Questions on implementation details #14
Comments
|
I implemented my own version of attention + LSTM. Since we don't have INPUT_DIM = 100
TIME_STEPS = 20
# if True, the attention vector is shared across the input_dimensions where the attention is applied.
SINGLE_ATTENTION_VECTOR = True
APPLY_ATTENTION_BEFORE_LSTM = False
ATTENTION_SIZE = 128
def attention_3d_block(hidden_states):
# hidden_states.shape = (batch_size, time_steps, hidden_size)
hidden_size = int(hidden_states.shape[2])
# _t stands for transpose
hidden_states_t = Permute((2, 1), name='attention_input_t')(hidden_states)
# hidden_states_t.shape = (batch_size, hidden_size, time_steps)
# this line is not useful. It's just to know which dimension is what.
hidden_states_t = Reshape((hidden_size, TIME_STEPS), name='attention_input_reshape')(hidden_states_t)
# Inside dense layer
# a (batch_size, hidden_size, time_steps) dot W (time_steps, time_steps) => (batch_size, hidden_size, time_steps)
# W is the trainable weight matrix of attention
# Luong's multiplicative style score
score_first_part = Dense(TIME_STEPS, use_bias=False, name='attention_score_vec')(hidden_states_t)
score_first_part_t = Permute((2, 1), name='attention_score_vec_t')(score_first_part)
# score_first_part_t dot last_hidden_state => attention_weights
# (batch_size, time_steps, hidden_size) dot (batch_size, hidden_size, 1) => (batch_size, time_steps, 1)
h_t = Lambda(lambda x: x[:, :, -1], output_shape=(hidden_size, 1), name='last_hidden_state')(hidden_states_t)
score = dot([score_first_part_t, h_t], [2, 1], name='attention_score')
attention_weights = Activation('softmax', name='attention_weight')(score)
# if SINGLE_ATTENTION_VECTOR:
# a = Lambda(lambda x: K.mean(x, axis=1), name='dim_reduction')(a)
# a = RepeatVector(hidden_size)(a)
# (batch_size, hidden_size, time_steps) dot (batch_size, time_steps, 1) => (batch_size, hidden_size, 1)
context_vector = dot([hidden_states_t, attention_weights], [2, 1], name='context_vector')
context_vector = Reshape((hidden_size,))(context_vector)
h_t = Reshape((hidden_size,))(h_t)
pre_activation = concatenate([context_vector, h_t], name='attention_output')
attention_vector = Dense(ATTENTION_SIZE, use_bias=False, activation='tanh', name='attention_vector')(pre_activation)
return attention_vectorThe interface remained same except you don't need Flatten layer anymore: def model_attention_applied_after_lstm():
inputs = Input(shape=(TIME_STEPS, INPUT_DIM,))
lstm_units = 32
lstm_out = LSTM(lstm_units, return_sequences=True)(inputs)
attention_mul = attention_3d_block(lstm_out)
# attention_mul = Flatten()(attention_mul)
output = Dense(INPUT_DIM, activation='sigmoid')(attention_mul)
model = Model(input=[inputs], output=output)
return modelThe results seems even better than your original implementation:
The process of building attention myself has brought me more questions than answers:
P.S. I have modified get_data_recurrent function a little bit to produce one-hot data as it is more similar to my actual needs. def get_data_recurrent(n, time_steps, input_dim, attention_column=10):
"""
Data generation. x is purely random except that it's first value equals the target y.
In practice, the network should learn that the target = x[attention_column].
Therefore, most of its attention should be focused on the value addressed by attention_column.
:param n: the number of samples to retrieve.
:param time_steps: the number of time steps of your series.
:param input_dim: the number of dimensions of each element in the series.
:param attention_column: the column linked to the target. Everything else is purely random.
:return: x: model inputs, y: model targets
"""
x = np.random.randint(input_dim, size=(n, time_steps))
x = np.eye(input_dim)[x]
y = x[:, attention_column, :]
return x, y |

|
Being confused about why attention can learn info about specific index in input sequence, I went on and read the code in official tensorflow implementation. I was wrong about the def attention_3d_block(hidden_states):
# hidden_states.shape = (batch_size, time_steps, hidden_size)
hidden_size = int(hidden_states.shape[2])
# Inside dense layer
# hidden_states dot W => score_first_part
# (batch_size, time_steps, hidden_size) dot (hidden_size, hidden_size) => (batch_size, time_steps, hidden_size)
# W is the trainable weight matrix of attention
# Luong's multiplicative style score
score_first_part = Dense(hidden_size, use_bias=False, name='attention_score_vec')(hidden_states)
# score_first_part dot last_hidden_state => attention_weights
# (batch_size, time_steps, hidden_size) dot (batch_size, hidden_size) => (batch_size, time_steps)
h_t = Lambda(lambda x: x[:, -1, :], output_shape=(hidden_size,), name='last_hidden_state')(
hidden_states)
score = dot([score_first_part, h_t], [2, 1], name='attention_score')
attention_weights = Activation('softmax', name='attention_weight')(score)
# (batch_size, time_steps, hidden_size) dot (batch_size, time_steps) => (batch_size, hidden_size)
context_vector = dot([hidden_states, attention_weights], [1, 1], name='context_vector')
pre_activation = concatenate([context_vector, h_t], name='attention_output')
attention_vector = Dense(128, use_bias=False, activation='tanh',
name='attention_vector')(
pre_activation)
return attention_vector
Surprisingly, even without any hard information on the index of sequence, attention model still managed to learn the importance of 10th element. Now I am super confused.
My guess is somehow LSTM learned to "count" to 10 in its hidden state. And that "count" is captured by attention. I will need to visualize the inner parameters of LSTM to be sure. An interesting finding I made is how attention is learnt through time:
Full code (except from keras.layers import concatenate, dot
from keras.layers.core import *
from keras.layers.recurrent import LSTM
from keras.models import *
from attention_utils import get_activations, get_data_recurrent
INPUT_DIM = 100
TIME_STEPS = 20
# if True, the attention vector is shared across the input_dimensions where the attention is applied.
SINGLE_ATTENTION_VECTOR = True
APPLY_ATTENTION_BEFORE_LSTM = False
def attention_3d_block(hidden_states):
# same as above
def model_attention_applied_after_lstm():
inputs = Input(shape=(TIME_STEPS, INPUT_DIM,))
lstm_units = 32
lstm_out = LSTM(lstm_units, return_sequences=True)(inputs)
attention_mul = attention_3d_block(lstm_out)
# attention_mul = Flatten()(attention_mul)
output = Dense(INPUT_DIM, activation='sigmoid', name='output')(attention_mul)
model = Model(input=[inputs], output=output)
return model
if __name__ == '__main__':
N = 300000
# N = 300 -> too few = no training
inputs_1, outputs = get_data_recurrent(N, TIME_STEPS, INPUT_DIM)
if APPLY_ATTENTION_BEFORE_LSTM:
m = model_attention_applied_before_lstm()
else:
m = model_attention_applied_after_lstm()
m.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
print(m.summary())
m.fit([inputs_1], outputs, epochs=1, batch_size=64, validation_split=0)
attention_vectors = []
for i in range(10):
testing_inputs_1, testing_outputs = get_data_recurrent(1, TIME_STEPS, INPUT_DIM)
activations = get_activations(m, testing_inputs_1, print_shape_only=True, layer_name='attention_weight')
attention_vec = np.mean(activations[0], axis=0).squeeze()
print('attention =', attention_vec)
assert (np.sum(attention_vec) - 1.0) < 1e-5
attention_vectors.append(attention_vec)
attention_vector_final = np.mean(np.array(attention_vectors), axis=0)
# plot part.
import matplotlib.pyplot as plt
import pandas as pd
pd.DataFrame(attention_vector_final, columns=['attention (%)']).plot(kind='bar',
title='Attention Mechanism as '
'a function of input'
' dimensions.')
