O Git é um sistema de controle de versão (VCS), um software projetado para registrar alterações feitas em um arquivo ou conjunto de arquivos ao longo do tempo. Isso permite reverter ou recuperar alterações em um arquivo ou em um conjunto de arquivos após as alterações. Se você estiver trabalhando em um projeto que contém muitos arquivos, o controle de versão oferece a capacidade de controlar todo o projeto e você pode reverter apenas um ou vários arquivos para as versões anteriores ou todo o projeto de volta. Você pode comparar as alterações feitas nos arquivos de uma versão para outra e pode ver exatamente o que foi alterado em cada arquivo quando a alteração foi introduzida ou quem a introduziu.
O melhor de um VCS é que você controla quase qualquer tipo de arquivo em um computador, não apenas os arquivos de código-fonte. Estudantes costumam usar o controle de versão para acompanhar diferentes versões de um ensaio ou trabalho de pesquisa. Um designer pode usar o controle de versão para manter as versões de uma imagem sem se preocupar em modificar a única versão dessa imagem e o controle de versão oferece a capacidade de explorar novas ideias com seu projeto, com a garantia de que você sempre pode voltar a uma versão anterior.
O método de controle de versão de muitas pessoas é copiar os arquivos para outro diretório (talvez um diretório com carimbo de tempo, se eles forem espertos). Esta abordagem é muito comum porque é muito simples, mas também é incrivelmente propensa a erros. É fácil esquecer em qual diretório você está e acidentalmente sobreescrever o arquivo errado ou copiar arquivos que não quer.
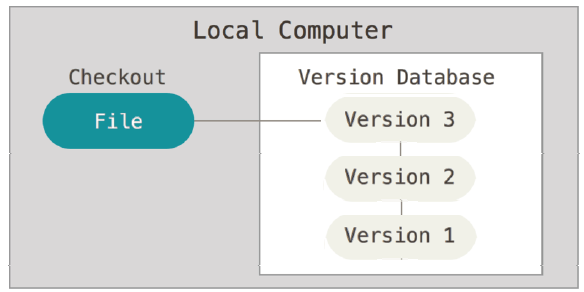
Para lidar com este problema, programadores há muito tempo desenvolveram VCSs locais que tem um banco de dados simples que mantêm todas as alterações nos arquivos sob controle de revisão. No começo dos anos 70 já havia o conceito de versionamento de código fonte. Em 1972 já havia o SCCS (Source Code Control System) desenvolvido na linguagem Snow Ball na Bell Labs e usado em sistemas como o IBM system 370 até o PDP11. Nos 80 foi surgiu sua evolução que foi o RCS (Revision Control System) mantido até hoje. Até mesmo o popular sistema operacional Mac OS X inclui o comando rcs quando você instala as Ferramentas de Desenvolvimento. RCS funciona mantendo conjuntos de alterações (ou seja, as diferenças entre os arquivos) em um formato especial no disco; ele pode, em seguida, re-criar como qualquer arquivo se parecia em qualquer ponto no tempo, adicionando-se todas as alterações.

A próxima questão importante que as pessoas encontram é que elas precisam colaborar com desenvolvedores em outros sistemas. Para lidar com este problema, Sistemas Centralizados de Controle de Versão (CVCSs) foram desenvolvidos. Finalmente por volta de 1990 surgiu o CVS (concorrent Version System) para substituir o RCS, têm um único servidor que contém todos os arquivos de controle de versão, e um número de clientes que usam arquivos a partir desse lugar central modelo chamado hoje de centralizado ou cliente-servidor que era arquitetura da moda nos anos 80 e 90.
Neste modelo configurava-se um servidor onde ficava o projeto e na máquina de cada desenvolvedor era instalado o cliente que conseguia se conectar nesse servidor. O servidor era responsável por coisas como autenticar o login de cada desenvolvedor para dar permissão de acesso ao código daí o desenvolvedor podia fazer check-out para baixar todo o código fazer check-in para subir as modificações e de tempos em tempos dar update para baixar as últimas modificações do servidor. O servidor também guardava os deltas de modificação, possível graças a ideia de patches. Novas versões adicionaram coisas como delta compresion a economizar espaço no disco guardando os patches zipados e novas funcionalidades foram aparecendo com uma ideia the branchs.
