forked from pytorch/pytorch
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
[inductor] run all kernel benchmarks individually in a compiled module (
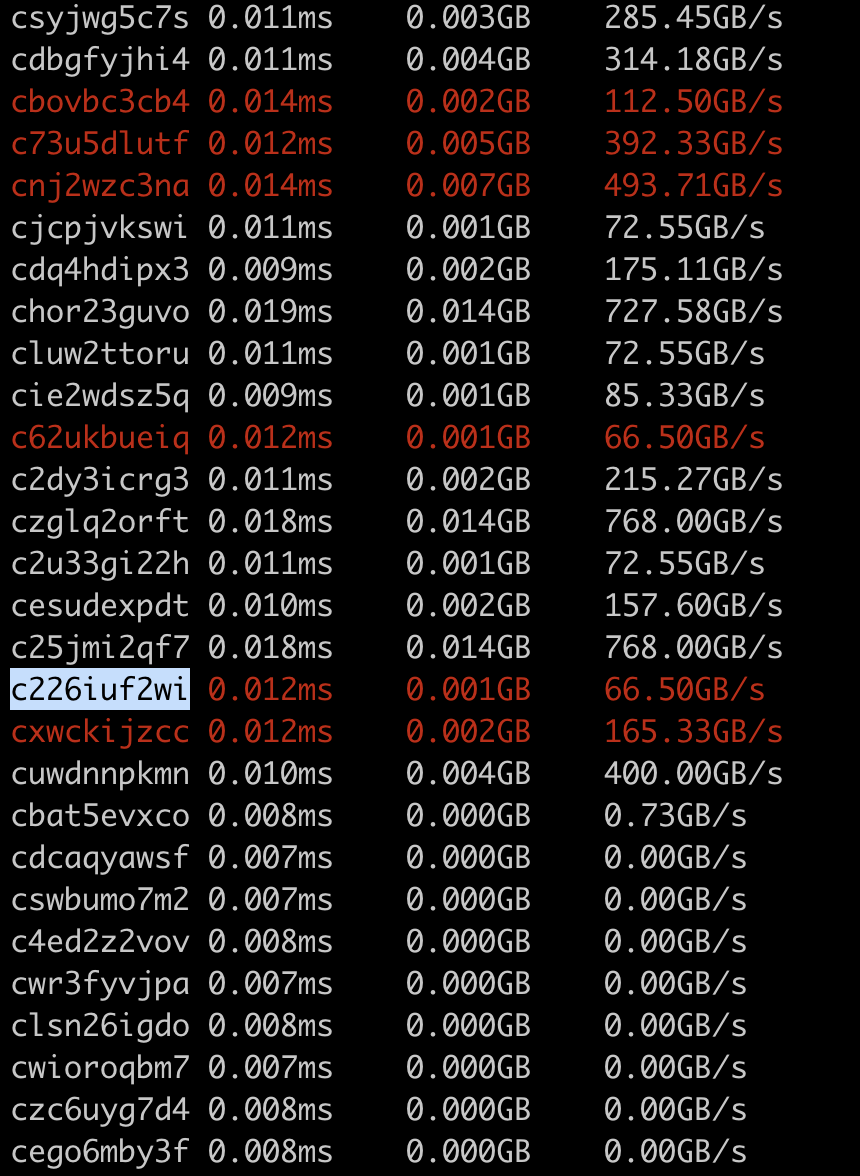
pytorch#95845) This is a follow up for PR pytorch#95506 to run all the triton kernels in a compiled module individually as suggested by Horace. Here are the steps: 1. Run the model as usual with a benchmark script and with TORCHINDUCTOR_BENCHMARK_KERNEL enabled. e.g. ``` TORCHINDUCTOR_BENCHMARK_KERNEL=1 python benchmarks/dynamo/torchbench.py --backend inductor --amp --performance --dashboard --only resnet18 --disable-cudagraphs --training ``` 2. From the output we will see 3 lines like ``` Compiled module path: /tmp/torchinductor_shunting/rs/crsuc6zrt3y6lktz33jjqgpkuahya56xj6sentyiz7iv4pjud43j.py ``` That's because we have one graph module for fwd/bwd/optitimizer respectively. Each graph module will have one such output corresponding to the compiled module. 3. We can run the compiled module directly. Without any extra arguments, we just maintain the previous behavior to run the call function -- which just does what the original graph module does but in a more efficient way. But if we add the '-k' argument, we will run benchmark for each individual kernels in the file. ``` python /tmp/torchinductor_shunting/rs/crsuc6zrt3y6lktz33jjqgpkuahya56xj6sentyiz7iv4pjud43j.py -k ``` Example output: <img width="430" alt="Screenshot 2023-03-01 at 4 51 06 PM" src="https://user-images.githubusercontent.com/52589240/222302996-814a85be-472b-463c-9e85-39d2c9d20e1a.png"> Note: I use the first 10 characters of the hash to identify each kernel since 1. hash is easier to get in the code :) 2. name like `triton__3` only makes sense within a compiled module, but a hash can make sense even without specifying the compiled module (assuming we have enough bytes for the hash) If we found a triton kernel with hash like c226iuf2wi having poor performance, we can look it up in the original compiled module file. It works since we comment each compiled triton kernel with the full hash. Pull Request resolved: pytorch#95845 Approved by: https://github.com/Chillee
{kind=link}
- Loading branch information
Showing
4 changed files
with
117 additions
and
15 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -8,6 +8,7 @@ | |
| import operator | ||
| import os | ||
| import os.path | ||
| import re | ||
| import threading | ||
| from typing import List | ||
|
|
||
|
|
||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters