I'm trying to learn functional programming, and that could be quite overwhelming.
Search for functional programming often results in a bunch of unreadable lingoes (for me at least), articles trying to wrap the F-word in new names like 'mappable', or people that do not understand it, but are writing tutorials either way.
That isn't what I'm trying to do here. What I'm doing is learn in public.
First, and that is worth even if you do not keep reading to the end, check this out:
-
Professor Frisby Introduces Composable Functional JavaScript by Brian Lonsdorf - This is an incredible free course, and is the source of most of the stuff you are going to see here, so do a favor to yourself and watch it.
-
Category Theory by Bartosz Milewski - If you're feeling adventurous and want to discover the crazy world of the Category Theory, watch this series of videos (I'm watching for the second time, and probably I'll need at least one more, but worth it).
Now that I pointed you to people who know what they're talking about, I'm free to throw here that stuff that is in my head while I'm trying to figure that out.
Table of content
- A naive approach to functional programming
As far as I understand, Category Theory is a way to try to structure things through abstraction.
Instead of walking in the streets trying to draw a map, we use a satellite picture for that.
We have these objects and the relations between them, and we're forbidden to look into the objects (not because we want to punish ourselves, but to create structures that serve to more than one type of category), so all our assertions need to be inferred from those relations, called morphisms.
Let's stop right there. Why on earth I need to engage in this math theory?! I'm not trying to understand the entire world through math. I want to become a better programmer.
Ok, I'm with you on that. But do you remember that those math guys have this constraint of only seeing things through their relations? If you take types as a Category and function as morphisms, you end up with a bunch of knowledge on how to deal with functions and can apply that to make your code better. I'm talking about composition and predictability.
So the main goal is to write code that is predictable and easy to reason about, and we can get that if we fit our functions and data structures into the Category Theory laws.
Category Theory is all about composition. We only have the morphism/arrows/functions to look at, since we're not allowed to check out the object's properties. So all the theory is based on these arrows and how to compose them.
The most common graphic representation we get when we start to search for Category Theory is:
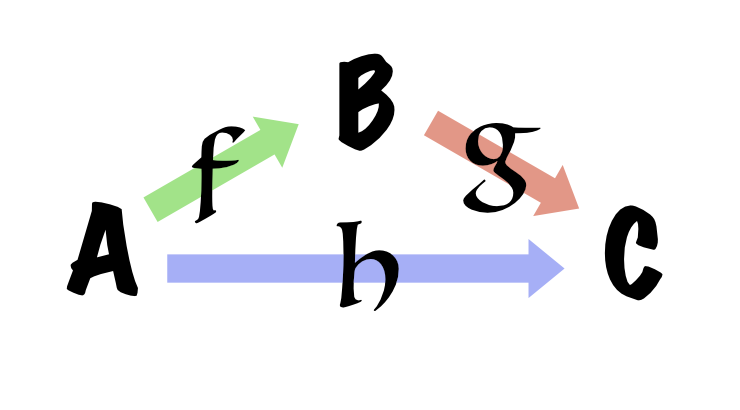
If we have a function from A to B and another one from B to C, we must have a function A to C:
const f = (x: string) => x.length > 0;
const g = (x: boolean) => (x ? 1 : 0);
// Composing g after f:
const h = (x: string) => g(f(x));And there is some laws:
Taking:
type f = <A, B>(x: A) => B;
type g = <B, C>(x: B) => C;
type h = <C, D>(x: C) => D;We have: h . (g . f) == (h . g) . f == h . g . f
After all it all translates to x => h(g(f(x)))
For every object, there is always a function that returns itself (identity): id = x => x
First, we need to use pure functions.
There is a bunch of rules to check a function as pure, but I'll stick with: referential transparency, that translates to I can swap my function invocation for the value it returns, like a lookup table. So, for that, no global variables, no side effects.
I knew it! I work with Web Apps, my life is side effects: DOM manipulation, users inputs, Ajax calls, are you crazy?!
Relax, take a deep breath 🧘♂️. We'll continue to do all that, believe me.
Also, we need currying that's a partial application where the end function always expect one argument (function arity 1). Languages like Haskel have that into it, but with JS we need to create or use a lib for that.
