This repository contains the code which detects whether a SMS message is a spam or a legitimate one

The SMS Spam Collection is a set of SMS tagged messages that have been collected for SMS Spam research. It contains one set of SMS messages in English of 5,574 messages, tagged acording being ham (legitimate) or spam.
The spam.csv contain one message per line. Each line is composed by two columns: v1 contains the label (ham or spam) and v2 contains the raw text. This corpus has been collected from free or free for research sources at the Internet:
- A collection of 425 SMS spam messages was manually extracted from the Grumbletext Web site. This is a UK forum in which cell phone users make public claims about SMS spam messages, most of them without reporting the very spam message received.
- A subset of 3,375 SMS randomly chosen ham messages of the NUS SMS Corpus (NSC), which is a dataset of about 10,000 legitimate messages collected for research at the Department of Computer Science at the National University of Singapore.
- A list of 450 SMS ham messages collected from Caroline Tag's PhD Thesis.
- Finally, we have incorporated the SMS Spam Corpus v.0.1 Big. It has 1,002 SMS ham messages and 322 spam messages.
- Importing dataset: I have used
pd.read_csv()method to import the dataset. While reading the data, I have used latin-1 which uses the characters 0 through 127, so it can encode half as many characters as latin-1. I have renamed the columns of the dataframe from v1 and v2 to label and message respectivelly. - Removing punctuations: I have used regular expressions library (re) to remove the punctuations using the function
re.sub('[^a-zA-Z]',' ',dataset['message'][i])which substitutes all the characters other than alphabets to whitespaces. - Removing stopwords: The stopwords like "is","the","or" etc which doesnt have any significance should be removed from the message and we used stopwords module from nltk to acheive this.
stopwords.words('english') - Stemming: Stemming is a process of reducing the word to its root stem or removing the affixes. I have used PorterStemmer in my code to acheive stemming.
PorterStemmer.stem(word) - Vectoriztion: Vectorization is a process of generating numerical vectors/arary from textual data. I have implemented Bag of Words(BoW) technique which counts the number of occurances of the word in a message. To implement this, I have leveraged CountVectorizer class to acheive this.
X=CountVectorizer.fit_transform(corpus).toarray() - Splitting dataset: The dataset is then divided into training and testing data in the ratio 80:20.
X_train,X_test,y_train,y_test= train_test_split(X,y,test_size=0.20,random_state=0)
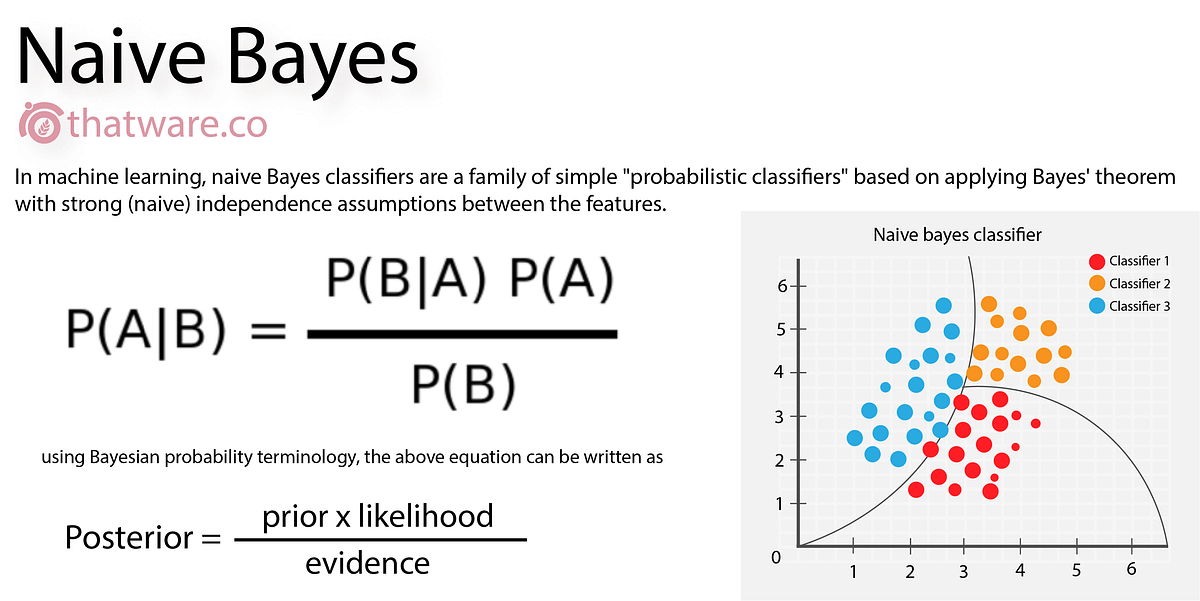
- Generate model: The Naive bayes classifier uses Bayes Theorem which is based on conditionl probability is used to generate a model for the spam dataset. I have used sklearn library for implementing Naive Bayes classifier.
spam_detector=MultinomialNB().fit(X_train,y_train) - Testing the model: I have used predict() function to test the model
y_pred=spam_detector.predict(X_test). - Measuring the performance: I have used confusion matrix and accuracy to determine the performance of the ML model.
cm=confusion_matrix(y_test,y_pred)accuracy=accuracy_score(y_test, y_pred).