move has_torch_function to C++, and make a special case object_has_torch_function #48965
Conversation
…rch_function [ghstack-poisoned]
💊 CI failures summary and remediationsAs of commit 3e9b809 (more details on the Dr. CI page):
This comment was automatically generated by Dr. CI (expand for details).Follow this link to opt-out of these comments for your Pull Requests.Please report bugs/suggestions to the (internal) Dr. CI Users group. This comment has been revised 129 times. |
…ject_has_torch_function" This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API. [ghstack-poisoned]
|
Ahhh. |
…ject_has_torch_function" This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API. [ghstack-poisoned]
…ject_has_torch_function" This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API. [ghstack-poisoned]
…ject_has_torch_function" This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API. [ghstack-poisoned]
…ject_has_torch_function" This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API. [ghstack-poisoned]
|
TODO: The logic in this PR should subsume the |
…ject_has_torch_function" This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API. [ghstack-poisoned]
…ject_has_torch_function" This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API. [ghstack-poisoned]
…ject_has_torch_function" This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API. [ghstack-poisoned]
…ject_has_torch_function" This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API. Test plan: Existing unit tests. Benchmarks are in #48966 [ghstack-poisoned]
…static False when scripting"
This PR lets us skip the `if not torch.jit.is_scripting():` guards on `functional` and `nn.functional` by directly registering `has_torch_function` and `object_has_torch_function` to the JIT as statically False.
**Benchmarks**
The benchmark script is kind of long. The reason is that it's testing all four PRs in the stack, plus threading and subprocessing so that the benchmark can utilize multiple cores while still collecting good numbers. Both wall times and instruction counts were collected. This stack changes dozens of operators / functions, but very mechanically such that there are only a handful of codepath changes. Each row is a slightly different code path (e.g. testing in Python, testing in the arg parser, different input types, etc.)
<details>
<summary> Test script </summary>
```
import argparse
import multiprocessing
import multiprocessing.dummy
import os
import pickle
import queue
import random
import sys
import subprocess
import tempfile
import time
import torch
from torch.utils.benchmark import Timer, Compare, Measurement
NUM_CORES = multiprocessing.cpu_count()
ENVS = {
"ref": "HEAD (current)",
"torch_fn_overhead_stack_0": "#48963",
"torch_fn_overhead_stack_1": "#48964",
"torch_fn_overhead_stack_2": "#48965",
"torch_fn_overhead_stack_3": "#48966",
}
CALLGRIND_ENVS = tuple(ENVS.keys())
MIN_RUN_TIME = 3
REPLICATES = {
"longer": 1_000,
"long": 300,
"short": 50,
}
CALLGRIND_NUMBER = {
"overnight": 500_000,
"long": 250_000,
"short": 10_000,
}
CALLGRIND_TIMEOUT = {
"overnight": 800,
"long": 400,
"short": 100,
}
SETUP = """
x = torch.ones((1, 1))
y = torch.ones((1, 1))
w_tensor = torch.ones((1, 1), requires_grad=True)
linear = torch.nn.Linear(1, 1, bias=False)
linear_w = linear.weight
"""
TASKS = {
"C++: unary `.t()`": "w_tensor.t()",
"C++: unary (Parameter) `.t()`": "linear_w.t()",
"C++: binary (Parameter) `mul` ": "x + linear_w",
"tensor.py: _wrap_type_error_to_not_implemented `__floordiv__`": "x // y",
"tensor.py: method `__hash__`": "hash(x)",
"Python scalar `__rsub__`": "1 - x",
"functional.py: (unary) `unique`": "torch.functional.unique(x)",
"functional.py: (args) `atleast_1d`": "torch.functional.atleast_1d((x, y))",
"nn/functional.py: (unary) `relu`": "torch.nn.functional.relu(x)",
"nn/functional.py: (args) `linear`": "torch.nn.functional.linear(x, w_tensor)",
"nn/functional.py: (args) `linear (Parameter)`": "torch.nn.functional.linear(x, linear_w)",
"Linear(..., bias=False)": "linear(x)",
}
def _worker_main(argv, fn):
parser = argparse.ArgumentParser()
parser.add_argument("--output_file", type=str)
parser.add_argument("--single_task", type=int, default=None)
parser.add_argument("--length", type=str)
args = parser.parse_args(argv)
single_task = args.single_task
conda_prefix = os.getenv("CONDA_PREFIX")
assert torch.__file__.startswith(conda_prefix)
env = os.path.split(conda_prefix)[1]
assert env in ENVS
results = []
for i, (k, stmt) in enumerate(TASKS.items()):
if single_task is not None and single_task != i:
continue
timer = Timer(
stmt=stmt,
setup=SETUP,
sub_label=k,
description=ENVS[env],
)
results.append(fn(timer, args.length))
with open(args.output_file, "wb") as f:
pickle.dump(results, f)
def worker_main(argv):
_worker_main(
argv,
lambda timer, _: timer.blocked_autorange(min_run_time=MIN_RUN_TIME)
)
def callgrind_worker_main(argv):
_worker_main(
argv,
lambda timer, length: timer.collect_callgrind(number=CALLGRIND_NUMBER[length], collect_baseline=False))
def main(argv):
parser = argparse.ArgumentParser()
parser.add_argument("--long", action="store_true")
parser.add_argument("--longer", action="store_true")
args = parser.parse_args(argv)
if args.longer:
length = "longer"
elif args.long:
length = "long"
else:
length = "short"
replicates = REPLICATES[length]
num_workers = int(NUM_CORES // 2)
tasks = list(ENVS.keys()) * replicates
random.shuffle(tasks)
task_queue = queue.Queue()
for _ in range(replicates):
envs = list(ENVS.keys())
random.shuffle(envs)
for e in envs:
task_queue.put((e, None))
callgrind_task_queue = queue.Queue()
for e in CALLGRIND_ENVS:
for i, _ in enumerate(TASKS):
callgrind_task_queue.put((e, i))
results = []
callgrind_results = []
def map_fn(worker_id):
# Adjacent cores often share cache and maxing out a machine can distort
# timings so we space them out.
callgrind_cores = f"{worker_id * 2}-{worker_id * 2 + 1}"
time_cores = str(worker_id * 2)
_, output_file = tempfile.mkstemp(suffix=".pkl")
try:
loop_tasks = (
# Callgrind is long running, and then the workers can help with
# timing after they finish collecting counts.
(callgrind_task_queue, callgrind_results, "callgrind_worker", callgrind_cores, CALLGRIND_TIMEOUT[length]),
(task_queue, results, "worker", time_cores, None))
for queue_i, results_i, mode_i, cores, timeout in loop_tasks:
while True:
try:
env, task_i = queue_i.get_nowait()
except queue.Empty:
break
remaining_attempts = 3
while True:
try:
subprocess.run(
" ".join([
"source", "activate", env, "&&",
"taskset", "--cpu-list", cores,
"python", os.path.abspath(__file__),
"--mode", mode_i,
"--length", length,
"--output_file", output_file
] + ([] if task_i is None else ["--single_task", str(task_i)])),
shell=True,
check=True,
timeout=timeout,
)
break
except subprocess.TimeoutExpired:
# Sometimes Valgrind will hang if there are too many
# concurrent runs.
remaining_attempts -= 1
if not remaining_attempts:
print("Too many failed attempts.")
raise
print(f"Timeout after {timeout} sec. Retrying.")
# We don't need a lock, as the GIL is enough.
with open(output_file, "rb") as f:
results_i.extend(pickle.load(f))
finally:
os.remove(output_file)
with multiprocessing.dummy.Pool(num_workers) as pool:
st, st_estimate, eta, n_total = time.time(), None, "", len(tasks) * len(TASKS)
map_job = pool.map_async(map_fn, range(num_workers))
while not map_job.ready():
n_complete = len(results)
if n_complete and len(callgrind_results):
if st_estimate is None:
st_estimate = time.time()
else:
sec_per_element = (time.time() - st_estimate) / n_complete
n_remaining = n_total - n_complete
eta = f"ETA: {n_remaining * sec_per_element:.0f} sec"
print(
f"\r{n_complete} / {n_total} "
f"({len(callgrind_results)} / {len(CALLGRIND_ENVS) * len(TASKS)}) "
f"{eta}".ljust(40), end="")
sys.stdout.flush()
time.sleep(2)
total_time = int(time.time() - st)
print(f"\nTotal time: {int(total_time // 60)} min, {total_time % 60} sec")
desc_to_ind = {k: i for i, k in enumerate(ENVS.values())}
results.sort(key=lambda r: desc_to_ind[r.description])
# TODO: Compare should be richer and more modular.
compare = Compare(results)
compare.trim_significant_figures()
compare.colorize(rowwise=True)
# Manually add master vs. overall relative delta t.
merged_results = {
(r.description, r.sub_label): r
for r in Measurement.merge(results)
}
cmp_lines = str(compare).splitlines(False)
print(cmp_lines[0][:-1] + "-" * 15 + "]")
print(f"{cmp_lines[1]} |{'':>10}\u0394t")
print(cmp_lines[2] + "-" * 15)
for l, t in zip(cmp_lines[3:3 + len(TASKS)], TASKS.keys()):
assert l.strip().startswith(t)
t0 = merged_results[(ENVS["ref"], t)].median
t1 = merged_results[(ENVS["torch_fn_overhead_stack_3"], t)].median
print(f"{l} |{'':>5}{(t1 / t0 - 1) * 100:>6.1f}%")
print("\n".join(cmp_lines[3 + len(TASKS):]))
counts_dict = {
(r.task_spec.description, r.task_spec.sub_label): r.counts(denoise=True)
for r in callgrind_results
}
def rel_diff(x, x0):
return f"{(x / x0 - 1) * 100:>6.1f}%"
task_pad = max(len(t) for t in TASKS)
print(f"\n\nInstruction % change (relative to `{CALLGRIND_ENVS[0]}`)")
print(" " * (task_pad + 8) + (" " * 7).join([ENVS[env] for env in CALLGRIND_ENVS[1:]]))
for t in TASKS:
values = [counts_dict[(ENVS[env], t)] for env in CALLGRIND_ENVS]
print(t.ljust(task_pad + 3) + " ".join([
rel_diff(v, values[0]).rjust(len(ENVS[env]) + 5)
for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]))
print("\033[4m" + " Instructions per invocation".ljust(task_pad + 3) + " ".join([
f"{v // CALLGRIND_NUMBER[length]:.0f}".rjust(len(ENVS[env]) + 5)
for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]) + "\033[0m")
print()
import pdb
pdb.set_trace()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--mode", type=str, choices=("main", "worker", "callgrind_worker"), default="main")
args, remaining = parser.parse_known_args()
if args.mode == "main":
main(remaining)
elif args.mode == "callgrind_worker":
callgrind_worker_main(remaining)
else:
worker_main(remaining)
```
</details>
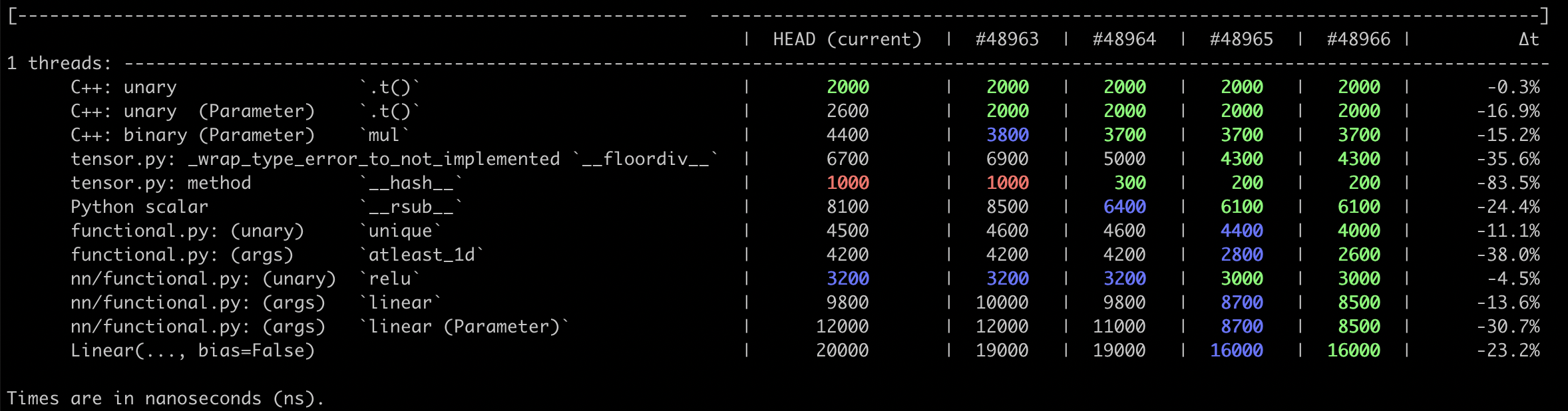
**Wall time**
<img width="1178" alt="Screen Shot 2020-12-12 at 12 28 13 PM" src="https://user-images.githubusercontent.com/13089297/101994419-284f6a00-3c77-11eb-8dc8-4f69a890302e.png">
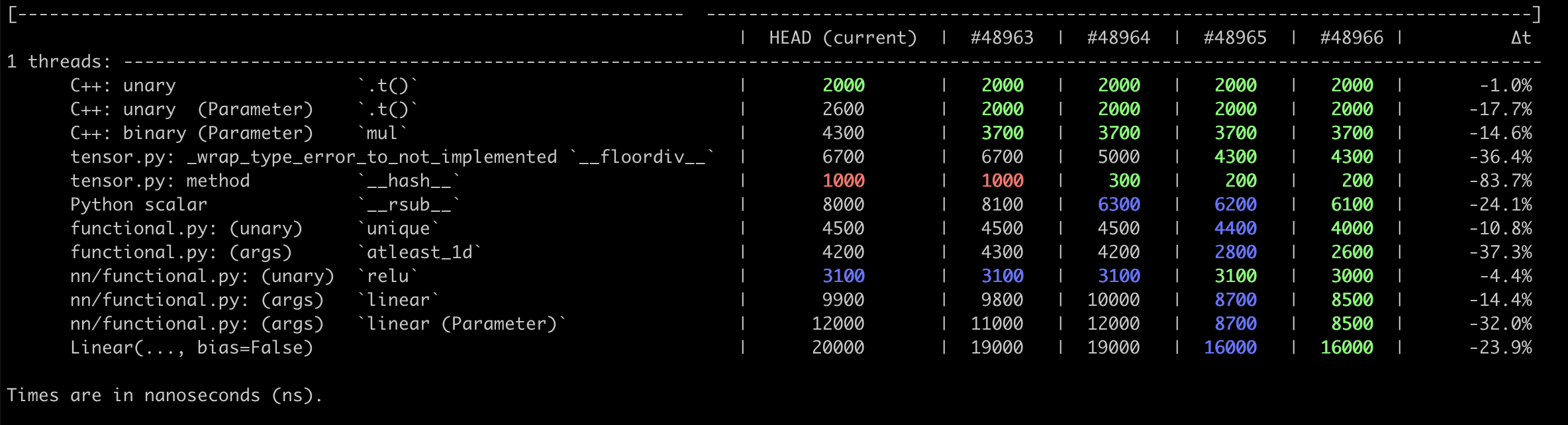
**Callgrind**
<img width="936" alt="Screen Shot 2020-12-12 at 12 28 54 PM" src="https://user-images.githubusercontent.com/13089297/101994421-2e454b00-3c77-11eb-9cd3-8cde550f536e.png">
Test plan: existing unit tests.
[ghstack-poisoned]
{kind=link}
{kind=link}
…ject_has_torch_function" This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API. Test plan: Existing unit tests. Benchmarks are in #48966 [ghstack-poisoned]
…static False when scripting"
This PR lets us skip the `if not torch.jit.is_scripting():` guards on `functional` and `nn.functional` by directly registering `has_torch_function` and `object_has_torch_function` to the JIT as statically False.
**Benchmarks**
The benchmark script is kind of long. The reason is that it's testing all four PRs in the stack, plus threading and subprocessing so that the benchmark can utilize multiple cores while still collecting good numbers. Both wall times and instruction counts were collected. This stack changes dozens of operators / functions, but very mechanically such that there are only a handful of codepath changes. Each row is a slightly different code path (e.g. testing in Python, testing in the arg parser, different input types, etc.)
<details>
<summary> Test script </summary>
```
import argparse
import multiprocessing
import multiprocessing.dummy
import os
import pickle
import queue
import random
import sys
import subprocess
import tempfile
import time
import torch
from torch.utils.benchmark import Timer, Compare, Measurement
NUM_CORES = multiprocessing.cpu_count()
ENVS = {
"ref": "HEAD (current)",
"torch_fn_overhead_stack_0": "#48963",
"torch_fn_overhead_stack_1": "#48964",
"torch_fn_overhead_stack_2": "#48965",
"torch_fn_overhead_stack_3": "#48966",
}
CALLGRIND_ENVS = tuple(ENVS.keys())
MIN_RUN_TIME = 3
REPLICATES = {
"longer": 1_000,
"long": 300,
"short": 50,
}
CALLGRIND_NUMBER = {
"overnight": 500_000,
"long": 250_000,
"short": 10_000,
}
CALLGRIND_TIMEOUT = {
"overnight": 800,
"long": 400,
"short": 100,
}
SETUP = """
x = torch.ones((1, 1))
y = torch.ones((1, 1))
w_tensor = torch.ones((1, 1), requires_grad=True)
linear = torch.nn.Linear(1, 1, bias=False)
linear_w = linear.weight
"""
TASKS = {
"C++: unary `.t()`": "w_tensor.t()",
"C++: unary (Parameter) `.t()`": "linear_w.t()",
"C++: binary (Parameter) `mul` ": "x + linear_w",
"tensor.py: _wrap_type_error_to_not_implemented `__floordiv__`": "x // y",
"tensor.py: method `__hash__`": "hash(x)",
"Python scalar `__rsub__`": "1 - x",
"functional.py: (unary) `unique`": "torch.functional.unique(x)",
"functional.py: (args) `atleast_1d`": "torch.functional.atleast_1d((x, y))",
"nn/functional.py: (unary) `relu`": "torch.nn.functional.relu(x)",
"nn/functional.py: (args) `linear`": "torch.nn.functional.linear(x, w_tensor)",
"nn/functional.py: (args) `linear (Parameter)`": "torch.nn.functional.linear(x, linear_w)",
"Linear(..., bias=False)": "linear(x)",
}
def _worker_main(argv, fn):
parser = argparse.ArgumentParser()
parser.add_argument("--output_file", type=str)
parser.add_argument("--single_task", type=int, default=None)
parser.add_argument("--length", type=str)
args = parser.parse_args(argv)
single_task = args.single_task
conda_prefix = os.getenv("CONDA_PREFIX")
assert torch.__file__.startswith(conda_prefix)
env = os.path.split(conda_prefix)[1]
assert env in ENVS
results = []
for i, (k, stmt) in enumerate(TASKS.items()):
if single_task is not None and single_task != i:
continue
timer = Timer(
stmt=stmt,
setup=SETUP,
sub_label=k,
description=ENVS[env],
)
results.append(fn(timer, args.length))
with open(args.output_file, "wb") as f:
pickle.dump(results, f)
def worker_main(argv):
_worker_main(
argv,
lambda timer, _: timer.blocked_autorange(min_run_time=MIN_RUN_TIME)
)
def callgrind_worker_main(argv):
_worker_main(
argv,
lambda timer, length: timer.collect_callgrind(number=CALLGRIND_NUMBER[length], collect_baseline=False))
def main(argv):
parser = argparse.ArgumentParser()
parser.add_argument("--long", action="store_true")
parser.add_argument("--longer", action="store_true")
args = parser.parse_args(argv)
if args.longer:
length = "longer"
elif args.long:
length = "long"
else:
length = "short"
replicates = REPLICATES[length]
num_workers = int(NUM_CORES // 2)
tasks = list(ENVS.keys()) * replicates
random.shuffle(tasks)
task_queue = queue.Queue()
for _ in range(replicates):
envs = list(ENVS.keys())
random.shuffle(envs)
for e in envs:
task_queue.put((e, None))
callgrind_task_queue = queue.Queue()
for e in CALLGRIND_ENVS:
for i, _ in enumerate(TASKS):
callgrind_task_queue.put((e, i))
results = []
callgrind_results = []
def map_fn(worker_id):
# Adjacent cores often share cache and maxing out a machine can distort
# timings so we space them out.
callgrind_cores = f"{worker_id * 2}-{worker_id * 2 + 1}"
time_cores = str(worker_id * 2)
_, output_file = tempfile.mkstemp(suffix=".pkl")
try:
loop_tasks = (
# Callgrind is long running, and then the workers can help with
# timing after they finish collecting counts.
(callgrind_task_queue, callgrind_results, "callgrind_worker", callgrind_cores, CALLGRIND_TIMEOUT[length]),
(task_queue, results, "worker", time_cores, None))
for queue_i, results_i, mode_i, cores, timeout in loop_tasks:
while True:
try:
env, task_i = queue_i.get_nowait()
except queue.Empty:
break
remaining_attempts = 3
while True:
try:
subprocess.run(
" ".join([
"source", "activate", env, "&&",
"taskset", "--cpu-list", cores,
"python", os.path.abspath(__file__),
"--mode", mode_i,
"--length", length,
"--output_file", output_file
] + ([] if task_i is None else ["--single_task", str(task_i)])),
shell=True,
check=True,
timeout=timeout,
)
break
except subprocess.TimeoutExpired:
# Sometimes Valgrind will hang if there are too many
# concurrent runs.
remaining_attempts -= 1
if not remaining_attempts:
print("Too many failed attempts.")
raise
print(f"Timeout after {timeout} sec. Retrying.")
# We don't need a lock, as the GIL is enough.
with open(output_file, "rb") as f:
results_i.extend(pickle.load(f))
finally:
os.remove(output_file)
with multiprocessing.dummy.Pool(num_workers) as pool:
st, st_estimate, eta, n_total = time.time(), None, "", len(tasks) * len(TASKS)
map_job = pool.map_async(map_fn, range(num_workers))
while not map_job.ready():
n_complete = len(results)
if n_complete and len(callgrind_results):
if st_estimate is None:
st_estimate = time.time()
else:
sec_per_element = (time.time() - st_estimate) / n_complete
n_remaining = n_total - n_complete
eta = f"ETA: {n_remaining * sec_per_element:.0f} sec"
print(
f"\r{n_complete} / {n_total} "
f"({len(callgrind_results)} / {len(CALLGRIND_ENVS) * len(TASKS)}) "
f"{eta}".ljust(40), end="")
sys.stdout.flush()
time.sleep(2)
total_time = int(time.time() - st)
print(f"\nTotal time: {int(total_time // 60)} min, {total_time % 60} sec")
desc_to_ind = {k: i for i, k in enumerate(ENVS.values())}
results.sort(key=lambda r: desc_to_ind[r.description])
# TODO: Compare should be richer and more modular.
compare = Compare(results)
compare.trim_significant_figures()
compare.colorize(rowwise=True)
# Manually add master vs. overall relative delta t.
merged_results = {
(r.description, r.sub_label): r
for r in Measurement.merge(results)
}
cmp_lines = str(compare).splitlines(False)
print(cmp_lines[0][:-1] + "-" * 15 + "]")
print(f"{cmp_lines[1]} |{'':>10}\u0394t")
print(cmp_lines[2] + "-" * 15)
for l, t in zip(cmp_lines[3:3 + len(TASKS)], TASKS.keys()):
assert l.strip().startswith(t)
t0 = merged_results[(ENVS["ref"], t)].median
t1 = merged_results[(ENVS["torch_fn_overhead_stack_3"], t)].median
print(f"{l} |{'':>5}{(t1 / t0 - 1) * 100:>6.1f}%")
print("\n".join(cmp_lines[3 + len(TASKS):]))
counts_dict = {
(r.task_spec.description, r.task_spec.sub_label): r.counts(denoise=True)
for r in callgrind_results
}
def rel_diff(x, x0):
return f"{(x / x0 - 1) * 100:>6.1f}%"
task_pad = max(len(t) for t in TASKS)
print(f"\n\nInstruction % change (relative to `{CALLGRIND_ENVS[0]}`)")
print(" " * (task_pad + 8) + (" " * 7).join([ENVS[env] for env in CALLGRIND_ENVS[1:]]))
for t in TASKS:
values = [counts_dict[(ENVS[env], t)] for env in CALLGRIND_ENVS]
print(t.ljust(task_pad + 3) + " ".join([
rel_diff(v, values[0]).rjust(len(ENVS[env]) + 5)
for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]))
print("\033[4m" + " Instructions per invocation".ljust(task_pad + 3) + " ".join([
f"{v // CALLGRIND_NUMBER[length]:.0f}".rjust(len(ENVS[env]) + 5)
for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]) + "\033[0m")
print()
import pdb
pdb.set_trace()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--mode", type=str, choices=("main", "worker", "callgrind_worker"), default="main")
args, remaining = parser.parse_known_args()
if args.mode == "main":
main(remaining)
elif args.mode == "callgrind_worker":
callgrind_worker_main(remaining)
else:
worker_main(remaining)
```
</details>
**Wall time**
<img width="1178" alt="Screen Shot 2020-12-12 at 12 28 13 PM" src="https://user-images.githubusercontent.com/13089297/101994419-284f6a00-3c77-11eb-8dc8-4f69a890302e.png">
<details>
<summary> Longer run (`python test.py --long`) is basically identical. </summary>
<img width="1184" alt="Screen Shot 2020-12-12 at 5 02 47 PM" src="https://user-images.githubusercontent.com/13089297/102000425-2350e180-3c9c-11eb-999e-a95b37e9ef54.png">
</details>
**Callgrind**
<img width="936" alt="Screen Shot 2020-12-12 at 12 28 54 PM" src="https://user-images.githubusercontent.com/13089297/101994421-2e454b00-3c77-11eb-9cd3-8cde550f536e.png">
Test plan: existing unit tests.
[ghstack-poisoned]
{kind=link}
|
There is code movement in this PR, could you please import it into Phabricator (which shows when code fragments are moved) or please comment on all locations where code was moved without changes. |
torch/functional.py
Outdated
| @@ -965,7 +965,7 @@ def tensordot(a, b, dims=2, out=None): | |||
| [ -0.2850, 4.2573, -3.5997]]) | |||
| """ | |||
| if not torch.jit.is_scripting(): | |||
| if (type(a) is not Tensor or type(b) is not Tensor) and has_torch_function((a, b)): | |||
| if has_torch_function((a, b)): | |||
There was a problem hiding this comment.
This seems like a pessimization. Previously, tuple construction only happened if a was not a tensor and b was not a tensor. Now you unconditionally do tuple construction so you can call has_torch_function. I'm not too sure how CPython internally implements variadic function calls, but has_torch_function(a, b) has the potential to bypass this (although I guess if in the variadic case CPython constructs a tuple anyway, you'll need separate overloads per arity.)
There was a problem hiding this comment.
Surprisingly it's not. (kind of)
import re
from torch.utils.benchmark import Timer
for stmt in (
"type(a) is not Tensor",
"type(a) is not Tensor or type(b) is not Tensor",
"object_has_torch_function(a)",
"object_has_torch_function(a) or object_has_torch_function(b)",
"has_torch_function((a, b))"
):
timer = Timer(
stmt,
setup="""
from torch import Tensor
from torch.overrides import has_torch_function, object_has_torch_function
a = torch.ones((1,))
b = torch.ones((1,))
# end_setup
"""
)
# Trim repeated `setup` for readability.
s = repr(timer.blocked_autorange(min_run_time=2))
print(re.sub(r"setup:.+# end_setup\n\n", "", s, flags=re.DOTALL), "\n")
<torch.utils.benchmark.utils.common.Measurement object at 0x7f254c3c5190>
type(a) is not Tensor
Median: 73.92 ns
IQR: 3.14 ns (72.39 to 75.52)
268 measurements, 100000 runs per measurement, 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7f254c546c50>
type(a) is not Tensor or type(b) is not Tensor
Median: 157.44 ns
IQR: 6.42 ns (153.04 to 159.46)
128 measurements, 100000 runs per measurement, 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7f254c3c5cd0>
object_has_torch_function(a)
Median: 31.67 ns
IQR: 1.40 ns (31.22 to 32.61)
624 measurements, 100000 runs per measurement, 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7f2571ba7a50>
object_has_torch_function(a) or object_has_torch_function(b)
Median: 60.68 ns
IQR: 4.44 ns (58.10 to 62.55)
323 measurements, 100000 runs per measurement, 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7f254c3c5bd0>
has_torch_function((a, b))
Median: 65.73 ns
IQR: 4.23 ns (63.92 to 68.16)
296 measurements, 100000 runs per measurement, 1 thread
Even though the previous version wouldn't create a tuple for Tensor args, tuples are not that expensive and doing things in Python is slow. I checked, and while CPython has METH_O, there's no METH_1 for static two arg functions so you'd have to go through METH_VARARGS and the tuple (or maybe list!!!) anyway. That said, one thing that I could do is to make a private version that statically expects a size two tuple as well to skip some of the unpacking work on the C++ side. (And MyPy will keep us honest on the calling side.) It won't be much, but since this is called everywhere it might be worth it to shave some nanoseconds.
There was a problem hiding this comment.
Ohh, actually METH_FASTCALL might be the thing.
There was a problem hiding this comment.
(It's 3.7+ though, so if it's useful it would have to be version guarded.)
There was a problem hiding this comment.
FASTCALL seems like the right thing, although object_has_torch_function(a) or object_has_torch_function(b) doesn't seem too shabby either. So while we're ripping up the floorboards right now, might as well design the API so that it is FASTCALL compatible.
There was a problem hiding this comment.
FASTCALL times:
<torch.utils.benchmark.utils.common.Measurement object at 0x7f5f511e3a90>
_has_torch_function_varargs(a)
Median: 40.99 ns
IQR: 1.53 ns (40.50 to 42.03)
475 measurements, 100000 runs per measurement, 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7f5f75c649d0>
_has_torch_function_varargs(a, b)
Median: 46.04 ns
IQR: 1.33 ns (45.49 to 46.82)
433 measurements, 100000 runs per measurement, 1 thread
So it's worth it to keep the single arg version, but for multiple it's considerably better to skip the intermediate tuple. And for Python 3.6 we can just use METH_VARARGS which isn't the end of the world. Particularly since we can statically use the tuple fast path that has to be checked in THPModule_has_torch_function.
There was a problem hiding this comment.
we're dumping py3.6 soon anyway
There was a problem hiding this comment.
By the way, I bet we have a lot of existing bindings that use METH_VARARGS and can switch to FASTCALL. So we should file a bug about this too.
| `object_has_torch_function(t)` | ||
| which skips unnecessary packing and unpacking work. | ||
| """ | ||
| ) |
There was a problem hiding this comment.
Yeah, it seems better to name the functions based on arity, makes it more obvious that object_has_torch_function is for one-input case (as opposed to being some object-y thing)
There was a problem hiding this comment.
My conundrum is that they're all technically unary functions. That said, if we do also go for the special case size two tuple case then something like unary_has_torch_function and unsafe_binary_has_torch_function might be clearer. Feel free to suggest better names if any occur to you.
There was a problem hiding this comment.
has_torch_function1, has_torch_function2, etc. etc. But I should actually respond to your comments on the other thread. Hang on...
| @@ -167,6 +167,7 @@ def get_ignored_functions() -> Set[Callable]: | |||
| torch.nn.functional.upsample_bilinear, | |||
| torch.nn.functional.upsample_nearest, | |||
| torch.nn.functional.has_torch_function, | |||
| torch.nn.functional.object_has_torch_function, | |||
| torch.nn.functional.handle_torch_function, | |||
There was a problem hiding this comment.
??? Are these getting secretly exported when they shouldn't be ???
There was a problem hiding this comment.
I was surprised too, but yeah. Tests fail if I don't.
There was a problem hiding this comment.
Can you file an issue about this? They shouldn't be exported... you might be able to fix this problem by importing the module rather than the functions; maybe from blah import foo implicitly sets up an export.
…ject_has_torch_function" This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API. Test plan: Existing unit tests. Benchmarks are in #48966 [ghstack-poisoned]
…ject_has_torch_function" This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API. Test plan: Existing unit tests. Benchmarks are in #48966 Differential Revision: [D25590732](https://our.internmc.facebook.com/intern/diff/D25590732) [ghstack-poisoned]
…static False when scripting"
This PR lets us skip the `if not torch.jit.is_scripting():` guards on `functional` and `nn.functional` by directly registering `has_torch_function` and `object_has_torch_function` to the JIT as statically False.
**Benchmarks**
The benchmark script is kind of long. The reason is that it's testing all four PRs in the stack, plus threading and subprocessing so that the benchmark can utilize multiple cores while still collecting good numbers. Both wall times and instruction counts were collected. This stack changes dozens of operators / functions, but very mechanically such that there are only a handful of codepath changes. Each row is a slightly different code path (e.g. testing in Python, testing in the arg parser, different input types, etc.)
<details>
<summary> Test script </summary>
```
import argparse
import multiprocessing
import multiprocessing.dummy
import os
import pickle
import queue
import random
import sys
import subprocess
import tempfile
import time
import torch
from torch.utils.benchmark import Timer, Compare, Measurement
NUM_CORES = multiprocessing.cpu_count()
ENVS = {
"ref": "HEAD (current)",
"torch_fn_overhead_stack_0": "#48963",
"torch_fn_overhead_stack_1": "#48964",
"torch_fn_overhead_stack_2": "#48965",
"torch_fn_overhead_stack_3": "#48966",
}
CALLGRIND_ENVS = tuple(ENVS.keys())
MIN_RUN_TIME = 3
REPLICATES = {
"longer": 1_000,
"long": 300,
"short": 50,
}
CALLGRIND_NUMBER = {
"overnight": 500_000,
"long": 250_000,
"short": 10_000,
}
CALLGRIND_TIMEOUT = {
"overnight": 800,
"long": 400,
"short": 100,
}
SETUP = """
x = torch.ones((1, 1))
y = torch.ones((1, 1))
w_tensor = torch.ones((1, 1), requires_grad=True)
linear = torch.nn.Linear(1, 1, bias=False)
linear_w = linear.weight
"""
TASKS = {
"C++: unary `.t()`": "w_tensor.t()",
"C++: unary (Parameter) `.t()`": "linear_w.t()",
"C++: binary (Parameter) `mul` ": "x + linear_w",
"tensor.py: _wrap_type_error_to_not_implemented `__floordiv__`": "x // y",
"tensor.py: method `__hash__`": "hash(x)",
"Python scalar `__rsub__`": "1 - x",
"functional.py: (unary) `unique`": "torch.functional.unique(x)",
"functional.py: (args) `atleast_1d`": "torch.functional.atleast_1d((x, y))",
"nn/functional.py: (unary) `relu`": "torch.nn.functional.relu(x)",
"nn/functional.py: (args) `linear`": "torch.nn.functional.linear(x, w_tensor)",
"nn/functional.py: (args) `linear (Parameter)`": "torch.nn.functional.linear(x, linear_w)",
"Linear(..., bias=False)": "linear(x)",
}
def _worker_main(argv, fn):
parser = argparse.ArgumentParser()
parser.add_argument("--output_file", type=str)
parser.add_argument("--single_task", type=int, default=None)
parser.add_argument("--length", type=str)
args = parser.parse_args(argv)
single_task = args.single_task
conda_prefix = os.getenv("CONDA_PREFIX")
assert torch.__file__.startswith(conda_prefix)
env = os.path.split(conda_prefix)[1]
assert env in ENVS
results = []
for i, (k, stmt) in enumerate(TASKS.items()):
if single_task is not None and single_task != i:
continue
timer = Timer(
stmt=stmt,
setup=SETUP,
sub_label=k,
description=ENVS[env],
)
results.append(fn(timer, args.length))
with open(args.output_file, "wb") as f:
pickle.dump(results, f)
def worker_main(argv):
_worker_main(
argv,
lambda timer, _: timer.blocked_autorange(min_run_time=MIN_RUN_TIME)
)
def callgrind_worker_main(argv):
_worker_main(
argv,
lambda timer, length: timer.collect_callgrind(number=CALLGRIND_NUMBER[length], collect_baseline=False))
def main(argv):
parser = argparse.ArgumentParser()
parser.add_argument("--long", action="store_true")
parser.add_argument("--longer", action="store_true")
args = parser.parse_args(argv)
if args.longer:
length = "longer"
elif args.long:
length = "long"
else:
length = "short"
replicates = REPLICATES[length]
num_workers = int(NUM_CORES // 2)
tasks = list(ENVS.keys()) * replicates
random.shuffle(tasks)
task_queue = queue.Queue()
for _ in range(replicates):
envs = list(ENVS.keys())
random.shuffle(envs)
for e in envs:
task_queue.put((e, None))
callgrind_task_queue = queue.Queue()
for e in CALLGRIND_ENVS:
for i, _ in enumerate(TASKS):
callgrind_task_queue.put((e, i))
results = []
callgrind_results = []
def map_fn(worker_id):
# Adjacent cores often share cache and maxing out a machine can distort
# timings so we space them out.
callgrind_cores = f"{worker_id * 2}-{worker_id * 2 + 1}"
time_cores = str(worker_id * 2)
_, output_file = tempfile.mkstemp(suffix=".pkl")
try:
loop_tasks = (
# Callgrind is long running, and then the workers can help with
# timing after they finish collecting counts.
(callgrind_task_queue, callgrind_results, "callgrind_worker", callgrind_cores, CALLGRIND_TIMEOUT[length]),
(task_queue, results, "worker", time_cores, None))
for queue_i, results_i, mode_i, cores, timeout in loop_tasks:
while True:
try:
env, task_i = queue_i.get_nowait()
except queue.Empty:
break
remaining_attempts = 3
while True:
try:
subprocess.run(
" ".join([
"source", "activate", env, "&&",
"taskset", "--cpu-list", cores,
"python", os.path.abspath(__file__),
"--mode", mode_i,
"--length", length,
"--output_file", output_file
] + ([] if task_i is None else ["--single_task", str(task_i)])),
shell=True,
check=True,
timeout=timeout,
)
break
except subprocess.TimeoutExpired:
# Sometimes Valgrind will hang if there are too many
# concurrent runs.
remaining_attempts -= 1
if not remaining_attempts:
print("Too many failed attempts.")
raise
print(f"Timeout after {timeout} sec. Retrying.")
# We don't need a lock, as the GIL is enough.
with open(output_file, "rb") as f:
results_i.extend(pickle.load(f))
finally:
os.remove(output_file)
with multiprocessing.dummy.Pool(num_workers) as pool:
st, st_estimate, eta, n_total = time.time(), None, "", len(tasks) * len(TASKS)
map_job = pool.map_async(map_fn, range(num_workers))
while not map_job.ready():
n_complete = len(results)
if n_complete and len(callgrind_results):
if st_estimate is None:
st_estimate = time.time()
else:
sec_per_element = (time.time() - st_estimate) / n_complete
n_remaining = n_total - n_complete
eta = f"ETA: {n_remaining * sec_per_element:.0f} sec"
print(
f"\r{n_complete} / {n_total} "
f"({len(callgrind_results)} / {len(CALLGRIND_ENVS) * len(TASKS)}) "
f"{eta}".ljust(40), end="")
sys.stdout.flush()
time.sleep(2)
total_time = int(time.time() - st)
print(f"\nTotal time: {int(total_time // 60)} min, {total_time % 60} sec")
desc_to_ind = {k: i for i, k in enumerate(ENVS.values())}
results.sort(key=lambda r: desc_to_ind[r.description])
# TODO: Compare should be richer and more modular.
compare = Compare(results)
compare.trim_significant_figures()
compare.colorize(rowwise=True)
# Manually add master vs. overall relative delta t.
merged_results = {
(r.description, r.sub_label): r
for r in Measurement.merge(results)
}
cmp_lines = str(compare).splitlines(False)
print(cmp_lines[0][:-1] + "-" * 15 + "]")
print(f"{cmp_lines[1]} |{'':>10}\u0394t")
print(cmp_lines[2] + "-" * 15)
for l, t in zip(cmp_lines[3:3 + len(TASKS)], TASKS.keys()):
assert l.strip().startswith(t)
t0 = merged_results[(ENVS["ref"], t)].median
t1 = merged_results[(ENVS["torch_fn_overhead_stack_3"], t)].median
print(f"{l} |{'':>5}{(t1 / t0 - 1) * 100:>6.1f}%")
print("\n".join(cmp_lines[3 + len(TASKS):]))
counts_dict = {
(r.task_spec.description, r.task_spec.sub_label): r.counts(denoise=True)
for r in callgrind_results
}
def rel_diff(x, x0):
return f"{(x / x0 - 1) * 100:>6.1f}%"
task_pad = max(len(t) for t in TASKS)
print(f"\n\nInstruction % change (relative to `{CALLGRIND_ENVS[0]}`)")
print(" " * (task_pad + 8) + (" " * 7).join([ENVS[env] for env in CALLGRIND_ENVS[1:]]))
for t in TASKS:
values = [counts_dict[(ENVS[env], t)] for env in CALLGRIND_ENVS]
print(t.ljust(task_pad + 3) + " ".join([
rel_diff(v, values[0]).rjust(len(ENVS[env]) + 5)
for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]))
print("\033[4m" + " Instructions per invocation".ljust(task_pad + 3) + " ".join([
f"{v // CALLGRIND_NUMBER[length]:.0f}".rjust(len(ENVS[env]) + 5)
for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]) + "\033[0m")
print()
import pdb
pdb.set_trace()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--mode", type=str, choices=("main", "worker", "callgrind_worker"), default="main")
args, remaining = parser.parse_known_args()
if args.mode == "main":
main(remaining)
elif args.mode == "callgrind_worker":
callgrind_worker_main(remaining)
else:
worker_main(remaining)
```
</details>
**Wall time**
<img width="1178" alt="Screen Shot 2020-12-12 at 12 28 13 PM" src="https://user-images.githubusercontent.com/13089297/101994419-284f6a00-3c77-11eb-8dc8-4f69a890302e.png">
<details>
<summary> Longer run (`python test.py --long`) is basically identical. </summary>
<img width="1184" alt="Screen Shot 2020-12-12 at 5 02 47 PM" src="https://user-images.githubusercontent.com/13089297/102000425-2350e180-3c9c-11eb-999e-a95b37e9ef54.png">
</details>
**Callgrind**
<img width="936" alt="Screen Shot 2020-12-12 at 12 28 54 PM" src="https://user-images.githubusercontent.com/13089297/101994421-2e454b00-3c77-11eb-9cd3-8cde550f536e.png">
Test plan: existing unit tests.
Differential Revision: [D25590731](https://our.internmc.facebook.com/intern/diff/D25590731)
[ghstack-poisoned]
Tests are now passing, modulo some noise on internal tests. |
|
As a follow up to #48965 (comment), I did some experiments with frozen and it is insanely fast. The std maps don't constexpr so I had to use const (constexpr-ability is pretty much the main selling point of frozen) and I just tweaked the benchmarks. The benchmark was pretty simple; fetch a key from a size four map of ints. (Since PyType will be a pointer, python strings will be an interned pointer, etc so I expect this to be pretty representative.) Taking a step back, I could see this being really powerful in conjunction with METH_FASTCALL | METH_KEYWORDS to really squeeze the python arg parser. |
…ject_has_torch_function" This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API. Test plan: Existing unit tests. Benchmarks are in #48966 Differential Revision: [D25590732](https://our.internmc.facebook.com/intern/diff/D25590732) [ghstack-poisoned]
…static False when scripting"
This PR lets us skip the `if not torch.jit.is_scripting():` guards on `functional` and `nn.functional` by directly registering `has_torch_function` and `object_has_torch_function` to the JIT as statically False.
**Benchmarks**
The benchmark script is kind of long. The reason is that it's testing all four PRs in the stack, plus threading and subprocessing so that the benchmark can utilize multiple cores while still collecting good numbers. Both wall times and instruction counts were collected. This stack changes dozens of operators / functions, but very mechanically such that there are only a handful of codepath changes. Each row is a slightly different code path (e.g. testing in Python, testing in the arg parser, different input types, etc.)
<details>
<summary> Test script </summary>
```
import argparse
import multiprocessing
import multiprocessing.dummy
import os
import pickle
import queue
import random
import sys
import subprocess
import tempfile
import time
import torch
from torch.utils.benchmark import Timer, Compare, Measurement
NUM_CORES = multiprocessing.cpu_count()
ENVS = {
"ref": "HEAD (current)",
"torch_fn_overhead_stack_0": "#48963",
"torch_fn_overhead_stack_1": "#48964",
"torch_fn_overhead_stack_2": "#48965",
"torch_fn_overhead_stack_3": "#48966",
}
CALLGRIND_ENVS = tuple(ENVS.keys())
MIN_RUN_TIME = 3
REPLICATES = {
"longer": 1_000,
"long": 300,
"short": 50,
}
CALLGRIND_NUMBER = {
"overnight": 500_000,
"long": 250_000,
"short": 10_000,
}
CALLGRIND_TIMEOUT = {
"overnight": 800,
"long": 400,
"short": 100,
}
SETUP = """
x = torch.ones((1, 1))
y = torch.ones((1, 1))
w_tensor = torch.ones((1, 1), requires_grad=True)
linear = torch.nn.Linear(1, 1, bias=False)
linear_w = linear.weight
"""
TASKS = {
"C++: unary `.t()`": "w_tensor.t()",
"C++: unary (Parameter) `.t()`": "linear_w.t()",
"C++: binary (Parameter) `mul` ": "x + linear_w",
"tensor.py: _wrap_type_error_to_not_implemented `__floordiv__`": "x // y",
"tensor.py: method `__hash__`": "hash(x)",
"Python scalar `__rsub__`": "1 - x",
"functional.py: (unary) `unique`": "torch.functional.unique(x)",
"functional.py: (args) `atleast_1d`": "torch.functional.atleast_1d((x, y))",
"nn/functional.py: (unary) `relu`": "torch.nn.functional.relu(x)",
"nn/functional.py: (args) `linear`": "torch.nn.functional.linear(x, w_tensor)",
"nn/functional.py: (args) `linear (Parameter)`": "torch.nn.functional.linear(x, linear_w)",
"Linear(..., bias=False)": "linear(x)",
}
def _worker_main(argv, fn):
parser = argparse.ArgumentParser()
parser.add_argument("--output_file", type=str)
parser.add_argument("--single_task", type=int, default=None)
parser.add_argument("--length", type=str)
args = parser.parse_args(argv)
single_task = args.single_task
conda_prefix = os.getenv("CONDA_PREFIX")
assert torch.__file__.startswith(conda_prefix)
env = os.path.split(conda_prefix)[1]
assert env in ENVS
results = []
for i, (k, stmt) in enumerate(TASKS.items()):
if single_task is not None and single_task != i:
continue
timer = Timer(
stmt=stmt,
setup=SETUP,
sub_label=k,
description=ENVS[env],
)
results.append(fn(timer, args.length))
with open(args.output_file, "wb") as f:
pickle.dump(results, f)
def worker_main(argv):
_worker_main(
argv,
lambda timer, _: timer.blocked_autorange(min_run_time=MIN_RUN_TIME)
)
def callgrind_worker_main(argv):
_worker_main(
argv,
lambda timer, length: timer.collect_callgrind(number=CALLGRIND_NUMBER[length], collect_baseline=False))
def main(argv):
parser = argparse.ArgumentParser()
parser.add_argument("--long", action="store_true")
parser.add_argument("--longer", action="store_true")
args = parser.parse_args(argv)
if args.longer:
length = "longer"
elif args.long:
length = "long"
else:
length = "short"
replicates = REPLICATES[length]
num_workers = int(NUM_CORES // 2)
tasks = list(ENVS.keys()) * replicates
random.shuffle(tasks)
task_queue = queue.Queue()
for _ in range(replicates):
envs = list(ENVS.keys())
random.shuffle(envs)
for e in envs:
task_queue.put((e, None))
callgrind_task_queue = queue.Queue()
for e in CALLGRIND_ENVS:
for i, _ in enumerate(TASKS):
callgrind_task_queue.put((e, i))
results = []
callgrind_results = []
def map_fn(worker_id):
# Adjacent cores often share cache and maxing out a machine can distort
# timings so we space them out.
callgrind_cores = f"{worker_id * 2}-{worker_id * 2 + 1}"
time_cores = str(worker_id * 2)
_, output_file = tempfile.mkstemp(suffix=".pkl")
try:
loop_tasks = (
# Callgrind is long running, and then the workers can help with
# timing after they finish collecting counts.
(callgrind_task_queue, callgrind_results, "callgrind_worker", callgrind_cores, CALLGRIND_TIMEOUT[length]),
(task_queue, results, "worker", time_cores, None))
for queue_i, results_i, mode_i, cores, timeout in loop_tasks:
while True:
try:
env, task_i = queue_i.get_nowait()
except queue.Empty:
break
remaining_attempts = 3
while True:
try:
subprocess.run(
" ".join([
"source", "activate", env, "&&",
"taskset", "--cpu-list", cores,
"python", os.path.abspath(__file__),
"--mode", mode_i,
"--length", length,
"--output_file", output_file
] + ([] if task_i is None else ["--single_task", str(task_i)])),
shell=True,
check=True,
timeout=timeout,
)
break
except subprocess.TimeoutExpired:
# Sometimes Valgrind will hang if there are too many
# concurrent runs.
remaining_attempts -= 1
if not remaining_attempts:
print("Too many failed attempts.")
raise
print(f"Timeout after {timeout} sec. Retrying.")
# We don't need a lock, as the GIL is enough.
with open(output_file, "rb") as f:
results_i.extend(pickle.load(f))
finally:
os.remove(output_file)
with multiprocessing.dummy.Pool(num_workers) as pool:
st, st_estimate, eta, n_total = time.time(), None, "", len(tasks) * len(TASKS)
map_job = pool.map_async(map_fn, range(num_workers))
while not map_job.ready():
n_complete = len(results)
if n_complete and len(callgrind_results):
if st_estimate is None:
st_estimate = time.time()
else:
sec_per_element = (time.time() - st_estimate) / n_complete
n_remaining = n_total - n_complete
eta = f"ETA: {n_remaining * sec_per_element:.0f} sec"
print(
f"\r{n_complete} / {n_total} "
f"({len(callgrind_results)} / {len(CALLGRIND_ENVS) * len(TASKS)}) "
f"{eta}".ljust(40), end="")
sys.stdout.flush()
time.sleep(2)
total_time = int(time.time() - st)
print(f"\nTotal time: {int(total_time // 60)} min, {total_time % 60} sec")
desc_to_ind = {k: i for i, k in enumerate(ENVS.values())}
results.sort(key=lambda r: desc_to_ind[r.description])
# TODO: Compare should be richer and more modular.
compare = Compare(results)
compare.trim_significant_figures()
compare.colorize(rowwise=True)
# Manually add master vs. overall relative delta t.
merged_results = {
(r.description, r.sub_label): r
for r in Measurement.merge(results)
}
cmp_lines = str(compare).splitlines(False)
print(cmp_lines[0][:-1] + "-" * 15 + "]")
print(f"{cmp_lines[1]} |{'':>10}\u0394t")
print(cmp_lines[2] + "-" * 15)
for l, t in zip(cmp_lines[3:3 + len(TASKS)], TASKS.keys()):
assert l.strip().startswith(t)
t0 = merged_results[(ENVS["ref"], t)].median
t1 = merged_results[(ENVS["torch_fn_overhead_stack_3"], t)].median
print(f"{l} |{'':>5}{(t1 / t0 - 1) * 100:>6.1f}%")
print("\n".join(cmp_lines[3 + len(TASKS):]))
counts_dict = {
(r.task_spec.description, r.task_spec.sub_label): r.counts(denoise=True)
for r in callgrind_results
}
def rel_diff(x, x0):
return f"{(x / x0 - 1) * 100:>6.1f}%"
task_pad = max(len(t) for t in TASKS)
print(f"\n\nInstruction % change (relative to `{CALLGRIND_ENVS[0]}`)")
print(" " * (task_pad + 8) + (" " * 7).join([ENVS[env] for env in CALLGRIND_ENVS[1:]]))
for t in TASKS:
values = [counts_dict[(ENVS[env], t)] for env in CALLGRIND_ENVS]
print(t.ljust(task_pad + 3) + " ".join([
rel_diff(v, values[0]).rjust(len(ENVS[env]) + 5)
for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]))
print("\033[4m" + " Instructions per invocation".ljust(task_pad + 3) + " ".join([
f"{v // CALLGRIND_NUMBER[length]:.0f}".rjust(len(ENVS[env]) + 5)
for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]) + "\033[0m")
print()
import pdb
pdb.set_trace()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--mode", type=str, choices=("main", "worker", "callgrind_worker"), default="main")
args, remaining = parser.parse_known_args()
if args.mode == "main":
main(remaining)
elif args.mode == "callgrind_worker":
callgrind_worker_main(remaining)
else:
worker_main(remaining)
```
</details>
**Wall time**
<img width="1178" alt="Screen Shot 2020-12-12 at 12 28 13 PM" src="https://user-images.githubusercontent.com/13089297/101994419-284f6a00-3c77-11eb-8dc8-4f69a890302e.png">
<details>
<summary> Longer run (`python test.py --long`) is basically identical. </summary>
<img width="1184" alt="Screen Shot 2020-12-12 at 5 02 47 PM" src="https://user-images.githubusercontent.com/13089297/102000425-2350e180-3c9c-11eb-999e-a95b37e9ef54.png">
</details>
**Callgrind**
<img width="936" alt="Screen Shot 2020-12-12 at 12 28 54 PM" src="https://user-images.githubusercontent.com/13089297/101994421-2e454b00-3c77-11eb-9cd3-8cde550f536e.png">
Test plan: existing unit tests.
Differential Revision: [D25590731](https://our.internmc.facebook.com/intern/diff/D25590731)
[ghstack-poisoned]
…ject_has_torch_function" This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API. Test plan: Existing unit tests. Benchmarks are in #48966 Differential Revision: [D25590732](https://our.internmc.facebook.com/intern/diff/D25590732) [ghstack-poisoned]
…static False when scripting"
This PR lets us skip the `if not torch.jit.is_scripting():` guards on `functional` and `nn.functional` by directly registering `has_torch_function` and `object_has_torch_function` to the JIT as statically False.
**Benchmarks**
The benchmark script is kind of long. The reason is that it's testing all four PRs in the stack, plus threading and subprocessing so that the benchmark can utilize multiple cores while still collecting good numbers. Both wall times and instruction counts were collected. This stack changes dozens of operators / functions, but very mechanically such that there are only a handful of codepath changes. Each row is a slightly different code path (e.g. testing in Python, testing in the arg parser, different input types, etc.)
<details>
<summary> Test script </summary>
```
import argparse
import multiprocessing
import multiprocessing.dummy
import os
import pickle
import queue
import random
import sys
import subprocess
import tempfile
import time
import torch
from torch.utils.benchmark import Timer, Compare, Measurement
NUM_CORES = multiprocessing.cpu_count()
ENVS = {
"ref": "HEAD (current)",
"torch_fn_overhead_stack_0": "#48963",
"torch_fn_overhead_stack_1": "#48964",
"torch_fn_overhead_stack_2": "#48965",
"torch_fn_overhead_stack_3": "#48966",
}
CALLGRIND_ENVS = tuple(ENVS.keys())
MIN_RUN_TIME = 3
REPLICATES = {
"longer": 1_000,
"long": 300,
"short": 50,
}
CALLGRIND_NUMBER = {
"overnight": 500_000,
"long": 250_000,
"short": 10_000,
}
CALLGRIND_TIMEOUT = {
"overnight": 800,
"long": 400,
"short": 100,
}
SETUP = """
x = torch.ones((1, 1))
y = torch.ones((1, 1))
w_tensor = torch.ones((1, 1), requires_grad=True)
linear = torch.nn.Linear(1, 1, bias=False)
linear_w = linear.weight
"""
TASKS = {
"C++: unary `.t()`": "w_tensor.t()",
"C++: unary (Parameter) `.t()`": "linear_w.t()",
"C++: binary (Parameter) `mul` ": "x + linear_w",
"tensor.py: _wrap_type_error_to_not_implemented `__floordiv__`": "x // y",
"tensor.py: method `__hash__`": "hash(x)",
"Python scalar `__rsub__`": "1 - x",
"functional.py: (unary) `unique`": "torch.functional.unique(x)",
"functional.py: (args) `atleast_1d`": "torch.functional.atleast_1d((x, y))",
"nn/functional.py: (unary) `relu`": "torch.nn.functional.relu(x)",
"nn/functional.py: (args) `linear`": "torch.nn.functional.linear(x, w_tensor)",
"nn/functional.py: (args) `linear (Parameter)`": "torch.nn.functional.linear(x, linear_w)",
"Linear(..., bias=False)": "linear(x)",
}
def _worker_main(argv, fn):
parser = argparse.ArgumentParser()
parser.add_argument("--output_file", type=str)
parser.add_argument("--single_task", type=int, default=None)
parser.add_argument("--length", type=str)
args = parser.parse_args(argv)
single_task = args.single_task
conda_prefix = os.getenv("CONDA_PREFIX")
assert torch.__file__.startswith(conda_prefix)
env = os.path.split(conda_prefix)[1]
assert env in ENVS
results = []
for i, (k, stmt) in enumerate(TASKS.items()):
if single_task is not None and single_task != i:
continue
timer = Timer(
stmt=stmt,
setup=SETUP,
sub_label=k,
description=ENVS[env],
)
results.append(fn(timer, args.length))
with open(args.output_file, "wb") as f:
pickle.dump(results, f)
def worker_main(argv):
_worker_main(
argv,
lambda timer, _: timer.blocked_autorange(min_run_time=MIN_RUN_TIME)
)
def callgrind_worker_main(argv):
_worker_main(
argv,
lambda timer, length: timer.collect_callgrind(number=CALLGRIND_NUMBER[length], collect_baseline=False))
def main(argv):
parser = argparse.ArgumentParser()
parser.add_argument("--long", action="store_true")
parser.add_argument("--longer", action="store_true")
args = parser.parse_args(argv)
if args.longer:
length = "longer"
elif args.long:
length = "long"
else:
length = "short"
replicates = REPLICATES[length]
num_workers = int(NUM_CORES // 2)
tasks = list(ENVS.keys()) * replicates
random.shuffle(tasks)
task_queue = queue.Queue()
for _ in range(replicates):
envs = list(ENVS.keys())
random.shuffle(envs)
for e in envs:
task_queue.put((e, None))
callgrind_task_queue = queue.Queue()
for e in CALLGRIND_ENVS:
for i, _ in enumerate(TASKS):
callgrind_task_queue.put((e, i))
results = []
callgrind_results = []
def map_fn(worker_id):
# Adjacent cores often share cache and maxing out a machine can distort
# timings so we space them out.
callgrind_cores = f"{worker_id * 2}-{worker_id * 2 + 1}"
time_cores = str(worker_id * 2)
_, output_file = tempfile.mkstemp(suffix=".pkl")
try:
loop_tasks = (
# Callgrind is long running, and then the workers can help with
# timing after they finish collecting counts.
(callgrind_task_queue, callgrind_results, "callgrind_worker", callgrind_cores, CALLGRIND_TIMEOUT[length]),
(task_queue, results, "worker", time_cores, None))
for queue_i, results_i, mode_i, cores, timeout in loop_tasks:
while True:
try:
env, task_i = queue_i.get_nowait()
except queue.Empty:
break
remaining_attempts = 3
while True:
try:
subprocess.run(
" ".join([
"source", "activate", env, "&&",
"taskset", "--cpu-list", cores,
"python", os.path.abspath(__file__),
"--mode", mode_i,
"--length", length,
"--output_file", output_file
] + ([] if task_i is None else ["--single_task", str(task_i)])),
shell=True,
check=True,
timeout=timeout,
)
break
except subprocess.TimeoutExpired:
# Sometimes Valgrind will hang if there are too many
# concurrent runs.
remaining_attempts -= 1
if not remaining_attempts:
print("Too many failed attempts.")
raise
print(f"Timeout after {timeout} sec. Retrying.")
# We don't need a lock, as the GIL is enough.
with open(output_file, "rb") as f:
results_i.extend(pickle.load(f))
finally:
os.remove(output_file)
with multiprocessing.dummy.Pool(num_workers) as pool:
st, st_estimate, eta, n_total = time.time(), None, "", len(tasks) * len(TASKS)
map_job = pool.map_async(map_fn, range(num_workers))
while not map_job.ready():
n_complete = len(results)
if n_complete and len(callgrind_results):
if st_estimate is None:
st_estimate = time.time()
else:
sec_per_element = (time.time() - st_estimate) / n_complete
n_remaining = n_total - n_complete
eta = f"ETA: {n_remaining * sec_per_element:.0f} sec"
print(
f"\r{n_complete} / {n_total} "
f"({len(callgrind_results)} / {len(CALLGRIND_ENVS) * len(TASKS)}) "
f"{eta}".ljust(40), end="")
sys.stdout.flush()
time.sleep(2)
total_time = int(time.time() - st)
print(f"\nTotal time: {int(total_time // 60)} min, {total_time % 60} sec")
desc_to_ind = {k: i for i, k in enumerate(ENVS.values())}
results.sort(key=lambda r: desc_to_ind[r.description])
# TODO: Compare should be richer and more modular.
compare = Compare(results)
compare.trim_significant_figures()
compare.colorize(rowwise=True)
# Manually add master vs. overall relative delta t.
merged_results = {
(r.description, r.sub_label): r
for r in Measurement.merge(results)
}
cmp_lines = str(compare).splitlines(False)
print(cmp_lines[0][:-1] + "-" * 15 + "]")
print(f"{cmp_lines[1]} |{'':>10}\u0394t")
print(cmp_lines[2] + "-" * 15)
for l, t in zip(cmp_lines[3:3 + len(TASKS)], TASKS.keys()):
assert l.strip().startswith(t)
t0 = merged_results[(ENVS["ref"], t)].median
t1 = merged_results[(ENVS["torch_fn_overhead_stack_3"], t)].median
print(f"{l} |{'':>5}{(t1 / t0 - 1) * 100:>6.1f}%")
print("\n".join(cmp_lines[3 + len(TASKS):]))
counts_dict = {
(r.task_spec.description, r.task_spec.sub_label): r.counts(denoise=True)
for r in callgrind_results
}
def rel_diff(x, x0):
return f"{(x / x0 - 1) * 100:>6.1f}%"
task_pad = max(len(t) for t in TASKS)
print(f"\n\nInstruction % change (relative to `{CALLGRIND_ENVS[0]}`)")
print(" " * (task_pad + 8) + (" " * 7).join([ENVS[env] for env in CALLGRIND_ENVS[1:]]))
for t in TASKS:
values = [counts_dict[(ENVS[env], t)] for env in CALLGRIND_ENVS]
print(t.ljust(task_pad + 3) + " ".join([
rel_diff(v, values[0]).rjust(len(ENVS[env]) + 5)
for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]))
print("\033[4m" + " Instructions per invocation".ljust(task_pad + 3) + " ".join([
f"{v // CALLGRIND_NUMBER[length]:.0f}".rjust(len(ENVS[env]) + 5)
for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]) + "\033[0m")
print()
import pdb
pdb.set_trace()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--mode", type=str, choices=("main", "worker", "callgrind_worker"), default="main")
args, remaining = parser.parse_known_args()
if args.mode == "main":
main(remaining)
elif args.mode == "callgrind_worker":
callgrind_worker_main(remaining)
else:
worker_main(remaining)
```
</details>
**Wall time**
<img width="1178" alt="Screen Shot 2020-12-12 at 12 28 13 PM" src="https://user-images.githubusercontent.com/13089297/101994419-284f6a00-3c77-11eb-8dc8-4f69a890302e.png">
<details>
<summary> Longer run (`python test.py --long`) is basically identical. </summary>
<img width="1184" alt="Screen Shot 2020-12-12 at 5 02 47 PM" src="https://user-images.githubusercontent.com/13089297/102000425-2350e180-3c9c-11eb-999e-a95b37e9ef54.png">
</details>
**Callgrind**
<img width="936" alt="Screen Shot 2020-12-12 at 12 28 54 PM" src="https://user-images.githubusercontent.com/13089297/101994421-2e454b00-3c77-11eb-9cd3-8cde550f536e.png">
Test plan: existing unit tests.
Differential Revision: [D25590731](https://our.internmc.facebook.com/intern/diff/D25590731)
[ghstack-poisoned]
| @@ -125,3 +126,111 @@ PyObject* THPModule_disable_torch_function(PyObject *self, PyObject *a) { | |||
| return result; | |||
| END_HANDLE_TH_ERRORS | |||
| } | |||
|
|
|||
| // Makes sure that we don't check for __torch_function__ on basic Python types | |||
| static bool is_basic_python_type(PyTypeObject *tp) | |||
There was a problem hiding this comment.
This function looks unchanged but the functions below seem to have been changed
There was a problem hiding this comment.
Indeed, this one was just moved from torch/csrc/utils/python_arg_parser.h The functions below were modified to:
a) Bail out faster. (e.g. don't do attr checks on known types)
b) More efficiently handle checking of multiple Python values, which generally means trying to be as lazy as possible with Python containers. (e.g. PySequence_Fast does an extra refcount bump and decref because it has no way of knowing that we'll keep args alive until it's done.)
| return ( | ||
| !THPVariable_CheckTypeExact(tp) && | ||
| !is_basic_python_type(tp) && | ||
| torch::torch_function_enabled() && |
There was a problem hiding this comment.
huh, I would have expected torch::torch_function_enabled to be the first thing to test. Is it more expensive than I thought?
There was a problem hiding this comment.
The main reason is that I expect !THPVariable_CheckTypeExact(tp) && !is_basic_python_type(tp) to be false in most cases (particularly in normal eager use) while torch::torch_function_enabled() is normally true, so it was a question of likely_false && likely_true instead of the other way around. I think I checked and it saved an instruction or two, although between branch predictors and instruction parallelism I don't know if it actually matters on a real chip. And because sequence_has_torch_function calls has_torch_function, you could wind up doing the check a whole two to three times!!! (Alas, we're waaaaayyyy under what I could hope to A/B with wall time here.) It probably doesn't matter, but this part of the path is so hot that I'm paranoid.
…ject_has_torch_function" This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API. Test plan: Existing unit tests. Benchmarks are in #48966 Differential Revision: [D25590732](https://our.internmc.facebook.com/intern/diff/D25590732) [ghstack-poisoned]
…static False when scripting"
This PR lets us skip the `if not torch.jit.is_scripting():` guards on `functional` and `nn.functional` by directly registering `has_torch_function` and `object_has_torch_function` to the JIT as statically False.
**Benchmarks**
The benchmark script is kind of long. The reason is that it's testing all four PRs in the stack, plus threading and subprocessing so that the benchmark can utilize multiple cores while still collecting good numbers. Both wall times and instruction counts were collected. This stack changes dozens of operators / functions, but very mechanically such that there are only a handful of codepath changes. Each row is a slightly different code path (e.g. testing in Python, testing in the arg parser, different input types, etc.)
<details>
<summary> Test script </summary>
```
import argparse
import multiprocessing
import multiprocessing.dummy
import os
import pickle
import queue
import random
import sys
import subprocess
import tempfile
import time
import torch
from torch.utils.benchmark import Timer, Compare, Measurement
NUM_CORES = multiprocessing.cpu_count()
ENVS = {
"ref": "HEAD (current)",
"torch_fn_overhead_stack_0": "#48963",
"torch_fn_overhead_stack_1": "#48964",
"torch_fn_overhead_stack_2": "#48965",
"torch_fn_overhead_stack_3": "#48966",
}
CALLGRIND_ENVS = tuple(ENVS.keys())
MIN_RUN_TIME = 3
REPLICATES = {
"longer": 1_000,
"long": 300,
"short": 50,
}
CALLGRIND_NUMBER = {
"overnight": 500_000,
"long": 250_000,
"short": 10_000,
}
CALLGRIND_TIMEOUT = {
"overnight": 800,
"long": 400,
"short": 100,
}
SETUP = """
x = torch.ones((1, 1))
y = torch.ones((1, 1))
w_tensor = torch.ones((1, 1), requires_grad=True)
linear = torch.nn.Linear(1, 1, bias=False)
linear_w = linear.weight
"""
TASKS = {
"C++: unary `.t()`": "w_tensor.t()",
"C++: unary (Parameter) `.t()`": "linear_w.t()",
"C++: binary (Parameter) `mul` ": "x + linear_w",
"tensor.py: _wrap_type_error_to_not_implemented `__floordiv__`": "x // y",
"tensor.py: method `__hash__`": "hash(x)",
"Python scalar `__rsub__`": "1 - x",
"functional.py: (unary) `unique`": "torch.functional.unique(x)",
"functional.py: (args) `atleast_1d`": "torch.functional.atleast_1d((x, y))",
"nn/functional.py: (unary) `relu`": "torch.nn.functional.relu(x)",
"nn/functional.py: (args) `linear`": "torch.nn.functional.linear(x, w_tensor)",
"nn/functional.py: (args) `linear (Parameter)`": "torch.nn.functional.linear(x, linear_w)",
"Linear(..., bias=False)": "linear(x)",
}
def _worker_main(argv, fn):
parser = argparse.ArgumentParser()
parser.add_argument("--output_file", type=str)
parser.add_argument("--single_task", type=int, default=None)
parser.add_argument("--length", type=str)
args = parser.parse_args(argv)
single_task = args.single_task
conda_prefix = os.getenv("CONDA_PREFIX")
assert torch.__file__.startswith(conda_prefix)
env = os.path.split(conda_prefix)[1]
assert env in ENVS
results = []
for i, (k, stmt) in enumerate(TASKS.items()):
if single_task is not None and single_task != i:
continue
timer = Timer(
stmt=stmt,
setup=SETUP,
sub_label=k,
description=ENVS[env],
)
results.append(fn(timer, args.length))
with open(args.output_file, "wb") as f:
pickle.dump(results, f)
def worker_main(argv):
_worker_main(
argv,
lambda timer, _: timer.blocked_autorange(min_run_time=MIN_RUN_TIME)
)
def callgrind_worker_main(argv):
_worker_main(
argv,
lambda timer, length: timer.collect_callgrind(number=CALLGRIND_NUMBER[length], collect_baseline=False))
def main(argv):
parser = argparse.ArgumentParser()
parser.add_argument("--long", action="store_true")
parser.add_argument("--longer", action="store_true")
args = parser.parse_args(argv)
if args.longer:
length = "longer"
elif args.long:
length = "long"
else:
length = "short"
replicates = REPLICATES[length]
num_workers = int(NUM_CORES // 2)
tasks = list(ENVS.keys()) * replicates
random.shuffle(tasks)
task_queue = queue.Queue()
for _ in range(replicates):
envs = list(ENVS.keys())
random.shuffle(envs)
for e in envs:
task_queue.put((e, None))
callgrind_task_queue = queue.Queue()
for e in CALLGRIND_ENVS:
for i, _ in enumerate(TASKS):
callgrind_task_queue.put((e, i))
results = []
callgrind_results = []
def map_fn(worker_id):
# Adjacent cores often share cache and maxing out a machine can distort
# timings so we space them out.
callgrind_cores = f"{worker_id * 2}-{worker_id * 2 + 1}"
time_cores = str(worker_id * 2)
_, output_file = tempfile.mkstemp(suffix=".pkl")
try:
loop_tasks = (
# Callgrind is long running, and then the workers can help with
# timing after they finish collecting counts.
(callgrind_task_queue, callgrind_results, "callgrind_worker", callgrind_cores, CALLGRIND_TIMEOUT[length]),
(task_queue, results, "worker", time_cores, None))
for queue_i, results_i, mode_i, cores, timeout in loop_tasks:
while True:
try:
env, task_i = queue_i.get_nowait()
except queue.Empty:
break
remaining_attempts = 3
while True:
try:
subprocess.run(
" ".join([
"source", "activate", env, "&&",
"taskset", "--cpu-list", cores,
"python", os.path.abspath(__file__),
"--mode", mode_i,
"--length", length,
"--output_file", output_file
] + ([] if task_i is None else ["--single_task", str(task_i)])),
shell=True,
check=True,
timeout=timeout,
)
break
except subprocess.TimeoutExpired:
# Sometimes Valgrind will hang if there are too many
# concurrent runs.
remaining_attempts -= 1
if not remaining_attempts:
print("Too many failed attempts.")
raise
print(f"Timeout after {timeout} sec. Retrying.")
# We don't need a lock, as the GIL is enough.
with open(output_file, "rb") as f:
results_i.extend(pickle.load(f))
finally:
os.remove(output_file)
with multiprocessing.dummy.Pool(num_workers) as pool:
st, st_estimate, eta, n_total = time.time(), None, "", len(tasks) * len(TASKS)
map_job = pool.map_async(map_fn, range(num_workers))
while not map_job.ready():
n_complete = len(results)
if n_complete and len(callgrind_results):
if st_estimate is None:
st_estimate = time.time()
else:
sec_per_element = (time.time() - st_estimate) / n_complete
n_remaining = n_total - n_complete
eta = f"ETA: {n_remaining * sec_per_element:.0f} sec"
print(
f"\r{n_complete} / {n_total} "
f"({len(callgrind_results)} / {len(CALLGRIND_ENVS) * len(TASKS)}) "
f"{eta}".ljust(40), end="")
sys.stdout.flush()
time.sleep(2)
total_time = int(time.time() - st)
print(f"\nTotal time: {int(total_time // 60)} min, {total_time % 60} sec")
desc_to_ind = {k: i for i, k in enumerate(ENVS.values())}
results.sort(key=lambda r: desc_to_ind[r.description])
# TODO: Compare should be richer and more modular.
compare = Compare(results)
compare.trim_significant_figures()
compare.colorize(rowwise=True)
# Manually add master vs. overall relative delta t.
merged_results = {
(r.description, r.sub_label): r
for r in Measurement.merge(results)
}
cmp_lines = str(compare).splitlines(False)
print(cmp_lines[0][:-1] + "-" * 15 + "]")
print(f"{cmp_lines[1]} |{'':>10}\u0394t")
print(cmp_lines[2] + "-" * 15)
for l, t in zip(cmp_lines[3:3 + len(TASKS)], TASKS.keys()):
assert l.strip().startswith(t)
t0 = merged_results[(ENVS["ref"], t)].median
t1 = merged_results[(ENVS["torch_fn_overhead_stack_3"], t)].median
print(f"{l} |{'':>5}{(t1 / t0 - 1) * 100:>6.1f}%")
print("\n".join(cmp_lines[3 + len(TASKS):]))
counts_dict = {
(r.task_spec.description, r.task_spec.sub_label): r.counts(denoise=True)
for r in callgrind_results
}
def rel_diff(x, x0):
return f"{(x / x0 - 1) * 100:>6.1f}%"
task_pad = max(len(t) for t in TASKS)
print(f"\n\nInstruction % change (relative to `{CALLGRIND_ENVS[0]}`)")
print(" " * (task_pad + 8) + (" " * 7).join([ENVS[env] for env in CALLGRIND_ENVS[1:]]))
for t in TASKS:
values = [counts_dict[(ENVS[env], t)] for env in CALLGRIND_ENVS]
print(t.ljust(task_pad + 3) + " ".join([
rel_diff(v, values[0]).rjust(len(ENVS[env]) + 5)
for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]))
print("\033[4m" + " Instructions per invocation".ljust(task_pad + 3) + " ".join([
f"{v // CALLGRIND_NUMBER[length]:.0f}".rjust(len(ENVS[env]) + 5)
for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]) + "\033[0m")
print()
import pdb
pdb.set_trace()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--mode", type=str, choices=("main", "worker", "callgrind_worker"), default="main")
args, remaining = parser.parse_known_args()
if args.mode == "main":
main(remaining)
elif args.mode == "callgrind_worker":
callgrind_worker_main(remaining)
else:
worker_main(remaining)
```
</details>
**Wall time**
<img width="1178" alt="Screen Shot 2020-12-12 at 12 28 13 PM" src="https://user-images.githubusercontent.com/13089297/101994419-284f6a00-3c77-11eb-8dc8-4f69a890302e.png">
<details>
<summary> Longer run (`python test.py --long`) is basically identical. </summary>
<img width="1184" alt="Screen Shot 2020-12-12 at 5 02 47 PM" src="https://user-images.githubusercontent.com/13089297/102000425-2350e180-3c9c-11eb-999e-a95b37e9ef54.png">
</details>
**Callgrind**
<img width="936" alt="Screen Shot 2020-12-12 at 12 28 54 PM" src="https://user-images.githubusercontent.com/13089297/101994421-2e454b00-3c77-11eb-9cd3-8cde550f536e.png">
Test plan: existing unit tests.
Differential Revision: [D25590731](https://our.internmc.facebook.com/intern/diff/D25590731)
[ghstack-poisoned]
…ject_has_torch_function" This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API. Test plan: Existing unit tests. Benchmarks are in #48966 Differential Revision: [D25590732](https://our.internmc.facebook.com/intern/diff/D25590732) [ghstack-poisoned]
…static False when scripting"
This PR lets us skip the `if not torch.jit.is_scripting():` guards on `functional` and `nn.functional` by directly registering `has_torch_function` and `object_has_torch_function` to the JIT as statically False.
**Benchmarks**
The benchmark script is kind of long. The reason is that it's testing all four PRs in the stack, plus threading and subprocessing so that the benchmark can utilize multiple cores while still collecting good numbers. Both wall times and instruction counts were collected. This stack changes dozens of operators / functions, but very mechanically such that there are only a handful of codepath changes. Each row is a slightly different code path (e.g. testing in Python, testing in the arg parser, different input types, etc.)
<details>
<summary> Test script </summary>
```
import argparse
import multiprocessing
import multiprocessing.dummy
import os
import pickle
import queue
import random
import sys
import subprocess
import tempfile
import time
import torch
from torch.utils.benchmark import Timer, Compare, Measurement
NUM_CORES = multiprocessing.cpu_count()
ENVS = {
"ref": "HEAD (current)",
"torch_fn_overhead_stack_0": "#48963",
"torch_fn_overhead_stack_1": "#48964",
"torch_fn_overhead_stack_2": "#48965",
"torch_fn_overhead_stack_3": "#48966",
}
CALLGRIND_ENVS = tuple(ENVS.keys())
MIN_RUN_TIME = 3
REPLICATES = {
"longer": 1_000,
"long": 300,
"short": 50,
}
CALLGRIND_NUMBER = {
"overnight": 500_000,
"long": 250_000,
"short": 10_000,
}
CALLGRIND_TIMEOUT = {
"overnight": 800,
"long": 400,
"short": 100,
}
SETUP = """
x = torch.ones((1, 1))
y = torch.ones((1, 1))
w_tensor = torch.ones((1, 1), requires_grad=True)
linear = torch.nn.Linear(1, 1, bias=False)
linear_w = linear.weight
"""
TASKS = {
"C++: unary `.t()`": "w_tensor.t()",
"C++: unary (Parameter) `.t()`": "linear_w.t()",
"C++: binary (Parameter) `mul` ": "x + linear_w",
"tensor.py: _wrap_type_error_to_not_implemented `__floordiv__`": "x // y",
"tensor.py: method `__hash__`": "hash(x)",
"Python scalar `__rsub__`": "1 - x",
"functional.py: (unary) `unique`": "torch.functional.unique(x)",
"functional.py: (args) `atleast_1d`": "torch.functional.atleast_1d((x, y))",
"nn/functional.py: (unary) `relu`": "torch.nn.functional.relu(x)",
"nn/functional.py: (args) `linear`": "torch.nn.functional.linear(x, w_tensor)",
"nn/functional.py: (args) `linear (Parameter)`": "torch.nn.functional.linear(x, linear_w)",
"Linear(..., bias=False)": "linear(x)",
}
def _worker_main(argv, fn):
parser = argparse.ArgumentParser()
parser.add_argument("--output_file", type=str)
parser.add_argument("--single_task", type=int, default=None)
parser.add_argument("--length", type=str)
args = parser.parse_args(argv)
single_task = args.single_task
conda_prefix = os.getenv("CONDA_PREFIX")
assert torch.__file__.startswith(conda_prefix)
env = os.path.split(conda_prefix)[1]
assert env in ENVS
results = []
for i, (k, stmt) in enumerate(TASKS.items()):
if single_task is not None and single_task != i:
continue
timer = Timer(
stmt=stmt,
setup=SETUP,
sub_label=k,
description=ENVS[env],
)
results.append(fn(timer, args.length))
with open(args.output_file, "wb") as f:
pickle.dump(results, f)
def worker_main(argv):
_worker_main(
argv,
lambda timer, _: timer.blocked_autorange(min_run_time=MIN_RUN_TIME)
)
def callgrind_worker_main(argv):
_worker_main(
argv,
lambda timer, length: timer.collect_callgrind(number=CALLGRIND_NUMBER[length], collect_baseline=False))
def main(argv):
parser = argparse.ArgumentParser()
parser.add_argument("--long", action="store_true")
parser.add_argument("--longer", action="store_true")
args = parser.parse_args(argv)
if args.longer:
length = "longer"
elif args.long:
length = "long"
else:
length = "short"
replicates = REPLICATES[length]
num_workers = int(NUM_CORES // 2)
tasks = list(ENVS.keys()) * replicates
random.shuffle(tasks)
task_queue = queue.Queue()
for _ in range(replicates):
envs = list(ENVS.keys())
random.shuffle(envs)
for e in envs:
task_queue.put((e, None))
callgrind_task_queue = queue.Queue()
for e in CALLGRIND_ENVS:
for i, _ in enumerate(TASKS):
callgrind_task_queue.put((e, i))
results = []
callgrind_results = []
def map_fn(worker_id):
# Adjacent cores often share cache and maxing out a machine can distort
# timings so we space them out.
callgrind_cores = f"{worker_id * 2}-{worker_id * 2 + 1}"
time_cores = str(worker_id * 2)
_, output_file = tempfile.mkstemp(suffix=".pkl")
try:
loop_tasks = (
# Callgrind is long running, and then the workers can help with
# timing after they finish collecting counts.
(callgrind_task_queue, callgrind_results, "callgrind_worker", callgrind_cores, CALLGRIND_TIMEOUT[length]),
(task_queue, results, "worker", time_cores, None))
for queue_i, results_i, mode_i, cores, timeout in loop_tasks:
while True:
try:
env, task_i = queue_i.get_nowait()
except queue.Empty:
break
remaining_attempts = 3
while True:
try:
subprocess.run(
" ".join([
"source", "activate", env, "&&",
"taskset", "--cpu-list", cores,
"python", os.path.abspath(__file__),
"--mode", mode_i,
"--length", length,
"--output_file", output_file
] + ([] if task_i is None else ["--single_task", str(task_i)])),
shell=True,
check=True,
timeout=timeout,
)
break
except subprocess.TimeoutExpired:
# Sometimes Valgrind will hang if there are too many
# concurrent runs.
remaining_attempts -= 1
if not remaining_attempts:
print("Too many failed attempts.")
raise
print(f"Timeout after {timeout} sec. Retrying.")
# We don't need a lock, as the GIL is enough.
with open(output_file, "rb") as f:
results_i.extend(pickle.load(f))
finally:
os.remove(output_file)
with multiprocessing.dummy.Pool(num_workers) as pool:
st, st_estimate, eta, n_total = time.time(), None, "", len(tasks) * len(TASKS)
map_job = pool.map_async(map_fn, range(num_workers))
while not map_job.ready():
n_complete = len(results)
if n_complete and len(callgrind_results):
if st_estimate is None:
st_estimate = time.time()
else:
sec_per_element = (time.time() - st_estimate) / n_complete
n_remaining = n_total - n_complete
eta = f"ETA: {n_remaining * sec_per_element:.0f} sec"
print(
f"\r{n_complete} / {n_total} "
f"({len(callgrind_results)} / {len(CALLGRIND_ENVS) * len(TASKS)}) "
f"{eta}".ljust(40), end="")
sys.stdout.flush()
time.sleep(2)
total_time = int(time.time() - st)
print(f"\nTotal time: {int(total_time // 60)} min, {total_time % 60} sec")
desc_to_ind = {k: i for i, k in enumerate(ENVS.values())}
results.sort(key=lambda r: desc_to_ind[r.description])
# TODO: Compare should be richer and more modular.
compare = Compare(results)
compare.trim_significant_figures()
compare.colorize(rowwise=True)
# Manually add master vs. overall relative delta t.
merged_results = {
(r.description, r.sub_label): r
for r in Measurement.merge(results)
}
cmp_lines = str(compare).splitlines(False)
print(cmp_lines[0][:-1] + "-" * 15 + "]")
print(f"{cmp_lines[1]} |{'':>10}\u0394t")
print(cmp_lines[2] + "-" * 15)
for l, t in zip(cmp_lines[3:3 + len(TASKS)], TASKS.keys()):
assert l.strip().startswith(t)
t0 = merged_results[(ENVS["ref"], t)].median
t1 = merged_results[(ENVS["torch_fn_overhead_stack_3"], t)].median
print(f"{l} |{'':>5}{(t1 / t0 - 1) * 100:>6.1f}%")
print("\n".join(cmp_lines[3 + len(TASKS):]))
counts_dict = {
(r.task_spec.description, r.task_spec.sub_label): r.counts(denoise=True)
for r in callgrind_results
}
def rel_diff(x, x0):
return f"{(x / x0 - 1) * 100:>6.1f}%"
task_pad = max(len(t) for t in TASKS)
print(f"\n\nInstruction % change (relative to `{CALLGRIND_ENVS[0]}`)")
print(" " * (task_pad + 8) + (" " * 7).join([ENVS[env] for env in CALLGRIND_ENVS[1:]]))
for t in TASKS:
values = [counts_dict[(ENVS[env], t)] for env in CALLGRIND_ENVS]
print(t.ljust(task_pad + 3) + " ".join([
rel_diff(v, values[0]).rjust(len(ENVS[env]) + 5)
for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]))
print("\033[4m" + " Instructions per invocation".ljust(task_pad + 3) + " ".join([
f"{v // CALLGRIND_NUMBER[length]:.0f}".rjust(len(ENVS[env]) + 5)
for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]) + "\033[0m")
print()
import pdb
pdb.set_trace()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--mode", type=str, choices=("main", "worker", "callgrind_worker"), default="main")
args, remaining = parser.parse_known_args()
if args.mode == "main":
main(remaining)
elif args.mode == "callgrind_worker":
callgrind_worker_main(remaining)
else:
worker_main(remaining)
```
</details>
**Wall time**
<img width="1178" alt="Screen Shot 2020-12-12 at 12 28 13 PM" src="https://user-images.githubusercontent.com/13089297/101994419-284f6a00-3c77-11eb-8dc8-4f69a890302e.png">
<details>
<summary> Longer run (`python test.py --long`) is basically identical. </summary>
<img width="1184" alt="Screen Shot 2020-12-12 at 5 02 47 PM" src="https://user-images.githubusercontent.com/13089297/102000425-2350e180-3c9c-11eb-999e-a95b37e9ef54.png">
</details>
**Callgrind**
<img width="936" alt="Screen Shot 2020-12-12 at 12 28 54 PM" src="https://user-images.githubusercontent.com/13089297/101994421-2e454b00-3c77-11eb-9cd3-8cde550f536e.png">
Test plan: existing unit tests.
Differential Revision: [D25590731](https://our.internmc.facebook.com/intern/diff/D25590731)
[ghstack-poisoned]
…ject_has_torch_function" This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API. Test plan: Existing unit tests. Benchmarks are in #48966 Differential Revision: [D25590732](https://our.internmc.facebook.com/intern/diff/D25590732) [ghstack-poisoned]
…static False when scripting"
This PR lets us skip the `if not torch.jit.is_scripting():` guards on `functional` and `nn.functional` by directly registering `has_torch_function` and `object_has_torch_function` to the JIT as statically False.
**Benchmarks**
The benchmark script is kind of long. The reason is that it's testing all four PRs in the stack, plus threading and subprocessing so that the benchmark can utilize multiple cores while still collecting good numbers. Both wall times and instruction counts were collected. This stack changes dozens of operators / functions, but very mechanically such that there are only a handful of codepath changes. Each row is a slightly different code path (e.g. testing in Python, testing in the arg parser, different input types, etc.)
<details>
<summary> Test script </summary>
```
import argparse
import multiprocessing
import multiprocessing.dummy
import os
import pickle
import queue
import random
import sys
import subprocess
import tempfile
import time
import torch
from torch.utils.benchmark import Timer, Compare, Measurement
NUM_CORES = multiprocessing.cpu_count()
ENVS = {
"ref": "HEAD (current)",
"torch_fn_overhead_stack_0": "#48963",
"torch_fn_overhead_stack_1": "#48964",
"torch_fn_overhead_stack_2": "#48965",
"torch_fn_overhead_stack_3": "#48966",
}
CALLGRIND_ENVS = tuple(ENVS.keys())
MIN_RUN_TIME = 3
REPLICATES = {
"longer": 1_000,
"long": 300,
"short": 50,
}
CALLGRIND_NUMBER = {
"overnight": 500_000,
"long": 250_000,
"short": 10_000,
}
CALLGRIND_TIMEOUT = {
"overnight": 800,
"long": 400,
"short": 100,
}
SETUP = """
x = torch.ones((1, 1))
y = torch.ones((1, 1))
w_tensor = torch.ones((1, 1), requires_grad=True)
linear = torch.nn.Linear(1, 1, bias=False)
linear_w = linear.weight
"""
TASKS = {
"C++: unary `.t()`": "w_tensor.t()",
"C++: unary (Parameter) `.t()`": "linear_w.t()",
"C++: binary (Parameter) `mul` ": "x + linear_w",
"tensor.py: _wrap_type_error_to_not_implemented `__floordiv__`": "x // y",
"tensor.py: method `__hash__`": "hash(x)",
"Python scalar `__rsub__`": "1 - x",
"functional.py: (unary) `unique`": "torch.functional.unique(x)",
"functional.py: (args) `atleast_1d`": "torch.functional.atleast_1d((x, y))",
"nn/functional.py: (unary) `relu`": "torch.nn.functional.relu(x)",
"nn/functional.py: (args) `linear`": "torch.nn.functional.linear(x, w_tensor)",
"nn/functional.py: (args) `linear (Parameter)`": "torch.nn.functional.linear(x, linear_w)",
"Linear(..., bias=False)": "linear(x)",
}
def _worker_main(argv, fn):
parser = argparse.ArgumentParser()
parser.add_argument("--output_file", type=str)
parser.add_argument("--single_task", type=int, default=None)
parser.add_argument("--length", type=str)
args = parser.parse_args(argv)
single_task = args.single_task
conda_prefix = os.getenv("CONDA_PREFIX")
assert torch.__file__.startswith(conda_prefix)
env = os.path.split(conda_prefix)[1]
assert env in ENVS
results = []
for i, (k, stmt) in enumerate(TASKS.items()):
if single_task is not None and single_task != i:
continue
timer = Timer(
stmt=stmt,
setup=SETUP,
sub_label=k,
description=ENVS[env],
)
results.append(fn(timer, args.length))
with open(args.output_file, "wb") as f:
pickle.dump(results, f)
def worker_main(argv):
_worker_main(
argv,
lambda timer, _: timer.blocked_autorange(min_run_time=MIN_RUN_TIME)
)
def callgrind_worker_main(argv):
_worker_main(
argv,
lambda timer, length: timer.collect_callgrind(number=CALLGRIND_NUMBER[length], collect_baseline=False))
def main(argv):
parser = argparse.ArgumentParser()
parser.add_argument("--long", action="store_true")
parser.add_argument("--longer", action="store_true")
args = parser.parse_args(argv)
if args.longer:
length = "longer"
elif args.long:
length = "long"
else:
length = "short"
replicates = REPLICATES[length]
num_workers = int(NUM_CORES // 2)
tasks = list(ENVS.keys()) * replicates
random.shuffle(tasks)
task_queue = queue.Queue()
for _ in range(replicates):
envs = list(ENVS.keys())
random.shuffle(envs)
for e in envs:
task_queue.put((e, None))
callgrind_task_queue = queue.Queue()
for e in CALLGRIND_ENVS:
for i, _ in enumerate(TASKS):
callgrind_task_queue.put((e, i))
results = []
callgrind_results = []
def map_fn(worker_id):
# Adjacent cores often share cache and maxing out a machine can distort
# timings so we space them out.
callgrind_cores = f"{worker_id * 2}-{worker_id * 2 + 1}"
time_cores = str(worker_id * 2)
_, output_file = tempfile.mkstemp(suffix=".pkl")
try:
loop_tasks = (
# Callgrind is long running, and then the workers can help with
# timing after they finish collecting counts.
(callgrind_task_queue, callgrind_results, "callgrind_worker", callgrind_cores, CALLGRIND_TIMEOUT[length]),
(task_queue, results, "worker", time_cores, None))
for queue_i, results_i, mode_i, cores, timeout in loop_tasks:
while True:
try:
env, task_i = queue_i.get_nowait()
except queue.Empty:
break
remaining_attempts = 3
while True:
try:
subprocess.run(
" ".join([
"source", "activate", env, "&&",
"taskset", "--cpu-list", cores,
"python", os.path.abspath(__file__),
"--mode", mode_i,
"--length", length,
"--output_file", output_file
] + ([] if task_i is None else ["--single_task", str(task_i)])),
shell=True,
check=True,
timeout=timeout,
)
break
except subprocess.TimeoutExpired:
# Sometimes Valgrind will hang if there are too many
# concurrent runs.
remaining_attempts -= 1
if not remaining_attempts:
print("Too many failed attempts.")
raise
print(f"Timeout after {timeout} sec. Retrying.")
# We don't need a lock, as the GIL is enough.
with open(output_file, "rb") as f:
results_i.extend(pickle.load(f))
finally:
os.remove(output_file)
with multiprocessing.dummy.Pool(num_workers) as pool:
st, st_estimate, eta, n_total = time.time(), None, "", len(tasks) * len(TASKS)
map_job = pool.map_async(map_fn, range(num_workers))
while not map_job.ready():
n_complete = len(results)
if n_complete and len(callgrind_results):
if st_estimate is None:
st_estimate = time.time()
else:
sec_per_element = (time.time() - st_estimate) / n_complete
n_remaining = n_total - n_complete
eta = f"ETA: {n_remaining * sec_per_element:.0f} sec"
print(
f"\r{n_complete} / {n_total} "
f"({len(callgrind_results)} / {len(CALLGRIND_ENVS) * len(TASKS)}) "
f"{eta}".ljust(40), end="")
sys.stdout.flush()
time.sleep(2)
total_time = int(time.time() - st)
print(f"\nTotal time: {int(total_time // 60)} min, {total_time % 60} sec")
desc_to_ind = {k: i for i, k in enumerate(ENVS.values())}
results.sort(key=lambda r: desc_to_ind[r.description])
# TODO: Compare should be richer and more modular.
compare = Compare(results)
compare.trim_significant_figures()
compare.colorize(rowwise=True)
# Manually add master vs. overall relative delta t.
merged_results = {
(r.description, r.sub_label): r
for r in Measurement.merge(results)
}
cmp_lines = str(compare).splitlines(False)
print(cmp_lines[0][:-1] + "-" * 15 + "]")
print(f"{cmp_lines[1]} |{'':>10}\u0394t")
print(cmp_lines[2] + "-" * 15)
for l, t in zip(cmp_lines[3:3 + len(TASKS)], TASKS.keys()):
assert l.strip().startswith(t)
t0 = merged_results[(ENVS["ref"], t)].median
t1 = merged_results[(ENVS["torch_fn_overhead_stack_3"], t)].median
print(f"{l} |{'':>5}{(t1 / t0 - 1) * 100:>6.1f}%")
print("\n".join(cmp_lines[3 + len(TASKS):]))
counts_dict = {
(r.task_spec.description, r.task_spec.sub_label): r.counts(denoise=True)
for r in callgrind_results
}
def rel_diff(x, x0):
return f"{(x / x0 - 1) * 100:>6.1f}%"
task_pad = max(len(t) for t in TASKS)
print(f"\n\nInstruction % change (relative to `{CALLGRIND_ENVS[0]}`)")
print(" " * (task_pad + 8) + (" " * 7).join([ENVS[env] for env in CALLGRIND_ENVS[1:]]))
for t in TASKS:
values = [counts_dict[(ENVS[env], t)] for env in CALLGRIND_ENVS]
print(t.ljust(task_pad + 3) + " ".join([
rel_diff(v, values[0]).rjust(len(ENVS[env]) + 5)
for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]))
print("\033[4m" + " Instructions per invocation".ljust(task_pad + 3) + " ".join([
f"{v // CALLGRIND_NUMBER[length]:.0f}".rjust(len(ENVS[env]) + 5)
for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]) + "\033[0m")
print()
import pdb
pdb.set_trace()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--mode", type=str, choices=("main", "worker", "callgrind_worker"), default="main")
args, remaining = parser.parse_known_args()
if args.mode == "main":
main(remaining)
elif args.mode == "callgrind_worker":
callgrind_worker_main(remaining)
else:
worker_main(remaining)
```
</details>
**Wall time**
<img width="1178" alt="Screen Shot 2020-12-12 at 12 28 13 PM" src="https://user-images.githubusercontent.com/13089297/101994419-284f6a00-3c77-11eb-8dc8-4f69a890302e.png">
<details>
<summary> Longer run (`python test.py --long`) is basically identical. </summary>
<img width="1184" alt="Screen Shot 2020-12-12 at 5 02 47 PM" src="https://user-images.githubusercontent.com/13089297/102000425-2350e180-3c9c-11eb-999e-a95b37e9ef54.png">
</details>
**Callgrind**
<img width="936" alt="Screen Shot 2020-12-12 at 12 28 54 PM" src="https://user-images.githubusercontent.com/13089297/101994421-2e454b00-3c77-11eb-9cd3-8cde550f536e.png">
Test plan: existing unit tests.
Differential Revision: [D25590731](https://our.internmc.facebook.com/intern/diff/D25590731)
[ghstack-poisoned]
…ject_has_torch_function" This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API. Test plan: Existing unit tests. Benchmarks are in #48966 Differential Revision: [D25590732](https://our.internmc.facebook.com/intern/diff/D25590732) [ghstack-poisoned]
…static False when scripting"
This PR lets us skip the `if not torch.jit.is_scripting():` guards on `functional` and `nn.functional` by directly registering `has_torch_function` and `object_has_torch_function` to the JIT as statically False.
**Benchmarks**
The benchmark script is kind of long. The reason is that it's testing all four PRs in the stack, plus threading and subprocessing so that the benchmark can utilize multiple cores while still collecting good numbers. Both wall times and instruction counts were collected. This stack changes dozens of operators / functions, but very mechanically such that there are only a handful of codepath changes. Each row is a slightly different code path (e.g. testing in Python, testing in the arg parser, different input types, etc.)
<details>
<summary> Test script </summary>
```
import argparse
import multiprocessing
import multiprocessing.dummy
import os
import pickle
import queue
import random
import sys
import subprocess
import tempfile
import time
import torch
from torch.utils.benchmark import Timer, Compare, Measurement
NUM_CORES = multiprocessing.cpu_count()
ENVS = {
"ref": "HEAD (current)",
"torch_fn_overhead_stack_0": "#48963",
"torch_fn_overhead_stack_1": "#48964",
"torch_fn_overhead_stack_2": "#48965",
"torch_fn_overhead_stack_3": "#48966",
}
CALLGRIND_ENVS = tuple(ENVS.keys())
MIN_RUN_TIME = 3
REPLICATES = {
"longer": 1_000,
"long": 300,
"short": 50,
}
CALLGRIND_NUMBER = {
"overnight": 500_000,
"long": 250_000,
"short": 10_000,
}
CALLGRIND_TIMEOUT = {
"overnight": 800,
"long": 400,
"short": 100,
}
SETUP = """
x = torch.ones((1, 1))
y = torch.ones((1, 1))
w_tensor = torch.ones((1, 1), requires_grad=True)
linear = torch.nn.Linear(1, 1, bias=False)
linear_w = linear.weight
"""
TASKS = {
"C++: unary `.t()`": "w_tensor.t()",
"C++: unary (Parameter) `.t()`": "linear_w.t()",
"C++: binary (Parameter) `mul` ": "x + linear_w",
"tensor.py: _wrap_type_error_to_not_implemented `__floordiv__`": "x // y",
"tensor.py: method `__hash__`": "hash(x)",
"Python scalar `__rsub__`": "1 - x",
"functional.py: (unary) `unique`": "torch.functional.unique(x)",
"functional.py: (args) `atleast_1d`": "torch.functional.atleast_1d((x, y))",
"nn/functional.py: (unary) `relu`": "torch.nn.functional.relu(x)",
"nn/functional.py: (args) `linear`": "torch.nn.functional.linear(x, w_tensor)",
"nn/functional.py: (args) `linear (Parameter)`": "torch.nn.functional.linear(x, linear_w)",
"Linear(..., bias=False)": "linear(x)",
}
def _worker_main(argv, fn):
parser = argparse.ArgumentParser()
parser.add_argument("--output_file", type=str)
parser.add_argument("--single_task", type=int, default=None)
parser.add_argument("--length", type=str)
args = parser.parse_args(argv)
single_task = args.single_task
conda_prefix = os.getenv("CONDA_PREFIX")
assert torch.__file__.startswith(conda_prefix)
env = os.path.split(conda_prefix)[1]
assert env in ENVS
results = []
for i, (k, stmt) in enumerate(TASKS.items()):
if single_task is not None and single_task != i:
continue
timer = Timer(
stmt=stmt,
setup=SETUP,
sub_label=k,
description=ENVS[env],
)
results.append(fn(timer, args.length))
with open(args.output_file, "wb") as f:
pickle.dump(results, f)
def worker_main(argv):
_worker_main(
argv,
lambda timer, _: timer.blocked_autorange(min_run_time=MIN_RUN_TIME)
)
def callgrind_worker_main(argv):
_worker_main(
argv,
lambda timer, length: timer.collect_callgrind(number=CALLGRIND_NUMBER[length], collect_baseline=False))
def main(argv):
parser = argparse.ArgumentParser()
parser.add_argument("--long", action="store_true")
parser.add_argument("--longer", action="store_true")
args = parser.parse_args(argv)
if args.longer:
length = "longer"
elif args.long:
length = "long"
else:
length = "short"
replicates = REPLICATES[length]
num_workers = int(NUM_CORES // 2)
tasks = list(ENVS.keys()) * replicates
random.shuffle(tasks)
task_queue = queue.Queue()
for _ in range(replicates):
envs = list(ENVS.keys())
random.shuffle(envs)
for e in envs:
task_queue.put((e, None))
callgrind_task_queue = queue.Queue()
for e in CALLGRIND_ENVS:
for i, _ in enumerate(TASKS):
callgrind_task_queue.put((e, i))
results = []
callgrind_results = []
def map_fn(worker_id):
# Adjacent cores often share cache and maxing out a machine can distort
# timings so we space them out.
callgrind_cores = f"{worker_id * 2}-{worker_id * 2 + 1}"
time_cores = str(worker_id * 2)
_, output_file = tempfile.mkstemp(suffix=".pkl")
try:
loop_tasks = (
# Callgrind is long running, and then the workers can help with
# timing after they finish collecting counts.
(callgrind_task_queue, callgrind_results, "callgrind_worker", callgrind_cores, CALLGRIND_TIMEOUT[length]),
(task_queue, results, "worker", time_cores, None))
for queue_i, results_i, mode_i, cores, timeout in loop_tasks:
while True:
try:
env, task_i = queue_i.get_nowait()
except queue.Empty:
break
remaining_attempts = 3
while True:
try:
subprocess.run(
" ".join([
"source", "activate", env, "&&",
"taskset", "--cpu-list", cores,
"python", os.path.abspath(__file__),
"--mode", mode_i,
"--length", length,
"--output_file", output_file
] + ([] if task_i is None else ["--single_task", str(task_i)])),
shell=True,
check=True,
timeout=timeout,
)
break
except subprocess.TimeoutExpired:
# Sometimes Valgrind will hang if there are too many
# concurrent runs.
remaining_attempts -= 1
if not remaining_attempts:
print("Too many failed attempts.")
raise
print(f"Timeout after {timeout} sec. Retrying.")
# We don't need a lock, as the GIL is enough.
with open(output_file, "rb") as f:
results_i.extend(pickle.load(f))
finally:
os.remove(output_file)
with multiprocessing.dummy.Pool(num_workers) as pool:
st, st_estimate, eta, n_total = time.time(), None, "", len(tasks) * len(TASKS)
map_job = pool.map_async(map_fn, range(num_workers))
while not map_job.ready():
n_complete = len(results)
if n_complete and len(callgrind_results):
if st_estimate is None:
st_estimate = time.time()
else:
sec_per_element = (time.time() - st_estimate) / n_complete
n_remaining = n_total - n_complete
eta = f"ETA: {n_remaining * sec_per_element:.0f} sec"
print(
f"\r{n_complete} / {n_total} "
f"({len(callgrind_results)} / {len(CALLGRIND_ENVS) * len(TASKS)}) "
f"{eta}".ljust(40), end="")
sys.stdout.flush()
time.sleep(2)
total_time = int(time.time() - st)
print(f"\nTotal time: {int(total_time // 60)} min, {total_time % 60} sec")
desc_to_ind = {k: i for i, k in enumerate(ENVS.values())}
results.sort(key=lambda r: desc_to_ind[r.description])
# TODO: Compare should be richer and more modular.
compare = Compare(results)
compare.trim_significant_figures()
compare.colorize(rowwise=True)
# Manually add master vs. overall relative delta t.
merged_results = {
(r.description, r.sub_label): r
for r in Measurement.merge(results)
}
cmp_lines = str(compare).splitlines(False)
print(cmp_lines[0][:-1] + "-" * 15 + "]")
print(f"{cmp_lines[1]} |{'':>10}\u0394t")
print(cmp_lines[2] + "-" * 15)
for l, t in zip(cmp_lines[3:3 + len(TASKS)], TASKS.keys()):
assert l.strip().startswith(t)
t0 = merged_results[(ENVS["ref"], t)].median
t1 = merged_results[(ENVS["torch_fn_overhead_stack_3"], t)].median
print(f"{l} |{'':>5}{(t1 / t0 - 1) * 100:>6.1f}%")
print("\n".join(cmp_lines[3 + len(TASKS):]))
counts_dict = {
(r.task_spec.description, r.task_spec.sub_label): r.counts(denoise=True)
for r in callgrind_results
}
def rel_diff(x, x0):
return f"{(x / x0 - 1) * 100:>6.1f}%"
task_pad = max(len(t) for t in TASKS)
print(f"\n\nInstruction % change (relative to `{CALLGRIND_ENVS[0]}`)")
print(" " * (task_pad + 8) + (" " * 7).join([ENVS[env] for env in CALLGRIND_ENVS[1:]]))
for t in TASKS:
values = [counts_dict[(ENVS[env], t)] for env in CALLGRIND_ENVS]
print(t.ljust(task_pad + 3) + " ".join([
rel_diff(v, values[0]).rjust(len(ENVS[env]) + 5)
for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]))
print("\033[4m" + " Instructions per invocation".ljust(task_pad + 3) + " ".join([
f"{v // CALLGRIND_NUMBER[length]:.0f}".rjust(len(ENVS[env]) + 5)
for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]) + "\033[0m")
print()
import pdb
pdb.set_trace()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--mode", type=str, choices=("main", "worker", "callgrind_worker"), default="main")
args, remaining = parser.parse_known_args()
if args.mode == "main":
main(remaining)
elif args.mode == "callgrind_worker":
callgrind_worker_main(remaining)
else:
worker_main(remaining)
```
</details>
**Wall time**
<img width="1178" alt="Screen Shot 2020-12-12 at 12 28 13 PM" src="https://user-images.githubusercontent.com/13089297/101994419-284f6a00-3c77-11eb-8dc8-4f69a890302e.png">
<details>
<summary> Longer run (`python test.py --long`) is basically identical. </summary>
<img width="1184" alt="Screen Shot 2020-12-12 at 5 02 47 PM" src="https://user-images.githubusercontent.com/13089297/102000425-2350e180-3c9c-11eb-999e-a95b37e9ef54.png">
</details>
**Callgrind**
<img width="936" alt="Screen Shot 2020-12-12 at 12 28 54 PM" src="https://user-images.githubusercontent.com/13089297/101994421-2e454b00-3c77-11eb-9cd3-8cde550f536e.png">
Test plan: existing unit tests.
Differential Revision: [D25590731](https://our.internmc.facebook.com/intern/diff/D25590731)
[ghstack-poisoned]
…static False when scripting"
This PR lets us skip the `if not torch.jit.is_scripting():` guards on `functional` and `nn.functional` by directly registering `has_torch_function` and `object_has_torch_function` to the JIT as statically False.
**Benchmarks**
The benchmark script is kind of long. The reason is that it's testing all four PRs in the stack, plus threading and subprocessing so that the benchmark can utilize multiple cores while still collecting good numbers. Both wall times and instruction counts were collected. This stack changes dozens of operators / functions, but very mechanically such that there are only a handful of codepath changes. Each row is a slightly different code path (e.g. testing in Python, testing in the arg parser, different input types, etc.)
<details>
<summary> Test script </summary>
```
import argparse
import multiprocessing
import multiprocessing.dummy
import os
import pickle
import queue
import random
import sys
import subprocess
import tempfile
import time
import torch
from torch.utils.benchmark import Timer, Compare, Measurement
NUM_CORES = multiprocessing.cpu_count()
ENVS = {
"ref": "HEAD (current)",
"torch_fn_overhead_stack_0": "#48963",
"torch_fn_overhead_stack_1": "#48964",
"torch_fn_overhead_stack_2": "#48965",
"torch_fn_overhead_stack_3": "#48966",
}
CALLGRIND_ENVS = tuple(ENVS.keys())
MIN_RUN_TIME = 3
REPLICATES = {
"longer": 1_000,
"long": 300,
"short": 50,
}
CALLGRIND_NUMBER = {
"overnight": 500_000,
"long": 250_000,
"short": 10_000,
}
CALLGRIND_TIMEOUT = {
"overnight": 800,
"long": 400,
"short": 100,
}
SETUP = """
x = torch.ones((1, 1))
y = torch.ones((1, 1))
w_tensor = torch.ones((1, 1), requires_grad=True)
linear = torch.nn.Linear(1, 1, bias=False)
linear_w = linear.weight
"""
TASKS = {
"C++: unary `.t()`": "w_tensor.t()",
"C++: unary (Parameter) `.t()`": "linear_w.t()",
"C++: binary (Parameter) `mul` ": "x + linear_w",
"tensor.py: _wrap_type_error_to_not_implemented `__floordiv__`": "x // y",
"tensor.py: method `__hash__`": "hash(x)",
"Python scalar `__rsub__`": "1 - x",
"functional.py: (unary) `unique`": "torch.functional.unique(x)",
"functional.py: (args) `atleast_1d`": "torch.functional.atleast_1d((x, y))",
"nn/functional.py: (unary) `relu`": "torch.nn.functional.relu(x)",
"nn/functional.py: (args) `linear`": "torch.nn.functional.linear(x, w_tensor)",
"nn/functional.py: (args) `linear (Parameter)`": "torch.nn.functional.linear(x, linear_w)",
"Linear(..., bias=False)": "linear(x)",
}
def _worker_main(argv, fn):
parser = argparse.ArgumentParser()
parser.add_argument("--output_file", type=str)
parser.add_argument("--single_task", type=int, default=None)
parser.add_argument("--length", type=str)
args = parser.parse_args(argv)
single_task = args.single_task
conda_prefix = os.getenv("CONDA_PREFIX")
assert torch.__file__.startswith(conda_prefix)
env = os.path.split(conda_prefix)[1]
assert env in ENVS
results = []
for i, (k, stmt) in enumerate(TASKS.items()):
if single_task is not None and single_task != i:
continue
timer = Timer(
stmt=stmt,
setup=SETUP,
sub_label=k,
description=ENVS[env],
)
results.append(fn(timer, args.length))
with open(args.output_file, "wb") as f:
pickle.dump(results, f)
def worker_main(argv):
_worker_main(
argv,
lambda timer, _: timer.blocked_autorange(min_run_time=MIN_RUN_TIME)
)
def callgrind_worker_main(argv):
_worker_main(
argv,
lambda timer, length: timer.collect_callgrind(number=CALLGRIND_NUMBER[length], collect_baseline=False))
def main(argv):
parser = argparse.ArgumentParser()
parser.add_argument("--long", action="store_true")
parser.add_argument("--longer", action="store_true")
args = parser.parse_args(argv)
if args.longer:
length = "longer"
elif args.long:
length = "long"
else:
length = "short"
replicates = REPLICATES[length]
num_workers = int(NUM_CORES // 2)
tasks = list(ENVS.keys()) * replicates
random.shuffle(tasks)
task_queue = queue.Queue()
for _ in range(replicates):
envs = list(ENVS.keys())
random.shuffle(envs)
for e in envs:
task_queue.put((e, None))
callgrind_task_queue = queue.Queue()
for e in CALLGRIND_ENVS:
for i, _ in enumerate(TASKS):
callgrind_task_queue.put((e, i))
results = []
callgrind_results = []
def map_fn(worker_id):
# Adjacent cores often share cache and maxing out a machine can distort
# timings so we space them out.
callgrind_cores = f"{worker_id * 2}-{worker_id * 2 + 1}"
time_cores = str(worker_id * 2)
_, output_file = tempfile.mkstemp(suffix=".pkl")
try:
loop_tasks = (
# Callgrind is long running, and then the workers can help with
# timing after they finish collecting counts.
(callgrind_task_queue, callgrind_results, "callgrind_worker", callgrind_cores, CALLGRIND_TIMEOUT[length]),
(task_queue, results, "worker", time_cores, None))
for queue_i, results_i, mode_i, cores, timeout in loop_tasks:
while True:
try:
env, task_i = queue_i.get_nowait()
except queue.Empty:
break
remaining_attempts = 3
while True:
try:
subprocess.run(
" ".join([
"source", "activate", env, "&&",
"taskset", "--cpu-list", cores,
"python", os.path.abspath(__file__),
"--mode", mode_i,
"--length", length,
"--output_file", output_file
] + ([] if task_i is None else ["--single_task", str(task_i)])),
shell=True,
check=True,
timeout=timeout,
)
break
except subprocess.TimeoutExpired:
# Sometimes Valgrind will hang if there are too many
# concurrent runs.
remaining_attempts -= 1
if not remaining_attempts:
print("Too many failed attempts.")
raise
print(f"Timeout after {timeout} sec. Retrying.")
# We don't need a lock, as the GIL is enough.
with open(output_file, "rb") as f:
results_i.extend(pickle.load(f))
finally:
os.remove(output_file)
with multiprocessing.dummy.Pool(num_workers) as pool:
st, st_estimate, eta, n_total = time.time(), None, "", len(tasks) * len(TASKS)
map_job = pool.map_async(map_fn, range(num_workers))
while not map_job.ready():
n_complete = len(results)
if n_complete and len(callgrind_results):
if st_estimate is None:
st_estimate = time.time()
else:
sec_per_element = (time.time() - st_estimate) / n_complete
n_remaining = n_total - n_complete
eta = f"ETA: {n_remaining * sec_per_element:.0f} sec"
print(
f"\r{n_complete} / {n_total} "
f"({len(callgrind_results)} / {len(CALLGRIND_ENVS) * len(TASKS)}) "
f"{eta}".ljust(40), end="")
sys.stdout.flush()
time.sleep(2)
total_time = int(time.time() - st)
print(f"\nTotal time: {int(total_time // 60)} min, {total_time % 60} sec")
desc_to_ind = {k: i for i, k in enumerate(ENVS.values())}
results.sort(key=lambda r: desc_to_ind[r.description])
# TODO: Compare should be richer and more modular.
compare = Compare(results)
compare.trim_significant_figures()
compare.colorize(rowwise=True)
# Manually add master vs. overall relative delta t.
merged_results = {
(r.description, r.sub_label): r
for r in Measurement.merge(results)
}
cmp_lines = str(compare).splitlines(False)
print(cmp_lines[0][:-1] + "-" * 15 + "]")
print(f"{cmp_lines[1]} |{'':>10}\u0394t")
print(cmp_lines[2] + "-" * 15)
for l, t in zip(cmp_lines[3:3 + len(TASKS)], TASKS.keys()):
assert l.strip().startswith(t)
t0 = merged_results[(ENVS["ref"], t)].median
t1 = merged_results[(ENVS["torch_fn_overhead_stack_3"], t)].median
print(f"{l} |{'':>5}{(t1 / t0 - 1) * 100:>6.1f}%")
print("\n".join(cmp_lines[3 + len(TASKS):]))
counts_dict = {
(r.task_spec.description, r.task_spec.sub_label): r.counts(denoise=True)
for r in callgrind_results
}
def rel_diff(x, x0):
return f"{(x / x0 - 1) * 100:>6.1f}%"
task_pad = max(len(t) for t in TASKS)
print(f"\n\nInstruction % change (relative to `{CALLGRIND_ENVS[0]}`)")
print(" " * (task_pad + 8) + (" " * 7).join([ENVS[env] for env in CALLGRIND_ENVS[1:]]))
for t in TASKS:
values = [counts_dict[(ENVS[env], t)] for env in CALLGRIND_ENVS]
print(t.ljust(task_pad + 3) + " ".join([
rel_diff(v, values[0]).rjust(len(ENVS[env]) + 5)
for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]))
print("\033[4m" + " Instructions per invocation".ljust(task_pad + 3) + " ".join([
f"{v // CALLGRIND_NUMBER[length]:.0f}".rjust(len(ENVS[env]) + 5)
for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]) + "\033[0m")
print()
import pdb
pdb.set_trace()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--mode", type=str, choices=("main", "worker", "callgrind_worker"), default="main")
args, remaining = parser.parse_known_args()
if args.mode == "main":
main(remaining)
elif args.mode == "callgrind_worker":
callgrind_worker_main(remaining)
else:
worker_main(remaining)
```
</details>
**Wall time**
<img width="1178" alt="Screen Shot 2020-12-12 at 12 28 13 PM" src="https://user-images.githubusercontent.com/13089297/101994419-284f6a00-3c77-11eb-8dc8-4f69a890302e.png">
<details>
<summary> Longer run (`python test.py --long`) is basically identical. </summary>
<img width="1184" alt="Screen Shot 2020-12-12 at 5 02 47 PM" src="https://user-images.githubusercontent.com/13089297/102000425-2350e180-3c9c-11eb-999e-a95b37e9ef54.png">
</details>
**Callgrind**
<img width="936" alt="Screen Shot 2020-12-12 at 12 28 54 PM" src="https://user-images.githubusercontent.com/13089297/101994421-2e454b00-3c77-11eb-9cd3-8cde550f536e.png">
Test plan: existing unit tests.
Differential Revision: [D25590731](https://our.internmc.facebook.com/intern/diff/D25590731)
[ghstack-poisoned]
Codecov Report
@@ Coverage Diff @@
## gh/robieta/9/base #48965 +/- ##
=====================================================
- Coverage 80.71% 80.70% -0.01%
=====================================================
Files 1904 1904
Lines 206676 206637 -39
=====================================================
- Hits 166819 166770 -49
- Misses 39857 39867 +10 |
…rch_function ghstack-source-id: a56c0bb791549614dba3130e1b323e3350b145e1 Pull Request resolved: #48965
…e when scripting (#48966) Summary: Pull Request resolved: #48966 This PR lets us skip the `if not torch.jit.is_scripting():` guards on `functional` and `nn.functional` by directly registering `has_torch_function` and `object_has_torch_function` to the JIT as statically False. **Benchmarks** The benchmark script is kind of long. The reason is that it's testing all four PRs in the stack, plus threading and subprocessing so that the benchmark can utilize multiple cores while still collecting good numbers. Both wall times and instruction counts were collected. This stack changes dozens of operators / functions, but very mechanically such that there are only a handful of codepath changes. Each row is a slightly different code path (e.g. testing in Python, testing in the arg parser, different input types, etc.) <details> <summary> Test script </summary> ``` import argparse import multiprocessing import multiprocessing.dummy import os import pickle import queue import random import sys import subprocess import tempfile import time import torch from torch.utils.benchmark import Timer, Compare, Measurement NUM_CORES = multiprocessing.cpu_count() ENVS = { "ref": "HEAD (current)", "torch_fn_overhead_stack_0": "#48963", "torch_fn_overhead_stack_1": "#48964", "torch_fn_overhead_stack_2": "#48965", "torch_fn_overhead_stack_3": "#48966", } CALLGRIND_ENVS = tuple(ENVS.keys()) MIN_RUN_TIME = 3 REPLICATES = { "longer": 1_000, "long": 300, "short": 50, } CALLGRIND_NUMBER = { "overnight": 500_000, "long": 250_000, "short": 10_000, } CALLGRIND_TIMEOUT = { "overnight": 800, "long": 400, "short": 100, } SETUP = """ x = torch.ones((1, 1)) y = torch.ones((1, 1)) w_tensor = torch.ones((1, 1), requires_grad=True) linear = torch.nn.Linear(1, 1, bias=False) linear_w = linear.weight """ TASKS = { "C++: unary `.t()`": "w_tensor.t()", "C++: unary (Parameter) `.t()`": "linear_w.t()", "C++: binary (Parameter) `mul` ": "x + linear_w", "tensor.py: _wrap_type_error_to_not_implemented `__floordiv__`": "x // y", "tensor.py: method `__hash__`": "hash(x)", "Python scalar `__rsub__`": "1 - x", "functional.py: (unary) `unique`": "torch.functional.unique(x)", "functional.py: (args) `atleast_1d`": "torch.functional.atleast_1d((x, y))", "nn/functional.py: (unary) `relu`": "torch.nn.functional.relu(x)", "nn/functional.py: (args) `linear`": "torch.nn.functional.linear(x, w_tensor)", "nn/functional.py: (args) `linear (Parameter)`": "torch.nn.functional.linear(x, linear_w)", "Linear(..., bias=False)": "linear(x)", } def _worker_main(argv, fn): parser = argparse.ArgumentParser() parser.add_argument("--output_file", type=str) parser.add_argument("--single_task", type=int, default=None) parser.add_argument("--length", type=str) args = parser.parse_args(argv) single_task = args.single_task conda_prefix = os.getenv("CONDA_PREFIX") assert torch.__file__.startswith(conda_prefix) env = os.path.split(conda_prefix)[1] assert env in ENVS results = [] for i, (k, stmt) in enumerate(TASKS.items()): if single_task is not None and single_task != i: continue timer = Timer( stmt=stmt, setup=SETUP, sub_label=k, description=ENVS[env], ) results.append(fn(timer, args.length)) with open(args.output_file, "wb") as f: pickle.dump(results, f) def worker_main(argv): _worker_main( argv, lambda timer, _: timer.blocked_autorange(min_run_time=MIN_RUN_TIME) ) def callgrind_worker_main(argv): _worker_main( argv, lambda timer, length: timer.collect_callgrind(number=CALLGRIND_NUMBER[length], collect_baseline=False)) def main(argv): parser = argparse.ArgumentParser() parser.add_argument("--long", action="store_true") parser.add_argument("--longer", action="store_true") args = parser.parse_args(argv) if args.longer: length = "longer" elif args.long: length = "long" else: length = "short" replicates = REPLICATES[length] num_workers = int(NUM_CORES // 2) tasks = list(ENVS.keys()) * replicates random.shuffle(tasks) task_queue = queue.Queue() for _ in range(replicates): envs = list(ENVS.keys()) random.shuffle(envs) for e in envs: task_queue.put((e, None)) callgrind_task_queue = queue.Queue() for e in CALLGRIND_ENVS: for i, _ in enumerate(TASKS): callgrind_task_queue.put((e, i)) results = [] callgrind_results = [] def map_fn(worker_id): # Adjacent cores often share cache and maxing out a machine can distort # timings so we space them out. callgrind_cores = f"{worker_id * 2}-{worker_id * 2 + 1}" time_cores = str(worker_id * 2) _, output_file = tempfile.mkstemp(suffix=".pkl") try: loop_tasks = ( # Callgrind is long running, and then the workers can help with # timing after they finish collecting counts. (callgrind_task_queue, callgrind_results, "callgrind_worker", callgrind_cores, CALLGRIND_TIMEOUT[length]), (task_queue, results, "worker", time_cores, None)) for queue_i, results_i, mode_i, cores, timeout in loop_tasks: while True: try: env, task_i = queue_i.get_nowait() except queue.Empty: break remaining_attempts = 3 while True: try: subprocess.run( " ".join([ "source", "activate", env, "&&", "taskset", "--cpu-list", cores, "python", os.path.abspath(__file__), "--mode", mode_i, "--length", length, "--output_file", output_file ] + ([] if task_i is None else ["--single_task", str(task_i)])), shell=True, check=True, timeout=timeout, ) break except subprocess.TimeoutExpired: # Sometimes Valgrind will hang if there are too many # concurrent runs. remaining_attempts -= 1 if not remaining_attempts: print("Too many failed attempts.") raise print(f"Timeout after {timeout} sec. Retrying.") # We don't need a lock, as the GIL is enough. with open(output_file, "rb") as f: results_i.extend(pickle.load(f)) finally: os.remove(output_file) with multiprocessing.dummy.Pool(num_workers) as pool: st, st_estimate, eta, n_total = time.time(), None, "", len(tasks) * len(TASKS) map_job = pool.map_async(map_fn, range(num_workers)) while not map_job.ready(): n_complete = len(results) if n_complete and len(callgrind_results): if st_estimate is None: st_estimate = time.time() else: sec_per_element = (time.time() - st_estimate) / n_complete n_remaining = n_total - n_complete eta = f"ETA: {n_remaining * sec_per_element:.0f} sec" print( f"\r{n_complete} / {n_total} " f"({len(callgrind_results)} / {len(CALLGRIND_ENVS) * len(TASKS)}) " f"{eta}".ljust(40), end="") sys.stdout.flush() time.sleep(2) total_time = int(time.time() - st) print(f"\nTotal time: {int(total_time // 60)} min, {total_time % 60} sec") desc_to_ind = {k: i for i, k in enumerate(ENVS.values())} results.sort(key=lambda r: desc_to_ind[r.description]) # TODO: Compare should be richer and more modular. compare = Compare(results) compare.trim_significant_figures() compare.colorize(rowwise=True) # Manually add master vs. overall relative delta t. merged_results = { (r.description, r.sub_label): r for r in Measurement.merge(results) } cmp_lines = str(compare).splitlines(False) print(cmp_lines[0][:-1] + "-" * 15 + "]") print(f"{cmp_lines[1]} |{'':>10}\u0394t") print(cmp_lines[2] + "-" * 15) for l, t in zip(cmp_lines[3:3 + len(TASKS)], TASKS.keys()): assert l.strip().startswith(t) t0 = merged_results[(ENVS["ref"], t)].median t1 = merged_results[(ENVS["torch_fn_overhead_stack_3"], t)].median print(f"{l} |{'':>5}{(t1 / t0 - 1) * 100:>6.1f}%") print("\n".join(cmp_lines[3 + len(TASKS):])) counts_dict = { (r.task_spec.description, r.task_spec.sub_label): r.counts(denoise=True) for r in callgrind_results } def rel_diff(x, x0): return f"{(x / x0 - 1) * 100:>6.1f}%" task_pad = max(len(t) for t in TASKS) print(f"\n\nInstruction % change (relative to `{CALLGRIND_ENVS[0]}`)") print(" " * (task_pad + 8) + (" " * 7).join([ENVS[env] for env in CALLGRIND_ENVS[1:]])) for t in TASKS: values = [counts_dict[(ENVS[env], t)] for env in CALLGRIND_ENVS] print(t.ljust(task_pad + 3) + " ".join([ rel_diff(v, values[0]).rjust(len(ENVS[env]) + 5) for v, env in zip(values[1:], CALLGRIND_ENVS[1:])])) print("\033[4m" + " Instructions per invocation".ljust(task_pad + 3) + " ".join([ f"{v // CALLGRIND_NUMBER[length]:.0f}".rjust(len(ENVS[env]) + 5) for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]) + "\033[0m") print() import pdb pdb.set_trace() if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("--mode", type=str, choices=("main", "worker", "callgrind_worker"), default="main") args, remaining = parser.parse_known_args() if args.mode == "main": main(remaining) elif args.mode == "callgrind_worker": callgrind_worker_main(remaining) else: worker_main(remaining) ``` </details> **Wall time** <img width="1178" alt="Screen Shot 2020-12-12 at 12 28 13 PM" src="https://user-images.githubusercontent.com/13089297/101994419-284f6a00-3c77-11eb-8dc8-4f69a890302e.png"> <details> <summary> Longer run (`python test.py --long`) is basically identical. </summary> <img width="1184" alt="Screen Shot 2020-12-12 at 5 02 47 PM" src="https://user-images.githubusercontent.com/13089297/102000425-2350e180-3c9c-11eb-999e-a95b37e9ef54.png"> </details> **Callgrind** <img width="936" alt="Screen Shot 2020-12-12 at 12 28 54 PM" src="https://user-images.githubusercontent.com/13089297/101994421-2e454b00-3c77-11eb-9cd3-8cde550f536e.png"> Test Plan: existing unit tests. Reviewed By: ezyang Differential Revision: D25590731 Pulled By: robieta fbshipit-source-id: fe05305ff22b0e34ced44b60f2e9f07907a099dd
Stack from ghstack:
This PR pulls
__torch_function__checking entirely into C++, and adds a specialobject_has_torch_functionmethod for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout forTensor(e.g.if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)) because they're actually slower than checking with the Python C API.Test plan: Existing unit tests. Benchmarks are in #48966
Differential Revision: D25590732