How to add Attention on top of a Recurrent Layer (Text Classification) #4962
Comments
|
It's been a while since I've used attention, so take this with a grain of salt.
As for implementing attention in Keras.. There are two possible methods: a) add a hidden On option a): this would apply attention to the output of the recurrent unit but not to the output/input passed to the next time step. I don't this is what is desired. In this case, the LSTM should have a squashing function applied, as LSTMs don't do too well with linear/relu style activation. On option b): this would apply attention to the output of the recurrentcy, and also to the output/input passed to the next timestep. I think that this is what is desired, but I could be wrong. In this case, the linear output of the neurons would be squashed directly by the softmax; if you wish to apply a pre-squashing such as I could draw a diagram if necessary, and I should probably read the activation papers again.. |
|
@patyork Thanks for the reply. If it is possible i would like for someone to offer an example in Keras. PS. is this the correct place to ask such question or i should do it at https://groups.google.com/d/forum/keras-users? |
|
@baziotis This area is supposed to be more for bugs as opposed to "how to implement" questions. I admit I don't often look at the google group, but that is a valid place to ask these questions, as well as on the Slack channel. Bengio et. al has a pretty good paper on attention (soft attention is the softmax attention). An example of method a) I described: vocab_size = embeddings.shape[0]
embedding_size = embeddings.shape[1]
model = Sequential()
model.add(Embedding(
input_dim=vocab_size,
output_dim=embedding_size,
input_length=max_length,
trainable=False,
mask_zero=True,
weights=[embeddings]
))
model.add(LSTM(200, return_sequences=False))
model.add(Activation('softmax')) #this guy here
model.add(Dropout(0.5))
model.add(Dense(3, activation='softmax', activity_regularizer=activity_l2(0.0001)))example b), with simple activation: vocab_size = embeddings.shape[0]
embedding_size = embeddings.shape[1]
model = Sequential()
model.add(Embedding(
input_dim=vocab_size,
output_dim=embedding_size,
input_length=max_length,
trainable=False,
mask_zero=True,
weights=[embeddings]
))
model.add(LSTM(200, return_sequences=False, activation='softmax'))
model.add(Dropout(0.5))
model.add(Dense(3, activation='softmax', activity_regularizer=activity_l2(0.0001)))example b) with sigmoid and then softmax (non-working, but the idea): vocab_size = embeddings.shape[0]
embedding_size = embeddings.shape[1]
def myAct(out):
return K.softmax(K.tanh(out))
model = Sequential()
model.add(Embedding(
input_dim=vocab_size,
output_dim=embedding_size,
input_length=max_length,
trainable=False,
mask_zero=True,
weights=[embeddings]
))
model.add(LSTM(200, return_sequences=False, activation=myAct))
model.add(Dropout(0.5))
model.add(Dense(3, activation='softmax', activity_regularizer=activity_l2(0.0001)))In addition, I should say that my notes about whether a) or b) above is what you probably need are based on your example, where you want one output (making option b probably the correct way). Attention is often used in spaces like caption generation where there is more than 1 output such as setting |
|
@patyork Thanks for the examples and for the paper. I new that posting here would get more attention :P I will try them and post back. |
|
@patyork, I'm sorry, but I don't see how this implements attention at all? From my understanding, the softmax in the Bengio et al. paper is not applied over the LSTM output, but over the output of an attention model, which is calculated from the LSTM's hidden state at a given timestep. The output of the softmax is then used to modify the LSTM's internal state. Essentially, attention is something that happens within an LSTM since it is both based on and modifies its internal states. I actually made my own attempt to create an attentional LSTM in Keras, based on the very same paper you cited, which I've shared here: https://gist.github.com/mbollmann/ccc735366221e4dba9f89d2aab86da1e There are several different ways to incorporate attention into an LSTM, and I won't claim 100% correctness of my implementation (though I'd appreciate any hints if something seems terribly wrong!), but I'd be surprised if it was as simple as adding a softmax activation. |
|
@mbollmann You are correct that none of the solutions @patyork is what i want. i want to get a weight distribution (importance) for the outputs from each timestep of the RNN. Like in the paper: "Hierarchical Attention Networks for Document Classification" but in my case i want just the representation of a sentence. I am trying to implement this using the available keras layers. Similar idea in this paper. |
|
@baziotis That indeed looks conceptually much simpler. I could just take a very short glance right now, but is there a specific point where you got stuck? |
|
@mbollmann Please do if you can. I don't have a working solution but i think i should set Also i think that putting Edit: to clarify i want to implement an attention mechanism like the one in [1].
