Introduction To QFS
Hadoop and other batch processing frameworks run best against a file system designed for their data access pattern: sequential reads and sequential writes of large files of at least tens of megabytes, and often gigabytes.
We have developed the Quantcast File System (QFS), a high-performance distributed file system, to meet the need. It evolved from the Kosmos File System (KFS), which we adopted in 2008 for secondary storage, and began hardening and improving. In 2011, we migrated our primary processing to QFS and stopped using HDFS. Since then we have stored all our data in QFS, and we’re confident it’s ready for other users’ production workloads. We are releasing QFS as open source with the hope that it will serve as a platform for experimental as well as commercial projects.
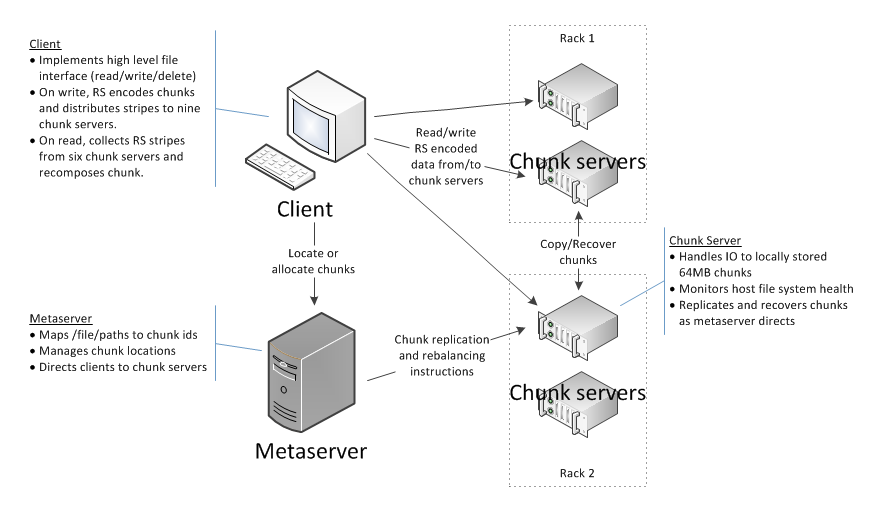
QFS consists of 3 components:
- Metaserver: A central metadata server that manages the file system's directory structure and mappings of files to physical storage.
- Chunk Server: The distributed component of the distributed file system. There's one chunk server for each machine that will store data, and it manages I/O to all the disks on that machine (via, for example, XFS or ext3 on Linux).
- Client Library: Library that provides the file system API to allow applications to interface with QFS. To integrate applications to use QFS, applications will need to be modified and relinked with the QFS client library.
QFS is implemented in C++ using standard system components such as TCP sockets, STL, and Boost libraries. The server components have been used in production on 64-bit x86 architectures running Linux CentOS 5 and 6, and the client library has been tested on CentOS 5 and 6, OSX 10.X, Cygwin, and Debian/Ubuntu.
- Incremental Scalability: Chunk Servers can be added to the system in an incremental fashion. When a chunk server is added, it establishes a connection to the metaserver and becomes part of the system. No metaserver restarts are needed.
- Balancing: During data placement, the metaserver tries to keep the data balanced across all nodes in the system.
- Rebalancing: The metaserver will rebalance data among the nodes in the system when the server detects that some nodes are under-utilized (i.e., < 20% of the chunk server's exported space is used) and other nodes are over-utilized (i.e., > 80% of a chunk server's exported space is used).
- Fault Tolerance: Tolerating missing data is the central design challenge for a distributed file system. QFS supports both per-chunk replication (storing multiple copies of each chunk) and Reed-Solomon 6+3 encoding (storing stripes of parity data that can rebuild chunks without storing all of the original data).
- Fine-tunable Replication, Striping, Recovery Mode: The degree of replication, striping, and recovery mode can be configured on a per-file basis.
- Re-replication: Whenever the degree of replication for a file drops below the configured amount (for example, due to an extended chunk server outage), the metaserver automatically forces the block to be re-replicated on the remaining chunk servers. Re-replication is done in the background without overwhelming the system.
- Data Integrity: To handle disk corruptions within data blocks, data blocks are checksummed. Whenever a chunk is read, checksum verification is performed; whenever there is a checksum mismatch, re-replication is used to recover the corrupted chunk.
- Client Side Metadata Caching: The QFS client library caches directory related metadata to avoid repeated server lookups for pathname translation. The metadata entries expire from the cache after 30 secs.
- File Writes: The QFS client library employs a write-back cache. Also, whenever the cache is full, the client will flush the data to the chunk servers. Applications can choose to flush data to the chunk servers via a sync() call.
- Leases: The QFS client library uses caching to improve performance. Leases are used to support cache consistency.
-
Versioning: Chunks are versioned to permit detection of "stale" chunks.
For instance, consider the following scenario:
- Let chunk servers s1, s2, and s3 store version v of chunk c.
- Suppose that s1 fails, and when s1 is down a client writes to c.
- The write will succeed at s2 and s3, and the version # will change to v'.
- When s1 is restarted, it notifies the metaserver of all the versions of all chunks it has.
- When the metaserver sees that s1 has version v of chunk c, but the latest is v', the metaserver will notify s1 that its copy of c is stale.
- s1 will delete c.
- Client Side Fail-over: The client library is resilient to chunk server failures. During reads, if the client library determines that the chunk server it was communicating with is unreachable, the client library will fail over to another chunk server and continue the read. This failover is transparent to the application.
- Language Support: The QFS client library can be accessed from C++ and Java. A experimental Python access module is also available.
-
Tools: The command line tool for accessing QFS gets installed as
.../bin/tools/qfs. It is meant as a drop in forhadoop fs. Unlikehadoop fs, there is no JVM loading when you invoke this tool, which brings the time to stat a file from 700 milliseconds to below 10 milliseconds in our tests. Additional tools for loading/unloading data into QFS, as well as tools to monitor the chunk servers and metaserver are also provided. - Direct IO: is used by default if supported by the OS and host file system in order to minimize CPU and OS memory utilization.
-
FUSE support on Linux and MacOS X: By mounting QFS via FUSE, this support
allows existing linux utilities (such as
ls) to interface with QFS. - Concurrent atomic write append support: multiple QFS clients can simultaneously append data to the same chunk. Each write is synchronously replicated. QFS write append protocol guarantees append operation atomicity [all or nothing] and ensures that all chunk replicas are identical.
- N+M Reed-Solomon error correction / encoding support: QFS has two encoders: one is optimized for N+3 (3 error correction stripes), the other supports arbitrary number of error correction stripes.
- Unix style permissions support.
- Kerberos and X.509 authentication support: meta server, chunk server, and QFS client can optionally use Kerberos and/or X.509 authentication.
- TLS encrypted network communication: TLS can optionally be used to secure communications between meta server, chunk server, and QFS client nodes.
- Object store [S3] support: file data can be optionally stored in AWS S3 compatible object store. "Object store" and conventional files can exist in same file system.
- Storage tiers support: files and directories can be assigned storage tiers range. When created, files and directories are assigned parent's directory tier range. Chunk servers, in turn, can be configured to use storage media with different characteristics for each tier. For example: RAM disk, SSD, and rotational media tiers, or standard S3 and "glacier" tiers.
- Meta server replication: solves single point of failure problem. QFS file system meta data stored in checkpoint and transaction log segments can be synchronously replicated to multiple meta server nodes, in order to mask node and communication failures by automatically determining set of connected and usable meta server nodes, and switching over to it.
- The maximum value for a file's degree of replication is 64 (assuming resources exist).
- The metaserver currently does not replicate chunks whenever files become "hot" (dynamic load balancing). The system does, however, perform a limited form of load balancing whenever it determines that disks on some nodes are under-utilized and those on other nodes are over-utilized.
- The system does not have a facility for taking snapshots.
- Limited "random" write support for files created with Reed-Solomon recovery. Only whole-stripe rewrite is currently supported. In other words, for all practical purposes only sequential writes are currently supported with RS files.
- Simultaneous read and write access to the same chunk is not supported for all practical purposes. The chunk cannot be read until the writer "closes" the chunk and the chunk becomes "stable" / readable. The client library currently does not attempt to buffer the data to allow simultaneous read/write access to the same chunk.
QFS builds upon some of the ideas outlined in the Google File System (GFS) paper (SOSP 2003).
