2011 04 29 customizability explained
Published on April 29th, 2011 at 15:06
In a previous post, I mentioned a set of features for better customizability of how the re-linq front-end parses expression trees. This time, I want to explain why you’d use those features, and how to decide which one to use.
To start, here’s an updated version of the diagram showing re-linq’s pipeline:
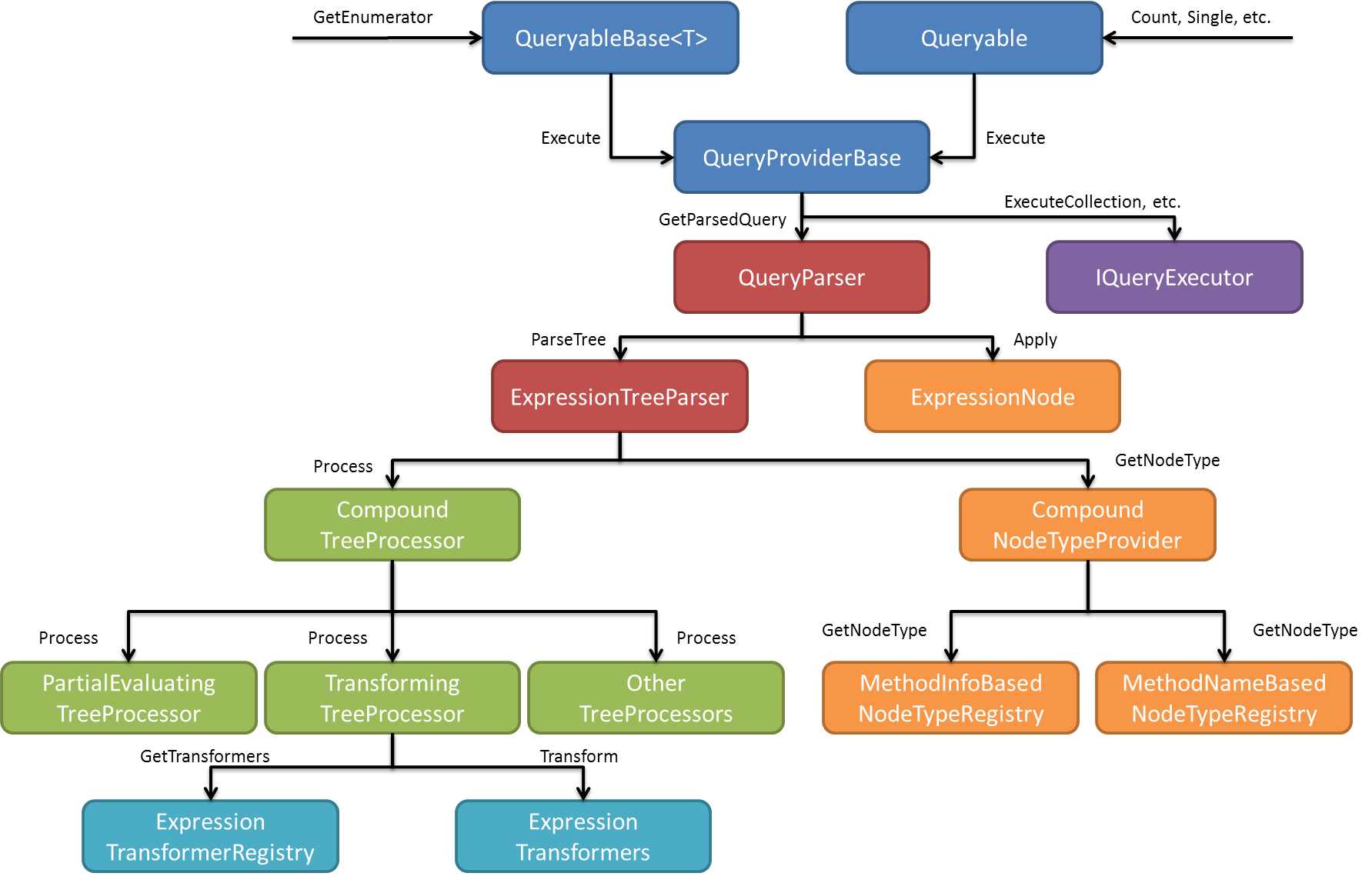
(Read my previous post for an explanation of this pipeline.)
There are four important points of extensibility in that pipeline:
- The query parser,
- the expression tree processors,
- the expression transformers, and
- the expression nodes.
Let’s take a look at each of them.
The query parser’s responsibility is to build a QueryModel from a LINQ expression tree. This responsibility is defined by the IQueryParser interface, and implemented by the QueryParser class. The latter performs quite a good job, so why would you want to replace it?
In reality, you wouldn’t usually want to replace re-linq’s query parser, but maybe you need to extend it. By implementing IQueryParser and decorating the existing QueryParser class, you can:
- Do anything you want with the expression tree before re-linq gets to see it;
- adapt the
QueryModelafter re-linq is done constructing it; - react to the fact that re-linq is asked to construct a
QueryModel; e.g., to implement logging, or to perform some checks; or - avoid the re-linq pipeline at all; e.g, if you want to perform caching at the
QueryModellevel.
The point about caching deserves some explanation. Let’s say you have a LINQ provider that translates queries to SQL. If your users issue the same queries again and again and your LINQ provider proves to be a bottleneck, you might need some possibility to cache the parsed SQL queries based on the incoming expression trees. re-linq currently does not have any support for caching query translation results, and while it’s possible to build a caching subclass of QueryProviderBase that intercepts Execute, this doesn’t really fit re-linq’s architecture with the IQueryExecutor class.
It is, however, easily possible to implement a two-part cache using the existing architecture. First, implement a caching IQueryParser implementation that calculates a cache key from the incoming expression tree, and caches QueryModel references based on that key. Then, implement a caching IQueryExecutor that keeps track of the generated SQL by QueryModel reference.
That said, replacing the query parser is probably not the most interesting extensibility point in re-linq, so let’s go on to the next one.
Expression tree processors are implementations of the IExpressionTreeProcessor interface that re-linq applies to the expression tree before that tree is actually analyzed. You can add your own processors to replace and transform the expression tree if your LINQ provider needs to do this. re-linq already defines two processors that are included in the pipeline by default: the partial evaluator and the transforming processor.
The partial evaluator is responsible for analyzing the parsed expression tree for any sub-expressions that can be evaluated in memory and replacing those sub-expressions with the result of the evaluation.
Here’s an example: Consider you write a query such as the following:
from o in Orders
where o.Date == DateTime.Today
select o
In this query, the partial evaluator will detect that the sub-expression “DateTime.Today” can be evaluated locally and will replace it with a constant expression that holds the respective date. (Note: If you implement query caching as explained above, keep this in mind!)
By default, the partial evaluator is the first processor to be executed. You can replace it if you need a custom evaluator.
The second default processor, the transforming processor, is responsible to execute the expression transformers explained below.
To add or replace expression tree processors, create a customized instance of the QueryParser and ExpressionTreeParser classes. See this description for the details: https://re-motion.atlassian.net/browse/RM-3721.
You’d typically add your own processor if you have an expression visitor that needs to be applied to the expression tree prior to query analysis. Note, however, that the number of expression visitors involved in query parsing can negatively affect the performance of your LINQ provider. For simple processing, expression transformers may be the better alternative, so let’s look at those next.
Expression transformers are a light-weight, efficient way of transforming sub-expressions in an expression tree. They work similar to the Visit... methods of the ExpressionTreeVisitor class, but unlike expression visitors, transformers are only meant for local transformations (i.e., transformations of expression patterns that can be detected by looking at a single expression and its (more or less) immediate children). Transformers are written for a dedicated expression type (e.g., MethodCallExpression), and they should not build up any state that spans multiple expression nodes in a tree.
Here’s an example from re-linq’s source code:
/// <summary>
/// Replaces calls to <see cref="Nullable{T}.Value"/> and
/// <see cref="Nullable{T}.HasValue"/> with casts and null checks. This
/// allows LINQ providers
/// to treat nullables like reference types.
/// </summary>
public class NullableValueTransformer : IExpressionTransformer<MemberExpression\>
{
public ExpressionType\[\] SupportedExpressionTypes
{
get { return new\[\] { ExpressionType.MemberAccess }; }
}
public Expression Transform (MemberExpression expression)
{
ArgumentUtility.CheckNotNull ("expression", expression);
if (expression.Member.Name == "Value" && IsDeclaredByNullableType(expression.Member))
return Expression.Convert (expression.Expression, expression.Type);
else if (expression.Member.Name == "HasValue"
&& IsDeclaredByNullableType (expression.Member))
return Expression.NotEqual (
expression.Expression,
Expression.Constant (null, expression.Member.DeclaringType));
else
return expression;
}
private bool IsDeclaredByNullableType (MemberInfo memberInfo)
{
return memberInfo.DeclaringType.IsGenericType && memberInfo.DeclaringType.GetGenericTypeDefinition()
== typeof (Nullable<>);
}
}
The NullableValueTransformer implements the IExpressionTransformer<T> interface for MemberExpression because it will handle that expression type, similar to an expression visitor implementing VisitMemberExpression. The SupportedExpressionTypes property is used to determine what expressions exactly should be handled by this transformer. (If the type parameter and the expression types don’t match, an exception is thrown at run-time.)
When the expression tree is parsed, the transforming processor (see above) will visit each sub-expression of the expression tree and pick the corresponding transformers based on the node type values. When it picks the NullableValueTransformer, it calls the Transform method, and the transformer may then decide whether to return the (untransformed) input expression, or to return a different expression. In the example, the transformer replaces calls to the Nullable<T>.Value and HasValue properties with cast expressions and null checks.
The transformers are called “inside out”, i.e., child nodes are transformed before their parent and ancestor nodes. When more than one transformer qualifies for the same expression, the transformers are called in a chain in the order of registration. When a transformer changes the expression, the chain is aborted and transformers are again chosen for the new expression (which may have a different type than the original one).
re-linq comes with a number of predefined transformers, including the nullable value transformer, a few VB syntax transformers, a transformer that detects invocations of LambdaExpressions, and a set of transformers that add metadata to constructor invocations for tuple types.
I’d think that most pre-processing requirements that a LINQ provider may have can be efficiently implemented as transformers. To add custom transformations, you again need to create a customized instance of the QueryParser and ExpressionTreeParser classes, see https://re-motion.atlassian.net/browse/RM-3721.
Last, but not least, there are the expression node parsers used by re-linq for translating query operators into query model clauses and result operators. I’ve written about these before, see Custom Query Operators. Add your own node parsers to support non-default query operators. Again, https://re-motion.atlassian.net/browse/RM-3721 shows how they are integrated into the pipeline.
Well, that’s it. I’ve to say I’m quite glad with these customization features. If you have any comments, questions, or suggestions regarding them, feel free to post at our mailing list: http://groups.google.com/group/re-motion-users.