plt.show() |


|
I am actually thinking you were trying to implement self attention, which is used in text classification. But nonetheless the weight parameters should be sized (hidden_size, hidden_size) instead of (time_steps, time_steps). |
|
@felixhao28 why do you use the layer that was named “last_hidden_state”? |
|
@Wangzihaooooo Because attention was first introduced in a Sequence to Sequence model, where attention score is computed based on both To be fair, you can totally remove |
|
@felixhao28 thank you ,I learned a lot from your code. |
|
@felixhao28 thank you very much. This is very well explained and removes the complexity around Attention Layer. I implemented the code inline for Seq2Seq model and able to grab attention matrix directly. Thanks once again for your help. Regards |
|
@felixhao28 I'm a bit confused in this part of the code:
Thanks! |
The input does pass through LSTM first. Layer is an abstract concept of how the tensor should be calculated, not the actual tensor to be calculated. The relationship is more like "class" and "instance" if you are familiar with OOP. the |
|
@felixhao28 I see, thanks for the explanation! |
Hi, can you clarify what you mean by "Since we don't have |
|
@farahshamout Here is a rather complete explanation on attention over sequence to sequence model. The original idea of attention uses the output of the decoder as |
|
@felixhao28 I see, thanks! |
|
Hi, i was trying to use your implementation, but i would like to save an attention heat map during the training (once for epoch), i tried to add |
|
@Bertorob I assume you added If you only need attention heat map once per epoch instead of once per batch, |
|
@felixhao28 Thank you for the answer. However if i want to plot the attention after training, I suppose i don't need to add the second ''ground-truth y'' but i don't get how you are able to do it. Could you please explain how can you do that? |
|
This part of the code calculates the attention heat map: attention_vectors = []
for i in range(10):
... # lines ommited
pd.DataFrame(attention_vector_final, columns=['attention (%)']).plot(kind='bar',
title='Attention Mechanism as '
'a function of input'
' dimensions.')
plt.show()The attention_weights are not directly fetched during training. It isn't run until later after m.fit([inputs_1], outputs, epochs=1, batch_size=64, validation_split=0)You see this line above just run one epoch. If you create a loop around it and change for epoch_i in range(n_epochs):
m.fit([inputs_1], outputs, epochs=1, batch_size=64, validation_split=0)
attention_vectors = []
for i in range(10):
... # lines ommited
pd.DataFrame(attention_vector_final, columns=['attention (%)']).plot(kind='bar',
title='Attention Mechanism as '
'a function of input'
' dimensions.')
plt.savefig(f'attention-weights-{epoch_i}.png')Edit: here I am still using |
|
Ok i'm figuring something out. Last question now i tried something like this: where x is my input and actually i have my attention vector but it is filled with ones , maybe i'm still doing something wrong, why is there 10 in the for ? EDIT: sorry i have understimated the relevance of |
|
@felixhao28 |
|
@LZQthePlane No it is more complicated than that. The basic idea is to replace the h_t with current state of the decoder step. You might want to find another ready-to-use seq2seq attention code. |
|
Hi @felixhao28, Thank you so much for your code and explanations above. I am new to learning attention and I want to use it after LSTM for a classification problem. I understood the concepts of attention from this presentation [1] by Sujit Pal : I got confused after reading your code about the type of attention (the theory behind it and how is it called in papers). does it compute an attention vector on an incoming matrix using a learned context vector? hope you could help! |
|
@felixhao28 |
|
@Goofy321 How do you calculate the attention score then? |
|
@OmniaZayed My implementation is similar to AttentionMV in Sujit Pal's code except that |
I mean the input of attention_score_vec layer change into hidden_states[:,:-1,:]. And the calculation of the attention score is the same as yours. |
|
@Goofy321 I think that works too. |
|
@felixhao28 : When i try to run your code I get following error when calculating the score: score = dot([score_first_part, h_t], axes=[2, 1], name='attention_score')
Currently I can't figure out why the dimensions don't match, any idea? Did anyone else experience the same issues? |
|
@patebel the shape of h_t should be (batch_size, hidden_size, 1), you are missing the final "1" dimension. Keras used to reshape the output of lambda layer to your output shape, maybe adding |
|
@felixhao28 Oh yes, I didn't recognize, thank you! |
|
Hi @felixhao28, thanks for your insights and helpfulness in this issue! Reading the original paper by Bahdanau et. al. and comparing the operations to this repository, I was really confused until I saw this.
However, when I apply the attention layer as you have suggested before the final dense layer for prediction with attension size of 256, I get extremely gibberish output, certain letters being repeated back to back in a nonsensical way. Below is that version.
Any ideas why this approach fails? I have also tried without stacking LSTM layers, and it still fails. The only thing I can think of is that the token-level for this language model is characters, whereas I have seen attention applied mostly to word-level language models. Any help will be appreciated! UPDATE: Solved it, turns out I didn't set one of the Dense layers to be trainable. |


|
@felixhao28 thanks for the quick responds. I have one other question regarding
which many have already asked you. if we were to take only the last hidden state, would it be in a way saying that we are focusing on one specific part (last part in this case) of the lstm output to do the many-to-one problem. What if however, the intuition was that the whole input sequence were important in predicting the one output, would it be more suitable to use the mean along the time axis instead? so something like
PS: using the mean is just an example, it could be any other function depending on the problem |
|
@felixhao28 thanks a ton for your useful comments! I haven't had time to work on this repo since then. I was pretty new to deep learning when I wrote it. I'm going to invest some time to integrate some of your suggestions and fix the things that need to be fixed :) |
|
@junhuang-ifast In my application I was using attention in a sequence prediction model, which just focuses on the very next token in the sequence. Taking only the last hidden state worked fine due to the locality nature of sequences. I am not an expert on applications other than sequence prediction. But if I have to guess, you can omit Averaging all hidden states feels strange because by using attention, you are assuming not all elements in the sequence are equal. It is attentions' job to figure out which ones are more important and by how much. Using the mean of all states erases that difference. Unless there is a global information which differs by each sequence, hiding in each element and you want sum it up, I don't feel averaging is the way to go. I might be wrong though. |
|
@philipperemy No problem. We are all learning it as we discuss it. |
|
@felixhao28 just to be clear, when u say
would be the equivalent to not calculating h_t or the first dot product ie
and just letting |
|
@junhuang-ifast yes |
|
@felixhao28 Do you have the link to the paper of this attention that was described in the TensorFlow tutorial? |
|
@philipperemy the original link is gone but I think they are: |
|
Actually, There are three different versions of attention. felixhao28' version is called global attention and philipperemy ' version is called self-attention. The rest one is called local attention, a little different with global attention. |
|
I updated the repo with all the comments of this thread. Thank you all! |
Do you know a good implementation for local attention? |
|
Do you know how I can apply the attention module to a 2D shaped input , I would like to apply to apply attention after the LSTM layer- Would really appreciate your suggestion on how to modify attention_3D block to make it work for a 2D input as well. thanks. |
|
@raghavgurbaxani I answered you in your thread. |
|
Hi @philipperemy and @felixhao28 . I am trying to apply attention model on top of an LSTM, where my input training data is a nd array. How should I fit my model in this case? I get the following error because of my data being a nd array ValueError: Failed to convert a NumPy array to a Tensor (Unsupported object type numpy.ndarray). What changes should I make? Would appreciate your help! Thank you |
|
@AnanyaO did you have a look at the examples here: https://github.com/philipperemy/keras-attention-mechanism/tree/master/examples? |
|
Hi, thanks for all of uers' comments. I have learned a lot from that. But can I ask a question. If we use an RNN(or some variants of it), we can get the hidden states of each time_step which can then be used to compute the score. But if I did not use Lstm to be as an encoder, alternately, I use a 1D CNN as an encoder, what should I do when I want to apply attention. For example, I would like to handle some textual messages, so I first used an embedding layer and then used a 1DConv layer. Is there some methods I can use to apply the attention mechanism to my model. Thanks so much. |
Update on 2019/2/14, nearly one year later:
The implementation in this repo is definitely bugged. Please refer to my implementation in a reply below for correction. My version has been working in our product since this thread and it outperforms both vanilla LSTM without attention and the incorrect version in this repo by a significant margin. I am not the only one raising the question 1.
Both this repo and my version of attention are intended for sequence-to-one networks (although it can be easily tweaked for seq2seq by replacing
h_twith current state of the decoder step). If you are looking for a ready-to-use attention for sequence-to-sequence networks, check this out: https://github.com/farizrahman4u/seq2seq.============Original answer==============
I am currently working on a text generation task and learnt attention from TensorFlow tutorials. The implementation details seems quite different from your code.
This is how TensorFlow tutorial describes the process:
If I am understanding it correctly, all learnable parameters in the attention mechanism are stored in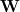 , which has a shape of
, which has a shape of 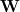 to calculate the score of each hidden state based on the value of the hidden state
to calculate the score of each hidden state based on the value of the hidden state  and
and 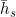 , but I am not seeing
, but I am not seeing  anywhere in your code. Instead, you applied a dense layer on all
anywhere in your code. Instead, you applied a dense layer on all 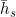 . And that means
. And that means  (Edit: h_t should be h_s in this equation) becomes the
(Edit: h_t should be h_s in this equation) becomes the  in the paper. This seems wrong.
in the paper. This seems wrong.
(rnn_size, rnn_size)(rnn_sizeis the size of hidden state). So first you need to useIn the next step you element-wise multiplies the attention weights with hidden states as equation (2). Then somehow missed the equation (3).
I noticed the tutorial is about Seq2Seq (Encoder-Decoder) model and your code is an RNN. Maybe that is why your code is different. Do you have any source on how attention is applied to a non Seq2Seq network?
Here is your code:
The text was updated successfully, but these errors were encountered: