Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Treat has_torch_function and object_has_torch_function as static Fals…
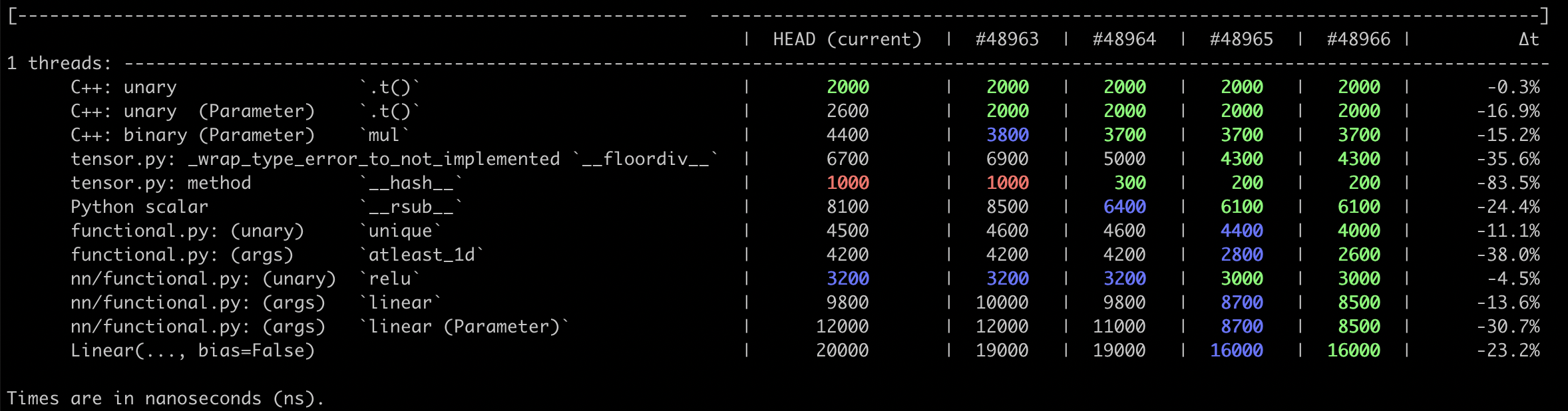
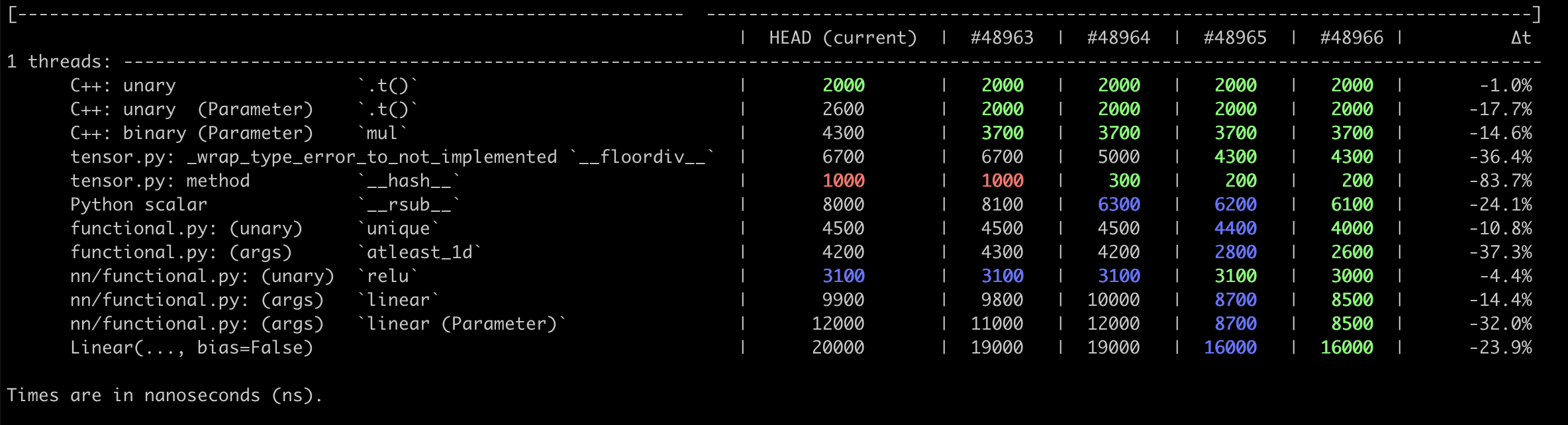
…e when scripting (#48966) Summary: Pull Request resolved: #48966 This PR lets us skip the `if not torch.jit.is_scripting():` guards on `functional` and `nn.functional` by directly registering `has_torch_function` and `object_has_torch_function` to the JIT as statically False. **Benchmarks** The benchmark script is kind of long. The reason is that it's testing all four PRs in the stack, plus threading and subprocessing so that the benchmark can utilize multiple cores while still collecting good numbers. Both wall times and instruction counts were collected. This stack changes dozens of operators / functions, but very mechanically such that there are only a handful of codepath changes. Each row is a slightly different code path (e.g. testing in Python, testing in the arg parser, different input types, etc.) <details> <summary> Test script </summary> ``` import argparse import multiprocessing import multiprocessing.dummy import os import pickle import queue import random import sys import subprocess import tempfile import time import torch from torch.utils.benchmark import Timer, Compare, Measurement NUM_CORES = multiprocessing.cpu_count() ENVS = { "ref": "HEAD (current)", "torch_fn_overhead_stack_0": "#48963", "torch_fn_overhead_stack_1": "#48964", "torch_fn_overhead_stack_2": "#48965", "torch_fn_overhead_stack_3": "#48966", } CALLGRIND_ENVS = tuple(ENVS.keys()) MIN_RUN_TIME = 3 REPLICATES = { "longer": 1_000, "long": 300, "short": 50, } CALLGRIND_NUMBER = { "overnight": 500_000, "long": 250_000, "short": 10_000, } CALLGRIND_TIMEOUT = { "overnight": 800, "long": 400, "short": 100, } SETUP = """ x = torch.ones((1, 1)) y = torch.ones((1, 1)) w_tensor = torch.ones((1, 1), requires_grad=True) linear = torch.nn.Linear(1, 1, bias=False) linear_w = linear.weight """ TASKS = { "C++: unary `.t()`": "w_tensor.t()", "C++: unary (Parameter) `.t()`": "linear_w.t()", "C++: binary (Parameter) `mul` ": "x + linear_w", "tensor.py: _wrap_type_error_to_not_implemented `__floordiv__`": "x // y", "tensor.py: method `__hash__`": "hash(x)", "Python scalar `__rsub__`": "1 - x", "functional.py: (unary) `unique`": "torch.functional.unique(x)", "functional.py: (args) `atleast_1d`": "torch.functional.atleast_1d((x, y))", "nn/functional.py: (unary) `relu`": "torch.nn.functional.relu(x)", "nn/functional.py: (args) `linear`": "torch.nn.functional.linear(x, w_tensor)", "nn/functional.py: (args) `linear (Parameter)`": "torch.nn.functional.linear(x, linear_w)", "Linear(..., bias=False)": "linear(x)", } def _worker_main(argv, fn): parser = argparse.ArgumentParser() parser.add_argument("--output_file", type=str) parser.add_argument("--single_task", type=int, default=None) parser.add_argument("--length", type=str) args = parser.parse_args(argv) single_task = args.single_task conda_prefix = os.getenv("CONDA_PREFIX") assert torch.__file__.startswith(conda_prefix) env = os.path.split(conda_prefix)[1] assert env in ENVS results = [] for i, (k, stmt) in enumerate(TASKS.items()): if single_task is not None and single_task != i: continue timer = Timer( stmt=stmt, setup=SETUP, sub_label=k, description=ENVS[env], ) results.append(fn(timer, args.length)) with open(args.output_file, "wb") as f: pickle.dump(results, f) def worker_main(argv): _worker_main( argv, lambda timer, _: timer.blocked_autorange(min_run_time=MIN_RUN_TIME) ) def callgrind_worker_main(argv): _worker_main( argv, lambda timer, length: timer.collect_callgrind(number=CALLGRIND_NUMBER[length], collect_baseline=False)) def main(argv): parser = argparse.ArgumentParser() parser.add_argument("--long", action="store_true") parser.add_argument("--longer", action="store_true") args = parser.parse_args(argv) if args.longer: length = "longer" elif args.long: length = "long" else: length = "short" replicates = REPLICATES[length] num_workers = int(NUM_CORES // 2) tasks = list(ENVS.keys()) * replicates random.shuffle(tasks) task_queue = queue.Queue() for _ in range(replicates): envs = list(ENVS.keys()) random.shuffle(envs) for e in envs: task_queue.put((e, None)) callgrind_task_queue = queue.Queue() for e in CALLGRIND_ENVS: for i, _ in enumerate(TASKS): callgrind_task_queue.put((e, i)) results = [] callgrind_results = [] def map_fn(worker_id): # Adjacent cores often share cache and maxing out a machine can distort # timings so we space them out. callgrind_cores = f"{worker_id * 2}-{worker_id * 2 + 1}" time_cores = str(worker_id * 2) _, output_file = tempfile.mkstemp(suffix=".pkl") try: loop_tasks = ( # Callgrind is long running, and then the workers can help with # timing after they finish collecting counts. (callgrind_task_queue, callgrind_results, "callgrind_worker", callgrind_cores, CALLGRIND_TIMEOUT[length]), (task_queue, results, "worker", time_cores, None)) for queue_i, results_i, mode_i, cores, timeout in loop_tasks: while True: try: env, task_i = queue_i.get_nowait() except queue.Empty: break remaining_attempts = 3 while True: try: subprocess.run( " ".join([ "source", "activate", env, "&&", "taskset", "--cpu-list", cores, "python", os.path.abspath(__file__), "--mode", mode_i, "--length", length, "--output_file", output_file ] + ([] if task_i is None else ["--single_task", str(task_i)])), shell=True, check=True, timeout=timeout, ) break except subprocess.TimeoutExpired: # Sometimes Valgrind will hang if there are too many # concurrent runs. remaining_attempts -= 1 if not remaining_attempts: print("Too many failed attempts.") raise print(f"Timeout after {timeout} sec. Retrying.") # We don't need a lock, as the GIL is enough. with open(output_file, "rb") as f: results_i.extend(pickle.load(f)) finally: os.remove(output_file) with multiprocessing.dummy.Pool(num_workers) as pool: st, st_estimate, eta, n_total = time.time(), None, "", len(tasks) * len(TASKS) map_job = pool.map_async(map_fn, range(num_workers)) while not map_job.ready(): n_complete = len(results) if n_complete and len(callgrind_results): if st_estimate is None: st_estimate = time.time() else: sec_per_element = (time.time() - st_estimate) / n_complete n_remaining = n_total - n_complete eta = f"ETA: {n_remaining * sec_per_element:.0f} sec" print( f"\r{n_complete} / {n_total} " f"({len(callgrind_results)} / {len(CALLGRIND_ENVS) * len(TASKS)}) " f"{eta}".ljust(40), end="") sys.stdout.flush() time.sleep(2) total_time = int(time.time() - st) print(f"\nTotal time: {int(total_time // 60)} min, {total_time % 60} sec") desc_to_ind = {k: i for i, k in enumerate(ENVS.values())} results.sort(key=lambda r: desc_to_ind[r.description]) # TODO: Compare should be richer and more modular. compare = Compare(results) compare.trim_significant_figures() compare.colorize(rowwise=True) # Manually add master vs. overall relative delta t. merged_results = { (r.description, r.sub_label): r for r in Measurement.merge(results) } cmp_lines = str(compare).splitlines(False) print(cmp_lines[0][:-1] + "-" * 15 + "]") print(f"{cmp_lines[1]} |{'':>10}\u0394t") print(cmp_lines[2] + "-" * 15) for l, t in zip(cmp_lines[3:3 + len(TASKS)], TASKS.keys()): assert l.strip().startswith(t) t0 = merged_results[(ENVS["ref"], t)].median t1 = merged_results[(ENVS["torch_fn_overhead_stack_3"], t)].median print(f"{l} |{'':>5}{(t1 / t0 - 1) * 100:>6.1f}%") print("\n".join(cmp_lines[3 + len(TASKS):])) counts_dict = { (r.task_spec.description, r.task_spec.sub_label): r.counts(denoise=True) for r in callgrind_results } def rel_diff(x, x0): return f"{(x / x0 - 1) * 100:>6.1f}%" task_pad = max(len(t) for t in TASKS) print(f"\n\nInstruction % change (relative to `{CALLGRIND_ENVS[0]}`)") print(" " * (task_pad + 8) + (" " * 7).join([ENVS[env] for env in CALLGRIND_ENVS[1:]])) for t in TASKS: values = [counts_dict[(ENVS[env], t)] for env in CALLGRIND_ENVS] print(t.ljust(task_pad + 3) + " ".join([ rel_diff(v, values[0]).rjust(len(ENVS[env]) + 5) for v, env in zip(values[1:], CALLGRIND_ENVS[1:])])) print("\033[4m" + " Instructions per invocation".ljust(task_pad + 3) + " ".join([ f"{v // CALLGRIND_NUMBER[length]:.0f}".rjust(len(ENVS[env]) + 5) for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]) + "\033[0m") print() import pdb pdb.set_trace() if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("--mode", type=str, choices=("main", "worker", "callgrind_worker"), default="main") args, remaining = parser.parse_known_args() if args.mode == "main": main(remaining) elif args.mode == "callgrind_worker": callgrind_worker_main(remaining) else: worker_main(remaining) ``` </details> **Wall time** <img width="1178" alt="Screen Shot 2020-12-12 at 12 28 13 PM" src="https://user-images.githubusercontent.com/13089297/101994419-284f6a00-3c77-11eb-8dc8-4f69a890302e.png"> <details> <summary> Longer run (`python test.py --long`) is basically identical. </summary> <img width="1184" alt="Screen Shot 2020-12-12 at 5 02 47 PM" src="https://user-images.githubusercontent.com/13089297/102000425-2350e180-3c9c-11eb-999e-a95b37e9ef54.png"> </details> **Callgrind** <img width="936" alt="Screen Shot 2020-12-12 at 12 28 54 PM" src="https://user-images.githubusercontent.com/13089297/101994421-2e454b00-3c77-11eb-9cd3-8cde550f536e.png"> Test Plan: existing unit tests. Reviewed By: ezyang Differential Revision: D25590731 Pulled By: robieta fbshipit-source-id: fe05305ff22b0e34ced44b60f2e9f07907a099dd
{kind=link}
{kind=link}
{kind=link}
- Loading branch information
1 parent
d31a760
commit 6a3fc0c