

Need a simple and powerful Gaussian-mixture code in pure python? It can be as easy as this:
import pygmmis
gmm = pygmmis.GMM(K=K, D=D) # K components, D dimensions
logL, U = pygmmis.fit(gmm, data) # logL = log-likelihood, U = association of data to componentsHowever, pyGMMis has a few extra tricks up its sleeve.
- It can account for independent multivariate normal measurement errors for each of the observed samples, and then recovers an estimate of the error-free distribution. This technique is known as "Extreme Deconvolution" by Bovy, Hogg & Roweis (2011).
- It works with missing data (features) by setting the respective elements of the covariance matrix to a vary large value, thus effectively setting the weights of the missing feature to 0.
- It can deal with gaps (aka "truncated data") and variable sample completeness as long as
- you know the incompleteness over the entire feature space,
- and the incompleteness does not depend on the sample density (missing at random).
- It can incorporate a "background" distribution (implemented is a uniform one) and separate signal from background, with the former being fit by the GMM.
- It keeps track of which components need to be evaluated in which regions of the feature space, thereby substantially increasing the performance for fragmented data.
If you want more context and details on those capabilities, have a look at this blog post.
Under the hood, pyGMMis uses the Expectation-Maximization procedure. When dealing with sample incompleteness it generates its best guess of the unobserved samples on the fly given the current model fit to the observed samples.
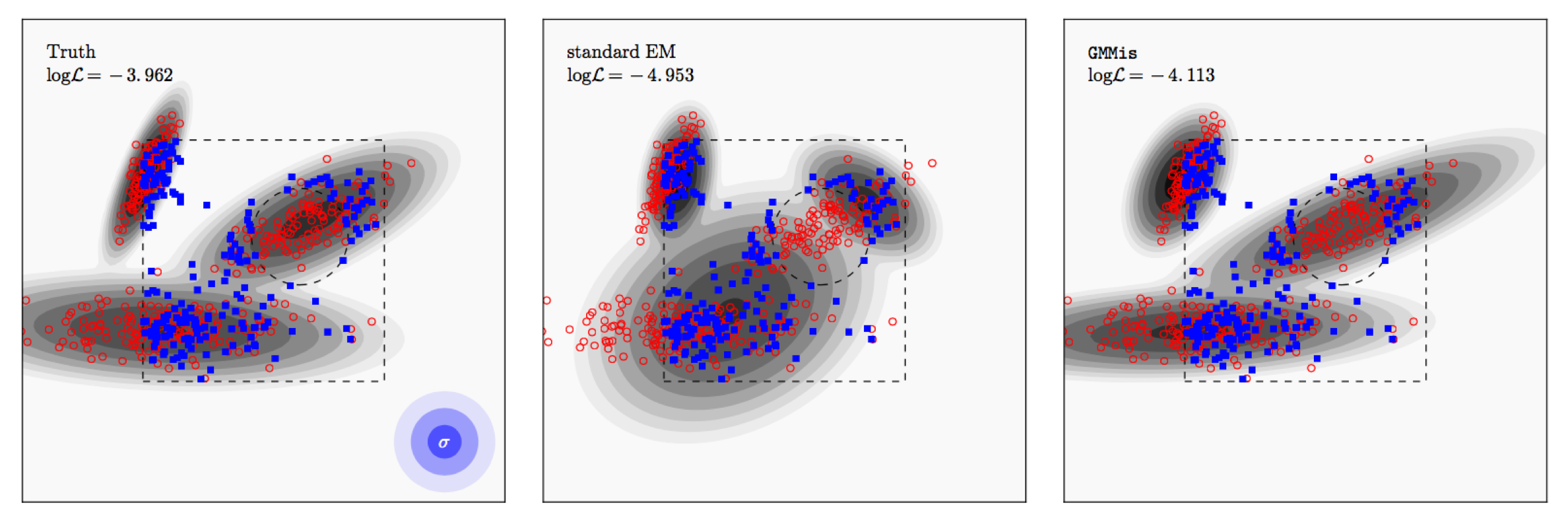
In the example above, the true distribution is shown as contours in the left panel. We then draw 400 samples from it (red), add Gaussian noise to them (1,2,3 sigma contours shown in blue), and select only samples within the box but outside of the circle (blue).
The code is written in pure python (developed and tested in 2.7), parallelized with multiprocessing, and is capable of performing density estimation with millions of samples and thousands of model components on machines with sufficient memory.
More details are in the paper listed in the file CITATION.cff.
You can either clone the repo and install by python setup.py install or get the latest release with
pip install pygmmis
Dependencies:
- numpy
- scipy
- multiprocessing
- parmap
-
Create a GMM object with the desired component number K and data dimensionality D:
gmm = pygmmis.GMM(K=K, D=D) -
Define a callback for the completeness function. When called with with
datawith shape(N,D)and returns the probability of each sample getting observed. Two simple examples:def cutAtSix(coords): """Selects all samples whose first coordinate is < 6""" return (coords[:,0] < 6) def selSlope(coords, rng=np.random): """Selects probabilistically according to first coordinate x: Omega = 1 for x < 0 = 1-x for x = 0 .. 1 = 0 for x > 1 """ return np.max(0, np.min(1, 1 - coords[:,0]))
-
If the samples are noisy (i.e. they have positional uncertainties), you need to provide the covariance matrix of each data sample, or one for all in case of i.i.d. noise.
-
If the samples are noisy and there completeness function isn't constant, you need to provide a callback function that returns an estimate of the covariance at arbitrary locations:
# example 1: simply using the same covariance for all samples dispersion = 1 default_covar = np.eye(D) * dispersion**2 covar_cb = lambda coords: default_covar # example: use the covariance of the nearest neighbor. def covar_tree_cb(coords, tree, covar): """Return the covariance of the nearest neighbor of coords in data.""" dist, ind = tree.query(coords, k=1) return covar[ind.flatten()] from sklearn.neighbors import KDTree tree = KDTree(data, leaf_size=100) from functools import partial covar_cb = partial(covar_tree_cb, tree=tree, covar=covar)
-
If there is a uniform background signal, you need to define it. Because a uniform distribution is normalizable only if its support is finite, you need to decide on the footprint over which the background model is present, e.g.:
footprint = data.min(axis=0), data.max(axis=0) amp = 0.3 bg = pygmmis.Background(footprint, amp=amp) # fine tuning, if desired bg.amp_min = 0.1 bg.amp_max = 0.5 bg.adjust_amp = False # freezes bg.amp at current value
-
Select an initialization method. This tells the GMM what initial parameters is should assume. The options are
'minmax','random','kmeans','none'. See the respective functions for details:pygmmis.initFromDataMinMax()pygmmis.initFromDataAtRandom()pygmmis.initFromKMeans()
For difficult situations, or if you are not happy with the convergence, you may want to experiment with your own initialization. All you have to do is set
gmm.amp,gmm.mean, andgmm.covarto desired values and useinit_method='none'. -
Decide to freeze out any components. This makes sense if you know some of the parameters of the components. You can freeze amplitude, mean, or covariance of any component by listing them in a dictionary, e.g:
frozen={"amp": [1,2], "mean": [], "covar": [1]}
This freezes the amplitudes of component 1 and 2 (NOTE: Counting starts at 0), and the covariance of 1.
-
Run the fitter:
w = 0.1 # minimum covariance regularization, same units as data cutoff = 5 # segment the data set into neighborhood within 5 sigma around components tol = 1e-3 # tolerance on logL to terminate EM # define RNG for deterministic behavior from numpy.random import RandomState seed = 42 rng = RandomState(seed) # run EM logL, U = pygmmis.fit(gmm, data, init_method='random',\ sel_callback=cb, covar_callback=covar_cb, w=w, cutoff=cutoff,\ background=bg, tol=tol, frozen=frozen, rng=rng)
This runs the EM procedure until tolerance is reached and returns the final mean log-likelihood of all samples, and the neighborhood of each component (indices of data samples that are within cutoff of a GMM component).
-
Evaluate the model:
# log of p(x) p = gmm(test_coords, as_log=False) N_s = 1000 # draw samples from GMM samples = gmm.draw(N_s) # draw sample from the model with noise, background, and selection: # if you want to get the missing sample, set invert_sel=True. # N_orig is the estimated number of samples prior to selection obs_size = len(data) samples, covar_samples, N_orig = pygmmis.draw(gmm, obs_size, sel_callback=cb,\ invert_sel=False, orig_size=None,\ covar_callback=covar_cb,background=bg)
For a complete example, have a look at the test script. For requests and bug reports, please open an issue.