{kind=link}
This is my first attempt at a Kaggle competition. My entry was ranked 1846th out of 2249 :(
Details: https://www.kaggle.com/c/liberty-mutual-group-property-inspection-prediction
I used my neural network library: https://github.com/phil8192/neural-network-light making use of k-folding. My entry was the average prediction of an ensemble of networks trained with early stopping.
Result was poor compared to other entries, but was > the random forest benchmark (2044th). Final ranking of my entry shown below (black line). Random forest benchmark is indicated by the blue line.
my.score <- 0.341737
bm.score <- 0.303405
lb <- read.csv("public_leaderboard.csv")
scores <- sort(as.vector(tapply(lb$Score, lb$TeamName, max)), decreasing=T)
scores <- scores[scores > 0]
plot(scores, type="l")
abline(v=head(which(abs(scores-bm.score) < 0.0001), 1), col="blue")
abline(v=which(scores == my.score))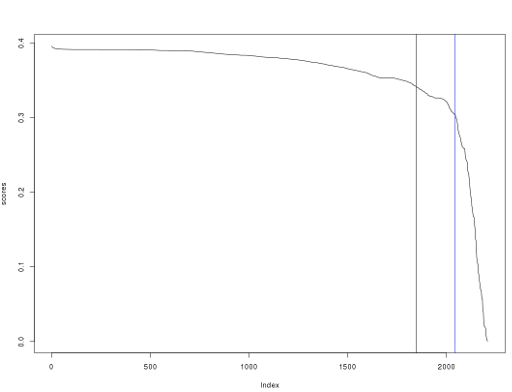
-
bagging: uses bootstrap (uniform selection with duplicates) to generate M subsets of the data. Each subset is the same size as the original data and may contain duplicates. For each subset, a model is trained. Then, the prediction/classification will be the average of model outputs (for prediction) or the plurity vote (for classification).
-
boosting: poor performing models are incrementaly trained on the data. each new model added to the set is trained on data that the previous model had difficulty with - the dataset is weighted.
-
ensemble averaging: take average or weighted average of models. models can be trained with different parameters or even be specialised according to domain knowledge. (linear combination of experts, "meta-network"). (technically: "stacking" - training a model to combine results of others.)
http://www.scholarpedia.org/article/Ensemble_learning weight decay: http://www.cs.rpi.edu/~magdon/courses/LFD-Slides/SlidesLect22.pdf https://web.stanford.edu/group/pdplab/pdphandbook/handbookch6.html http://www.quora.com/How-do-you-add-regularization-in-the-training-of-a-neural-net-that-uses-stochastic-gradient-descent http://ufldl.stanford.edu/wiki/index.php/Backpropagation_Algorithm http://www.cs.bham.ac.uk/~jxb/NN/l10.pdf http://www.faqs.org/faqs/ai-faq/neural-nets/part3/section-6.html http://neuralnetworksanddeeplearning.com/chap3.html#overfitting_and_regularization drop-connect: (based on drop-out) http://cs.nyu.edu/~wanli/dropc/dropc.pdf http://rodrigob.github.io/are_we_there_yet/build/classification_datasets_results.html
- implement weight decay/regularisation in neural-network-light.