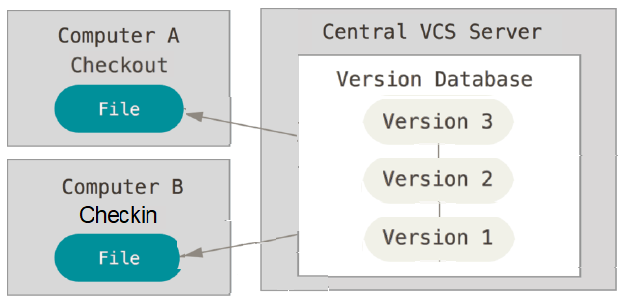
Esta configuração oferece muitas vantagens, especialmente sobre VCSs locais. Por exemplo, todo mundo sabe, até certo ponto o que todo mundo no projeto está fazendo. Os administradores têm controle refinado sobre quem pode fazer o que; e é muito mais fácil de administrar um CVCS do que lidar com bancos de dados locais em cada cliente.
Os branch é um conceito simples, mas com operação complicada. O branch é duplicar o diretório do projeto, trabalhar no diretório separado e quando terminar, gerar os patches para aplicar no diretório principal e no fim apagar o diretório duplicado. É uma forma de trabalhar numa funcionalidade que pode demorar ou testar correção de bugs sem atrapalhar o diretório principal. Isso funciona bem se você trabalha sozinho ou com poucas pessoas ou com pessoas que estão muito bem coordenadas entre si caso contrário isso se torna um pesadelo muito rápido. Nos dias de hoje você tem pull requests no GitHub que basicamente um branch do projeto.

Após o CVS, surgiu o Subversion com o lema de “CVS feito direito” que ainda era no modelo centralizado e com muito problemas ainda em branchs. Porém, foi apenas quando o GitHub atingiu o pico de popularidade, em 2008, que conseguiram consertar branchs, adicionando a funcionalidade de Merge tracking, na versão 1.5.
O conceito de bloquear arquivos para só uma pessoa usar de cada vez causava muitos problemas também para gerenciar Releases ou fechar versões. Nos anos 90 e começo nos 2000 havia a figura de um gestor de configuração pago em tempo integral para fazer o equivalente fazer commits e tagear versões para não corromper muito o código-fonte.
O ponto único de falha que o servidor centralizado representa era outro problema. Se esse servidor der problema por uma hora, durante essa hora ninguém pode colaborar ou salvar as alterações de versão para o que quer que eles estejam trabalhando. Se o disco rígido do banco de dados central for corrompido, e backups apropriados não foram mantidos, você perdia absolutamente tudo - toda a história do projeto, exceto imagens pontuais que desenvolvedores possam ter em suas máquinas locais. Sistemas VCS locais sofrem com esse mesmo problema - sempre que você tenha toda a história do projeto em um único lugar, há o risco de perder tudo.
Outro problema eram as branchs e a razão principal de porque CVS e Subversion tiveram reputação tão ruim. Conflitos de merge é o pesadelo de todo desenvolvedor de sistemas antigos e incompetentes., pois nos sistemas antigos, fazer branches e merges eram complicados você evitava ao máximo fazer, só que quanto mais você espera mais acumulava as diferenças no branch e conflitos no merge. Por isso, a maioria simplesmente desistia de fazer branches e todo mundo trabalhava na mesma versão (trunk, no Subversion e master, no Git) e havia muita discussão sobre quem podia ter acesso de committ no master. No Git, trabalhar em branches e merges é comum, você raramente encontra conflitos e mesmo quando encontra eles costumam ser fáceis de resolver pois, geralmente, você faz merges com frequência e evita deixar código não mergeado esquecido num branch por semanas ou meses.
Outro grande defeito estrutural do CVS é que ele guardava a revisões por arquivo ele não entende o conceito de um único arquivão (TAR) de patch de uma funcionalidade inteira como um pull request de hoje (que é um conjunto de commits). De forma simplória um commit é nada mais que um arquivo de patch com o cabeçalho com metadados (autor, data e hora). Era difícil de gerenciar a versão no CVS, pois cada desenvolvedor precisava trabalhar em um branch ou fork diferente (uma duplicata do projeto original) só que para combinar as modificações de dezenas de desenvolvedores em uma única versão eram um trabalho que podia levar um dia inteiro ou mais para conseguir fazer esse merge.
Mesmo Subversion não era nem uma grande maravilha, o mundo open-source e o mundo corporativo estavam bem mal servidos, haviam produto comercial bem porcaria como Microsoft Source Safe ou Rational Clear Case. Mundo open-source ainda não tinha tanta força muitos projetos ainda usavam CVS alguns poucos estavam indo para Subversion era mais a filosofia do menos pior.

Na virada do século surge a Bit Mover e seu produto Bitkeeper muita gente pensa que a principal diferença entre os sistemas de versionamento anteriores é que seria descentralizado.

Na realidade a principal novidade foi tornar branchs, forks e principalmente merges operações razoavelmente triviais. Um trabalho que podia levar horas ou dias reduzido para minutos e com muito menos margem de erros. Assim em 2002, apesar de ser um produto comercial de código fechado, o Linus resolve migrar o desenvolvimento do kernell do Linux para o Bitkeeper pois, assim como GitHub, apesar de serem uma ferramenta fechada eles tinham uma política que deixavam projetos open-source usar a ferramenta gratuitamente.
O problema de confiar uma ferramenta comercial é que por um tempo eles permitem usar de graça mas chega um dia que eles podem simplesmente proibir de usar. E isso que ocorreu na relação do BitKeeper com o Linux, após dois ou três anos, por que alguém tentou fazer engenharia reversa do protocolo do Bitkeeper, a Bit Mover resolveu botar restrições demais ao ponto que o Linux ia ficar sem o Bitkeeper.
Outras alternativas comerciais surgiram em 2003 (Darcs), em 2005 (Mercurial, Bazaar e Git), é aqui que Sistemas Distribuídos de Controle de Versão (DVCS) entram em cena.

Em um DVCS, clientes não somente usam o estado mais recente dos arquivos: eles duplicam localmente o repositório completo. Assim, se qualquer servidor morrer, e esses sistemas estiverem colaborando por meio dele, qualquer um dos repositórios de clientes podem ser copiado de volta para o servidor para restaurá-lo. Cada clone é de fato um backup completo de todos os dados. O foco dos DVCS era també em resolver o problema de branchs e merges.
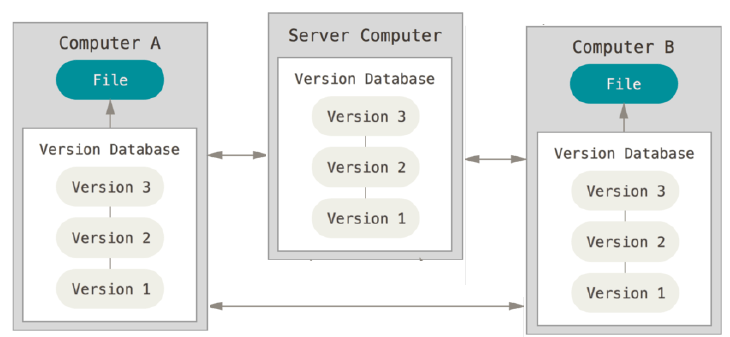
Além disso, muitos desses sistemas trabalham muito bem com vários repositórios remotos, tal que você possa colaborar em diferentes grupos de pessoas de maneiras diferentes ao mesmo tempo dentro do mesmo projeto. Isso permite que você configure vários tipos de fluxos de trabalho que não são possíveis em sistemas centralizados, como modelos hierárquicos.
O núcleo (kernel) do Linux é um projeto de código aberto com um escopo bastante grande. A maior parte da vida da manutenção do núcleo o Linux (1991-2002), as mudanças no código eram feitas com patches e tarball.
- Patches: termo da língua inglesa que significa, literalmente, "remendo". É um programa de computador criado para atualizar ou corrigir um software de forma a melhorar sua usabilidade ou performance. Quando patches corrigem bugs ou vulnerabilidades de segurança, se dá o nome de bugfix. Esta técnica pode ser utilizada como uma das formas de distribuir uma liberação de software. É muito utilizada em jogos para computadores de forma a atualizar o conteúdo disponível.
- Tarball: tar é um utilitário de software de computador para coletar muitos arquivos em um único arquivo, geralmente chamado de tarball, para fins de distribuição ou backup. O nome é derivado de "Tape ARchive", pois foi desenvolvido originalmente para gravar dados em dispositivos de E/S seqüenciais sem sistema de arquivos próprio. Os conjuntos de dados de archive criados pelo tar contêm vários parâmetros do sistema de arquivos, como nome, data e hora, propriedade, permissões de acesso a arquivos e organização de diretórios. O utilitário de linha de comando foi introduzido pela primeira vez na versão 7 Unix em janeiro de 1979, substituindo o programa tp. A estrutura do arquivo para armazenar essas informações foi padronizada no POSIX.1-1988 e posteriormente no POSIX.1-2001, e tornou-se um formato suportado pela maioria dos sistemas modernos de arquivamento de arquivos.
Por volta dos anos 70 na época dos Unix que surgiram duas ferramentas que existem até hoje no Linux. Que são termos que todo mundo de Unix e Linux sempre usa mas pouco sabem o que realmente é:
- Ferramenta diff:
- Ferramenta patch:
Nasceu por volta de 1976 e é usado para tirar diferença entre dois arquivos em um terceiro arquivo. É um problema exponencial que fica lento muito rápido se implementar de jeito incorreto mas existe um algoritmo bem conhecido para encontrar a subsequência comum mais longa (Longgest Common Subsequence) entre dois strings:
- No pior caso a complexidade vai ser de O(2m) sendo m o tamanho de um dos arquivos.
- No melhor caso a complexidade cai para O(mv) sendo n e m o tamanho dos dois arquivos
Para entender como você consegue achar essa subsequencia e a partir dessa subsequencia se um conteúdo existe no arquivo original mas não existe na subsequencia podemos marcar com o caracter com o sinal de menos(-) se não existe no arquivo original mais existe na subsequencia podemos marcar com o sinal de mais(+). Adiciona nessa subsequência alguns metadados como em qual linha do arquivo aquela subsequencia se localiza e chegamos no que chamamos o formato de um patch. Abaixo um exemplo de saída com comando diff do Git:
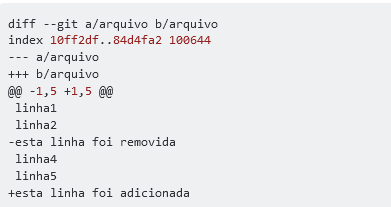
Então a ferramenta diff que todo o linux tem consegue achar a subsequencia como mais longa entre dois arquivos adiciona metadados como o número da linha no arquivo e gera esse arquivo de patch (em inglês, remendo) alguns dizem que essa é a origem do nome Apache o servidor web que era feito com um monte de patches ou seja o tipo disso a parte enfim dentro de um arquivo de patch você tem chunk ou hunk que é literalmente nacos de código. Vários nacos de código ou hunks formam um patch que é um remendo daí digamos que você queira mandar as modificações que você fez no arquivo para um amigo seu que tem o mesmo arquivo, você só envia o arquivo de patch
E no linux tem a segunda ferramenta que se chama patch e é feita para aplicar um arquivo de patch no arquivo original para ter a versão novas. Se observar um projeto GitHub já deve ter visto o formato de patches só que colorizado mas é basicamente a mesma coisa. A ferramenta diff tornou mais econômico guardar só as modificações feitas sobre o arquivo original em vez de duplicar o arquivo toda vez só por causa de uma linha modificada então economizamos tanto espaço de disco como banda de rede já que para transferir as modificações pela rede agora pode ir só o patch. Mas observe que se você tiver outro programador que já está colaborando no mesmo projeto não basta só dar o patch para ele ele precisa ter alguma versão do projeto baixado para aplicar esse patch

Para baixar o projeto nos primórdios da internet era outro problema. Uma forma de fazer isso seria baixar de um servidor de arquivos, só que com baixa velocidade de tráfego de rede, dependendo do tamanho do projeto pode ser um processo bem lento. Nos anos 70 para trás disco rígido era uma coisa bem cara e a forma mais comuns nos mainframes era armazenada rolos de fita magnética e era preciso tentar desperdiçar menos espaço possível. Daí no fim dos anos 70 nasceu o formato de gravação de arquivos em fita ou “tape arquive”(TAR) a estrutura de dados de um tar é gravar uma série de objetos um atrás do outro tá é traduzido literalmente com alcatrão, poluente de petróleo, um bola de piche. Então se você tem uma bola de piche onde objetos vão grudando você tem um TAR. Na prática pense que em vez de ter 100 arquivos você combinou eles um atrás do outro em um único arquivão. Na prática pense que em vez de ter 100 arquivos você combinou eles um atrás do outro em um único arquivão.
E para ser mais eficiente o comando TAR dos de unix e linux ganhou capacidade de adicionar compressão sem perda a partir dos anos 90. Compressão existem dois tipos
- Lossy(que perde): É extensão jpg para imagens ou mp3 para músic
- Lossless(que não perde): É extensão zip sevenzip, um exemplo algoritmo de compressão mais simples é o algoritmo de Huffman para a compreensão de texto. O formato gzip você vê até hoje em linux usa oalgoritmo Deflate que é uma combinação de uma variação do LZ(Lempel-Ziv) e do Huffman
Algoritmos de compressãoé outra área que os russos dominam o formato RAR vem de Roschal Archive que é o nome do inventor russo Eugeny Roschal. O zip e o sevenzip vem de outro russo Igor Pavlov. No fim dos anos 80 uns compressores mais famosos na época do MS-DOS eram pkzip que era do americano Phil Katz que também inventou o Deflate do Unix.
Com essas ferramentas já era possível montar um fluxo de trabalho para um projeto como a kernel do Linux. O Linus Torvalds fez um TARball da versão 1.0 da Kernell do Linuz e colocava no servidor FTP público um outro desenvolvedor como Alan Cox ou Andrew Morton baixa do FTP e começa a desenvolver alguma nova funcionalidade quando termina faz um diff dos arquivos e envie anexado no e-mail de volta para o Linus. No unix e Linux existem comandos de terminal para conectar em servidores pop3 ou imap que a gente usa hoje em dia então o Linus conseguia automatizar, baixando o e-mail separava o anexo e usava o comando patch do Linux para aplicar os patches na versão na sua máquina. Se tudo estiver certoi ele fazia um novo TARball versão 1.1 e colocava no servidor. Se você já viu um servidor de FTP já deve ter visto diretório de projetos com TARball de diversas versões. Não é um fluxo de trabalho eficiente em 2020 mais nos anos 90 a gente tá falando do que havia de mais avançado em fluxo de trabalho distribuído. Então a internet, somado com ferramental Linux como diff e patch TAR, gzip, FTP e e-mail permitiram um fluxo de trabalho distribuído e o nascimento do mundo open source como conhecemos hoje alguma variação disso já existia no mundo em Unix nos anos 80 mas foi com o Linux que esse modelo de trabalho começou a ganhar chão.
Em 2002, o projeto do núcleo do Linux começou usar uma DVCS proprietária chamada BitKeeper. Em 2005, a ferramenta passou a ser paga. Depois de lançar a kernell 2.6, por volta de 2005, o Linus Torvalds desenvolve em duas semanas a sua própria ferramenta baseada em lições aprendidas ao usar o BitKeeper. Algumas metas do novo sistema era os seguintes:
- Velocidade
- Projeto simples
- Forte suporte para desenvolvimento não-linear (milhares de ramos paralelos)
- Completamente distribuído
- Lidar com projetos grandes como o núcleo o Linux com eficiência (velocidade e tamanho dos dados)
Os problemas resolvidos com o Git, e que não eram pelos versionadores da época, foram:
index.php
index2.php
index3.php
index-97-02-111.php- Versionamento: é quando você escreve um código e vai salvando em algum diretório e cai nos mesmos erros que todo programador sempre caiu, você vai escrever em cima do seu código de ontem, salvar e depois descobri que fez errado e agora perdeu a versão de ontem. Ou pode ser que você queira renomear ou apagar arquivos e uma hora vai apagar um arquivo que não devia. Depois de apagar coisas por acidente algumas vezes você vai começar a duplicar os arquivos antes de editar e vai começar a ficar com versões diferentes do mesmo arquivo no mesmo diretório e encontra projetos dos outros cheios de arquivos velhos que não deviam estar lá. Esse procedimento de cópias de arquivos, além de ser super ineficiente não só porque vai sujando seu diretório com arquivos desnecessários mais vira um enorme desperdício de espaço em disco.
- Compartilhamento: o segundo problema é qunado você precisa que outro desenvolvedor trabalhe no mesmo projeto que você. Uma das maneiras de fazer isso é colocaro diretório do projeto em alguma pasta compartilhada na rede local daí acontecede os dois abrir o mesmo arquivo para editar você digita e salva o primeiro daí o segundo cara edita a parte dele e salva por cima e pronto você acabou de perder o que estava fazendo. Para resolver parcialmente esse problema que muitos produtos comerciais daquela época como o Source Safe ou Clear Case trabalhavam com o princípio de ter uma camada por cima do sistema de arquivos de rede e ofereciam a opção de bloquear um arquivo ou diretório (dar check-out) daí se esse outro programador tentar abrir o mesmo arquivo sistema vai negar e ele tem que esperar você terminar salvar e dar check-in para desbloquear o arquivo. Isso resolvia parcialmente o problema pois em projetos distribuídos em regiões distantes, caso alguém deixasse de realizar o check-in de seus arquivos, bloqueava o arquivo para edição para outro programador. Esses produtos atendiam somente razoavelmente em casos de equipes pequenas lozalizadas no mesmo escritótio, da mesma empresa, cenários bem limitados.
- Segurança: Uma das coisas que o Linus queria garantir é que os dados no repositório Git sejam sempre confiáveis, ou seja, que que o texto que eu recupero dele é sempre o mesmo que coloquei nele. Para garantir isso, o Git commit, após fazer o comando diff e fazer o patch das alterações ele passa por um algoritmo de hash SHA-1. O Git armazena tudo em seu banco de dados não pelo nome do arquivo, mas pelo valor de hash do seu conteúdo. Se modificar um bit dentro desse patch o SHA-1 vai mudar completamente e gerando uma nova assinatura, sabemos que o patch está corrompido.
O SHA-1 é uma sequência de 40 caracteres composta de caracteres hexadecimais (0-9 e-f) e é calculada com base no conteúdo de uma estrutura de arquivo ou diretório no Git. Um hash SHA-1 é algo como o seguinte:
24b9da6552252987aa493b52f8696cd6d3b00373Os subdiretórios, .cvs (no CVC) e .svn (no Subversion), começavam com o ponto porque em Linux um arquivo que começa com ponto significa escondido. Quando mexia nesses diretórios tinha muita chance de estragar tudo e tem que dar um checkout de novo para reconstruir certo. Em 2003, nem Windows XP em Windows Server entendiam direito arquivos que começavam com o ponto e era um dos motivos principais de quase ninguém usar Subversion no Visual Studio pois não conseguia abrir os projetos. Hoje em dia o Windows já entende arquivos e diretórios que começa com ponto porque o Git faz a mesma coisa ele cria um diretório chamado .git mas ele é diferente do CVC e Subversion porque na na realidade agora os arquivos diretórios do projeto que você edita que não tem importância o conteúdo de verdade dos arquivos fica no repositório dentro desse .git e por isso só tem um a raiz e não em cada um dos subdiretórios do projeto (como era no CVC e Subversion).
No Git, suponhamos que você crie um projeto de Node.js, C# e faça o comando git init para iniciar, git add para preparar e o primeiro git commit para confirmar. Depois, por acidente, apague os arquivos originais com exceção do diretório .git, se você der o comando git checkout, o Git vai procurar o arquivo dentro desse .git e recuperar os arquivos sem precisar perguntar nada para nenhum servidor. Porém, se você listar o que tem dentro desse diretório não irá achar os arquivos do projeto, em vez disso vai ter subdiretórios em que o maior é o .git/object (a base de ddos). Nele vai achar um monte de arquivos com nomes de hashes de SHA-1 dos commits, trees e blobs que é a base que o git usa para recuperar os arquivos, criar branchs, etc.
Performance: Os versionadores Mercurial, Bazaar e Darcs apesar de serem descentralizados tinham problema de performance. Mercurial, Bazaar eram feitos em python então eles não tinham como escalar em performance até certo ponto. Darcs era feito em Haskell e também era criticado por problemas de performance. O Git sempre foi super-rápido, porém difícil de usar, mas em casos como esse performance e segurança têm prioridade. O git commit faz algo equivalente ao comando diff, é um patch de modificações desde o commit anterior. O merge faz algo equivalente ao comando patch e o pull request seria equivalente a um Tarball, ou seja, um conjunto de commits. Esses conceitos que garantiram a performance superior do Git em relação a outros versionadores.
Em 2007 ninguém fora dos colaboradores da kernel do linux tinham muita ideia sobre Git. Em maio de 2007 o próprio Linus Torvalds dá uma palestra em uma tech-talk dentro do Google: Linus Tovards on Git

Os arquivos agora estão sendo controlados por versão, mas tudo ainda está localmente no computador, não sendo possível o acesso remoto dos arquivos. Para resolver esse problema, precisamos de um provedor de hospedagem de código e os mais populares são o GitHub, Azure DevOps, o GitLab e o BitBucket. Além de ser um serviço de hospedagem de repositórios Git, os provedores de hospedagem de código oferecem recursos adicionais para ajudar a melhorar seus repositórios Git em colaboração e facilitar as contribuições entre outros desenvolvedores em todo o mundo. O recurso mais importante que esses provedores oferecem é a capacidade de integrar colaborações de maneira integrada aos seus repositórios Git.
Para criar uma conta GitHub basta ir para o seguinte endereço: github.com
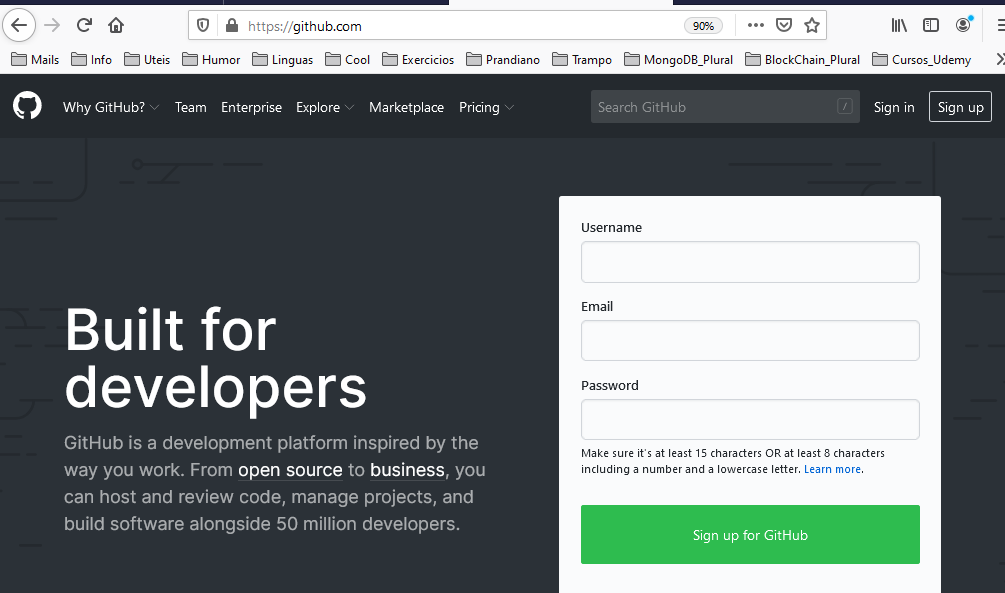
Vamos clicar em Sign Up e preencher um nome de usuário, endereço de email e senha shyoutarou2020.