Ok, but there are more than pure functions. I'll throw a bunch of loose definitions here, so we can feel more comfortable when I talk Category Theory terms (and of course, it's valid to remember that's what I got about them):
-
Functors = A type that implements a
map(not related to iteration, but applying a function on its value) preserving composition (F(x).map(f).map(g) === F(x).map(g(f(x)))) and identity (F(x).map(x => x) = F(x)). -
Pointed Functors = Functor that implements an
ofmethod (that is a way to throw a value inside our container). -
Applicative Functors = Functor that implements the method
ap(apply the value of one container on the value of another container, remember, the value can be a function). -
Semigroups = A type that implements a
concatmethod that is associativity, that means'Hello' + ('World' + '!') = ('Hello' + 'World') + '!' -
Monoids = It's a semigroup that has an
emptymethod. In other words, it's safe to work no matter the number of elements:empty string + 'all fine' = 'all fine'no errors in our dear console. -
Monads = Is a pointed functor that implements a
flatMaporchainmethod (instead of nested Monads, it'll return a unidimensional Monad); -
Natural transformation = FunctorA(value) => FunctorB(value)
-
Isomorphism = You can change from a type to another and vice-versa without losing information.
I already can see people coming with torches and forks, to punish me for all the nonsense that I put here. But hold your horses. That's a living document from my learning process, and that's what I get so far.
Ok, ok. But I'm starting to lose my interest. Can we see some code? I want to check how to implement all of that!
Fair enough. Let's move on.
Have you ever saw those Category Theory diagrams, where there is a dot, and an arrow that goes from that dot to itself?
Those are identity functors. In our case, where our category is a set of types, they're endofunctors (because they map to the same set).
Ok, but why would I be interested in such a thing, a functor that maps to itself?
Because that's our ticket for the marvelous world of composition.
We're going to put our value inside this container (functor) and use its map method to apply a function on its value and then return another functor to keep that going, till we finish with our operations and redeem our result using fold.
First, let's define our Identity Functor:
interface Identity<A> {
map: <B>(f: (x: A) => B) => Identity<B>;
chain: <B>(f: (x: A) => Identity<B>) => Identity<B>;
fold: <B>(f: (x: A) => B) => B;
inspect: () => string;
}
const identity = <A>(value: A): Identity<A> => ({
map: <B>(f: (x: A) => B) => identity<B>(f(value)),
chain: <B>(f: (x: A) => Identity<B>) => f(value),
fold: <B>(f: (x: A) => B) => f(value),
inspect: () => `Identity(${value})`
});There are five methods here:
- map: We apply a function to our value and put the result back in a functor to keep composing.
- chain: Imagine that the function that you want to
mapreturns anotherIdentity. In that case, we'll end up withIdentity(Identity(value)). Chain flat that, resulting in a singleIdentity(value). - fold: It's tough, but sooner or later, our value needs to leave the cozy and secure functor.
- inspect: Friendly console.
Wait a minute. You said five methods, but there are only four here!
Yeap, the identity call has the same effect of the of method, that is the way to insert the value inside our functor.
And how about conditional constructs and error handler? Can functional programming improve that aspect of coding?
Yes, it can!
In this talk Scott Wlaschin uses this Railway Track model:

Here we have functions that can return two different things, and we have a functor that can help us with that called Either:
interface Either<L, R> {
map: <B>(f: (x: R) => B) => Either<L, B>;
chain: <B, C>(f: (x: R) => Either<B, C>) => Either<L, R> | Either<B, C>;
fold: <B, C>(onLeft: (x: L) => B, onRight: (x: R) => C) => B | C;
inspect: () => string;
}
const either = <L, R>(left?: L, right?: R): Either<L, R> => ({
map: <B>(f: (x: R) => B) =>
exist(right) ? either<L, B>(undefined, f(right as R)) : either<L, B>(left),
chain: <B, C>(f: (x: R) => Either<B, C>) =>
exist(right) ? f(right as R) : either<L, R>(left),
fold: <B, C>(onLeft: (x: L) => B, onRight: (x: R) => C) =>
exist(right) ? onRight(right as R) : onLeft(left as L),
inspect: () => (exist(right) ? `Right(${right})` : `Left(${left})`)
});That serves to handle errors, if some pops up, we skip the other steps in our chain. But also for skipping unnecessary computation, imagine that we have three predicates, but we only need one to be true to pass to the next step. If the first one returns true, we don't need to compute the next two, we skip them and move on in our pipe.
I want to go rad and put our curried functions in our pipeline. However, I don't want to fold just for that.
To do so, I need to apply functors to functors:
F(x => x + 10) -> F(10) = F(20).
In the end, we need a method ap in a Functor containing a function as value and call that passing another Functor with our expect argument into it:
ap: (functor) => functor.map(value)
A pointed functor with an ap method is called applicative functor.
Typing that with TypeScript end up being impossible for me (TypeScript does not have higher-kinded types like Haskel, and I got lost within so many letters using HKT like in fp-ts), so I cheated a little bit:
interface Applicative<A, B> {
ap: (i: Identity<A>) => Identity<B>;
}
interface Applicative2<A, B, C> {
ap: (i: Identity<A>) => Applicative<B, C>;
}
interface Applicative3<A, B, C, D> {
ap: (i: Identity<A>) => Applicative2<B, C, D>;
}
const applicative = <A, B>(value: (x: A) => B): Applicative<A, B> => ({
ap: (i: Identity<A>) => i.map(value)
});
const applicative2 = <A, B, C>(
value: (x: A) => (y: B) => C
): Applicative2<A, B, C> => ({
ap: (i: Identity<A>) => applicative<B, C>(i.fold(value))
});
const applicative3 = <A, B, C, D>(
value: (x: A) => (y: B) => (z: C) => D
): Applicative3<A, B, C, D> => ({
ap: (i: Identity<A>) => applicative2<B, C, D>(i.fold(value))
});Applicative Functors are not only about currying but also they help us parallelism. In a case where we have a couple of fetch calls, and we wrap them in a functor:
const synchronousLongTask = () => {
// ...
return identity("txt");
};
// sequential:
synchronousLongTask().chain(t1 =>
synchronousLongTask().map(t2 => synchronousLongTask().map(t3 => t1 + t2 + t3))
);
// We have this waterfall effect, where we need to wait for the first `synchronousLongTask`
// return to call the next one and so on.
// But in our example, the calls do not depend on the predecessor.
// They can be called in parallel:
const composeTxt = (txt1: string) => (txt2: string) => (txt3: string) =>
txt1 + txt2 + txt3;
applicative3(composeTxt)
.ap(synchronousLongTask())
.ap(synchronousLongTask())
.ap(synchronousLongTask());We saw that we could pass a function to a map method, let's say a => b, and get F(a) => F(b). But how about on the Functor itself (F(a) => G(a))?
Let's use our Identity and Either:
const identityToEither = <A>(i: Identity<A>) =>
i.fold(x => either<undefined, A>(undefined, x));In this point we already know that we need to respect some law to fit in the predictable Category world:
nt(x).map(f) === nt(x.map(f))
So, we need to put our function to the test:
identityToEither(identity(10))
.map(x => x * x)
.inspect() === identityToEither(identity(10).map(x => x * x)).inspect();
// true (fireworks)Finally, now I can understand this:
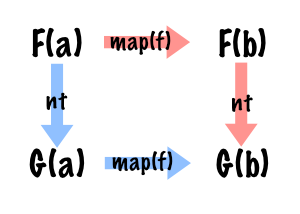
Follow the path ➡️ ⬇️ (red) is equal to go ⬇️ ➡️ (blue):
nt(F(a).map(f)) === nt(F(a)).map(f) === G
And of course, there is some more pro stuff like:
⬇️
⬆️ ⬆️ ⬇️ ⬇️ ⬅️ ➡️ ⬅️ ➡️ + B + A + Start
Haha! Pretty funny, it's a Konami Code, haha... But wait, I'm losing focus here. Why do I want to transform a functor in another?
You don't want to hammer a nail with a saw or cut a log with a hammer. In the same way, you use different functors for each type of task.
However, the functions of your pipeline can return different functors, and we have Natural Transformations at our disposal to fit them in a new functor when we need the methods that it has to offer. Like we took a battery from a drilling machine into a circular saw (Okay, enough of analogies).
