape endpoint
Off the bat, Zipkin 2.17 should boot faster. For example, one "laptop test" went from "best of 5" 3.4s down to under 3s with no reduction in functionality. While docker containers always start slower than java directly, you should see similar reductions in startup time there, too.
For those still unsatisfied, please upvote our slim distribution which can put things in the 2s range with the same hardware, for those who are only using in-memory storage or Elasticsearch.
While we know bootstrap time is unimportant to most sites, it is very important emotionally to some. We'd like to make things as fun as possible, and hope this sort of effort keeps things snappy for you!
Zipkin 2.16
Zipkin 2.16 includes revamps of two components, our Lens UI and our Elasticsearch storage implementation. Thanks in particular to @tacigar and @anuraaga who championed these two important improvements. Thanks also to all the community members who gave time to guide, help with and test this work! Finally, thanks to the Armeria project whose work much of this layers on.
If you are interested in joining us, or have any questions about Zipkin, join our chat channel!
Lens UI Revamp
As so much has improved in the Zipkin Lens UI since 2.15, let's look at the top 5, in order of top of screen to bottom. The lion's share of effort below is with thanks to @tacigar who has put hundreds of hours effort into this release.
To understand these, you can refer to the following images which annotate the number discussed. The first image in each section refers to 2.15 and the latter 2.16.2 (latest patch at the time)






1. Default search to 15minutes, not 1 hour, and pre-can 5 minute search
Before, we had an hour search default which unnecessarily hammers the backend. Interviewing folks, we realized that more often it is 5-15minutes window of interest when searching for traces. By changing this, we give back a lot of performance with zero tuning on the back end. Thanks @zeagord for the help implementing this.
2. Global search parameters apply to the dependency diagram
One feature of Expedia Haystack we really enjoy is the global search. This is where you can re-use context added by the user for trace queries, for other screens such as network diagrams. Zipkin 2.16 is the first version to share this, as before the feature was stubbed out with different controls.
3. Single-click into a trace
Before, we had a feature to preview traces by clicking on them. The presumed use case was to compare multiple traces. However, this didn't really work as you can't guarantee traces will be near eachother in a list. Moreover, large traces are not comparable this way. We dumped the feature for a simpler single-click into the trace similar to what we had before Lens. This is notably better when combined with network improvements described in 5. below.
4. So much better naming
Before, in both the trace list and also detail, names focused on the trace ID as opposed to what most are interested in (the top-level span name). By switching this out, and generally polishing the display, we think the user interface is a lot more intuitive than before.
5. Fast switching between Trace search and detail screen.
You cannot see 5 unless you are recording, because the 5th is about network performance. Lens now shares data between the trace search and the trace detail screen, allowing you to quickly move back and forth with no network requests and reduced rendering overhead.


Elasticsearch client refactor
Our first Elasticsearch implementation allowed requests to multiple HTTP endpoints to failover on error. However, it did not support multiple HTTPS endpoints, nor any load balancing features such round-robin or health checked pools.
For over two years, Zipkin sites have asked us to support sending data to an Elasticsearch cluster of multiple https endpoints. While folks have been patient, workarounds such as "setup a load balancer", or change your hostnames and certificates, have not been received well. It was beyond clear we needed to do the work client-side. Now, ES_HOSTS can take a list of https endpoints.
Under the scenes, any endpoints listed receive periodic requests to /_cluster/health. Endpoints that pass this check receive traffic in a round-robin fashion, while those that don't are marked bad. You can see detailed status from the Prometheus endpoint:
$ curl -sSL localhost:9411/prometheus|grep ^armeria_client_endpointGroup_healthy
armeria_client_endpointGroup_healthy{authority="search-zipkin-2rlyh66ibw43ftlk4342ceeewu.ap-southeast-1.es.amazonaws.com:443",ip="52.76.120.49",name="elasticsearch",} 1.0
armeria_client_endpointGroup_healthy{authority="search-zipkin-2rlyh66ibw43ftlk4342ceeewu.ap-southeast-1.es.amazonaws.com:443",ip="13.228.185.43",name="elasticsearch",} 1.0Note: If you wish to disable health checks for any reason, set zipkin.storage.elasticsearch.health-check.enabled=false using any mechanism supported by Spring Boot.
The mammoth of effort here is with thanks to @anuraaga. Even though he doesn't use Elasticsearch anymore, he volunteered a massive amount of time to ensure everything works end-to-end all the way to prometheus metrics and client-side health checks. A fun fact is Rag also wrote the first Elasticsearch implementation! Thanks also to the brave who tried early versions of this work, including @jorgheymans, @jcarres-mdsol and stanltam
If you have any feedback on this feature, or more questions about us, please reach out on gitter
Test refactoring
Keeping the project going is not automatic. Over time, things take longer because we are doing more, testing more, testing more dimensions. We ran into a timeout problem in our CI server. Basically, Travis has an absolute time of 45 minutes for any task. When running certain integration tests, and publishing at the same time, we were hitting near that routinely, especially if the build cache was purged. @anuraaga did a couple things to fix this. First, he ported the test runtime from classic junit to jupiter, which allows more flexibility in how things are wired. Then, he scrutinized some expensive cleanup code, which was unnecessary when consider containers were throwaway. At the end of the day, this bought back 15 minutes for us to.. later fill up again 😄 Thanks, Rag!
Small changes
- We now document instructions for custom certificates in Elasticsearch.
- We now document the behaviour of in-memory storage thanks @jorgheymans
- We now have consistent COLLECTOR_X_ENABLED variables to turn off collectors explicitly thanks @jeqo
Background on Elasticsearch client migration
The OkHttp java library is everywhere in Zipkin.. first HTTP instrumentation in Brave, the encouraged way to report spans, and relevant to this topic, even how we send data to Elasticsearch!
For years, the reason we didn't support multiple HTTPS endpoints was the feature we needed was on OkHttp backlog. This is no criticism of OkHttp as it is both an edge case feature, and there are ways including layering a client-side load balancer on top. This stalled out for lack of volunteers to implement the OkHttp side or an alternative. Yet, people kept asking for the feature!
We recently moved our server to Armeria, resulting in increasing stake, experience and hands to do work. Even though its client side code is much newer than OkHttp, it was designed for advanced features such as client-side load balancing. The idea of re-using Armeria as an Elasticsearch client was interesting to @anuraaga, who volunteered both ideas and time to implement them. The result was a working implementation complete with client-side health checking, supported by over a month of Rag's time.
The process of switching off OkHttp taught us more about its elegance, and directly influenced improvements in Armeria. For example, Armeria's test package now includes utilities inspired by OkHttp's MockWebServer.
What we want to say is.. thanks OkHttp! Thanks for the formative years of our Elasticsearch client and years ahead as we use OkHttp in other places in Zipkin. Keep up the great work!
Zipkin 2.15
ActiveMQ 5.x span transport
Due to popular demand, we've added support for ActiveMQ 5.x. Zipkin server will connect to ActiveMQ when the env variable ACTIVEMQ_URL is set to a valid broker. Thanks very much to @IAMTJW for work on this feature and @thanhct for testing it against AWS MQ.
Ex. simple usage against a local broker
ACTIVEMQ_URL=tcp://localhost:61616 java -jar zipkin.jarEx. usage with docker against a remote AWS MQ failover group
docker run -d -p 9411:9411 -e ACTIVEMQ_URL='failover:(ssl://b-da18ebe4-54ff-4dfc-835f-3862a6c144b1-1.mq.ap-southeast-1.amazonaws.com:61617,ssl://b-da18ebe4-54ff-4dfc-835f-3862a6c144b1-2.mq.ap-southeast-1.amazonaws.com:61617)' -e ACTIVEMQ_USERNAME=zipkin -e ACTIVEMQ_PASSWORD=zipkin12345678 -e ACTIVEMQ_CONCURRENCY=8 openzipkin/zipkinRewrite of Zipkin Lens global search component
One of the most important roles in open source is making sure the project is maintainable. As features were added in our new UI, maintainability started to degrade. Thanks to an immense amount of effort by @tacigar, we now have new, easier to maintain search component. Under the covers, it is implemented in Material-UI and React Hooks.

Behind the crisp new look is clean code that really helps the sustainability of our project. Thanks very much to @tacigar for his relentless attention.
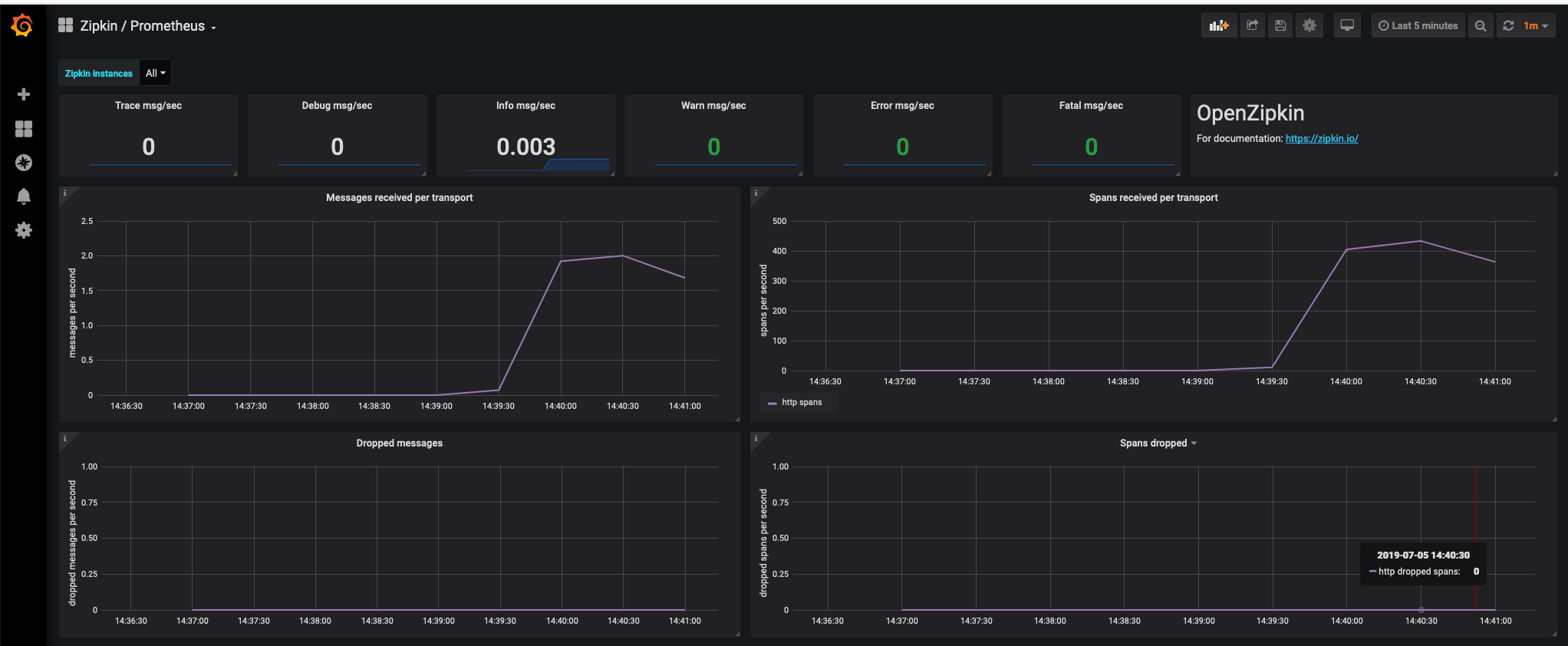
Refreshed Grafana Dashboard
While many have tried our Grafana dashboard either directly or via our docker setup, @mstaalesen really dug deep. He noticed some things drifted or were in less than ideal places. Through a couple weeks of revision, we now have a tighter dashboard. If you have suggestions, please bring them to Gitter as well!
Small, but appreciated fixes
- Fixes a bug where a Java 8 class could be accidentally loaded when in Java 1.7
- Ensures special characters are not used in RabbitMQ consumer tags (thx @bianxiaojin)
- Shows connect exceptions when using RabbitMQ (thx @thanhct)
- Fixes glitch where health check wasn't reported properly when throttled (thx @lambcode)