CPP extension for overdrive effect in functional #580
Conversation
Signed-off-by: Bhargav Kathivarapu <bhargavkathivarapu31@gmail.com>
Signed-off-by: Bhargav Kathivarapu <bhargavkathivarapu31@gmail.com>
Signed-off-by: Bhargav Kathivarapu <bhargavkathivarapu31@gmail.com>
|
Thanks for the PR. This is exciting. I will take a look into it.
Environment (Docker `nvidia/cuda:10.1-cudnn7-devel-ubuntu18.04`)TimeStretchSpectrogram |
My remote docker GPU environmentCollecting environment information...PyTorch version: 1.4.0 OS: Ubuntu 18.04.3 LTS Python version: 3.6 Nvidia driver version: 410.79 Versions of relevant libraries: |
There was a problem hiding this comment.
Adding C++ extensions is an ongoing topic of discussion for torchaudio/torchtext/torchvision (cc @fmassa), and requires some alignment, since we need to do so in a pytorch way to maintain jitability, and gpu-support. For instance:
- We would love to see
torchaudio.loadlinked in a way that maintains jitability. - In CPP Implementation of lfilter for CPU #290, we decided to delay merging a C++ implementation of
lfilterfor these reasons even though we know that the pytorch implementation is slower.
Since this is of interest to you, and we are indeed interested in offering something like this, we can provide guidance to align this with our plans though it will take a little bit more time to get this merged properly.
|
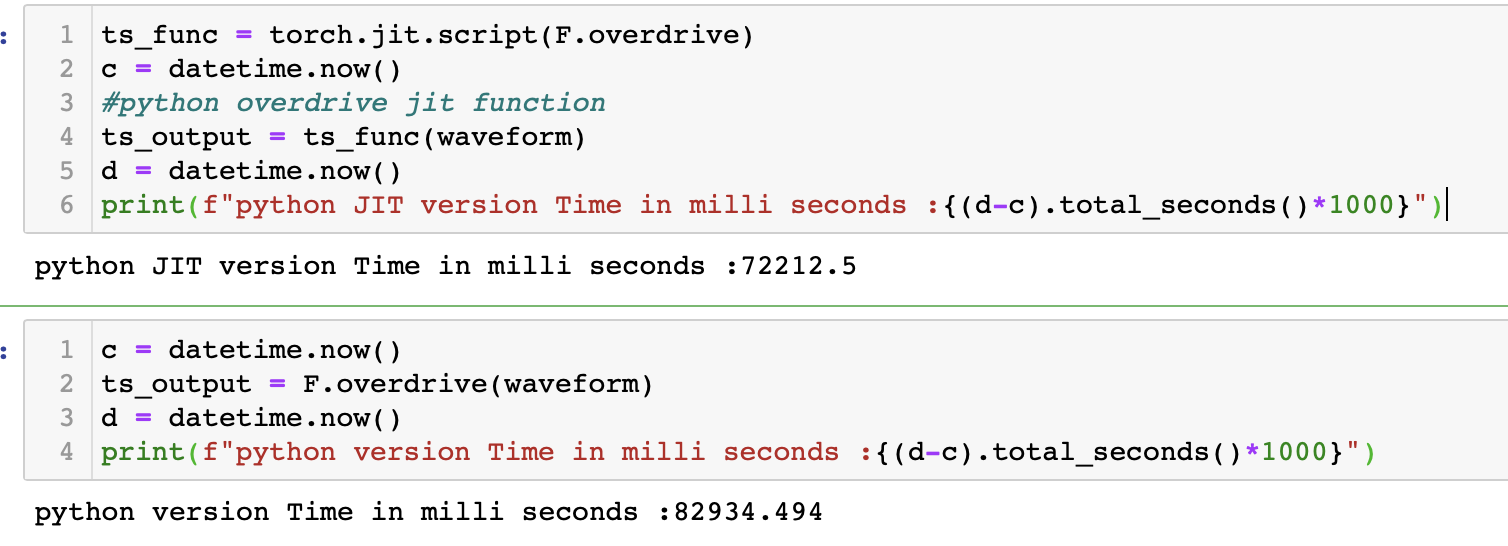
For completeness, in terms of performance, it'd be nice to see a comparison with the jitted version available in pytorch. :) |
comparsion between jit and python versions for overdrive implemented using python.
|
ok . Once the approach for the integrating cpp, cuda extensions is finalized may be you can put an github issue for optimizing existing codes, I would like to contribute and learn some torch cpp and cuda internals in the process |
| int64_t n_frames = waveform_accessor.size(1); | ||
| int64_t n_channels = waveform_accessor.size(0); | ||
|
|
||
| for (int64_t i_channel = 0; i_channel < n_channels; ++i_channel) { |
There was a problem hiding this comment.
Depending on the amount of work you might benefit from using parallel_for.
Most PyTorch CPU operators are parallelized, unless there's no obvious need due to memory-boundedness.
Another issue with pure C for C++ extensions, for now, is autovectorization. We can't ship avx2 code without a CPU capability based dispatch. That means for C code in extensions like this we're for now restricted to SSE and related.
Of course this is taken care of when you call into at:: operations directly, since they each take advantage being part of libtorch.
There was a problem hiding this comment.
@cpuhrsch , yeah parallelization can be applied only for the channels loop . I was not sure how the parallel_for treats the inner sequential loop , so kept it without the parallel_for. A parallel thread won't interfere with other parallel thread's inner loop working right ?
There was a problem hiding this comment.
@bhargavkathivarapu - I'm not sure what you mean by "interfere with" exactly. As in, shared variables or creating integers etc.? In this particular case it seems that the inner loops are independent of each other given that they differ in i_channel. The pointers and such will still be picked up as shared variables, but as long as you don't write to a single memory location from multiple threads concurrently etc., there's no issue.
By default PyTorch uses openmp which yields this implementation. Look into openmp's omp parallel (here is what looks like a good explanation) for some more detail on what that means.
| for (int64_t i_frame = 0; i_frame < n_frames; ++i_frame) { | ||
| last_out_accessor[i_channel] = temp_accessor[i_channel][i_frame] - | ||
| last_in_accessor[i_channel] + 0.995 * last_out_accessor[i_channel]; | ||
| last_in_accessor[i_channel] = temp_accessor[i_channel][i_frame]; |
There was a problem hiding this comment.
You're setting the value of last_in to the value of temp for the current iteration so that the next iteration those values may be used . But instead you could just read from temp all the time (except for the first iteration) right? I added a similar comment for the Python code above.
There was a problem hiding this comment.
But instead you could just read from temp all the time (except for the first iteration) right?
Yes , the first iteration needs to be handled then we can remove the last_in variable
|
Sorry for taking such long time to get back to this, but we finally cleaned up the build process and how we can write C++ extension. Recently, @parmeet has added C++ loop for |
|
Hi @mthrok , Thanks for sharing the update on this. I will try to implement |
|
Closing this PR as there is new version of this PR (new - #1299 ) |
Hi ,
I have tried implementing existing fucntional
overdriveusing cpp as the python version is slow compared to Sox version . ( #260 ( Reducing dependency in Sox) )Though cpp version is slight slower than sox version . It is much better compated to python version
Almost >700X speed compared to python implementation
ENV : pytorch - 1.4 , CUDA 10 , Multi GPU
Below is a part of the log
Any idea of this error above "Can't redefine method: forward on class"
@mthrok or @vincentqb could review these changes