Ok by now, we're starting to get the gist of morphisms (arrows), so let's put some spicy on it.
We saw a bunch of arrows from a to b. But what if we also have a morphism from b to a?
In this case, they are no equal, but isomorphic. We can map a -> b and b -> a without losing information.
What?!
I guess an example it's better than all my gibresh:
const insert = x => [x];
const extract = a => a[0];
const start = 10;
const advanceOneSpace = insert(start);
const goBackOneSpace = extract(advanceOneSpace);
start === goBackOneSpace; // True - I guess we're a stuck in this Monopoly game.That gives us the ability to use a natural transformation to temporarily put our value in another Functor, solve a task that suits its peculiarities, and then put it back into the original Functor.
Till now, I'm dodging the TS inability to deal with generics of generics (F< A < B >>).
Here an explanation of what is HKT and how we can simulate its behavior in TS: Higher kinded types in TypeScript, static and fantasy land by gcanti.
It seems it's time to try that out:
So now we have a Record of types. We can define them using HKT<[Identifier], [Type]> for functors holding values from a single type. Or HKT<[Identifier], [TypeA], [TypeB]> for functors that can hold A|B.
// Higher Kinded Types
// Unique type:
export interface URI2HKT<A> {}
export type URIS = keyof URI2HKT<any>;
export type HKT<URI extends URIS, A> = URI2HKT<A>[URI];
// A | B:
export interface URI2HKT2<A, B> {}
export type URIS2 = keyof URI2HKT2<any, any>;
export type HKT2<URI extends URIS2, A, B> = URI2HKT2<A, B>[URI];Like gcanti show in his Medium, I'm using Module Augmentation to add each one of my functors:
// src/Identity.ts:
declare module "./HKT" {
interface URI2HKT<A> {
Identity: Identity<A>;
}
}
// src/Either.ts:
declare module "./HKT" {
interface URI2HKT2<A, B> {
Either: Either<A, B>;
}
}With that, I changed my first version of Applicative, that only can handle Identity Functors, for any Functor A, and create a new Applicative2 to deal with Functor A|B:
// src/Applicative.ts:
export interface Applicative<A, B> {
ap: <F extends URIS>(fa: HKT<F, A>) => HKT<F, B>;
}
export const applicative = <A, B>(value: (x: A) => B): Applicative<A, B> => ({
ap: <F extends URIS>(fa: HKT<F, A>) => fa.map(value)
});
// src/Applicative2.ts:
export interface Applicative2<A, B> {
ap: <F extends URIS2, L>(fea: HKT2<F, L, A>) => HKT2<F, L, B>;
}
export const applicative2 = <A, B>(value: (x: A) => B): Applicative2<A, B> => ({
ap: <F extends URIS2, L>(fea: HKT2<F, L, A>) => fea.map(value)
});Bear with me. That will be a crazy trip.
I was researching about I/O. Especially how to fit user inputs (that can be everything) and system outputs (functions that return void) in our functional world.
First, I find articles assuming that's a side effect, and I/O returns a thunk (delayed calculation). So that serves as a flag (I'll leave the predictable world and go rad, so only call me in a safe place).
However, I find a different approach to this problem:
In this video, Tsoding reimplements the I/O monad, trying to answer that same question.
Maybe we should change or perspective over the problem. Would a function that receives the state of the World and returns the state of the World be pure?
type IO = <World>(w: World) => World;
It's like instead of any we had a type everything and from it we can extract the user input, or insert a console.log.
I'm not even bothering to discuss the
state of Worldpart, but when I use I/O in Haskell, I'm not passing anything to I/O.
Well, what if you are doing it, but Haskell hides that from you?
Why?
Unless we're dealing with the multi-dimension scenario, you have a single World that is being modified and passed to another function.
World1 -> (someOperation) -> World2 -> (someOperation) -> World3
So we're not allowed to reuse World1. To prevent the user from doing that, Haskell makes the World inaccessible for the user.
Either way, going into the crazy World thing, or only deferring the evaluation of a side effect, we can have segments in our code, where we only deal with pure functions and points where the I/O (synchronous) or Task (asynchronous) side effect happens.
At the end (at least till the point I understand it), I/O is the same as creating a function to receive user input or read a file that returns Identity or Either:
const unsafe = (): Either<string, number> => {
// ex.: get user input, parse to an Int or return 'error'
};
const safe = (input: Either<string, number>) => {
input
.map(x => x + 10)
.map(x => x * x)
.fold(
x => x,
x => x
);
};
safe(unsafe());Following this Bartosz's talk, we have four algebraic data types:
- Unit
- Products
- Sums
- Exponentials
Their names correspond to the number of possible values:
Taking const setA = [true, false], const setB = [r,g, b]:
- Unit: single value =
void; - products: 6 possible results (2 * 3) in
pair<A, B>=[[true,r],[true,g],[true,b], [false,r],[false,g],[false,b]] - sums: 5 possible results (2 + 3) in
A|B=[true, false, r, g, b] - exponentials: 8 possible results (2^3), if we take the function type
B -> A=[r => true, r => false, g => true, g => false, b => true, b => false, _ => false, _ => true]
In type theory, whenever we define a type, we need to say how it's created (introduction) and how to use it (elimination), so let's try that out:
Taking a Pair, as an example, we need two values to create it (intoduction), and first and second methods give us access to each one of them (elimination):
const pair = <A, B>(a: A) => (b: B) => ({
first: a,
second: b
});Here we have a union type: A|B. We can introduce using our naive either implementation:
const x = either<string, number>(undefined, 10);
const y = either<string, number>("error");And to eliminate/use it we have the fold method:
x.fold(console.error, console.log);We implement them using lambdas (a: A) => B and eliminate them calling the function.
It's always available so that you can use it everywhere. And there is no elimination since there is no value in it.
But how that relates to better programming?
It's all about composing. We compose small functions to perform a complex operation, and we can compose types, to hold complex data.
Scalar types (string, number, boolean) compose in more complex data types, like arrays, or objects. Types that, besides containing a value, bring with them a series of methods.
Algebraic data types are ways to compose types, embeded with algebra laws, that can help us solve complex cases like define List recursively as:
type List<T> = void | { head: T; tail: List<T> };Which makes sense for a lazily evaluated language as Haskell.
Speaking of that, check out the gvergnaud's implementation using generators: lazy-list.js.
Finally, let's talk about the state.
We saw that composition creates those pipes through which we pass our values and receive the results after they are processed.
But what if they need a state besides their inputs to run?
Of course, we'll not rely on a global variable. We're functional programmers (or at least we wish). Give us some credit.
There is a way to keep all pure. We need to pass the state as input.
The state will go through the pipes with our values. So given the same state and value, we'll get the same result. Here, as usual, my naive implementation of a State Monad:
export interface State<S, A> {
runWith: (s: S) => [S, A];
chain: <B>(st: (a: A) => State<S, B>) => State<S, B>;
map: <B>(f: (a: A) => B) => State<S, B>;
}
export const state = <S, A>(f: (s: S) => [S, A]): State<S, A> => ({
runWith: (s: S) => f(s),
chain<B>(st: (a: A) => State<S, B>) {
return state<S, B>(s1 => {
const [s2, a] = this.runWith(s1);
return st(a).runWith(s2);
});
},
map<B>(f: (a: A) => B) {
return state<S, B>(s1 => {
const [s2, a] = this.runWith(s1);
return [s2, f(a)];
});
}
});We have almost an Applicative since we hold a function. But this function has this particular signature: state => [state, A]. Now, we return a pair of our state and value.
You pile up functions and then, in the end, call runWith and pass the initial value.
const initialState = true;
const state = state<boolean, number>(st => [st, 50]);
const process1 = (x: number) => x * 10;
const process2 = (x: number) =>
state<boolean, Either<string, number>>(st =>
st
? [st, either<string, number>(undefined, x + 50)]
: [st, either<string, number>("error")]
);
const process3 = (x: number) => x + 10;
const x = state
.map(process1)
.chain(process2)
.map(e => e.map(process3))
.runWith(initialState)[1]
.fold(
x => x,
x => x
);
// x = 560 (50 -> 500 -> 550 -> 560)In this case, we composed some functions, including a function that returns Either<string, number>.
It's quite elegant solution. In our example, we did not change the state, but it's possible with the chain method.
In addition to states, our functions may need configuration. For these cases, we use the Reader Monad.
The good news is that since we already created the State Monad, we almost have the Reader Monad, with a little gotcha, we need to prevent the config change.
So our naive implementation would be:
export interface Reader<C, A> {
addConfig: (c: C) => [C, A];
chain: <B>(st: (a: A) => Reader<C, B>) => Reader<C, B>;
map: <B>(f: (a: A) => B) => Reader<C, B>;
}
export const reader = <C, A>(f: (c: C) => [C, A]): Reader<C, A> => ({
addConfig: (c: C) => f(c),
chain<B>(r: (a: A) => Reader<C, B>) {
return reader<C, B>(c => {
const [_, a] = this.addConfig(c);
return r(a).addConfig(c);
});
},
map<B>(f: (a: A) => B) {
return reader<C, B>(c => {
const [_, a] = this.addConfig(c);
return [c, f(a)];
});
}
});As we can see, in the chain method, I'm ignoring the config that cames from the first Reader ([_, a]), and using the first one. That way, even if the user changes the config by mistake, we stick with the original.
And, of course, our super contrived example:
const config = { env: "development" };
type Config = typeof config;
const withConfig = (c: Config): [Config, number] => [
c,
c.env === "development" ? 10 : 0
];
const f = (x: number) => x * 10;
const g = (x: number) => x - 10;
reader<Config, number>(withConfig)
.map(f)
.map(g)
.addConfig(config);
// env === 'development' -> 10 -> 100 -> 90I was researching about pattern matching and found an incredible article and lib written by Wim Jongeneel.
He uses a lot of TS features that are new to me. Here another cool article from Artur Czemiel explaining the infer and conditional types.
With that, I rewrote the Either to use pattern matching:
ype EitherValue<L, R> = { tag: "left"; value: L } | { tag: "right"; value: R };
export interface Right<L, R> {
map: <B>(f: (x: R) => B) => Right<L, B>;
chain: <B>(f: (x: R) => Right<L, B>) => Right<L, B>;
fold: <B, C>(onLeft: (x: L) => B, onRight: (x: R) => C) => B | C;
inspect: () => string;
}
export interface Left<L, R> {
map: <B>(f: (x: R) => B) => Left<L, B>;
chain: <B>(f: (x: R) => Left<L, B>) => Left<L, B>;
fold: <B, C>(onLeft: (x: L) => B, onRight: (x: R) => C) => B | C;
inspect: () => string;
}
const right = <L, R>(value: R): Right<L, R> => ({
map: <B>(f: (x: R) => B) => right<L, B>(f(value)),
chain: <B>(f: (x: R) => Right<L, B>) => f(value),
fold: <B, C>(onLeft: (x: L) => B, onRight: (x: R) => C) => onRight(value),
inspect: () => `Right(${value})`
});
const left = <L, R>(value: L): Left<L, R> => ({
map: <B>(_: (x: R) => B) => left<L, B>(value),
chain: <B>(_: (x: R) => Right<L, B>) => left<L, B>(value),
fold: <B, C>(onLeft: (x: L) => B, onRight: (x: R) => C) => onLeft(value),
inspect: () => `Left(${value})`
});
export type Either<L, R> = Right<L, R> | Left<L, R>;
export const either = <L, R>(
taggedValue: EitherValue<L, R>
): Left<L, R> | Right<L, R> =>
match<EitherValue<L, R>, Right<L, R> | Left<L, R>>(taggedValue)
.with({ tag: "left" }, ({ tag, value }) => left<L, R>(value))
.with({ tag: "right" }, ({ tag, value }) => right<L, R>(value))
.run();There still a ton to TS stuff I need to learn. Conditional typing can improve our sum types, so stay tuned for more refactor soon.
This repo is a journal of my learning process though the land of Functional Programing and TypeScript. All help is welcome, so feel free to propose code improvements, fixes, and more material to learn.
- Fork it!
- Create your feature branch: git checkout -b my-new-feature
- Commit your changes: git commit -am 'Add some feature'
- Push to the branch: git push origin my-new-feature
- Submit a pull request :D
The MIT License (MIT)
Copyright (c) 2020 Rafael Campos
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.