Enforce docstring type and default consistency #4155
Conversation
Codecov Report
@@ Coverage Diff @@
## main #4155 +/- ##
==========================================
+ Coverage 95.57% 95.74% +0.17%
==========================================
Files 95 96 +1
Lines 20282 20422 +140
==========================================
+ Hits 19384 19553 +169
+ Misses 898 869 -29 |
I noticed some of these, they are annoying.
Yes, this makes sense to me.
Agreed.
This definitely makes sense for the docs at least. And I'm pleasantly surprised that And I also want to note that the first screenshot you showed is wrong on multiple points. Firstly,
If what you're saying is "keep type hints correct, let doc types be less correct but more meaningful" then I agree. They serve different purposes so I have no issues letting the two diverge a bit. Of course there should be no blatant contradictions.
If by "typehints" you mean the actual type annotations, then I think not. If you mean the ones for the docs, sure. See also my previous point.
I think it would make sense to use
Absolutely, I'd expect most end users to be looking at the docs more than anything else. Having broken/ugly/confusing types listed there is not very helpful. And an additional point of my own: you specifically raised >>> np.array(bytes([1, 3, 5])).size
1
>>> np.array(bytes([1, 3, 5]))
array(b'\x01\x03\x05', dtype='|S3')(Although by some definitions this is still an array-like... so I'm using a definition where the resulting array has a numeric type. This might or might not be headcanon.) Semantically we're not looking for a sequence here, we want an array-like. But in many many cases we really do want a sequence, or actually a fixed-length iterable of any kind (think bounds, min/max limits, light attenuation values etc.). So we should keep an eye out for places where we need array-likes, and perhaps use that instead of In fact it seems that NumPy has an intersphinx link to |
That's what I'm hoping for.
Fully agree, and if we can use array_like[float] and glossary links work, even better.
It's always good to ask, especially before going through a refactor. I want the docs to look like one mind wrote them. If we can converge (or at least start to converge) on an idea then it's worth discussing it. Thanks for the comp-sci discussion. |
|
In an effort to keep this PR sub 2k LOC, I'm calling it sufficient for the moment.
Ready for review. |
|
Review in progress. I'm still annoyed by the fact that what we end up with is largely hit or miss: (In the same sentence |
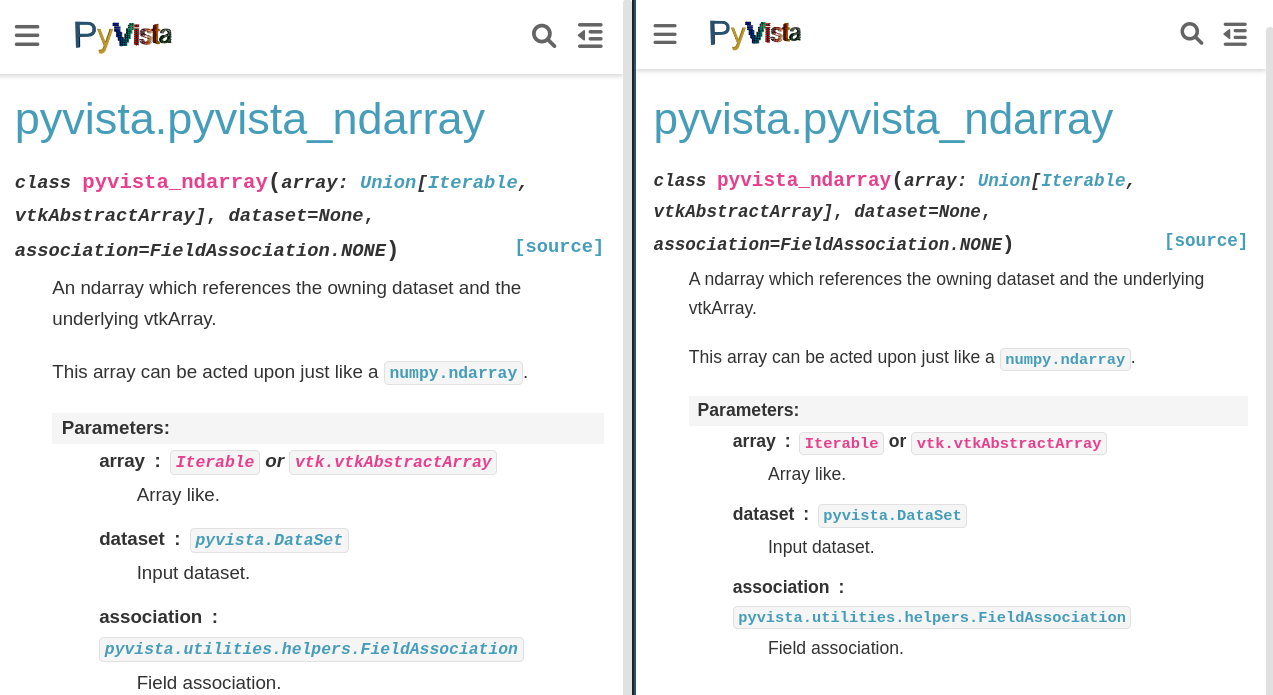
I've started by disabling rendering the parameter types as italic. Left is I feel this improves the readability and helps with nested typing I'm going to try disabling the border to see if that cleans things up more (which it probably will). |
|
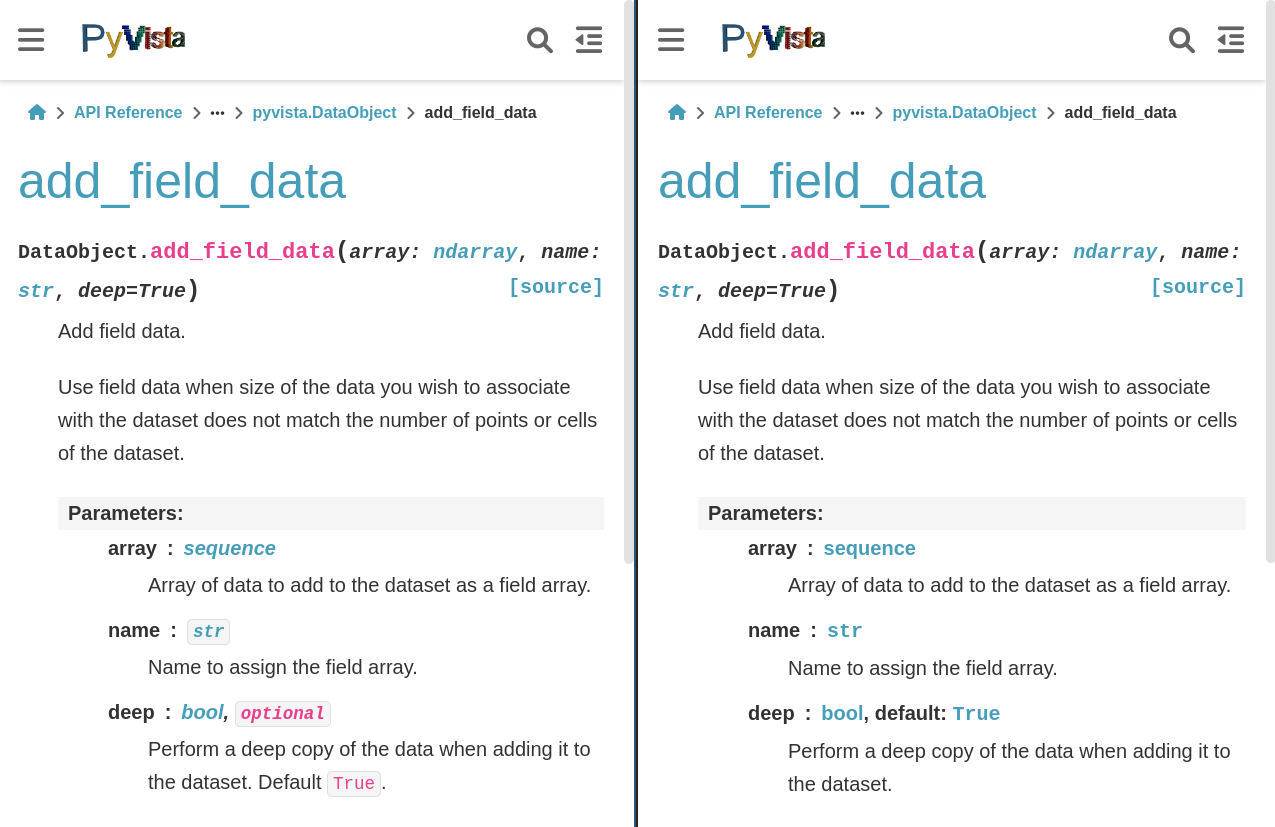
Now, here's without the border and the reduction of the text size to fit said border. Again,
|
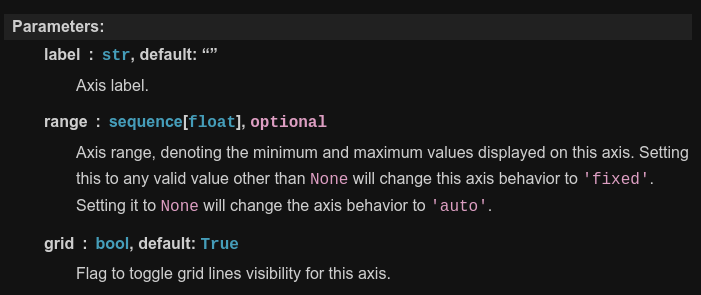
I think that looks a lot better ❤️ Here's a screenshot where we have a generic type:
It feels a bit unfamiliar that the type links are so big (i.e. as big as the rest of the text). I think I'll get used to the new readable one fast. Assuming you agree this is better and we should keep it. |
There was a problem hiding this comment.
Partial review, 4 more big files to go later (filters/poly_data.py, examples/downloads.py, plotting/plotting.py, plotting/renderer.py).
Sorry if a handful of my comments are obsolete upon posting; I haven't checked them against the newest commits you've made.
Co-authored-by: Andras Deak <adeak@users.noreply.github.com>
…43/pyvista/pyvista into doc/sequence-docstring-types
|
This is everything but |
Co-authored-by: Andras Deak <adeak@users.noreply.github.com>
Co-authored-by: Andras Deak <adeak@users.noreply.github.com>
There was a problem hiding this comment.
One future-proofing remark, but this is already fine as is if you don't want to bother with it. Thanks for the quick fixes @akaszynski!
|
As always, thanks @adeak! |
This PR is more of a discussion + code suggestion rather than a genuine PR as I'd like to gain traction before implementing this widely.
@akeak, this is particularly for you.
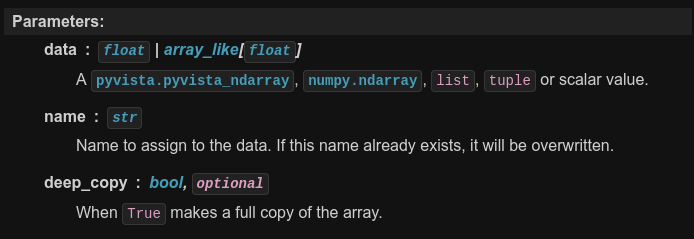
Looking across our docs, I've found that in, for example, DataSet.find_closest_cell, the
Sequencetype does not get rendered properly:This isn't a big deal, we have many types that have no links, but still it's annoying. Plus, we're reminded of the "is numpy.ndarray a sequence?" question since we have to accept both a
Sequenceandnp.ndarrayhere.After some brief research, I found this SO answer stating that a
numpy.ndarrayis a sequence and not a Sequence.This is actually incredibly helpful because this lets us simplify out documentation because we're fundamentally worried about if it is ordered collection of objects that implementes
__len__and__get_item__. We're really concerned about duck typing here, not if it's inherited from collections.abc.Sequence (capital "s").Therefore, I propose we change our docstrings to use the ducktyping sequence where applicable. This is because, according to PEP 3119,
collections.abccheck if the object has the expected interface with without requiring true subclassing.In fact, this is appears the same as VTK's rules:
Therefore, to finally clear up the confusion, wherever possible, replace
iterable,Sequenceornp.ndarray, or whatever mess of values we have with just sequence:Agreement with type hints
We already have a mismatch between our type hints and the docstring, and this suggestion will not improve it. However, I'd argue that our existing typehints, while helpful for
mypy, are not helpful for humans. Furthermore, inDataSet.find_closest_cell, we excluderangeand other possible types that work. For example:Output:
A few questions then:
sequence[float]wherever possible even though it disagrees with our type hints?