本文基于 hashicorp/raft
v1.3.11版本进行源码分析
raft snapshot 快照是用来归档 raft log, 避免 raft log 太大造成读写性能和空间占用问题.
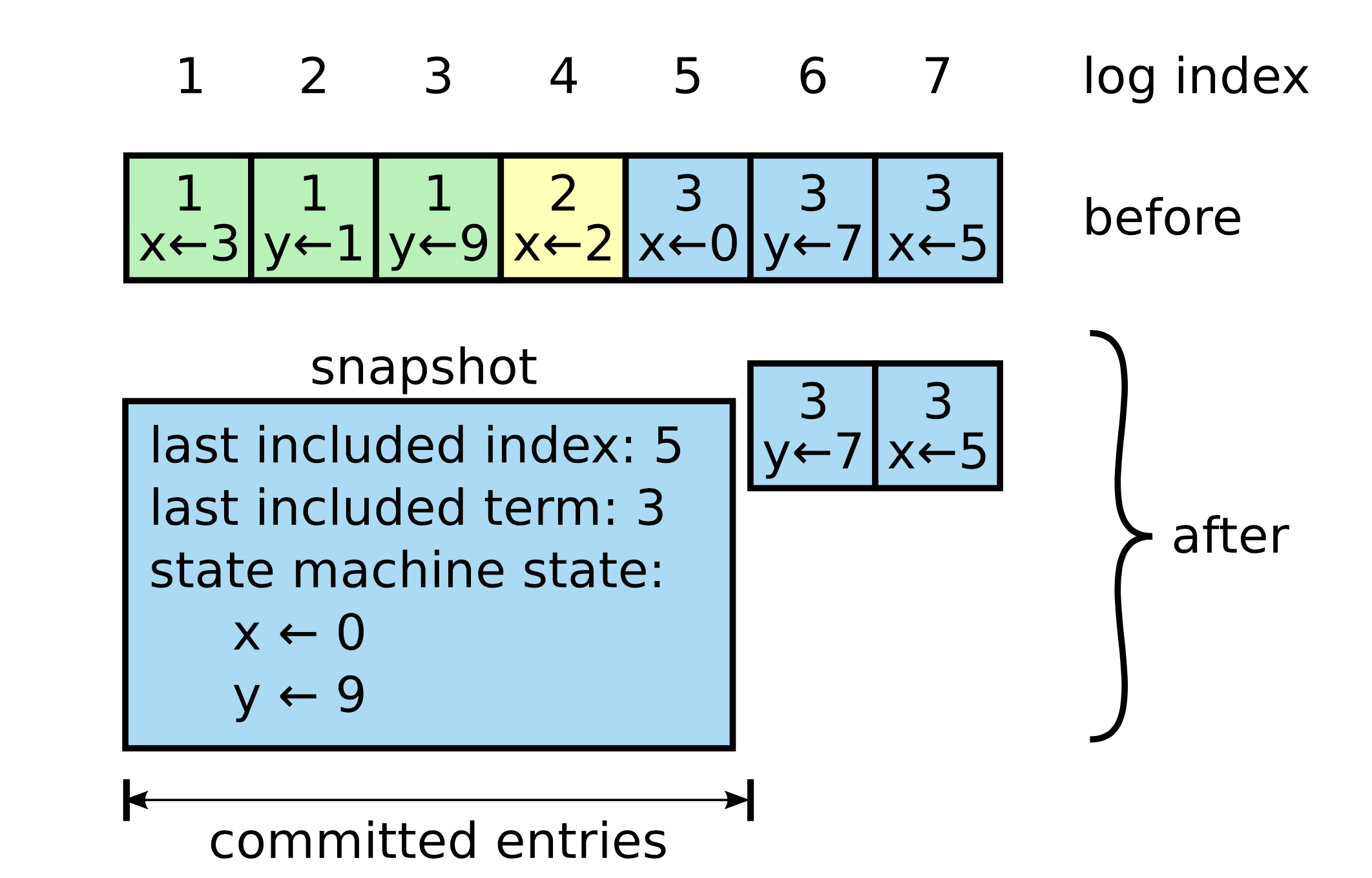
如下图, 按照 raft 策略生成快照文件, 对 raft log 中的 index 1 -> 5 生成快照后, 快照中只有两个值 x=0, y=9. 当一个新 follower 加入集群或者 follower 需要同步的日志已经被归档到 snapshot 快照中, 这时候需要先同步全量数据, 这里指的是快照文件, 之后, 再进行日志的复制同步.
golang hashicorp raft 原理系列
- 源码分析 hashicorp raft election 选举的设计实现原理
- 源码分析 hashicorp raft replication 日志复制的实现原理
- 源码分析 hashicorp raft 持久化存储的实现原理
- 源码分析 hashicorp raft snapshot 快照的实现原理
hashicorp raft 在启动时会启动三个协程, 其一就是 runSnapshots 协程, 该协程用来监听用户的快照请求和定时器, 判断是否需要快照, 当 log 超过阈值或者用户主动提交快照时, 进行执行快照.
func (r *Raft) runSnapshots() {
for {
select {
// 随机定时器 120s - 240s
case <-randomTimeout(r.config().SnapshotInterval):
// 判断是否需要执行快照.
if !r.shouldSnapshot() {
continue
}
// 执行快照
if _, err := r.takeSnapshot(); err != nil {
r.logger.Error("failed to take snapshot", "error", err)
}
case future := <-r.userSnapshotCh:
// 用户上层触发, 执行快照操作.
id, err := r.takeSnapshot()
if err != nil {
r.logger.Error("failed to take snapshot", "error", err)
} else {
// 注册 opener 方法, 指定 snapshot id.
future.opener = func() (*SnapshotMeta, io.ReadCloser, error) {
return r.snapshots.Open(id)
}
}
// 返回
future.respond(err)
case <-r.shutdownCh:
return
}
}
}shouldSnapshot 用来判断是否满足快照阈值, 计算方法是当前最新日志 index 跟上次快照的 index 相减是否超过了 SnapshotThreshold 阈值, 默认阈值为 8192. 但这个值太小了, 工厂上来说, 该值最少要 10w, 因为执行快照阈值太小, 在写请求密集下, 意味着需要频繁的执行快照, 快照执行成本不低的. 另外当 follower 由于一些原因没及时同步 raft log, 如果由于阈值太小已经被归档快照了, 那么这时候需要执行快照传输, 及快照还原的重逻辑.
// 判断是否满足需要快照的条件
func (r *Raft) shouldSnapshot() bool {
// 获取最新 snapshot 对象
lastSnap, _ := r.getLastSnapshot()
// 获取最新的 index
lastIdx, err := r.logs.LastIndex()
if err != nil {
return false
}
// 如果差值超过了 SnapshotThreshold, 则需要进行快照.
delta := lastIdx - lastSnap
return delta >= r.config().SnapshotThreshold
}
takeSnapshot 用来真正的创建新的快照, 其逻辑是首先用 snapshots.Create 创建 sink 输出对象, 然后调用 Persist 对 sink 进行持久化. 最后需要调用 compactLogs 用删除已经快照的日志数据, 毕竟 log 文件的磁盘空间不断增长.
func (r *Raft) takeSnapshot() (string, error) {
snapReq := &reqSnapshotFuture{}
snapReq.init()
select {
case r.fsmSnapshotCh <- snapReq:
// 传递一个 snapshot 请求到队列中, 该管道由 runFSM 来监听处理, 最后执行的方法是 fsm.Snapshot().
case <-r.shutdownCh:
return "", ErrRaftShutdown
}
// 等待 snapshot 执行完毕, 返回一个 response.
if err := snapReq.Error(); err != nil {
if err != ErrNothingNewToSnapshot {
err = fmt.Errorf("failed to start snapshot: %v", err)
}
return "", err
}
defer snapReq.snapshot.Release()
// 传递 config req
configReq := &configurationsFuture{}
configReq.ShutdownCh = r.shutdownCh
configReq.init()
select {
case r.configurationsCh <- configReq:
case <-r.shutdownCh:
return "", ErrRaftShutdown
}
if err := configReq.Error(); err != nil {
return "", err
}
// 从获取配置中获取 committedIndex
committed := configReq.configurations.committed
committedIndex := configReq.configurations.committedIndex
if snapReq.index < committedIndex {
return "", fmt.Errorf("cannot take snapshot now, wait until the configuration entry at %v has been applied (have applied %v)",
committedIndex, snapReq.index)
}
r.logger.Info("starting snapshot up to", "index", snapReq.index)
start := time.Now()
// 获取版本.
version := getSnapshotVersion(r.protocolVersion)
// 创建 snapshot 相关目录, 创建 meta 和 state 文件, 构建 sink 对象并返回.
sink, err := r.snapshots.Create(version, snapReq.index, snapReq.term, committed, committedIndex, r.trans)
if err != nil {
return "", fmt.Errorf("failed to create snapshot: %v", err)
}
// 调用 persist() 对 snapshot 快照进行持久化.
start = time.Now()
if err := snapReq.snapshot.Persist(sink); err != nil {
sink.Cancel()
return "", fmt.Errorf("failed to persist snapshot: %v", err)
}
// 关闭 sink
if err := sink.Close(); err != nil {
return "", fmt.Errorf("failed to close snapshot: %v", err)
}
// 设置 snapshot 的 log index 和 term.
r.setLastSnapshot(snapReq.index, snapReq.term)
// Compact the logs.
// 计算出需要删除的 log index 范围, 调用 logs DeleteRange 删除.
if err := r.compactLogs(snapReq.index); err != nil {
return "", err
}
r.logger.Info("snapshot complete up to", "index", snapReq.index)
return sink.ID(), nil
}
// 尝试范围删除快照后的日志.
func (r *Raft) compactLogs(snapIdx uint64) error {
defer metrics.MeasureSince([]string{"raft", "compactLogs"}, time.Now())
// 获取当前 LogStore 里第一个 log 的 Index
minLog, err := r.logs.FirstIndex()
if err != nil {
return fmt.Errorf("failed to get first log index: %v", err)
}
// 最新的日志 index
lastLogIdx, _ := r.getLastLog()
// Use a consistent value for trailingLogs for the duration of this method
// call to avoid surprising behaviour.
trailingLogs := r.config().TrailingLogs
if lastLogIdx <= trailingLogs {
return nil
}
// 计算需要删除的最大的日志 log index.
// TrailingLogs 可以理解为延后删除, 快照文件的下一条日志并不是紧跟这 log 的 first, 在 LogStore 保留更多的日志作为缓冲, 可更好的避免由于同步延迟, 造成频繁快照同步的问题.
maxLog := min(snapIdx, lastLogIdx-trailingLogs)
if minLog > maxLog {
// 没什么可以删除的.
return nil
}
r.logger.Info("compacting logs", "from", minLog, "to", maxLog)
// 调用 logs 进行范围删除日志.
if err := r.logs.DeleteRange(minLog, maxLog); err != nil {
return fmt.Errorf("log compaction failed: %v", err)
}
return nil
}在实例化 raft 对象时, 需要传入用户自定的 FSM 状态机接口, 其接口有三个方法 Apply, Snapshot 和 Restore. Apply 用来写数据的接口, 而 Snapshot 和 Restore 都是跟快照相关的接口.
- Snapshot, 构建 FSMSnapshot 对象, 其实现的 Persist 方法可以对快照文件进行落盘写入.
- Restore, 使用快照来还原数据, 该方法不能并发调用, 另外在进行快照恢复时, 需要把先前的状态状态都清理掉.
type FSM interface {
// ...
Apply(*Log) interface{}
// 构建 FSMSnapshot 对象, 可以对快照文件进行写入.
Snapshot() (FSMSnapshot, error)
// 使用快照还原数据, 该方法不能并发调用, 另外进行快照恢复时, 需要把先前的状态状态都清理掉.
Restore(snapshot io.ReadCloser) error
}
type FSMSnapshot interface {
// 使用 sink.Write 对快照进行持久化写入.
Persist(sink SnapshotSink) error
// 当执行完毕后, 调用 release.
Release()
}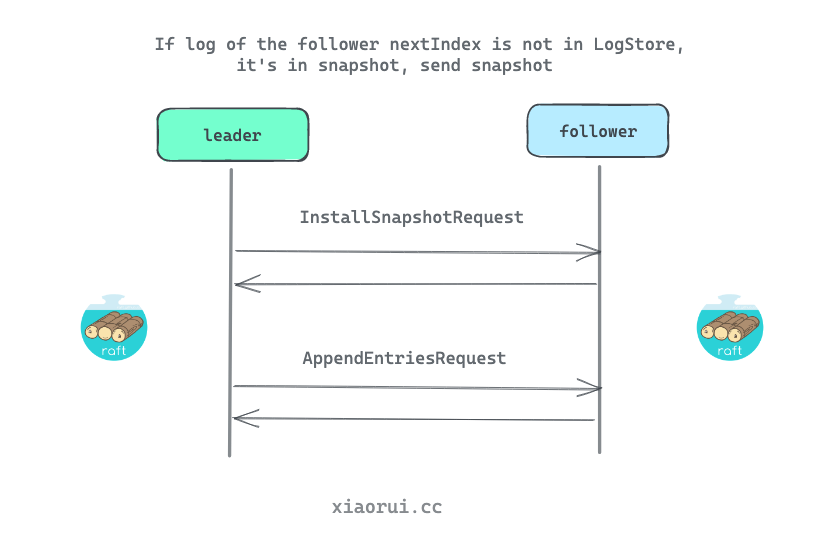
follower 收到 rpc 请求类型为 InstallSnapshotRequest 时, 则调用 installSnapshot 进行快照数据持久化, 然后配合 runFSM 状态机运行期来完成快照文件的数据恢复还原操作.
func (r *Raft) installSnapshot(rpc RPC, req *InstallSnapshotRequest) {
resp := &InstallSnapshotResponse{
Term: r.getCurrentTerm(),
Success: false, // 默认失败
}
var rpcErr error
defer func() {
rpc.Respond(resp, rpcErr)
}()
// ...
version := getSnapshotVersion(r.protocolVersion)
// create 用来初始化 snapshot 的目录及 meta 和 stable 数据, 返回 sink 对象.
sink, err := r.snapshots.Create(version, req.LastLogIndex, req.LastLogTerm,
reqConfiguration, reqConfigurationIndex, r.trans)
if err != nil {
return
}
// 从网络读取数据并写到文件里, 这里使用了 io.copy 做分段拷贝.
countingRPCReader := newCountingReader(rpc.Reader)
transferMonitor := startSnapshotRestoreMonitor(r.logger, countingRPCReader, req.Size, true)
n, err := io.Copy(sink, countingRPCReader)
transferMonitor.StopAndWait()
if err != nil {
sink.Cancel()
return
}
// 如果 size 大小不一致, 则说明有异常, 返回报错.
if n != req.Size {
sink.Cancel()
r.logger.Error("failed to receive whole snapshot",
"received", hclog.Fmt("%d / %d", n, req.Size))
rpcErr = fmt.Errorf("short read")
return
}
// 这里会 sync 同步磁盘, 写 meta 数据, 把临时文件更名为正式文件, 删除旧的快照文件等.
if err := sink.Close(); err != nil {
return
}
r.logger.Info("copied to local snapshot", "bytes", n)
// 构建一个 restore future 对象
future := &restoreFuture{ID: sink.ID()}
future.ShutdownCh = r.shutdownCh
future.init()
select {
case r.fsmMutateCh <- future:
// 把 future 传递给 runFSM 去执行.
case <-r.shutdownCh:
future.respond(ErrRaftShutdown)
return
}
// 等待 future 有回应.
if err := future.Error(); err != nil {
rpcErr = err
return
}
// 更新 info
r.setLastApplied(req.LastLogIndex)
r.setLastSnapshot(req.LastLogIndex, req.LastLogTerm)
r.setLatestConfiguration(reqConfiguration, reqConfigurationIndex)
r.setCommittedConfiguration(reqConfiguration, reqConfigurationIndex)
// 删除已经被归档到快照文件的日志数据.
if err := r.compactLogs(req.LastLogIndex); err != nil {
}
// 逻辑到这里说明, 快照恢复成功.
resp.Success = true
return
}runFSM 里会执行快照的恢复还原操作, 其内部逻辑是收到 restoreFuture 事件类型后, 调用 restore 对数据进行恢复.
func (r *Raft) runFSM() {
// ...
// 快照恢复
restore := func(req *restoreFuture) {
// 打开 snaptshot 对象
meta, source, err := r.snapshots.Open(req.ID)
if err != nil {
req.respond(fmt.Errorf("failed to open snapshot %v: %v", req.ID, err))
return
}
defer source.Close()
// 尝试恢复数据, 内部会调用用户注册的 FSM.Store 方法进行恢复数据.
if err := fsmRestoreAndMeasure(snapLogger, r.fsm, source, meta.Size); err != nil {
// 恢复失败, 则通知失败
req.respond(fmt.Errorf("failed to restore snapshot %v: %v", req.ID, err))
return
}
// 通知已完事
req.respond(nil)
}
for {
select {
case ptr := <-r.fsmMutateCh:
switch req := ptr.(type) {
case []*commitTuple:
// 应用提交的日志
applyBatch(req)
case *restoreFuture:
// 如果收到 restore 请求, 则调用 restore 进行恢复.
restore(req)
}
case req := <-r.fsmSnapshotCh:
...
case <-r.shutdownCh:
return
}
}
}
func fsmRestoreAndMeasure(logger hclog.Logger, fsm FSM, source io.ReadCloser, snapshotSize int64) error {
// 封装了 read size counter 的 io 对象.
crc := newCountingReadCloser(source)
// 调用用户的 fsm.Restore 方法
if err := fsm.Restore(crc); err != nil {
return err
}
return nil
}其原理简单说, 就是把 leader 发送的快照文件给持久化到指定文件路径里, 然后回调用户注册的 FSM.Restore 方法来还原数据.
下面是一个简化的 fsm 样例代码, 一个简单内存的 kv 数据库的场景, 内部使用 map 实现了存储, 快照为一个简单的 json 文件.
Snapshot方法会使用 json 对内存 map 进行序列化, 并调用传入的 sink.Write 对快照数据进行持久化到磁盘.Restore方法会读取 snapshot 快照的 IO.ReadCloser 对象, 在读取后进行反序列化, 最后更新到内存数据库对象里.
package store
import (
"encoding/json"
"fmt"
"io"
"github.com/hashicorp/raft"
)
type fsm Store
func (f *fsm) Apply(l *raft.Log) interface{} {
var c command
if err := json.Unmarshal(l.Data, &c); err != nil {
panic(fmt.Sprintf("failed to unmarshal command: %s", err.Error()))
}
switch c.Op {
case "set":
return f.applySet(c.Key, c.Value)
case "delete":
return f.applyDelete(c.Key)
}
}
func (f *fsm) Snapshot() (raft.FSMSnapshot, error) {
f.mu.Lock()
defer f.mu.Unlock()
o := make(map[string]string)
for k, v := range f.m {
o[k] = v
}
return &fsmSnapshot{store: o}, nil
}
func (f *fsm) Restore(rc io.ReadCloser) error {
o := make(map[string]string)
// 恢复快照文件
if err := json.NewDecoder(rc).Decode(&o); err != nil {
return err
}
f.m = o
return nil
}
func (f *fsm) applySet(key, value string) interface{} {
f.mu.Lock()
defer f.mu.Unlock()
f.m[key] = value
return nil
}
func (f *fsm) applyDelete(key string) interface{} {
f.mu.Lock()
defer f.mu.Unlock()
delete(f.m, key)
return nil
}
type fsmSnapshot struct {
store map[string]string
}
func (f *fsmSnapshot) Persist(sink raft.SnapshotSink) error {
err := func() error {
// 序列化为 []byte
b, err := json.Marshal(f.store)
if err != nil {
return err
}
// 写到磁盘文件里
if _, err := sink.Write(b); err != nil {
return err
}
// 关闭 sink io 对象
return sink.Close()
}()
if err != nil {
sink.Cancel()
}
return err
}
func (f *fsmSnapshot) Release() {}rqlite 是基于 hashicorp/raft 实现的分布式 sqlite 数据库, 先不看它的实现原理, 这里光看下 rqlite 里 Snapshot 和 Restore 的实现原理. 看完后你会有些失望, 因为其快照的实现有些简单.
https://github.com/rqlite/rqlite
func (s *Store) Snapshot() (raft.FSMSnapshot, error) {
defer func() {
s.numSnapshotsMu.Lock()
defer s.numSnapshotsMu.Unlock()
}()
// 锁住库, 把 db 数据
s.queryTxMu.Lock()
defer s.queryTxMu.Unlock()
// 构建 FSMSnapshot 对象, 传入 sqlite db 对象.
fsm := newFSMSnapshot(s.db, s.logger)
// ...
return fsm, nil
}fsmSnapshot 实现了 Persist 方法, 该方法主要实现快照数据的持久化.
func newFSMSnapshot(db *sql.DB, logger *log.Logger) *fsmSnapshot {
fsm := &fsmSnapshot{
startT: time.Now(),
logger: logger,
}
// 把 sqlite db 的数据捞出来序列化到 database []byte 对象里.
fsm.database, _ = db.Serialize()
return fsm
}
// Persist writes the snapshot to the given sink.
func (f *fsmSnapshot) Persist(sink raft.SnapshotSink) error {
err := func() error {
// ...
// 压缩下 database bytes 数据, 这里使用 gzip BestCompression 压缩.
cdb, err := f.compressedDatabase()
if err != nil {
return err
}
if cdb != nil {
// 先把压缩后的文件字节数, 用 binary 编码写到文件的头部.
err = writeUint64(b, uint64(len(cdb)))
if err != nil {
return err
}
// 使用 sink write 把压缩后的 bytes 写到数据的文件.
if _, err := sink.Write(b.Bytes()); err != nil {
return err
}
// 把压缩的 db 数据写到文件里.
if _, err := sink.Write(cdb); err != nil {
return err
}
}
// 关闭 sink 对象
return sink.Close()
}()
if err != nil {
sink.Cancel() // 关闭 sink
return err
}
return nil
}
// 使用 gzip 压缩算法.
func (f *fsmSnapshot) compressedDatabase() ([]byte, error) {
var buf bytes.Buffer
gz, err := gzip.NewWriterLevel(&buf, gzip.BestCompression)
if err != nil {
return nil, err
}
if _, err := gz.Write(f.database); err != nil {
return nil, err
}
if err := gz.Close(); err != nil {
return nil, err
}
return buf.Bytes(), nil
}
func (f *fsmSnapshot) Release() {}func (s *Store) Restore(rc io.ReadCloser) error {
startT := time.Now()
// 把 io reader 对象的数据都读取出来.
b, err := dbBytesFromSnapshot(rc)
if err != nil {
return fmt.Errorf("restore failed: %s", err.Error())
}
// 关闭以前的 sqlite db 对象
if err := s.db.Close(); err != nil {
return fmt.Errorf("failed to close pre-restore database: %s", err)
}
var db *sql.DB
if s.StartupOnDisk || (!s.dbConf.Memory && s.lastCommandIdxOnOpen == 0) {
// 如果使用了 ondisk, 则使用持久化 sqlite db.
db, err = createOnDisk(b, s.dbPath, s.dbConf.FKConstraints)
if err != nil {
return fmt.Errorf("open on-disk file during restore: %s", err)
}
s.onDiskCreated = true
} else {
// 反之,使用基于内存构建的 sqlite 对象.
db, err = createInMemory(b, s.dbConf.FKConstraints)
if err != nil {
return fmt.Errorf("createInMemory: %s", err)
}
}
// 重新赋值新的 db 对象
s.db = db
return nil
}createOnDisk 用来恢复 sqlite, 其逻辑很简单, 首先删除以前的 db 的数据库文件, 然后把快照数据写到 sqlite 库文件里, 然后使用 sql.Open 重新打开 sqlite 文件.
这个代码实现有些粗暴呀, 先把数据装载到内存里, 然后写到 db 文件里, 最少可以使用 io.Copy 按 chunk 写入.
func createOnDisk(b []byte, path string, fkConstraints bool) (*sql.DB, error) {
if err := os.Remove(path); err != nil && !os.IsNotExist(err) {
return nil, err
}
if b != nil {
if err := ioutil.WriteFile(path, b, 0660); err != nil {
return nil, err
}
}
return sql.Open(path, fkConstraints)
}上面 hashicorp raft example 和 rqlite 里, 关于快照备份和还原的实现略显简单. 假设当集群中单节点的数据已经到了 50G, 难道需要把 50G 的数据全遍历读取出来, 接着在内存里进行序列化和压缩, 然后保存到快照文件里. 后面通过 raft replication 复制机制把快照传到 follower, follower 把文件读取出来, 内存中解压和反序列化, 最后还原数据.
不合理, 这样的快照生成和数据还原在大数据集下显得不合理. 通常 kv 引擎都是可以实现热备份的, 通过热备份接口实现全量数据的生成快照功能, 这样无需序列化和压缩, 发送给 follower 后, follower 把快照写到指定文件里, 在关闭 DB 对象后, 直接使用新 DB 文件启动即可.
另外, 对于 single raft 来说, 当加入新 follower 时, 只需要把一个已存在的 follower 的数据同步到新节点即可. 像 360 pika 是一个支持 multi raft 的支持外存的 redis, 其内部快照的发送的逻辑是先对 rocksdb 做快照, 然后再发送数据到从端, 后面的流程差不多.
下面是 rocksdb, badgerdb 和 boltdb 热备份的方法.
hashicorp raft 快照的实现原理讲完了.