streamlit_video_all_nlp_app.mp4
This is a project developed to create a use case where multiple NLP concepts are integrated.
I've implemented many NLP techniques individually. You can check their corresponding articles and repo.
I explored multiple techniques, libraries in each of these projects. Then, I selected a single best method/model from each of these projects and created a use case where all of them are assembled.
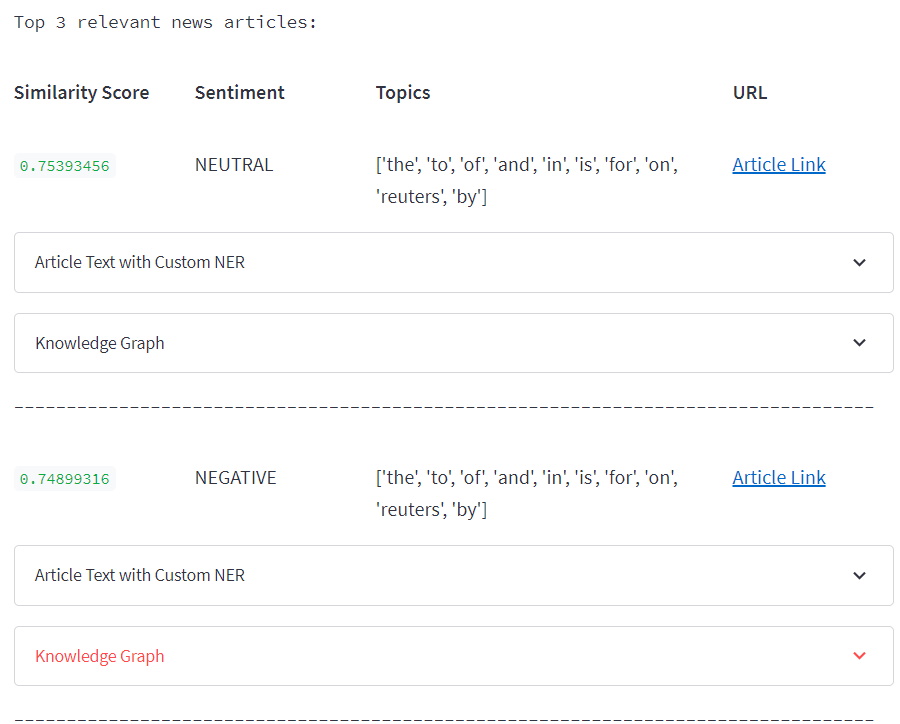
Create an application where user can search for entity(user query) in news articles(knowledge base) Relevant articles fetched should show sentiment, topics, custom NER entities, knowledge graph Use best practices in MLOps to develop project. A project quality should be production ready.
1.Data Collection
2.Data Cleaning
3.Data Annotation
4.Text Classification
5.Coreference Resolution
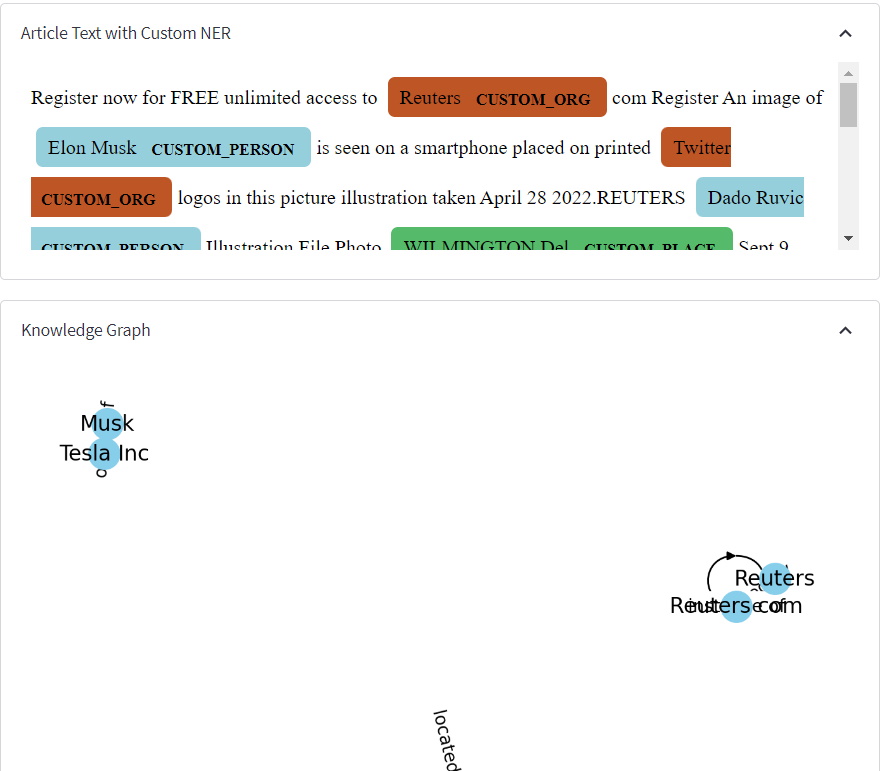
6.Named Entity Recognition
7.Entity Linking
8.Relationship Extraction
9.Knowledge Graph Creation
10.Searching
11.CI/CD
1.Data Collection
Collected news articles.
2.Data Cleaning
created nlp text cleaning library and published on Pypi
3.Data Annotation:
Used doccano for annotation.
4.Text Classification
Classify text into POSITIVE,NEGATIVE,NEUTRAL
5.Coreference Resolution
Convert pronouns to their original nouns
6.Named Entity Recognition
Sometimes you 'll need only certain entities types . We can extract default entities like NAME,PERSON etc from many available libraries or we can also build our own NER model. I've created a project to build custom NER-PERSON,ORG,PLACE,ROLE.
7.Entity Linking
We can get different words/nouns for same entity. Example, U.S,United States of America,America. All these should be considered as one entity. We can achieve this by getting their root id if we have some knowledge base. Here, we are going to use Wikipedia knowledge. So, many time entity linking is also called as wikification.
8.Relationship Extraction
It means fetching relationships in text.
9.Knowledge Graph Creation
10.Searching
Used elasticsearch to fetch relevant news article based on input query.
11.Code structure, CI/CD
Used code template from my another project which is based on standard coding practices.Used circleci,docker for CI/CD.
Streamlit application
Unit test cases are written
Deployment is done locally using docker.
Like any production code,this code is organized in following way:
- Keep all Requirement gathering documents in docs folder.
- Write and keep inference code in src/inference.
- Write Logging and configuration code in src/utility.
- Write unit test cases in tests folder.pytest,pytest-cov
- Write performance test cases in tests folder.locust
- Build docker image.Docker
- Use and configure code formatter.black
- Use and configure code linter.pylint
- Use Circle Ci for CI/CD.Circlci
Clone this repo locally and add/update/delete as per your requirement.
├── README.md <- top-level README for developers using this project.
├── pyproject.toml <- black code formatting configurations.
├── .dockerignore <- Files to be ognored in docker image creation.
├── .gitignore <- Files to be ignored in git check in.
├── .circleci/config.yml <- Circleci configurations
├── .pylintrc <- Pylint code linting configurations.
├── Dockerfile <- A file to create docker image.
├── environment.yml <- stores all the dependencies of this project
├── main_streamlit.py <- A main file to run API server.
├── src <- Source code files to be used by project.
│ ├── inference <- model output generator code
│ ├── training <- model training code
│ ├── utility <- contains utility and constant modules.
├── logs <- log file path
├── config <- config file path
├── docs <- documents from requirement,team collabaroation etc.
├── tests <- unit and performancetest cases files.
│ ├── cov_html <- Unit test cases coverage report
Development Environment used to create this project:
Operating System: Windows 10 Home
Anaconda:4.8.5 Anaconda installation
Go to location of environment.yml file and run:
conda env create -f environment.yml
- Start Streamlit application
- Run:
conda activate all_nlp_app
streamlit run main_streamlit.py

- Go inside 'tests' folder on command line.
- Run:
pytest -vv
pytest --cov-report html:tests/cov_html --cov=src tests/
- Open 2 terminals and start main application in one terminal
python main.py
- In second terminal,Go inside 'tests' folder on command line.
- Run:
locust -f locust_test.py
- Go inside 'all_nlp_app' folder on command line.
- Run:
black src
- Go inside 'all_nlp_app' folder on command line.
- Run:
pylint src
- Go inside 'all_nlp_app' folder on command line.
- Run:
docker build -t myimage .
docker run -d --name mycontainer -p 5000:5000 myimage
- Add project on circleci website then monitor build on every commit.
src/models folder is empty because of their size. You can build the models or contact me for sharingthe models.
Please create a Pull request for any change.
NOTE: This software depends on other packages that are licensed under different open source licenses.