Fix race condition for trial number computation. #1490
Conversation
|
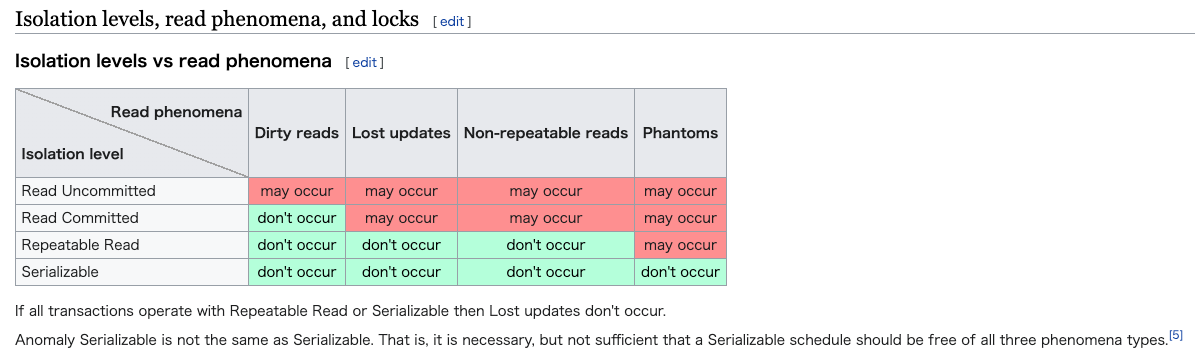
"Read Uncommitted" is lower isolation level than "Repeatable Read". It looks that this PR depends on "Dirty Reads", right? Like this table said, "Dirty reads" may occure when using "Read Uncommitted". So it looks that this fixes is not safe. |
2ebd008
to
d3060a2
Compare
|
Thanks @c-bata for you quick comment. I changed the logic to do row level locking on all trials for the given study, and retrying on failures, rather than relaxing the isolation level. Verified the logic with MySQL and PostgreSQL locally. Note that this has the downside of significantly making creation of trials slower. However, this cannot be helped given our "constraint" on the number that it must be unique, etc. |
|
Mini bench my MySQL. Code
import argparse
import math
import time
import optuna
from optuna.samplers import TPESampler
import sqlalchemy
class Profile:
def __enter__(self):
self.start = time.time()
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.end = time.time()
def get(self):
return self.end - self.start
def build_objective_fun(n_param):
def objective(trial):
return sum(
[
math.sin(trial.suggest_uniform("param-{}".format(i), 0, math.pi * 2))
for i in range(n_param)
]
)
return objective
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("mysql_user", type=str)
parser.add_argument("mysql_host", type=str)
args = parser.parse_args()
storage_str = "mysql+pymysql://{}@{}/".format(args.mysql_user, args.mysql_host)
optuna.logging.set_verbosity(optuna.logging.CRITICAL)
print(f"| #params | #trials | time(sec) |")
print(f"| ------- | ------- | --------- |")
for n_param in [1, 2, 4, 8, 16, 32]:
for n_trial in [1, 10, 100, 1000]:
engine = sqlalchemy.create_engine(storage_str)
conn = engine.connect()
conn.execute("commit")
database_str = "profile_storage_t{}_p{}".format(n_trial, n_param)
try:
conn.execute("drop database {}".format(database_str))
except Exception:
pass
conn.execute("create database {}".format(database_str))
conn.close()
storage = optuna.storages.get_storage(storage_str + database_str)
study = optuna.create_study(storage=storage, sampler=TPESampler())
with Profile() as prof:
study.optimize(
build_objective_fun(n_param), n_trials=n_trial, gc_after_trial=False,
)
print(f"| {n_param} | {n_trial} | {prof.get():.2f} |")
|
optuna/storages/_rdb/storage.py
Outdated
| # Lock all trials belonging to this study. This might lead to a deadlock | ||
| # (`OperationalError`) in which case we will retry. | ||
| session.query(models.TrialModel).filter( | ||
| models.TrialModel.study_id == study_id | ||
| ).with_for_update().all() |
There was a problem hiding this comment.
How about locking a entry in the studies table instead of locking the whole trials (though I haven't checked that it improves the latency)?
There was a problem hiding this comment.
Ah, that might scale better with the number of trials. Let me just verify it.
There was a problem hiding this comment.
Looks good.
| #params | #trials | time(sec) |
|---|---|---|
| 1 | 1 | 0.02 |
| 1 | 10 | 0.11 |
| 1 | 100 | 1.26 |
| 1 | 1000 | 17.41 |
| 2 | 1 | 0.02 |
| 2 | 10 | 0.12 |
| 2 | 100 | 1.32 |
| 2 | 1000 | 20.22 |
| 4 | 1 | 0.02 |
| 4 | 10 | 0.13 |
| 4 | 100 | 1.61 |
| 4 | 1000 | 25.82 |
| 8 | 1 | 0.04 |
| 8 | 10 | 0.16 |
| 8 | 100 | 2.07 |
| 8 | 1000 | 35.07 |
| 16 | 1 | 0.06 |
| 16 | 10 | 0.20 |
| 16 | 100 | 3.02 |
| 16 | 1000 | 55.23 |
| 32 | 1 | 0.12 |
| 32 | 10 | 0.30 |
| 32 | 100 | 4.76 |
| 32 | 1000 | 90.28 |
|
Thanks @c-bata as always. Regarding the performance hit, it's actually negligible now with @ytsmiling's suggestion of restricting the lock to a single row (at most), instead of all trials. |
There was a problem hiding this comment.
@hvy Now I noticed that we should modify the implementation of count_past_trials.
optuna/optuna/storages/_rdb/models.py
Lines 251 to 257 in d7bdd63
We need to remove TrialModel.trial_id < self.trial_id from here.
|
It's highly unlikely, but if trial_id is not assigned sequentially, the |
optuna/storages/_rdb/storage.py
Outdated
| @@ -464,9 +464,46 @@ def _create_new_trial( | |||
|
|
|||
| session = self.scoped_session() | |||
|
|
|||
| # Ensure that that study exists. | |||
| models.StudyModel.find_or_raise_by_id(study_id, session) | |||
| try: | |||
There was a problem hiding this comment.
Memo: Try n (maybe 3) times and propagate the OperationalError in case they all fail. It should be easier to debug.
|
Changed the logic to propagate sqlalchemy errors after 3 retries to reduce the risk of silencing unexpected errors and to aid debugging in case of what would previously have resulted in maxim recursion depth error. |
|
PTAL. |
Motivation
Fixes #1488.
Description of the changes
Allows
count_past_trialsto circumvent repeatable read isolation level. See the comments in the code for details.Note
Verified the changes with MySQL, by inspection, by checking for unique trial numbers after running a distributed optimization. The bug is otherwise reproducible, simply running a lot of trials with.
About isolation levels in sqlalchemy for different dialect
https://docs.sqlalchemy.org/en/13/core/connections.html#sqlalchemy.engine.Connection.execution_options.params.isolation_level.