Broadcasting is consuming a lot of memory in Gorgonnx/Gorgonia #68
Comments
|
I just made a quick test by "hacking" the tensor package. The results look promising: Normal bench: bench with the hack: |
|
This commit from then
However, I will keep this issue open for now to do a further investigation with the broadcasting mechanism. |

|
In Gorgonia, the broadcast mechanism is based on the d := dst.arr().slice(dstart, dend)
s := src.arr().slice(sstart, send)Within this loop, we are creating |
|
With the PR 43 from the tensor package, the results are now: Comparing with the initial investigation of the issue, the performance comparison will be: Once the PR is merged, that will be enough to close this issue |
|
Closed thanks to PR #43 of the tensor package |
|
I reopen this issue because on NN involving small tensors, broadcasting is ok, but on bigger tensor it's still too slow. |
|
PR 299 from Gorgonia should improve things |
Bench
I've created this simple benchmark with the MNIST model to analyze the behavior of the code:
Running this with
go test -bench=. -benchmem -memprofile memprofile.out -cpuprofile profile.out -benchtime=10sgenerates two files to decode with the go profiler.CPU
The result for the CPU is displayed herer:
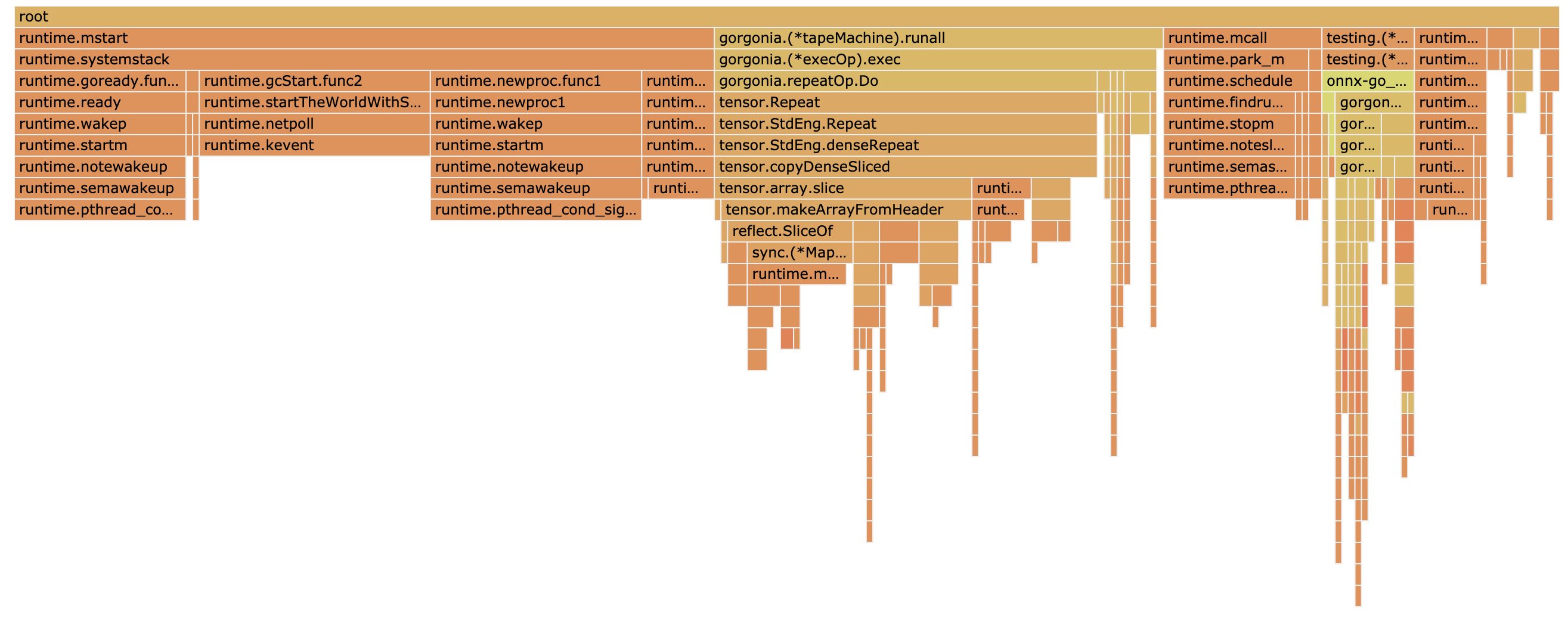
There are possible enhancements, but nothing obvious.
Memory
The result for the Memory usage is more interesting. It shows that the
repeatOpof Gorgonia is using a lot of memory. TherepeatOpis the foundation of the broadcasting.This
opseems to copy a lot of data:gorgonia.TensorThe analysis point that this function from the tensor package is involved in extra memory consumption:
https://github.com/gorgonia/tensor/blob/8eeece33868236224d51e7362e36a68642870bd2/array.go#L34-L51
Especially this call to
val.Interface()According to the comment, this field is even not mandatory by the array.
On top of that, the
reflectpackage from stdlib references a TODO with something to enhance in thepackEface function (packEface converts v to the empty interface. ):The
safeflag is true when callingInterface() function:This suggests that avoiding the copy would significantly improve the performances.
cc @chewxy
The text was updated successfully, but these errors were encountered: