Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Implement fast pass for CPU scalars /number literals (#29915)
Summary:
The main changes in this PR are:
- skip device dispatch for CPU scalars (number literals also fall into this). In most cases scalars should be on CPU for best perf, but if users explicitly put on other device, we will respect that setting and exit fast pass.
- directly manipulate Tensor data_ptr when filling scalar into a 1-element tensor.
Some perf benchmark numbers:
```
## Before
In [4]: def test(x):
...: x = x + 2
...: return x
...:
In [5]: with torch.no_grad():
...: x = torch.ones(100)
...: %timeit {test(x)}
...:
79.8 µs ± 127 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
## After
In [2]: def test(x):
...: x = x + 2
...: return x
...:
In [3]: with torch.no_grad():
...: x = torch.ones(100)
...: %timeit {test(x)}
...:
60.5 µs ± 334 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
```
Before the patch `tensor_slow` took 15.74% of total time.
<img width="1186" alt="Screen Shot 2019-11-15 at 12 49 51 PM" src="https://user-images.githubusercontent.com/5248122/68976895-cc808c00-07ab-11ea-8f3c-7f15597d12cf.png">
After the patch `tensor_slow` takes 3.84% of total time.
<img width="1190" alt="Screen Shot 2019-11-15 at 1 13 03 PM" src="https://user-images.githubusercontent.com/5248122/68976925-e28e4c80-07ab-11ea-94c0-91172fc3bb53.png">
cc: roosephu who originally reported this issue to me.
Pull Request resolved: #29915
Differential Revision: D18584251
Pulled By: ailzhang
fbshipit-source-id: 2353c8012450a81872e1e09717b3b181362be401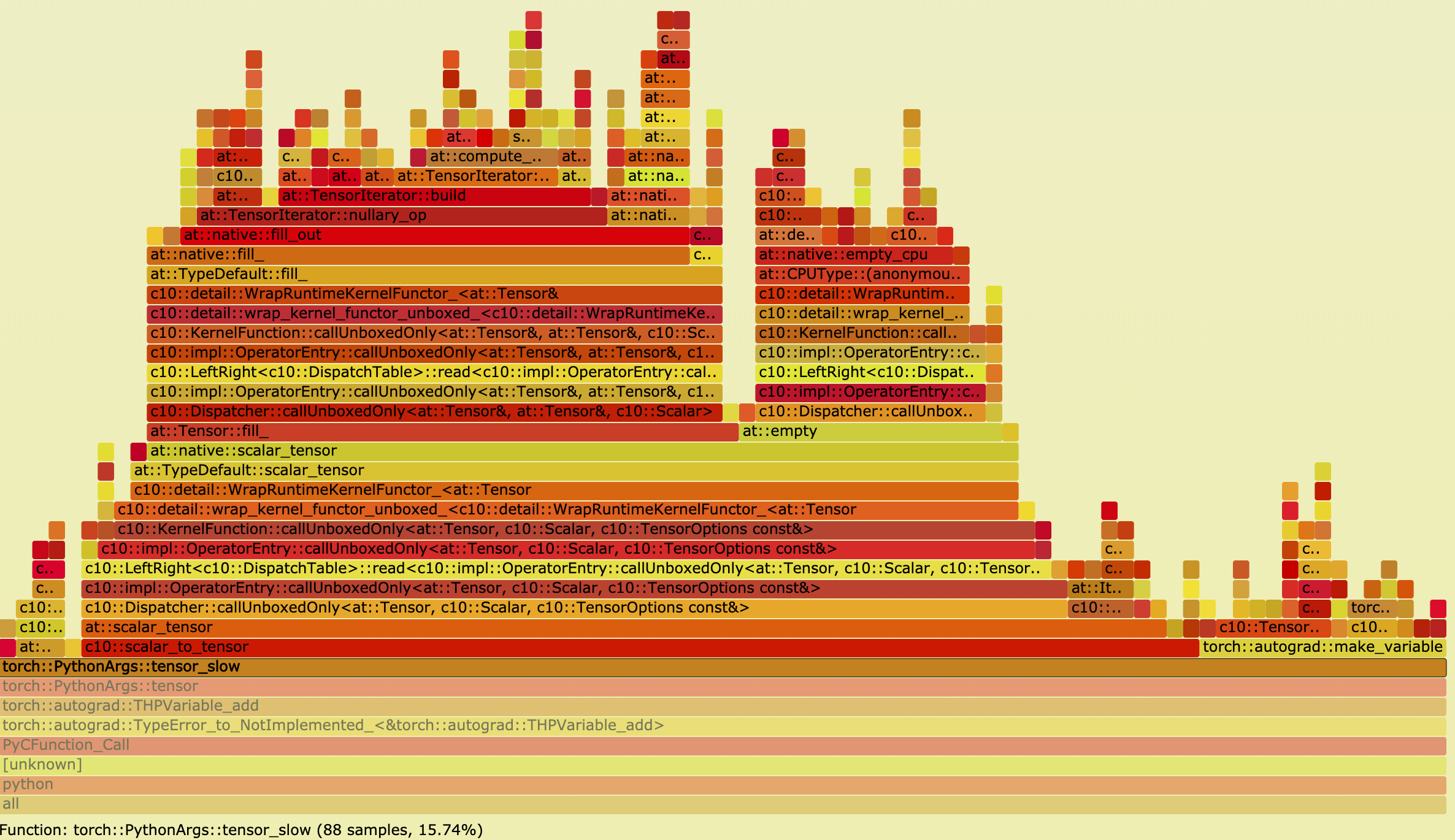{kind=link}
{kind=link}
- Loading branch information
1 parent
e88d096
commit 2b02d15