|

|
I tried this: _input = Input(shape=[max_length], dtype='int32')
# get the embedding layer
embedded = embeddings_layer(embeddings=embeddings_matrix,
trainable=False, masking=False, scale=False, normalize=False)(_input)
activations = LSTM(64, return_sequences=True)(embedded)
# attention
attention = TimeDistributed(Dense(1, activation='tanh'))(activations)
attention = Flatten()(attention)
attention = Activation('softmax')(attention)
activations = Merge([activations, attention], mode='mul')
probabilities = Dense(3, activation='softmax')(activations)
model = Model(input=_input, output=probabilities)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=[])and i get the following error: |
|
@baziotis The cause of the error probably is that you need to use the Apart from that, as far as I understood it: The part with the For the multiplication with a trained context vector/parameter vector, I believe (no longer -- see EDIT) this might be a simple (EDIT: Nope, doesn't seem that way, they train a parameter vector with dimensionality of the embedding, not a matrix with a timestep dimension.) |
|
My apologies; this would explain why I was not impressed with the results from my "attention" implementation. There is an implementation here that seems to be working for people. |
|
@mbollmann you were right about the I think this is really close: units = 64
max_length = 50
_input = Input(shape=[max_length], dtype='int32')
# get the embedding layer
embedded = embeddings_layer(embeddings=embeddings_matrix,
trainable=False, masking=False, scale=False, normalize=False)(_input)
activations = LSTM(units, return_sequences=True)(embedded)
# compute importance for each step
attention = TimeDistributed(Dense(1, activation='tanh'))(activations)
attention = Flatten()(attention)
attention = Activation('softmax')(attention)
attention = RepeatVector(units)(attention)
attention = Permute([2, 1])(attention)
# apply the attention
sent_representation = merge([activations, attention], mode='mul')
sent_representation = Lambda(lambda xin: K.sum(xin, axis=0))(sent_representation)
sent_representation = Flatten()(sent_representation)
probabilities = Dense(3, activation='softmax')(sent_representation)
model = Model(input=_input, output=probabilities)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=[])but i get an error because Lamda doesn't output the right dimensions. I should be getting [1,units] right? Update: i tried explicitly passing the sent_representation = merge([activations, attention], mode='mul')
sent_representation = Lambda(lambda xin: K.sum(xin, axis=0), output_shape=(units, ))(sent_representation)
# sent_representation = Flatten()(sent_representation)but now i get the following error: |
|
Well i found out why it wasn't working. I was expecting the input to Lamda to be (max_length, units) but it was (None, max_length, units), so i just had to change the axis to 1. This now works. units = 64
max_length = 50
vocab_size = embeddings.shape[0]
embedding_size = embeddings.shape[1]
_input = Input(shape=[max_length], dtype='int32')
# get the embedding layer
embedded = Embedding(
input_dim=vocab_size,
output_dim=embedding_size,
input_length=max_length,
trainable=trainable,
mask_zero=masking,
weights=[embeddings]
)(_input)
activations = LSTM(units, return_sequences=True)(embedded)
# compute importance for each step
attention = TimeDistributed(Dense(1, activation='tanh'))(activations)
attention = Flatten()(attention)
attention = Activation('softmax')(attention)
attention = RepeatVector(units)(attention)
attention = Permute([2, 1])(attention)
# apply the attention
sent_representation = merge([activations, attention], mode='mul')
sent_representation = Lambda(lambda xin: K.sum(xin, axis=1))(sent_representation)
probabilities = Dense(3, activation='softmax')(sent_representation)
model = Model(input=_input, output=probabilities)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=[])I would like if someone could verify that this implementation is correct. |
|
@baziotis Looks good to me. I re-read the description in Zhou et al. and the code looks like it does what they describe. I no longer understand how what they're doing does anything useful, since the attention model only depends on the input and applies the same weights at every timestep, but ... that's probably just my insufficient understanding (I'm used to slightly different types of attention). :) |
|
@mbollmann i am confused about the same thing. can you give an example of the type of attention that you have in mind? I think that i have to put the word (embedding) in the calculation of the attention. From what i understand the Dense layer:
I plotted the weights of the
The problem is that this is static. If an important word happens to occur in a position with a small weight then the representation of the sentence won't be good enough. I would like some feedback on this, and preferably a good paper with a better attention mechanism. |

|
@baziotis Are you sure you don't have it the wrong way around? The Dense layer takes the output of the LSTM at one timestep and transforms it. The TimeDistributed wrapper applies the same Dense layer with the same weights to each timestep -- which means the output of the calculation cannot depend on the position/timestep since the Dense layer doesn't even know about it. So my confusion seems to be of a different nature than yours. :) (In short: I don't see what calculating a softmax and multiplying the original vector by that gets you that a plain |
|
@mbollmann I'm also a bit confused (but I have been from the get go). I think this blog post is fairly informative, or at least has some decent pictures. So, @baziotis is using time series with multiple output steps (LSTM, with I'm thinking the code above is just the line |

|
@mbollmann i thought that the TimeDistributed applies different weights to each timestep... |
|
TimeDistributed applies the same weight set across every timestep. You'd need to setup a standard Dense layer as a matrix e.g. |
|
Sorry for the miss-click. activations = LSTM(units, return_sequences=True)(embedded)
# compute importance for each step
attention = Dense(50 , activation='tanh')(activations)
attention = Flatten()(attention) |
|
Actually, no, I think you would just remove the |
|
So I guess that is what you are looking for.
_input = Input(shape=[max_length], dtype='int32')
# get the embedding layer
embedded = Embedding(
input_dim=vocab_size,
output_dim=embedding_size,
input_length=max_length,
trainable=False,
mask_zero=False
)(_input)
activations = LSTM(units, return_sequences=True)(embedded)
# compute importance for each step
attention = Dense(1, activation='tanh')(activations)
attention = Flatten()(attention)
attention = Activation('softmax')(attention)
attention = RepeatVector(units)(attention)
attention = Permute([2, 1])(attention)
sent_representation = merge([activations, attention], mode='mul')
sent_representation = Lambda(lambda xin: K.sum(xin, axis=-2), output_shape=(units,))(sent_representation)
probabilities = Dense(3, activation='softmax')(sent_representation)I think this (ugly) chart maps the above out pretty well; it's up to you to determine if it makes sense for what you are doing: |

|
@patyork Thanks! I think this is what is described in the paper. I have a question about this line: sent_representation = Lambda(lambda xin: K.sum(xin, axis=-2), output_shape=(units,))(sent_representation)Why |
|
continuing from my last comment, this is what is described in the blog post that you mentioned. See after the image that you posted...
What different kind of attention do you have in mind? In the article attention is described in the context of machine translation. In my case (classification) i just want a better representation for the sentence. |
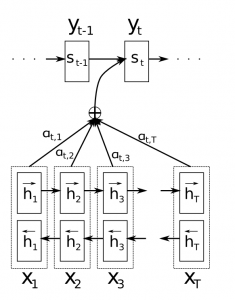
|
Yeah, after thinking about this, it makes sense. The softmax multiplication will weight the timestep outputs (most will be near zero, some nearer to 1) and the so the sum of those will be close to the outputs of the "near to 1" timesteps - pretty clever. In this case, I just mean that implementation seems a little limiting - you have to set |
|
Phew, a lot happened here, and I think I agree with most of what was written. Using |
|
@mbollmann I read that - it seems like you talked yourself out of that at some point though, based on the edit. I was confusing/arguing with myself to no end throughout this entire issue as well. I learned quite a bit though, at least. |
|
@patyork @mbollmann Thank you both! I learned a lot. Btw after runnng some tests, i am not impressed. I see no obvious improvement compared to the classic senario (using just the last timestep). But the idea is interesting... @patyork This may be stupid, but what do you mean by saying:
Why are they thrown? They are used in the weighted sum, aren't they? * *Do you mean the timesteps that are padded to keep a constant length? |
|
Hey, have a look at this repo: https://github.com/philipperemy/keras-attention-mechanism It shows how to build an attention module of top of a recurrent layer. Thanks |
|
@philipperemy I tested your approach. Indeed you can learn an attention vector, but testing across a suite of contrived problems, I see the model is just as skillful as a plan Dense + LSTM combination. Attention is an optimization that should lift skill or decrease training time for the same skill. Perhaps you have an example where your approach is more skillful than a straight Dense + LSTM setup with the same resources? @cbaziotis After testing, I believe your attention method is something new/different inspired by Bahdanau, et al. [1]. It does not appear skillful on contrived problems either. Perhaps you have a good demonstration of where it does do well? @mbollmann is correct as far as I can tell. The attention approach of Bahdanau, et al. requires access to the decoder hidden state (decoder output) of the last time step in order to compute the current time step (s_i-1 in the paper). This is unavailable unless you write your own layer and access it. |
|
@jbrownlee |
|
@cbaziotis , How will the above attention mechanism work for the imdb example in keras? The input size is (5000, 80) (#max_length=80) and output is (5000, ). This the model for training : |
|
Hi, @cbaziotis Thanks for your code. |
|
If you read carefully you will see that i have posted the updated versions of the layers. Here you go: model.add(LSTM(64, return_sequences=True))
model.add(AttentionWithContext())
# next add a Dense layer (for classification/regression) or whatever...model.add(LSTM(64, return_sequences=True))
model.add(Attention())
# next add a Dense layer (for classification/regression) or whatever...And as i say, the layers take into account the mask. |
|
does the attention+lstm improve the accuracy in text classification? In my dataset, I find that, there is no difference with mean pooling + lstm. |
|
@cbaziotis I have a query regarding the attention: I read somewhere, that in that hh is hidden state and cc is the cell state. Are hh and cc the final hidden and cell states? Also what is the difference between attention and attention with context |
|
@Ravin0512 Any updates? |
|
@Ravin0512 i recently made this tool https://github.com/cbaziotis/neat-vision Just make sure to return the attention scores besides the final representation of the sentence from the attention layer. |
|
@cbaziotis As per sharing the weights across time-steps, I think it is fine. Even Andrew Ng's Sequence Models course have shared weight implementation. |
inputs=Input(shape=(input_len,)) isnt it the same as the Long Version the dot function contracts the Tensor at the axis=1 sum_t a_t*h_th= h_h the dense layer for the activation shouldnt have a bias, since the weights accoording th zhou work only on the hidden components of the hidden states. further more in zhous model a linear activation is enough as far as i understood the Attention-dense layer has to be time distributed. because the weights act on the hidden states components they have the same role mor or less as all matrices in the the recurrent layer which all share the weights over time. the time dependence oft the activation factors rises from the the hidden state differences (components deiffer an therefore alpha(t)=softmax(w^T*h_t) differs, |
|
@Ravin0512 I just found an ugly method. |
|
@cbaziotis the best attention visualization tools I have ever seen 👍 |
|
i want to Regression output with Attention LSTM I tried this: but gives the following error:
` my understanding may be inadequate... |
|
Sorry, made an error, activaton and flatten had to be changed, (first flatten and than activation('softmax') fixed it. I tested my Version, and it worked, so far as i could see here is the graph of an example with 1 layer GRU und nextword prediction with attantion including shapes for clarification (for real language processing typical stacked lstms insteand of grus and higher hidden_dims and embedding_dims are used. ist only a toy example)
|

|
Hi, @stevewyl -- what is inside that |
|
attention = Flatten()(attention) |
|
Hello all , I am trying to use attention on top of a BiLSTM in tensorflow 2. my model is the following: Could you please let me know if my implementation is correct ? Thanks in advance. |
|
here a simple solution to add attention in your network |
|
Hey everyone. I saw that everyone adds Dense( ) layer in their custom attention layer, which I think isn't needed.
This is an image from a tutorial here. Here, we are just multiplying 2 vectors and then doing several operations on these vectors only. So what is the need of Dense( ) layer. Is the tutorial on 'how does attention work' wrong? |

Thanks Philip. Your implementation is clean and easy to follow. |
Same question I have |
I am doing text classification. Also I am using my pre-trained word embeddings and i have a
LSTMlayer on top with asoftmaxat the end.Pretty simple. Now I want to add attention to the model, but i don't know how to do it.
My understanding is that i have to set
return_sequences=Trueso as the attention layer will weigh each timestep accordingly. This way the LSTM will return a 3D Tensor, right?After that what do i have to do?
Is there a way to easily implement a model with attention using Keras Layers or do i have to write my own custom layer?
If this can be done with the available Keras Layers, I would really appreciate an example.
The text was updated successfully, but these errors were encountered: