[inductor] generate triton kernel benchmark #95506
Conversation
🔗 Helpful Links🧪 See artifacts and rendered test results at hud.pytorch.org/pr/95506
Note: Links to docs will display an error until the docs builds have been completed. ❌ 1 FailuresAs of commit a101f4e: BROKEN TRUNK - The following jobs failed but were present on the merge base f1dbfe2:
This comment was automatically generated by Dr. CI and updates every 15 minutes. |
|
Change plans. |
fab5375
to
abfff3a
Compare
torch/_inductor/codegen/triton.py
Outdated
| buf = V.graph.get_buffer(arg_name) | ||
| if buf: | ||
| result.writeline( | ||
| f"{arg_name} = rand_strided({tuple(buf.get_size())}, {tuple(buf.get_stride())}, device='{buf.get_device()}', dtype={buf.get_dtype()})" |
There was a problem hiding this comment.
this won't be exactly right for aliased inputs/outputs, but I don't think it has material impact on perf
torch/_inductor/codegen/triton.py
Outdated
| # print_performance assert non-None return value, but a triton kernel | ||
| # indeed returns None. Override the return value to True to handle this. | ||
| result.writeline( | ||
| f"print_performance(lambda: triton_.run({call_args}, grid=grid({', '.join(grid)}), stream={stream_name}) or True)" |
There was a problem hiding this comment.
@Chillee I'm not sure we want print_performance here, should TORCHINDUCTOR_PROFILE be enough?
There was a problem hiding this comment.
AFAICT, TORCHINDUCTOR_PROFILE collects latency and bandwidth information for each triton kernel being called. With that, we can find good candidates (with poor perf) to dive into.
For the kernel benchmark in this PR, I can let the benchmark print latency and bandwidth information as well. This way, we can easily tune configs manually and see the impact on the latency/bandwidth of the kernel.
There was a problem hiding this comment.
imo we should ideally be able to have some flexibility in how we call the kernel and with how many arguments.
For example, ideally, the code would look something like
def call(args):
arg0_1, = args
args.clear()
with torch.cuda._DeviceGuard(0):
torch.cuda.set_device(0) # no-op to ensure context
buf0 = empty_strided((2, 3), (3, 1), device='cuda', dtype=torch.float32)
stream0 = get_cuda_stream(0)
triton__0.run(arg0_1, buf0, 6, grid=grid(6), stream=stream0)
del arg0_1
return (buf0, )
def get_args():
arg0_1 = rand_strided((2, 3), (3, 1), device='cuda:0', dtype=torch.float32)
return (arg0_1,)
if __name__ == "__main__":
from torch._dynamo.testing import rand_strided
from torch._inductor.utils import print_performance
args = get_args()
print_performance(lambda: call(list(args)))
And then future work would be able to do something like
for kernel in kernel_dataset:
# do something with kernel
Concretely, in this PR, would be nice to refactor the arg generation a little bit into its own function.
There was a problem hiding this comment.
So given a kernel, its argument list is already fixed. Currently the generated benchmark code looks like:
if __name__ == "__main__":
from torch._C import _cuda_getCurrentRawStream as get_cuda_stream
from torch._dynamo.testing import rand_strided
from torch._inductor.utils import print_performance
import torch
from torch._inductor.triton_ops.autotune import grid
arg0_1 = rand_strided((2, 3), (3, 1), device='cuda:0', dtype=torch.float32)
buf0 = rand_strided((2, 3), (3, 1), device='cuda:0', dtype=torch.float32)
stream0 = get_cuda_stream(0)
print_performance(lambda: triton_.run(arg0_1, buf0, 6, grid=grid(6), stream=stream0) or True)
I can add the missing DeviceGuard. One more difference I see in your example is, you treat arg0_1 as kernel input and buf0 as kernel output (although it's address is passed in as kernel argument). But in my example, they are alls randomly generated arguments. I think your way is better. The question I have is, do we have a good way to figure out which kernel arguments is actually for output?
There was a problem hiding this comment.
@shunting314 I'm saying that I think the main thing that's missing from this PR is the ability to pull out the kernel from the dumped file and have control over how often I'm calling it.
Like, if you import the kernel file, you'll have access to a call function, but we don't have a way of calling that function since we don't have programmatic access to the arguments. Our only way of calling the function is to call __main__.
There was a problem hiding this comment.
ah got it. I'll organized code into
- call function
- get_args function
- use the above 2 functions in
__main__
torch/_inductor/graph.py
Outdated
| @@ -590,8 +597,8 @@ def compile_to_module(self): | |||
| for name, value in self.constants.items(): | |||
| setattr(mod, name, value) | |||
|
|
|||
| if dynamo_config.output_code: | |||
| log.info("Output code: %s", mod.__file__) | |||
| if config.output_compiled_module_path: | |||
There was a problem hiding this comment.
I'm also a little bit uncertain about what's changing here and why we need 2 environmental variables for this?
There was a problem hiding this comment.
So if we enable output_code config other things like
- guards
- fx graph
are also printed.
Added another environment variable so when enabling it, we just specifically print the compiled module path.
There was a problem hiding this comment.
I guess it seems weird to me to add 2 new env variables for one piece of new functionality. In particular, this change seems weird since we're just changing some logging info for the pre-existing config option.
There was a problem hiding this comment.
I see. Would it be better if I only add config.benchmark_kernel . Print the compiled module path if that config is true?
BTW, the reason I change log.info to print is because enable info log just cause too much other stuff being being printed. So I print directly to stderr.
abfff3a
to
530c8ca
Compare
|
Some test on vgg16 shows this PR does not handle random seed input properly. I'll need debug more. Otherwise it's ready for reviewing again. Re Horace's another comment about doing sth like I think we can add an option to the
I can add that in a followup PR if people don't mind :) |
torch/_inductor/codegen/triton.py
Outdated
| result.writeline("") | ||
|
|
||
| result.writeline( | ||
| "ms = do_bench(lambda: call(get_args()), rep=40, fast_flush=True)[0]" |
There was a problem hiding this comment.
I think you should move the get_args() out of the lambda. As it is, you'll benchmark the argument construction code every iteration as well.
There was a problem hiding this comment.
Good catch, will do!
530c8ca
to
9b8058b
Compare
|
The random seed issue mentioned above is fixed in latest revision of this PR. The reason is random seed is treated as constant tensor rather than buffer in GraphLowering class. Have to handle that separately when generating kernel benchmarks. |
9b8058b
to
98541fa
Compare
98541fa
to
a101f4e
Compare
|
@pytorchbot merge -f "the test failure is unrelated and is caused by timeout for a single model" |
Merge startedYour change will be merged immediately since you used the force (-f) flag, bypassing any CI checks (ETA: 1-5 minutes). Learn more about merging in the wiki. Questions? Feedback? Please reach out to the PyTorch DevX Team |
A PR to generate benchmark code for individual triton kernels. We can explore improving autotuning with the saved compiled kernel directly. This potentially can speedup our iteration and separate the concern with the upstream components that generate the compiled module. Since I'm still ramping up on inductor, I'll reflect what I learned here so people can correct me if I'm wrong. In inductor, WrapperCodeGen class is used to generate the compiled module for CUDA (or triton). Here is an example compiled module for a toy model like: `def f(x): return sin(x) + cos(x)` https://gist.github.com/shunting314/c6ed9f571919e3b414166f1696dcc61b . A compiled module contains the following part: - various triton kernels - a wrapper (or a method named call . The name is hardcoded) that calls the triton kernels and potentially ATen kernels to efficiently do the same work as the original Fx graph being compiled by inductor - some utility code that generate random inputs and run the wrapper The triton kernels in the compiled module are annotated with decorator like pointwise which is used for autotuning. This PR add a config so enabling it will just trigger the path of the compiled module being printed. It can be controlled from environment variable as well. The path to each compiled triton kernel is added as comment in the compiled module. E.g. ``` # kernel path: /tmp/torchinductor_shunting/gn/cgn6x3mqoltu7q77gjnu2elwfupinsvcovqwibc6fhsoiy34tvga.py triton__0 = async_compile.triton(''' import triton import triton.language as tl ... """) ```` Example command: ``` TORCHINDUCTOR_OUTPUT_COMPILED_MODULE_PATH=1 TORCHINDUCTOR_BENCHMARK_KERNEL=1 python benchmarks/dynamo/huggingface.py --backend inductor --amp --performance --training --dashboard --only AlbertForMaskedLM --disable-cudagraphs ``` Pull Request resolved: pytorch/pytorch#95506 Approved by: https://github.com/Chillee
A PR to generate benchmark code for individual triton kernels. We can explore improving autotuning with the saved compiled kernel directly. This potentially can speedup our iteration and separate the concern with the upstream components that generate the compiled module. Since I'm still ramping up on inductor, I'll reflect what I learned here so people can correct me if I'm wrong. In inductor, WrapperCodeGen class is used to generate the compiled module for CUDA (or triton). Here is an example compiled module for a toy model like: `def f(x): return sin(x) + cos(x)` https://gist.github.com/shunting314/c6ed9f571919e3b414166f1696dcc61b . A compiled module contains the following part: - various triton kernels - a wrapper (or a method named call . The name is hardcoded) that calls the triton kernels and potentially ATen kernels to efficiently do the same work as the original Fx graph being compiled by inductor - some utility code that generate random inputs and run the wrapper The triton kernels in the compiled module are annotated with decorator like pointwise which is used for autotuning. This PR add a config so enabling it will just trigger the path of the compiled module being printed. It can be controlled from environment variable as well. The path to each compiled triton kernel is added as comment in the compiled module. E.g. ``` # kernel path: /tmp/torchinductor_shunting/gn/cgn6x3mqoltu7q77gjnu2elwfupinsvcovqwibc6fhsoiy34tvga.py triton__0 = async_compile.triton(''' import triton import triton.language as tl ... """) ```` Example command: ``` TORCHINDUCTOR_OUTPUT_COMPILED_MODULE_PATH=1 TORCHINDUCTOR_BENCHMARK_KERNEL=1 python benchmarks/dynamo/huggingface.py --backend inductor --amp --performance --training --dashboard --only AlbertForMaskedLM --disable-cudagraphs ``` Pull Request resolved: pytorch/pytorch#95506 Approved by: https://github.com/Chillee
A PR to generate benchmark code for individual triton kernels. We can explore improving autotuning with the saved compiled kernel directly. This potentially can speedup our iteration and separate the concern with the upstream components that generate the compiled module. Since I'm still ramping up on inductor, I'll reflect what I learned here so people can correct me if I'm wrong. In inductor, WrapperCodeGen class is used to generate the compiled module for CUDA (or triton). Here is an example compiled module for a toy model like: `def f(x): return sin(x) + cos(x)` https://gist.github.com/shunting314/c6ed9f571919e3b414166f1696dcc61b . A compiled module contains the following part: - various triton kernels - a wrapper (or a method named call . The name is hardcoded) that calls the triton kernels and potentially ATen kernels to efficiently do the same work as the original Fx graph being compiled by inductor - some utility code that generate random inputs and run the wrapper The triton kernels in the compiled module are annotated with decorator like pointwise which is used for autotuning. This PR add a config so enabling it will just trigger the path of the compiled module being printed. It can be controlled from environment variable as well. The path to each compiled triton kernel is added as comment in the compiled module. E.g. ``` # kernel path: /tmp/torchinductor_shunting/gn/cgn6x3mqoltu7q77gjnu2elwfupinsvcovqwibc6fhsoiy34tvga.py triton__0 = async_compile.triton(''' import triton import triton.language as tl ... """) ```` Example command: ``` TORCHINDUCTOR_OUTPUT_COMPILED_MODULE_PATH=1 TORCHINDUCTOR_BENCHMARK_KERNEL=1 python benchmarks/dynamo/huggingface.py --backend inductor --amp --performance --training --dashboard --only AlbertForMaskedLM --disable-cudagraphs ``` Pull Request resolved: pytorch/pytorch#95506 Approved by: https://github.com/Chillee
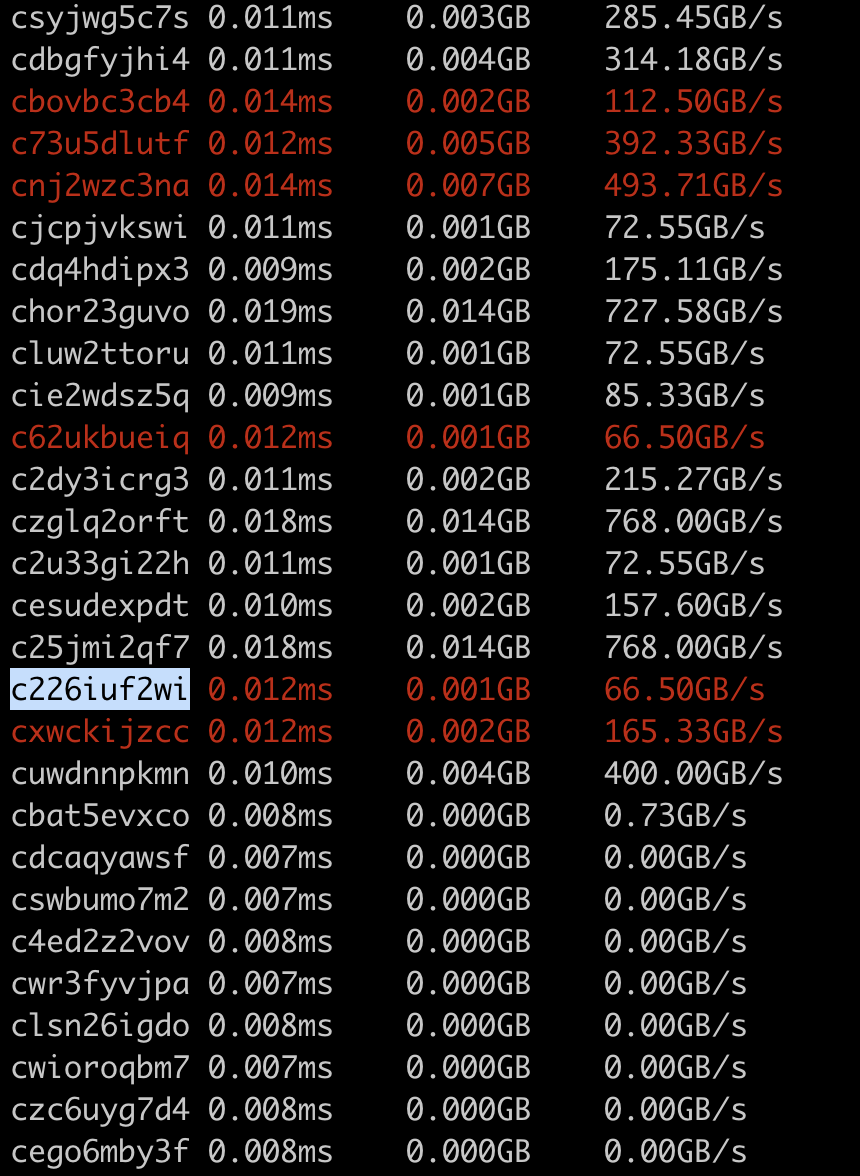
#95845) This is a follow up for PR #95506 to run all the triton kernels in a compiled module individually as suggested by Horace. Here are the steps: 1. Run the model as usual with a benchmark script and with TORCHINDUCTOR_BENCHMARK_KERNEL enabled. e.g. ``` TORCHINDUCTOR_BENCHMARK_KERNEL=1 python benchmarks/dynamo/torchbench.py --backend inductor --amp --performance --dashboard --only resnet18 --disable-cudagraphs --training ``` 2. From the output we will see 3 lines like ``` Compiled module path: /tmp/torchinductor_shunting/rs/crsuc6zrt3y6lktz33jjqgpkuahya56xj6sentyiz7iv4pjud43j.py ``` That's because we have one graph module for fwd/bwd/optitimizer respectively. Each graph module will have one such output corresponding to the compiled module. 3. We can run the compiled module directly. Without any extra arguments, we just maintain the previous behavior to run the call function -- which just does what the original graph module does but in a more efficient way. But if we add the '-k' argument, we will run benchmark for each individual kernels in the file. ``` python /tmp/torchinductor_shunting/rs/crsuc6zrt3y6lktz33jjqgpkuahya56xj6sentyiz7iv4pjud43j.py -k ``` Example output: <img width="430" alt="Screenshot 2023-03-01 at 4 51 06 PM" src="https://user-images.githubusercontent.com/52589240/222302996-814a85be-472b-463c-9e85-39d2c9d20e1a.png"> Note: I use the first 10 characters of the hash to identify each kernel since 1. hash is easier to get in the code :) 2. name like `triton__3` only makes sense within a compiled module, but a hash can make sense even without specifying the compiled module (assuming we have enough bytes for the hash) If we found a triton kernel with hash like c226iuf2wi having poor performance, we can look it up in the original compiled module file. It works since we comment each compiled triton kernel with the full hash. Pull Request resolved: #95845 Approved by: https://github.com/Chillee
{kind=link}
pytorch#95845) This is a follow up for PR pytorch#95506 to run all the triton kernels in a compiled module individually as suggested by Horace. Here are the steps: 1. Run the model as usual with a benchmark script and with TORCHINDUCTOR_BENCHMARK_KERNEL enabled. e.g. ``` TORCHINDUCTOR_BENCHMARK_KERNEL=1 python benchmarks/dynamo/torchbench.py --backend inductor --amp --performance --dashboard --only resnet18 --disable-cudagraphs --training ``` 2. From the output we will see 3 lines like ``` Compiled module path: /tmp/torchinductor_shunting/rs/crsuc6zrt3y6lktz33jjqgpkuahya56xj6sentyiz7iv4pjud43j.py ``` That's because we have one graph module for fwd/bwd/optitimizer respectively. Each graph module will have one such output corresponding to the compiled module. 3. We can run the compiled module directly. Without any extra arguments, we just maintain the previous behavior to run the call function -- which just does what the original graph module does but in a more efficient way. But if we add the '-k' argument, we will run benchmark for each individual kernels in the file. ``` python /tmp/torchinductor_shunting/rs/crsuc6zrt3y6lktz33jjqgpkuahya56xj6sentyiz7iv4pjud43j.py -k ``` Example output: <img width="430" alt="Screenshot 2023-03-01 at 4 51 06 PM" src="https://user-images.githubusercontent.com/52589240/222302996-814a85be-472b-463c-9e85-39d2c9d20e1a.png"> Note: I use the first 10 characters of the hash to identify each kernel since 1. hash is easier to get in the code :) 2. name like `triton__3` only makes sense within a compiled module, but a hash can make sense even without specifying the compiled module (assuming we have enough bytes for the hash) If we found a triton kernel with hash like c226iuf2wi having poor performance, we can look it up in the original compiled module file. It works since we comment each compiled triton kernel with the full hash. Pull Request resolved: pytorch#95845 Approved by: https://github.com/Chillee
pytorch#95845) This is a follow up for PR pytorch#95506 to run all the triton kernels in a compiled module individually as suggested by Horace. Here are the steps: 1. Run the model as usual with a benchmark script and with TORCHINDUCTOR_BENCHMARK_KERNEL enabled. e.g. ``` TORCHINDUCTOR_BENCHMARK_KERNEL=1 python benchmarks/dynamo/torchbench.py --backend inductor --amp --performance --dashboard --only resnet18 --disable-cudagraphs --training ``` 2. From the output we will see 3 lines like ``` Compiled module path: /tmp/torchinductor_shunting/rs/crsuc6zrt3y6lktz33jjqgpkuahya56xj6sentyiz7iv4pjud43j.py ``` That's because we have one graph module for fwd/bwd/optitimizer respectively. Each graph module will have one such output corresponding to the compiled module. 3. We can run the compiled module directly. Without any extra arguments, we just maintain the previous behavior to run the call function -- which just does what the original graph module does but in a more efficient way. But if we add the '-k' argument, we will run benchmark for each individual kernels in the file. ``` python /tmp/torchinductor_shunting/rs/crsuc6zrt3y6lktz33jjqgpkuahya56xj6sentyiz7iv4pjud43j.py -k ``` Example output: <img width="430" alt="Screenshot 2023-03-01 at 4 51 06 PM" src="https://user-images.githubusercontent.com/52589240/222302996-814a85be-472b-463c-9e85-39d2c9d20e1a.png"> Note: I use the first 10 characters of the hash to identify each kernel since 1. hash is easier to get in the code :) 2. name like `triton__3` only makes sense within a compiled module, but a hash can make sense even without specifying the compiled module (assuming we have enough bytes for the hash) If we found a triton kernel with hash like c226iuf2wi having poor performance, we can look it up in the original compiled module file. It works since we comment each compiled triton kernel with the full hash. Pull Request resolved: pytorch#95845 Approved by: https://github.com/Chillee
This reverts commit 5d29b68.
A PR to generate benchmark code for individual triton kernels. We can explore improving autotuning with the saved compiled kernel directly. This potentially can speedup our iteration and separate the concern with the upstream components that generate the compiled module.
Since I'm still ramping up on inductor, I'll reflect what I learned here so people can correct me if I'm wrong. In inductor, WrapperCodeGen class is used to generate the compiled module for CUDA (or triton). Here is an example compiled module for a toy model like:
def f(x): return sin(x) + cos(x)https://gist.github.com/shunting314/c6ed9f571919e3b414166f1696dcc61b . A compiled module contains the following part:The triton kernels in the compiled module are annotated with decorator like pointwise which is used for autotuning.
This PR add a config so enabling it will just trigger the path of the compiled module being printed. It can be controlled from environment variable as well.
The path to each compiled triton kernel is added as comment in the compiled module. E.g.
Example command:
cc @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire