本文基于 hashicorp/raft
v1.3.11版本进行源码分析
关于 hashcrop/raft 其实现原理会分多个章节来讲解. 本文主要分析 hashicorp/raft 选举的实现原理. 在阅读本文前需要有一定的 raft 论文基础, 不然直接看源码会一头雾水.
link
golang hashicorp raft 原理系列
- 源码分析 hashicorp raft election 选举的设计实现原理
- 源码分析 hashicorp raft replication 日志复制的实现原理
- 源码分析 hashicorp raft 持久化存储的实现原理
- 源码分析 hashicorp raft snapshot 快照的实现原理
代码位置: github.com/hashicorp/raft/raft.go
下图为 raft 各个角色的变更迁移图.
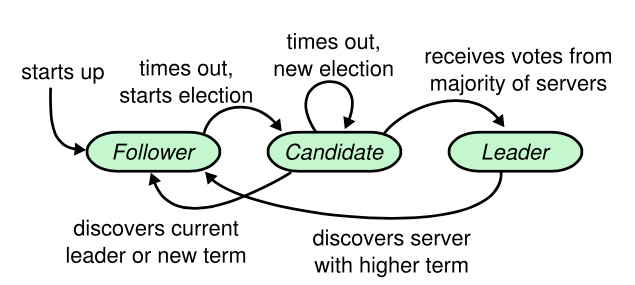
hashicorp raft 中定义了几个 raftState.
type RaftState uint32
const (
// Follower is the initial state of a Raft node.
Follower RaftState = iota
// Candidate is one of the valid states of a Raft node.
Candidate
// Leader is one of the valid states of a Raft node.
Leader
// Shutdown is the terminal state of a Raft node.
Shutdown
)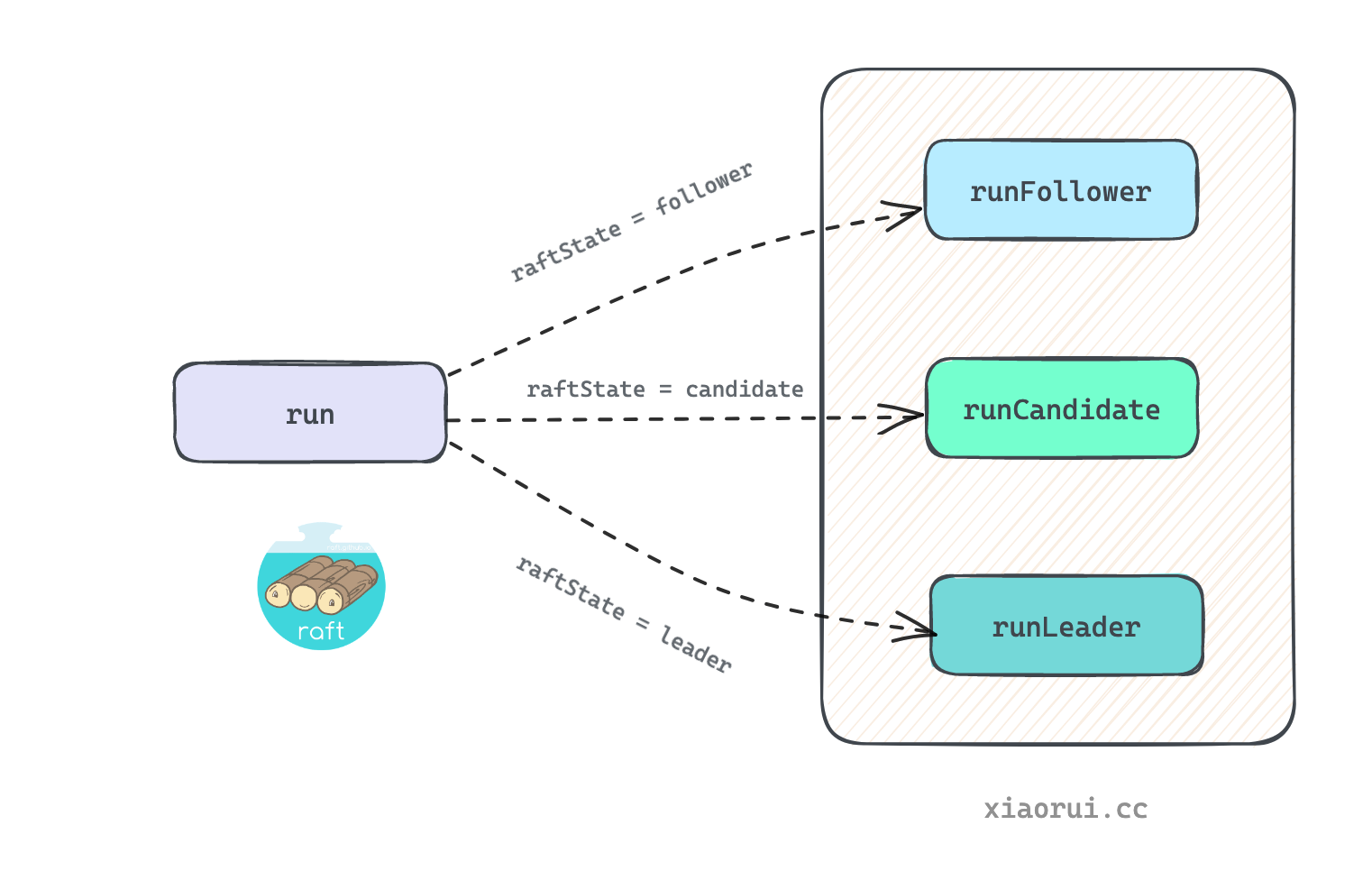
run() 为 hashicorp/raft 的核心启动入口, 通过判断当前 state 状态, 调用不同的方法来处理. 刚启动时 state 为 follower 跟随者.
// run the main thread that handles leadership and RPC requests.
func (r *Raft) run() {
for {
// 检测是否需要退出
select {
case <-r.shutdownCh:
// 清空 leader 状态
r.setLeader("", "")
return
default:
}
switch r.getState() {
case Follower:
// 当 state 为 follower, 则运行 runFollower 逻辑.
r.runFollower()
case Candidate:
// 当 state 为 condidate, 则运行 runCondidate 逻辑.
r.runCandidate()
case Leader:
// 当 state 为 condidate, 则运行 runCondidate 逻辑.
r.runLeader()
}
}
}runFollower() 为 follower 核心处理方法. 首先创建一个心跳定时器, 定时器时长为 1000ms - 2000ms 内的随机值.
- 当 heartbeat 心跳定时器触发到期超时, 可以理解为在心跳周期内没有收到 leader AppendEntries 请求, 所以假设认定 leader 异常, follower 切换到 candidate 候选者进行发起选举.
- 但在 heartbeat 心跳时间内, 收到了其他 peer 请求.
- 当收到了 candidate 的 requestVote 投票请求, 在验证请求的 term 和 index 后, 决定是授权还是拒绝, 重置定时器.
- 当收到 leader 的 AppendEntries 日志请求时, 会调用
setLeader()方法记录 leader 信息, 并且会重置定时器.
所以 follower 只要触发了 heartbeat 定时器, 那么就会切换到 candidate 候选者的角色进行选举.
runFollower() 其内部需要判断边界条件不少, 详细流程请看下面的代码注释.
// runFollower runs the main loop while in the follower state.
func (r *Raft) runFollower() {
didWarn := false
// 尝试加锁从内存里获取 leader 地址和 ID.
leaderAddr, leaderID := r.LeaderWithID()
// 生成一个随机的心跳timer, 最大拿到的时间为 1000ms - 2000ms 以内的随机值, 默认为 1000ms
heartbeatTimer := randomTimeout(r.config().HeartbeatTimeout)
// 不断循环监听各个通知管道.
for r.getState() == Follower {
// 标记休眠中
r.mainThreadSaturation.sleeping()
select {
case rpc := <-r.rpcCh:
// 标记工作中
r.mainThreadSaturation.working()
// 处理 rpc 请求, 这里有投票、传输日志、传递快照的 RPC 请求
r.processRPC(rpc)
case c := <-r.configurationChangeCh:
// 标记工作中
r.mainThreadSaturation.working()
// 当前不是 leader 角色时, 拒绝配置变更.
c.respond(ErrNotLeader)
case a := <-r.applyCh:
// 标记工作中
r.mainThreadSaturation.working()
// 当前不是 leader 角色时, 拒绝写请求.
a.respond(ErrNotLeader)
case v := <-r.verifyCh:
r.mainThreadSaturation.working()
// 当前不是 leader 角色时, 拒绝执行校验.
v.respond(ErrNotLeader)
case ur := <-r.userRestoreCh:
r.mainThreadSaturation.working()
// 当前不是 leader 角色时, 拒绝存储逻辑.
ur.respond(ErrNotLeader)
case c := <-r.configurationsCh:
r.mainThreadSaturation.working()
c.configurations = r.configurations.Clone()
c.respond(nil)
case b := <-r.bootstrapCh:
r.mainThreadSaturation.working()
// 返回配置
b.respond(r.liveBootstrap(b.configuration))
case <-r.leaderNotifyCh:
// Ignore since we are not the leader
case <-r.followerNotifyCh:
// 把心跳时间
heartbeatTimer = time.After(0)
case <-heartbeatTimer:
r.mainThreadSaturation.working()
// 重置心跳时间
hbTimeout := r.config().HeartbeatTimeout
heartbeatTimer = randomTimeout(hbTimeout)
// 如果距离上次请求处理时间间隔小于心跳时间, 则 continue 跳过.
lastContact := r.LastContact()
if time.Now().Sub(lastContact) < hbTimeout {
continue
}
// 没有收到 leader 的心跳, 则从 follower 转变为 candidate 状态
lastLeaderAddr, lastLeaderID := r.LeaderWithID()
// 再次清理 leader 状态信息
r.setLeader("", "")
// 如果最后一条日志为 0, 则不进行选举.
if r.configurations.latestIndex == 0 {
...
} else if r.configurations.latestIndex == r.configurations.committedIndex &&
!hasVote(r.configurations.latest, r.localID) {
// 如果最后 lastestIndex 和 committedIndex 一致, 当前节点 id 不在 config.Servers 里, 则不进行选举.
...
} else {
// 当前实例 id 在配置的服务列表里, 则切到 candidate 角色进行后面的选举.
if hasVote(r.configurations.latest, r.localID) {
// 切换 candidate 角色
r.setState(Candidate)
return
}
}
case <-r.shutdownCh:
// 收到退出信号
return
}
}
}processRPC 用来接收处理来自其他节点 RPC 请求, follower、candidate、leader 三者都可处理下面类型的 RPC 请求.
代码上 hashicorp/raft 没有区分各个角色的 rpc 请求方法, 而是统一做处理, 这样代码看起来复杂了一些.
// processRPC is called to handle an incoming RPC request. This must only be
// called from the main thread.
func (r *Raft) processRPC(rpc RPC) {
// 检测 header 中的 proto 版本.
if err := r.checkRPCHeader(rpc); err != nil {
rpc.Respond(nil, err)
return
}
switch cmd := rpc.Command.(type) {
case *AppendEntriesRequest:
// 处理日志同步请求
r.appendEntries(rpc, cmd)
case *RequestVoteRequest:
// 处理投票请求
r.requestVote(rpc, cmd)
case *InstallSnapshotRequest:
// 处理快照安装请求
r.installSnapshot(rpc, cmd)
case *TimeoutNowRequest:
// 超时请求
r.timeoutNow(rpc, cmd)
default:
// 未知的请求命令, 返回错误.
rpc.Respond(nil, fmt.Errorf("unexpected command"))
}
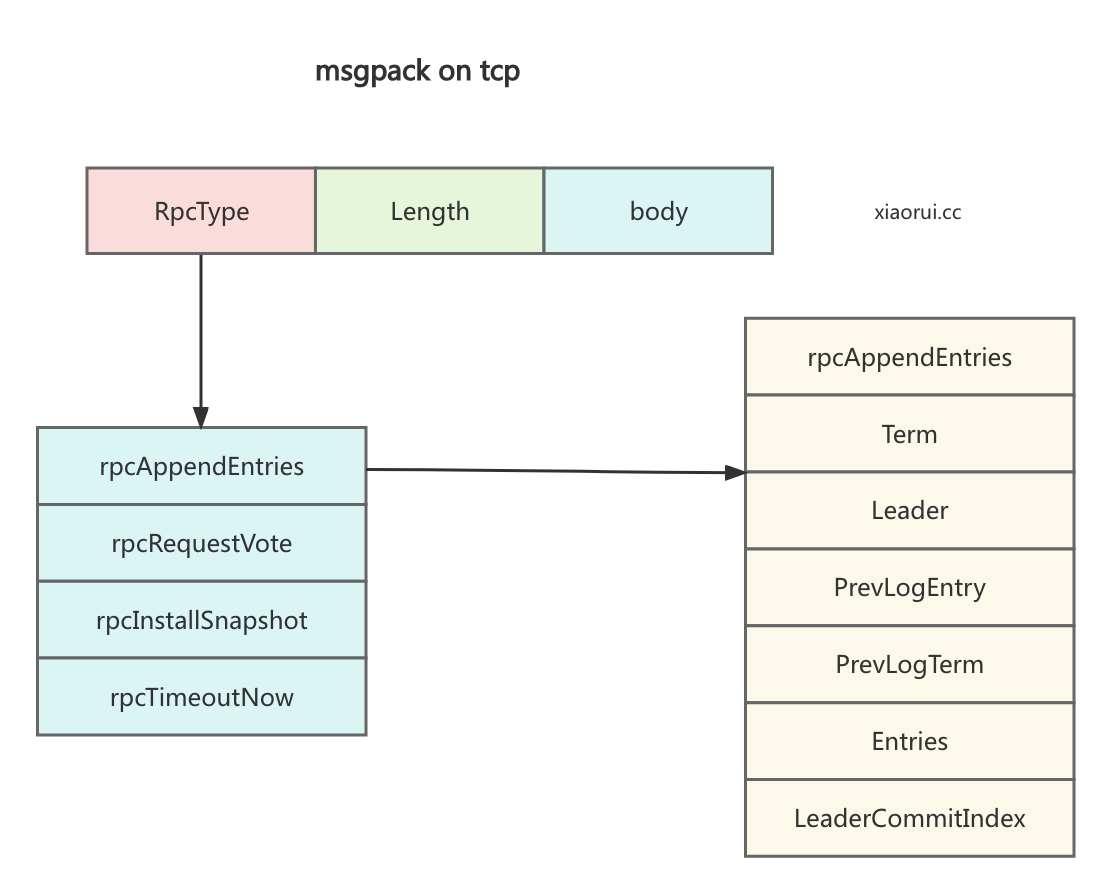
}hashicorp raft server/client 是使用 msgpack on tcp 实现的 rpc 服务, 关于 hashcrop raft transport server/client 的实现原理没什么可深入的, 请直接看代码实现. msgpack rpc 的协议报文格式如下.
// requestVote is invoked when we get a request vote RPC call.
func (r *Raft) requestVote(rpc RPC, req *RequestVoteRequest) {
r.observe(*req)
// 实例化 vote response 结构体.
resp := &RequestVoteResponse{
RPCHeader: r.getRPCHeader(),
Term: r.getCurrentTerm(),
Granted: false,
}
var rpcErr error
defer func() {
// 当方法退出时, 返回 vote response 结果..
rpc.Respond(resp, rpcErr)
}()
// Version 0 servers will panic unless the peers is present. It's only
// used on them to produce a warning message.
if r.protocolVersion < 2 {
resp.Peers = encodePeers(r.configurations.latest, r.trans)
}
// 从 req header 中获取 candidate 信息.
var candidate ServerAddress
var candidateBytes []byte
if len(req.RPCHeader.Addr) > 0 {
candidate = r.trans.DecodePeer(req.RPCHeader.Addr)
candidateBytes = req.RPCHeader.Addr
} else {
candidate = r.trans.DecodePeer(req.Candidate)
candidateBytes = req.Candidate
}
// 如果 candidate id 不在 config servers 集合里, 则不进行投票. 我们要确保节点在 config server 集合里.
if len(req.ID) > 0 {
candidateID := ServerID(req.ID)
if len(r.configurations.latest.Servers) > 0 && !inConfiguration(r.configurations.latest, candidateID) {
return
}
}
// 如果已经有一个 leader, 但当前记录的 leader 跟发送 vote 请求的 candidate 不是一个, 则进行拒绝投票.
if leaderAddr, leaderID := r.LeaderWithID(); leaderAddr != "" && leaderAddr != candidate && !req.LeadershipTransfer {
r.logger.Warn("rejecting vote request since we have a leader",
"from", candidate,
"leader", leaderAddr,
"leader-id", string(leaderID))
return
}
// 如果请求的 term 任期比当期那小, 则直接拒绝投票.
if req.Term < r.getCurrentTerm() {
return
}
// 如果请求的 term 任期大于当前的 term, 则配置请求的 term为当前的 term.
if req.Term > r.getCurrentTerm() {
r.setState(Follower)
r.setCurrentTerm(req.Term)
resp.Term = req.Term
}
// 如果请求的 candidate 不是 voter, 那么直接拒绝投票. 这个 case 比较发杂, 请直接看这个 issue.
// https://github.com/hashicorp/raft/pull/526
if len(req.ID) > 0 {
candidateID := ServerID(req.ID)
if len(r.configurations.latest.Servers) > 0 && !hasVote(r.configurations.latest, candidateID) {
r.logger.Warn("rejecting vote request since node is not a voter", "from", candidate)
return
}
}
// 从持久化存储中获取上次的投票的 term 任期, 默认为 0.
lastVoteTerm, err := r.stable.GetUint64(keyLastVoteTerm)
if err != nil && err.Error() != "not found" {
// 访问失败, 则直接拒绝投票.
return
}
// 从持久化存储中获取上次投票的 candidate 信息.
lastVoteCandBytes, err := r.stable.Get(keyLastVoteCand)
if err != nil && err.Error() != "not found" {
// 访问失败, 则直接拒绝投票.
return
}
// 如果上次的投票 term 跟请求 term 一样, 且 candidate 也一致, 则进行投票成功.
if lastVoteTerm == req.Term && lastVoteCandBytes != nil {
r.logger.Info("duplicate requestVote for same term", "term", req.Term)
// 上次和请求的 candidate 一致, 则投票成功.
if bytes.Compare(lastVoteCandBytes, candidateBytes) == 0 {
r.logger.Warn("duplicate requestVote from", "candidate", candidate)
resp.Granted = true
}
return
}
// 获取当前节点中上最新的 index 和 term.
lastIdx, lastTerm := r.getLastEntry()
// 如果当前的日志的 term 比请求的上次 term 大, 则说明当前 follower 的 term 更大更新, 则拒绝投票.
if lastTerm > req.LastLogTerm {
r.logger.Warn("rejecting vote request since our last term is greater",
"candidate", candidate,
"last-term", lastTerm,
"last-candidate-term", req.LastLogTerm)
return
}
// 如果当前日志的 term 跟 请求的上次 term 一样, 但日志 index 更新, 则说明当前 follower 的日志更新, 拒绝投票.
if lastTerm == req.LastLogTerm && lastIdx > req.LastLogIndex {
r.logger.Warn("rejecting vote request since our last index is greater",
"candidate", candidate,
"last-index", lastIdx,
"last-candidate-index", req.LastLogIndex)
return
}
// 持久化当前的投票结果.
if err := r.persistVote(req.Term, candidateBytes); err != nil {
// 如果保存 vote 失败, 说明当前节点持久化发生异常了, 直接返回异常.
return
}
// 配置投票成功.
resp.Granted = true
// 配置最近联系时间
r.setLastContact()
return
}appendEntries() 用来处理来自 leader 发起的 appendEntries 请求. 首先判断请求的日志是否合法, 合法则保存日志, 然后 processLogs 应用日志.
如果请求的上条日志跟本实例最新日志不一致, 则返回失败. 而 leader 会根据 follower 返回结果, 获取 follower 最新的 log term 及 index, 然后再同步给 follower 缺失的日志.
简单说 appendEntries() 同步日志是 leader 和 follower 不断调整位置再同步数据的过程.
下一篇讲 hashicorp/raft replicate 同步日志时, 详细分析其实现原理.
// appendEntries is invoked when we get an append entries RPC call. This must
// only be called from the main thread.
func (r *Raft) appendEntries(rpc RPC, a *AppendEntriesRequest) {
// Setup a response
// 实例化返回结构
resp := &AppendEntriesResponse{
RPCHeader: r.getRPCHeader(),
Term: r.getCurrentTerm(),
LastLog: r.getLastIndex(),
Success: false,
NoRetryBackoff: false,
}
var rpcErr error
defer func() {
rpc.Respond(resp, rpcErr)
}()
// 如果请求的 term 比当前的小, 则直接忽略.
if a.Term < r.getCurrentTerm() {
return
}
// 如果请求的 term 比当前 term 大或者当前不是 follower 状态, 则切到 follower 角色. 并且更新当前 term.
if a.Term > r.getCurrentTerm() || (r.getState() != Follower && !r.candidateFromLeadershipTransfer) {
r.setState(Follower)
r.setCurrentTerm(a.Term)
resp.Term = a.Term
}
// 在当前节点保存 leader 信息.
if len(a.Addr) > 0 {
r.setLeader(r.trans.DecodePeer(a.Addr), ServerID(a.ID))
} else {
r.setLeader(r.trans.DecodePeer(a.Leader), ServerID(a.ID))
}
// 检查对比请求的上一条 prev 日志跟本地日志的 index 和 term 是否一样,
// 不一致, 则说明缺失了多条日志.
if a.PrevLogEntry > 0 {
lastIdx, lastTerm := r.getLastEntry()
var prevLogTerm uint64
if a.PrevLogEntry == lastIdx {
prevLogTerm = lastTerm
} else {
var prevLog Log
if err := r.logs.GetLog(a.PrevLogEntry, &prevLog); err != nil {
return
}
prevLogTerm = prevLog.Term
}
// 如果请求体中上次 term 跟当前 term 不一致, 则直接写失败.
if a.PrevLogTerm != prevLogTerm {
return
}
}
// 把日志持久化到本地
if len(a.Entries) > 0 {
// ...
// 清理冲突的日志
// 保存日志到本地
}
// 更新并提交日志到 FSM
if a.LeaderCommitIndex > 0 && a.LeaderCommitIndex > r.getCommitIndex() {
// 求最小
idx := min(a.LeaderCommitIndex, r.getLastIndex())
r.setCommitIndex(idx)
// 把 commitIndex 之前的日志提交到状态机 FSM 进行应用日志.
r.processLogs(idx, nil)
}
// 处理成功
resp.Success = true
r.setLastContact()
return
}
runCandidate 为候选者的核心处理方法, 其大概流程如下.
- 首先会把当前的实例的 term 任期号递增加一.
- 然后创建一个 electionTimer 随机定时器, 时间在 1000ms - 2000ms 之间.
- 接着调用
electSelf()方法对各节点发起选举请求, 本节点默认投票成功, 其他节点则需要发起 requestVote 请求. - 计算出选举成功的法定的投票数
votesNeeded, 计算公式为n/2 + 1, 然后监听 electSelf 返回各节点的投票结果. - 当拿到的投票数满足法定投票数
votesNeeded则调用setState(Leader)换成 leader 领导者角色. - 如果在
electionTimer时间内未拿到法定的投票数, 则直接 return 退出, 由 raft.run 主调度再次切入到 runCandidate 方法, 再次发起选举.
// runCandidate runs the main loop while in the candidate state.
func (r *Raft) runCandidate() {
// 把当前的 term 时间周期加一.
term := r.getCurrentTerm() + 1
r.logger.Info("entering candidate state", "node", r, "term", term)
// 启动选举投票, 并配置一个超时.
voteCh := r.electSelf()
defer func() { r.candidateFromLeadershipTransfer = false }()
// 选举的超时时间, 随机的时间范围在 1000ms - 20000ms 以内, electionTimeout 默认为 10000ms, 跟心跳时间超时一样.
electionTimeout := r.config().ElectionTimeout
electionTimer := randomTimeout(electionTimeout)
// 拿到的投票数, 初始化为 0.
grantedVotes := 0
// 计算出选举成功需要拿到投票数, 计算规则是 `n/2 + 1`
votesNeeded := r.quorumSize()
// 循环遍历
for r.getState() == Candidate {
r.mainThreadSaturation.sleeping()
select {
case rpc := <-r.rpcCh:
r.mainThreadSaturation.working()
// 处理 rpc 请求.
r.processRPC(rpc)
case vote := <-voteCh:
r.mainThreadSaturation.working()
// 接收其他节点发来的投票结果
// 如果收到的投票结果 term 任期比当前 term 大, 则 candidate 退化为 follower 角色, 并更新 term.
if vote.Term > r.getCurrentTerm() {
r.setState(Follower)
r.setCurrentTerm(vote.Term)
return
}
// 如果收到的投票状态为成功, 则更新 grantedVotes 计数.
if vote.Granted {
grantedVotes++
}
// 如果当前的拿到的投票数满足选举的要求, 则更新状态为 leader, 并配置 leader 信息.
if grantedVotes >= votesNeeded {
r.logger.Info("election won", "term", vote.Term, "tally", grantedVotes)
r.setState(Leader)
r.setLeader(r.localAddr, r.localID)
return
}
case c := <-r.configurationChangeCh:
r.mainThreadSaturation.working()
// Reject any operations since we are not the leader
c.respond(ErrNotLeader)
case a := <-r.applyCh:
// 不是 leader 时, 拒绝处理写请求.
a.respond(ErrNotLeader)
case v := <-r.verifyCh:
// 不是 leader 时, 拒绝处理验证.
v.respond(ErrNotLeader)
case ur := <-r.userRestoreCh:
// 不是 leader 时, 拒绝处理还原逻辑.
ur.respond(ErrNotLeader)
case l := <-r.leadershipTransferCh:
// 不是 leader 时, 拒绝处理变更.
l.respond(ErrNotLeader)
...
case <-r.leaderNotifyCh:
// Ignore since we are not the leader
case <-r.followerNotifyCh:
// 如果 electionTimeout 值发生变更, 则重新实例化超时时间并构建超时定时器.
if electionTimeout != r.config().ElectionTimeout {
electionTimeout = r.config().ElectionTimeout
electionTimer = randomTimeout(electionTimeout)
}
case <-electionTimer:
// election timer 超时则说明在该时间周期内, 未拿到指定数量的投票, 跳出后重新选举.
return
case <-r.shutdownCh:
// 退出
return
}
}
}遍历配置中的 server 集合, 过滤出状态为 Voter 的 server, 最后通过 n/2 + 1 公式计算出法定投票数, 简单说就是绝大多数的节点数量.
3 个节点的 quorum 为 2, 4 个节点 quorum 为 3, 5 个节点那么 quorum 为 3 个.
func (r *Raft) quorumSize() int {
voters := 0
for _, server := range r.configurations.latest.Servers {
// 过滤出 Voter
if server.Suffrage == Voter {
voters++
}
}
return voters/2 + 1
}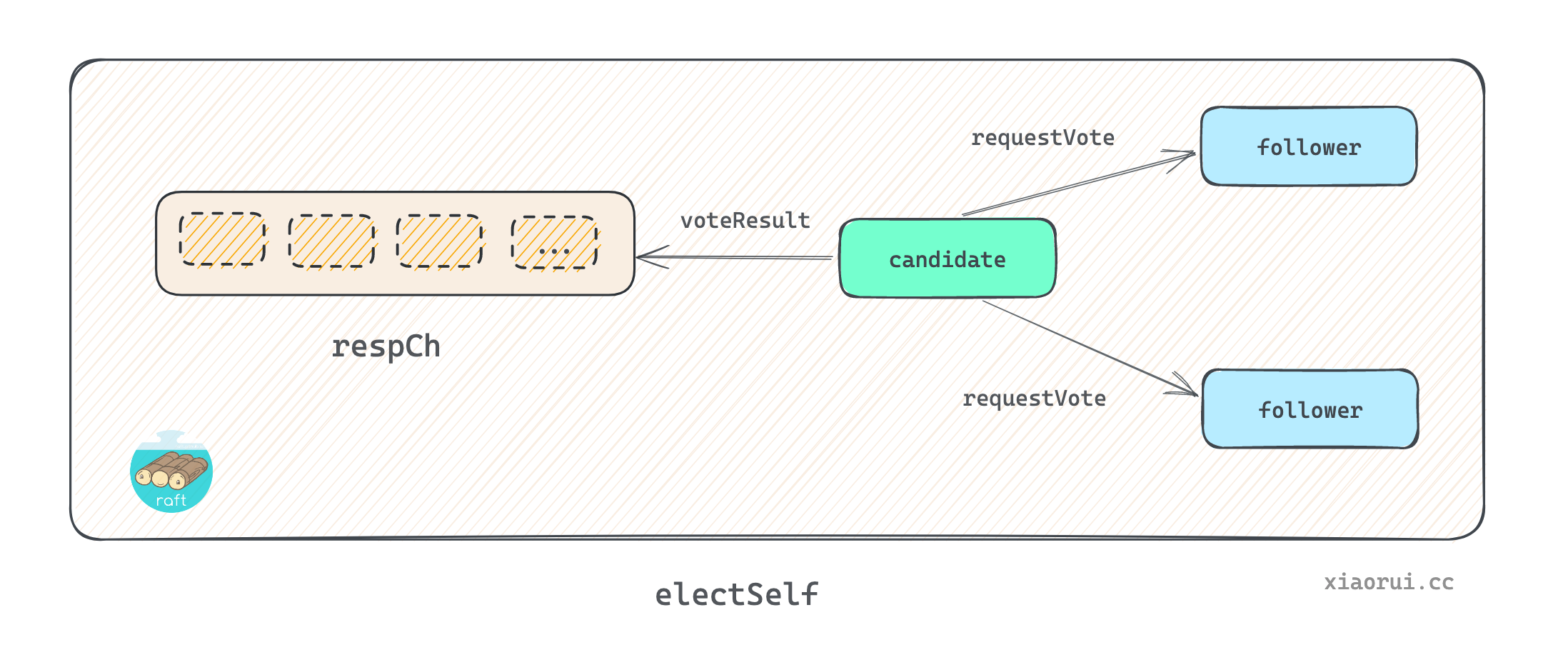
electSelf() 方法用来发起 raft 的选举. 首先需要当前实例的 term 任期递增加一, 获取本地最近日志的 index 和 term, 跟当前 term 和 candidate 字段一起构建 vote 请求体. 遍历配置中的 server, 对本地的 server 直接构建一个成功状态的投票对象, 对其他 server 则需要发起 requestVote 投票请求. 把投票结果对象扔到 respCh 管道里.
vote 是需要安全持久化本地的, 这样当 follower 发生 crash 重启后, 可以获取上次的投票状态. 当收到投票请求的 candidate 和 term 跟 stable 存储一致, 则直接返回.
// electSelf is used to send a RequestVote RPC to all peers, and vote for
// ourself. This has the side affecting of incrementing the current term. The
// response channel returned is used to wait for all the responses (including a
// vote for ourself). This must only be called from the main thread.
func (r *Raft) electSelf() <-chan *voteResult {
// 创建接收 vote 投票结果的管道, 该 chan 由 runCandidate 来监听.
respCh := make(chan *voteResult, len(r.configurations.latest.Servers))
// 增加 term 任期号.
r.setCurrentTerm(r.getCurrentTerm() + 1)
// 获取最近一条的日志的 index 索引号和 term 任期号.
lastIdx, lastTerm := r.getLastEntry()
// 构建 vote 请求结构体
req := &RequestVoteRequest{
// 构建 header 结构, 内置当前节点的 id 和 addr.
RPCHeader: r.getRPCHeader(),
Term: r.getCurrentTerm(),
Candidate: r.trans.EncodePeer(r.localID, r.localAddr),
LastLogIndex: lastIdx,
LastLogTerm: lastTerm,
LeadershipTransfer: r.candidateFromLeadershipTransfer,
}
// 向 peer 对端 server 发起投票请求.
askPeer := func(peer Server) {
// 异步执行
r.goFunc(func() {
// 构建结果对象.
resp := &voteResult{voterID: peer.ID}
// trans 维护了各个 server 的 client 客户端, 通过 RequestVote 发起请求.
err := r.trans.RequestVote(peer.ID, peer.Address, req, &resp.RequestVoteResponse)
if err != nil {
// 如果出现各种异常错误, 也算失败, 需要设置 Granted 为 false.
resp.Term = req.Term
resp.Granted = false
}
// 把结果塞到 respCh 管道里.
respCh <- resp
})
}
// 遍历各个节点, 并发对各个节点进行投票请求.
for _, server := range r.configurations.latest.Servers {
if server.Suffrage == Voter {
// 如果遍历的 server 是本地节点.
if server.ID == r.localID {
r.logger.Debug("voting for self", "term", req.Term, "id", r.localID)
// 持久化投票到本地存储.
if err := r.persistVote(req.Term, req.RPCHeader.Addr); err != nil {
return nil
}
// 构建投票结果对象, 传递到 respCh 管道里.
respCh <- &voteResult{
RequestVoteResponse: RequestVoteResponse{
RPCHeader: r.getRPCHeader(),
Term: req.Term,
Granted: true,
},
voterID: r.localID,
}
} else {
// 遍历的节点不是本地, 则需要发起 rpc 请求.
r.logger.Debug("asking for vote", "term", req.Term, "from", server.ID, "address", server.Address)
askPeer(server)
}
}
}
return respCh
}runLeader 为 leader 领导者的核心处理方法. 进入该函数说明当前节点为 leader.
startStopReplication启动各个 follower 的 replication, 开启心跳 heartbeat 和同步 replicate 协程.- 构建一个 LogNoop 空日志, 然后通过
dispatchLogs方法发给所有的 follower 副本. 这里的空日志用来向 follower 通知确认 leader, 并获取各 follower 的一些日志元信息. leaderLoop为 leader 的主调度循环.
// runLeader runs the main loop while in leader state. Do the setup here and drop into
// the leaderLoop for the hot loop.
func (r *Raft) runLeader() {
r.logger.Info("entering leader state", "leader", r)
// 通知 leader 状态, 查看代码引用关系, 可以确定只是用在单元测试.
overrideNotifyBool(r.leaderCh, true)
// 当前为 leader, 则进行信号通知
notify := r.config().NotifyCh
if notify != nil {
select {
case notify <- true:
case <-r.shutdownCh:
}
}
// 配置 leader 状态.
r.setupLeaderState()
// 用来实现关闭通知.
stopCh := make(chan struct{})
// 开启一个后台协程周期性 10秒在 metrics 中更新 leader age 生存时间.
go emitLogStoreMetrics(r.logs, []string{"raft", "leader"}, oldestLogGaugeInterval, stopCh)
// 退出时进行状态收尾.
defer func() {
// 关闭管道
close(stopCh)
...
r.setLastContact()
// 遍历关闭各个 replication 同步副本.
for _, p := range r.leaderState.replState {
close(p.stopCh)
}
// 清理 leader state 状态字段
r.leaderState.commitCh = nil
r.leaderState.commitment = nil
r.leaderState.inflight = nil
r.leaderState.replState = nil
r.leaderState.notify = nil
r.leaderState.stepDown = nil
r.leaderLock.Lock()
// 清空 leaderAddr 和 leaderID 字段.
if r.leaderAddr == r.localAddr && r.leaderID == r.localID {
r.leaderAddr = ""
r.leaderID = ""
}
r.leaderLock.Unlock()
// 通知当前实例也不是 Leader, 主要用来单元测试.
overrideNotifyBool(r.leaderCh, false)
// 这里已经不是 leader, 进行信号通知.
if notify != nil {
select {
case notify <- false:
...
}
}
}()
// 启动各个 replication 的后台协程.
r.startStopReplication()
// 构建一个空日志, 然后对所有 follower 发起请求, follower 也确认 leader 信息, 获取各个 follower 的log index, comit index 等元信息.
noop := &logFuture{log: Log{Type: LogNoop}}
r.dispatchLogs([]*logFuture{noop})
// 运行 leader 自循环逻辑.
r.leaderLoop()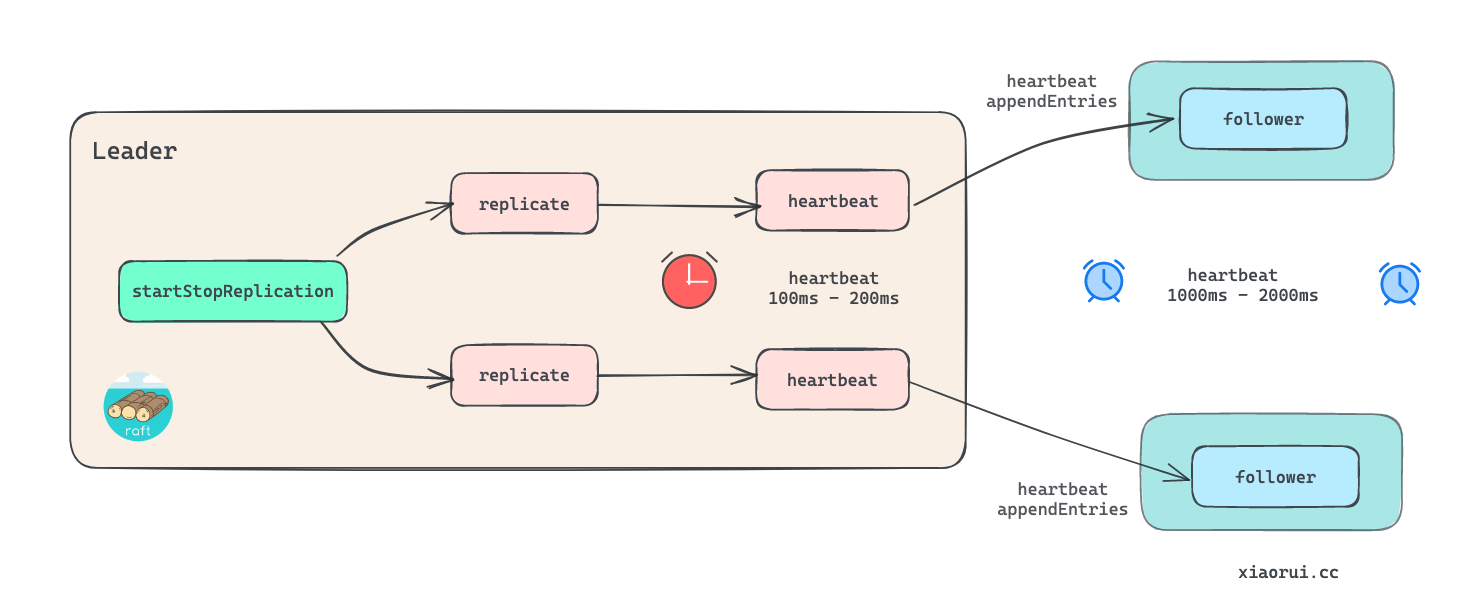
startStopReplication 为各个 follower 实例化 followerReplication 对象, 然后分别启动 replicate 协程.
replication 涉及到的逻辑会不少, 这里先只关注 heartbeat 心跳逻辑. 每个 replication 都会启动一个 heartbeat 协程, 其内部会创建一个随机值为 100ms - 200ms 区间的心跳定时器, 每当该心跳定时器到期时, 使用 AppendEntries RPC 对 follower 发起心跳请求, 这里不携带日志, 只携带 term 任期及 leader 领导者信息.
为什么需要 leader 给 follower 发送心跳 ? raft 论文里有说明, 当 follower 在一段时间内收不到 leader 的心跳请求时, 则判定 leader 有异常, 切换到 candidate 进行选举 election.
值得注意的是 follower 的重新选举的心跳超时间为 1000ms - 2000ms, 而 leader 给 follower 发送心跳请求的间隔为 100ms - 200ms. 发心跳的时间间隔必然要远小于 follower 重新选举的心跳间隔, 另外通常同一个内网下两台服务器的网络时延在 1ms 以内.
func (r *Raft) startStopReplication() {
for _, server := range r.configurations.latest.Servers {
// server 为本实例无需启动 replication 复制副本.
if server.ID == r.localID {
continue
}
s, ok := r.leaderState.replState[server.ID]
if !ok {
s = &followerReplication{
...
}
r.leaderState.replState[server.ID] = s
// 启动 replication 复制副本
r.goFunc(func() { r.replicate(s) })
}
}
}
func (r *Raft) replicate(s *followerReplication) {
...
// 启动一个 heartbeat 心跳协程
r.goFunc(func() { r.heartbeat(s, stopHeartbeat) })
...
...
}
func (r *Raft) heartbeat(s *followerReplication, stopCh chan struct{}) {
// ...
req := AppendEntriesRequest{
RPCHeader: r.getRPCHeader(),
// 只需要携带当前 term 就可以.
Term: s.currentTerm,
Leader: r.trans.EncodePeer(r.localID, r.localAddr),
}
var resp AppendEntriesResponse
for {
select {
case <-randomTimeout(r.config().HeartbeatTimeout / 10):
// 发送心跳的间隔为 100ms - 200ms, HeartbeatTimeout 为 1000ms.
case <-stopCh:
return
}
s.peerLock.RLock()
peer := s.peer
s.peerLock.RUnlock()
// 调用 trans peer 的客户端对象进行 appendEntries rpc 请求.
if err := r.trans.AppendEntries(peer.ID, peer.Address, &req, &resp); err != nil {
// ...
select {
case <-time.After(nextBackoffTime):
// 当出现访问失败时, 进行退避等待.
case <-stopCh:
return
}
}
// ...
}
}dispatchLogs 用来记录本地日志以及派发日志给所有的 follower.
- 把日志先写到本地里.
- commitment.match 来计算各个 server 的 matchIndex, 计算出 commit 提交索引.
- 记录当前的日志的信息.
- 把请求的日志通知给所有的 replication 同步副本.
// dispatchLog is called on the leader to push a log to disk, mark it
// as inflight and begin replication of it.
func (r *Raft) dispatchLogs(applyLogs []*logFuture) {
// 获取当前最新的 term 任期和日志索引.
term := r.getCurrentTerm()
lastIndex := r.getLastIndex()
n := len(applyLogs)
logs := make([]*Log, n)
for idx, applyLog := range applyLogs {
applyLog.dispatch = now
lastIndex++
// raft log index 是全局单调递增的, 所以对遍历的日志加一.
applyLog.log.Index = lastIndex
applyLog.log.Term = term
applyLog.log.AppendedAt = now
logs[idx] = &applyLog.log
r.leaderState.inflight.PushBack(applyLog)
}
// 把日志写到本地存储里 storage, 先写到本地, 再发给其他 follower.
if err := r.logs.StoreLogs(logs); err != nil {
r.logger.Error("failed to commit logs", "error", err)
for _, applyLog := range applyLogs {
// 遍历返回错误
applyLog.respond(err)
}
// 如果写本地日志失败, 则直接切换状态为 follower.
r.setState(Follower)
return
}
// 计算 matchIndex
r.leaderState.commitment.match(r.localID, lastIndex)
// 记录当前的日志的信息.
r.setLastLog(lastIndex, term)
// 把请求的日志通知给所有的 replication 同步副本.
for _, f := range r.leaderState.replState {
asyncNotifyCh(f.triggerCh)
}
}关于 followerReplication 同步数据的详细会在下一篇做源码和原理的分析, 简单说通知信号给 replication, replication 收到信号后, 通过 nextIndex 和 lastIndex 拿到新增的日志集合, 然后通过 transport 发起 appendEntries rpc 请求.
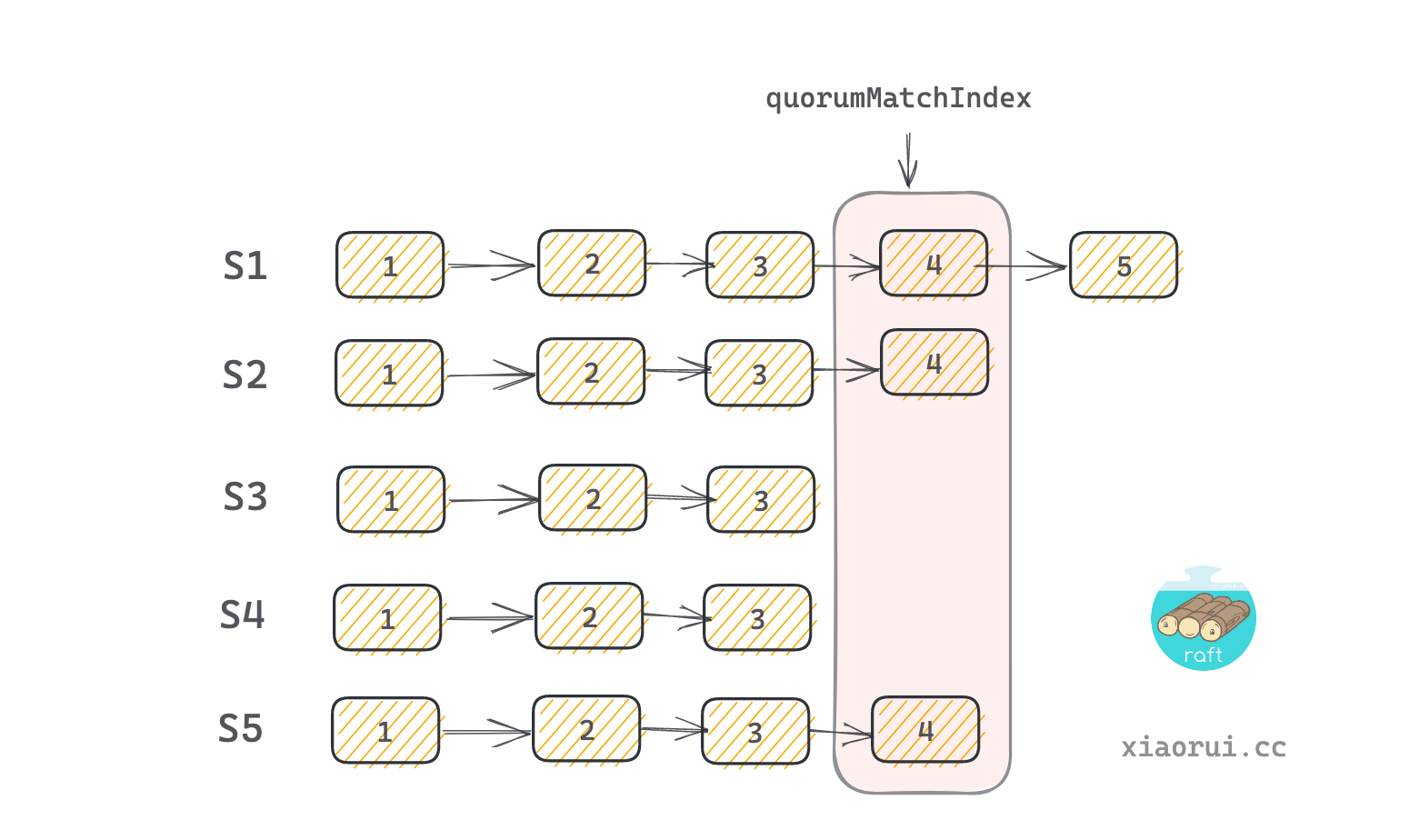
match 通过计算各个 server 的 matchIndex 计算出 commitIndex. commitIndex 可以理解为法定的提交索引值. 对所有 server 的 matchIndex 进行排序, 然后使用 matched[(len(matched)-1)/2] 值作为 commitIndex. 这样比 commitIndex 小的 log index 会被推到 commitCh 管道里. 后面由 leaderLoop 进行消费, 然后调用 fsm 状态机进行应用日志.
func (c *commitment) match(server ServerID, matchIndex uint64) {
c.Lock()
defer c.Unlock()
// 如果传入的 server 已投票, 另外 index 大于上一个记录的 index, 则更新 matchIndex.
if prev, hasVote := c.matchIndexes[server]; hasVote && matchIndex > prev {
c.matchIndexes[server] = matchIndex
// 重新计算
c.recalculate()
}
}
func (c *commitment) recalculate() {
// 需要重计算, 但还未初始化 matchIndex 数据时, 直接退出.
if len(c.matchIndexes) == 0 {
return
}
// 构建一个容器存放各个 server 的 index.
matched := make([]uint64, 0, len(c.matchIndexes))
for _, idx := range c.matchIndexes {
matched = append(matched, idx)
}
// 对整数切片进行排序, 从小到大正序排序
sort.Sort(uint64Slice(matched))
// 找到 quorum match index 点. 比如 [1 2 3 4 5], 那么 2 为 quorumMatchIndex 法定判断点.
quorumMatchIndex := matched[(len(matched)-1)/2]
// 如果法定判断点大于当前的提交点, 并且法定点大于 first index, 则更新 commitIndex 和通知 commitCh.
if quorumMatchIndex > c.commitIndex && quorumMatchIndex >= c.startIndex {
c.commitIndex = quorumMatchIndex
// 给 commitCh 发送通知, 该 chan 由 leaderLoop 来监听处理.
asyncNotifyCh(c.commitCh)
}
}leader commit 提交哪些日志 ?
提交大部分 follower 已存在的日志. 只有提交的日志才能应用到状态机 FSM 里, 然后状态机调用上层注册的回调方法来处理日志.
关于 hashicorp raft 选举的实现原理分析完了, 其正常流程是这样, 初始阶段为 follower, 在时间窗口内没有获取到 leader 的确认请求, 则切换到 candidate 发起选举, 当收到大多数节点的投票 (n/2 + 1) 时, 切换到 leader 角色, leader 不仅处理读写请求, 且定时给 follower 发送心跳.
关于其他各种异常下的处理, 这里就不再复述, 请直接看正文中的源码分析. 另外 hashicorp raft 作为 raft 一致性协议的工程实践, 其内部还是做了一些的优化.