🚧 Work-In-Progress
search-ebooks is a Python command-line program that searches through content and metadata of various types of ebooks (djvu, epub, pdf, txt). It is based on the pyebooktools package for building ebook management scripts.
- For the moment, the
search-ebooksscript is only tested on macOS. It will be tested also on linux.- More to come! Check the Roadmap to know what is coming soon.
search-ebooks allows you to choose the search methods for the different ebook formats. These are the supported search-backends for each type of ebooks:
| File type | Supported search-backends |
|---|---|
.djvu |
|
.epub |
|
.doc1 |
|
.pdf |
|
- The utilities mentioned in the Supported search-backends column are used to extract text from ebooks. Then the text is searched with Python's re library (re.findall and re.search). epubtxt is the only one that is not an ebook converter per se like the others.
- More specifically, epubtxt consists in uncompressing first the
epubfile with unzip since epubs are zipped HTML files. Then, the extracted text is searched with Python's re library. I tried to use zipgrep to do both the unzipping and searching but I couldn't make it to work with regular expressions such as\bpattern\b. - The default search methods (except for
epub) are used since they are quicker to extract text than calibre's ebook-convert. But if these default utilities are not installed, then the searching relies onebook-convertfor converting the documents totxt - On macOS, textutil is a built-in command-line text converter.
- Eventually, I will add support for Lucene as a search backend since it has "powerful indexing and search features, as well as spellchecking, hit highlighting and advanced analysis/tokenization capabilities".
I didn't set epubtxt as a default search-backend for
epubfiles because it also includes the HTML tags in the extracted text even though text extraction is faster than with ebook-convert.Once I clean up the extracted text, I will set
epubtxtas a default search method forepubfiles if it is still faster thanebook-convertfor text extraction.
All the utilities that extract text make use of a file-based cache to save the converted files (txt) of the ebooks and hence subsequent searching can be greatly speed up.
The search results are ranked in decreasing order of the number of matches found in the ebook contents.
- Platforms: macOS [soon linux]
- Python: >= 3.6
- diskcache >= 5.2.1 for caching persistently the converted files into
txt - pyebooktools >= 0.1.0a3 for converting files to
txt(see convert_to_txt.py) along with its library lib.py that has useful functions for building ebook management scripts.
As explained in the documentation for pyebooktools, you need recent version of:
- calibre to convert ebook files to
txtand get metadata from ebooks
And optionally, you might need recent versions of the following utilities:
(Highly recommended) poppler, catdoc and DjVuLibre can be installed for faster than calibre's conversion of
.pdf,.docand.djvufiles respectively to.txt.⚠️ On macOS, you don't need catdoc since it has the built-in textutil command-line tool that converts any
txt,html,rtf,rtfd,doc,docx,wordml,odt, orwebarchivefile.- Tesseract for running OCR on books - version 4 gives better results even though it's still in alpha. OCR is disabled by default since it is a slow resource-intensive process.
Cache is used especially to save the converted ebook files into txt to avoid re-converting them which is a time consuming process, especially if it is a document with hundreds of pages. DiskCache, a disk and file backed cache library, is used by the search-ebooks script.
The cache is also used to save the results of calibre's ebook-meta when searching the metadata of ebooks such as their authors and tags.
The search-ebooks script can use the cache with the --use-cache flag.
ℹ️
The MD5 hashes of the ebook files are used as keys to the file-based cache.
A file-based cache library was choosen instead of a memory-based cache like Redis because the converted files (txt) needed to be persistent to speed up subsequent searches and since we are storing huge quantities of data (e.g. we can have thousands of ebooks to search from), a memory-based cache might not be suited. In order to avoid using too much disk space, you can set the cache size with the --cache-size-limit flag which by default is set to 1 GB.
As an example to see how much disk space you might need to cache the txt conversion of one thousand ebooks, let's say that on average each txt file (what is actually being cached) uses approximately 700 KB which roughly corresponds to a file with 350 pages. Thus, you will need a cache size of at least 700 MB to be able to store the txt conversion of one thousand ebooks.
Also DiskCache has interesting features compared to other file-based cache libraries such as being thread-safe and process-safe and supporting multiple eviction policies. See Features for a more complete list.
See DiskCache Cache Benchmarks for comparaisons to Memcached and Redis.
- When enabling the cache with the
--use-cacheflag, thesearch-ebooksscript has to cache the converted ebooks (txt) if they were not already saved in previous runs. Therefore, the speed up of the searching will be seen in subsequent executions of the script.- Keep in mind that caching has its caveats. For instance if the ebook is modified (e.g. tags were added) then the
search-ebooksscript has to runebook-metaagain since the keys in the cache are the MD5 hashes of the ebooks.- There is no problem in the cache growing without bounds since its size is set to a maximum of 1 GB by default (check the
--cache-size-limitoption) and its eviction policy determines what items get to be evicted to make space for more items which by default it is the least-recently-stored eviction policy (check the--eviction-policyoption).
Use the --regex flag to perform regex-based search of ebook contents and metadata. Thus:
--query "a battle"will find any line that contains the words "a battle".--query "^a battle" --regexwill find any line that starts with the words "a battle" because the--regexflag considers the search query as a regex.
ℹ️
By default, the
search-ebooksscript considers the search queries as non-regex, i.e. it searches for the given query anywhere in the text by not processing any regex tokens (e.g.$or^).
⭐
When searching ebook contents and metadata at the same time, note that both types of search are linked by ANDs. For instance, the following command will search for the "reason" string on those ebooks whose filenames start with "The" and whose tags contain "history":
$ search-ebooks ~/ebooks/ --query "reason" --filename "^The" --tags "history" --regex -i --use-cache
Let's say we want to search for the string "turned into a democracy" in the following text:

The difficulty in searching the given string is that sometimes it spans multiple lines and you want to make the regex as general as possible in matching the string no matter where the newline(s) happens in the string.
If we use the simple search query without tokens "turned into a democracy", we will only match the first occurrence of the given string, as shown in the following regex101.com demo:
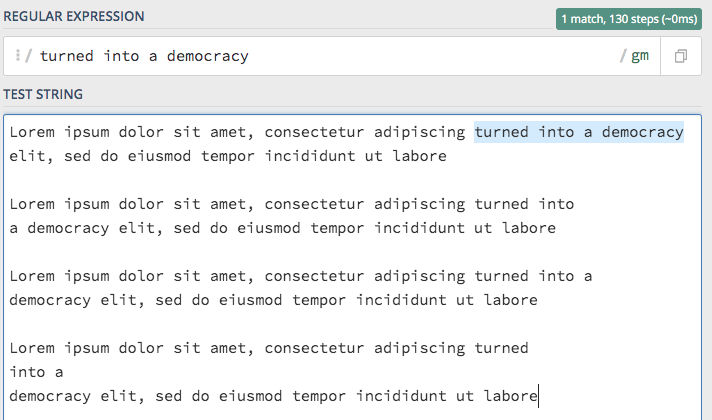
To match all occurrences of the string no matter how many lines it spans, the following regex will do the trick: "turned\s+into\s+a\s+democracy". We replaced the space between the words with whitespaces (one or unlimited), as shown in the following regex101.com demo:
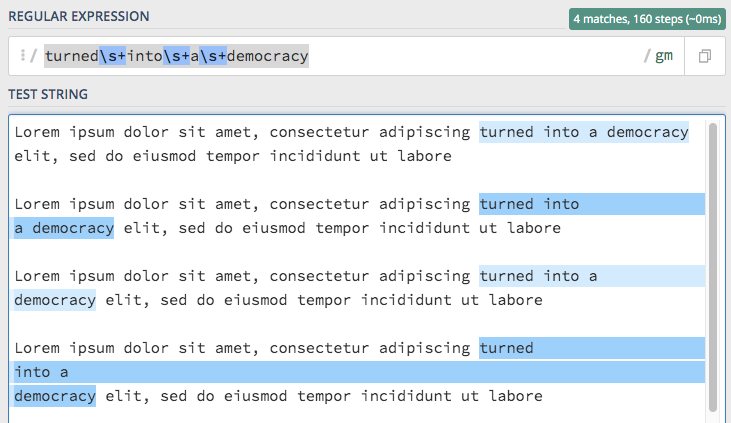
We can now try it out with the search-ebooks script which will search the ~/ebooks/ folder from the Examples:
$ search-ebooks ~/ebooks/ --query "turned\s+into\s+a\s+democracy" --regex -i --use-cacheOutput:

ℹ️
Only the ebook Politics_ A Treatise on Government by Aristotle whose two versions
epubandtxtcorrespond to the same translation could match the given string "turned into a democracy" which is found in the following part of thetxtversion:
and in the text conversion of the
epubfile:


The search-ebooks script accepts regular expressions for the search queries through the --regex flag. Thus you can perform specific searches such as a "full word" search (also called "whole words only" search) or a "starts with" search by making use of regex-based search queries.
This is how you would perform some of the important types of search based on regular expressions:
| Search type | Regex | Examples |
|---|---|---|
| "full word" search | \bword\b: surround the word with the \\b anchor |
--query "\bknowledge\b" --regex: will match exactly the word "knowledge" thus words like "acknowledge" or "knowledgeable" will be rejected |
| "starts with" search | ^string: add the caret ^ before the string to match lines that start with the given string |
--query "^Th" --regex: will find all lines that start with the characters "Th" |
| "ends with" search | string$: add the dollar sign $ at the end of the string to match all lines that start with the given string |
--query "through the$" --regex: will find all lines that end with the words "through the" |
| "contains pattern" search |
|
|
ℹ️
The
--regexflag in the examples allow you to perform regex-based search of ebook contents and metadata, i.e. thesearch-ebookstreats the search queries as regular expressions.
We will present search examples that are not trivial in order to show the potential of the search-ebooks script for executing complex queries.
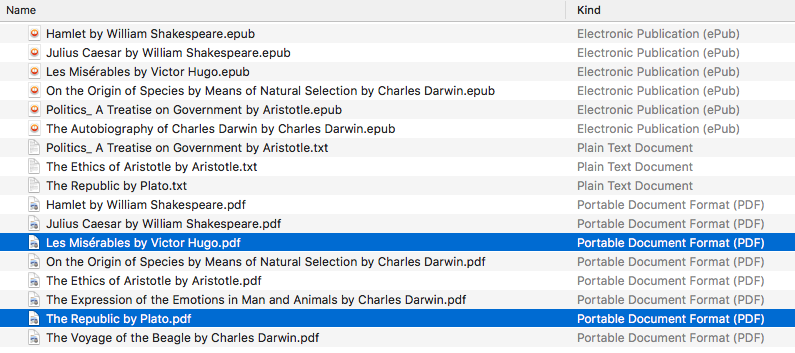
This is the ~/ebooks/ folder that contains the files which we will search from in the following examples:
ℹ️
Of the total eight PDF files, two are files that contain only images: Les Misérables by Victor Hugo.pdf and The Republic by Plato.pdf which both consist of only two images for testing purposes.
We want to search for the word "knowledge" but only for those ebooks whose filenames contain either "Aristotle" or "Plato" and also we want the search to be case insensitive (i.e. ignore case):
$ search-ebooks ~/ebooks/ --query "\bknowledge\b" --filename "Aristotle|Plato" --regex -i --use-cacheℹ️
--regextreats the search query and metadata (e.g. filename) as regex.\bknowledge\bmatches exactly the word "knowledge", i.e. it performs a “whole words only” search. Thus, words like "acknowledge" or "knowledgeable" are rejected.- The
-iflag ignores case when searching in ebook contents and metadata.- Since we already converted the files to
txtin previous runs, we make use of the cache with the--use-cacheflag.
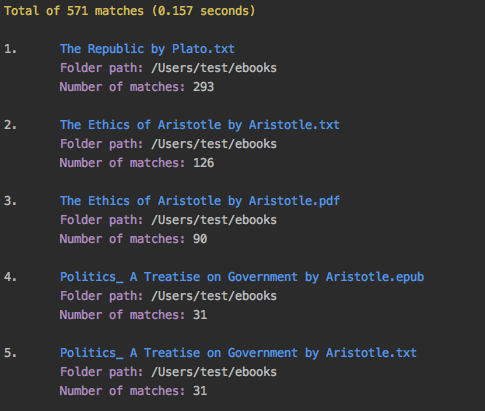
Output:
ℹ️
- The
txtand- On the other hand, the
txtandepubversions of Politics_ A Treatise on Government by Aristotle show the same number of matches because they are both the same translation.- As explained previously, The Republic by Plato.pdf is not included in the matches because it is a file with images only and since we didn't use the
--ocrflag, the file couldn't be converted totxt. The next example makes use of the--ocrflag.
We will execute the previous query but this time we will include the file The Republic by Plato.pdf (which contains images) in the search by using the --ocr flag which will convert the images to text with Tesseract:
$ search-ebooks ~/ebooks/ --query "\bknowledge\b" --filename "Aristotle|Plato" --regex -i --use-cache --ocr trueℹ️
- The
--ocrflag allows you to search.djvuand image files but it is disabled by default because OCR is a slow resource-intensive process.The
--ocrflag takes on three values:{always,true,false}where:
always: try OCR-ing first the ebook before trying the simple conversion toolstrue: use OCR for books that failed to be converted totxtor were converted to empty files by the simple conversion toolsfalse: try the simple conversion tools only. No OCR.More info in pyebooktools README.
Output:
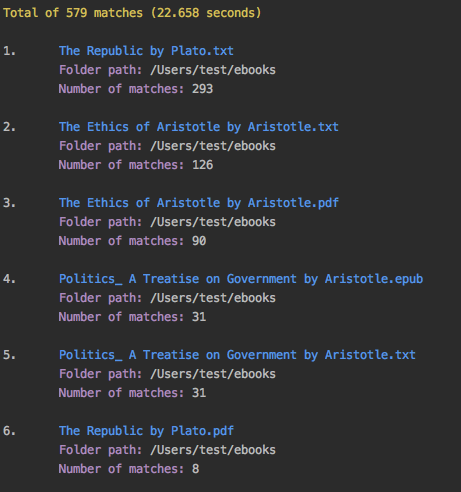
ℹ️
- Since the file The Republic by Plato.pdf was not already processed, the cache didn't have its text conversion at the start of the script. But by the end of the script, the text conversion was saved in the cache.
- As you can see from the search time, OCR is a slow process. Thus, use it wisely!
Search for the words "confront" OR "treason" in ebook contents but only for those ebooks that have the "drama" AND "history" tags:
$ search-ebooks ~/ebooks/ --query "confront|treason" --tags "^(.*drama)(.*history).*$" --regex -i --use-cacheℹ️
- The AND-based regex
^(.*drama)(.*history).*$is a little more complex than an OR-based regex which only uses a vertical bar|.2- calibre's ebook-meta is used by the
search-ebooksscript to get ebook metadata such asTitleandTags. The cache not only save the text conversion but also ebook metadata.- The
--tagsoption acts like a filter by only executing the "confront|treason" regex on those ebooks that have at least the two tags "drama" and "history".
Output:

ℹ️
- The results of ebook-meta were already cached from previous runs of the
search-ebooksscript by using the--use-cacheflag. Hence, the running time of the script can be speed up not only by caching the text conversion of ebooks but also the results ofebook-meta.Here is the output of
ebook-metawhen running it on Julius Caesar by William Shakespeare.epub:
- All the other 16 ebooks from the ~/ebooks/ folder were rejected for not satisfying the two regexes (
--queryand--tags).- Julius Caesar by William Shakespeare.pdf doesn't have any tag, unlike its
epubcounterpart.- Julius Caesar by William Shakespeare.epub only matches once for the word "treason".

If we don't cache calibre's ebook-meta and the converted files (txt), the searching time is greater:

ℹ️
See Cache for important info to know about using the
--use-cacheflag.
Starting from first priority tasks
- Add examples for searching text content and metadata of ebooks
- Add instructions on how to install the
searchebookspackage - Test on linux
- Create a docker image for this project
- Add tests on Travis CI
- Eventually add documentation on Read the Docs
- Read also metadata from calibre's
metadata.opfif found Add support for Lucene as a search backend
PyLucene will be used to access
Lucene's text indexing and searching capabilities from Python
- Add support for multiprocessing so you can have multiple ebook files being searched in parallel based on the number of cores
Implement a GUI, specially to make navigation of search results easier since you can have thousands of matches for a given search query
Though, for the moment not sure which GUI library to choose from (e.g. Kivy, TkInter)
This program is licensed under the GNU General Public License v3.0. For more details see the LICENSE file in the repository.
txt,html,rtf,rtfd,doc,wordml, orwebarchive. See https://ss64.com/osx/textutil.html↩Regex from stackoverflow (but without positive lookahead)↩