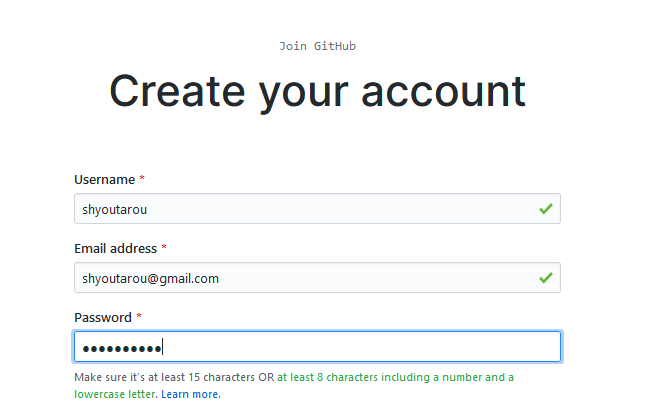
Há a etapa de escolha do tipo de plano pessoal que pode ser um plano gratuito para criar repositórios públicos ilimitados ou um plano pago para criar repositórios privados ilimitados. Depois, precisamos verificar o seu endereço de e-mail que nos levará de volta para página do GitHub e fim. https://github.com/shyoutarou
Na tela para enviar um repositório Git para um provedor é necessário informar um nome válido, no qual, informamos wired-brain-recipes. Em seguida, podemos adicionar uma descrição opcional e temos a opção de tornar esses repositórios públicos ou privados.
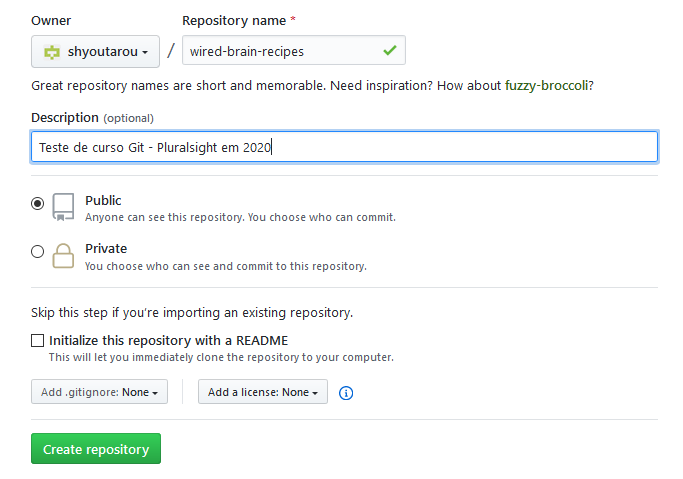
Há uma opção para inicializar esses repositórios com um arquivo leia-me, que é uma maneira rápida e simples de os colaboradores aprenderem mais sobre seus repositórios. E as outras duas opções são para adicionar um Git ignore, que é uma maneira de adicionar arquivos que você não deseja que a versão seja controlada pelo Git; e o outro é adicionar uma licença aos seus repositórios.
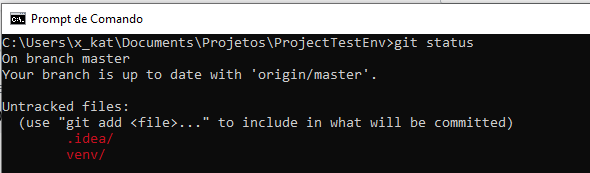
OBSERVAÇÂO: Caso deseje criar um README.md ou arquivo de Licença na criação do repositório o Git irá criar um commit automático.
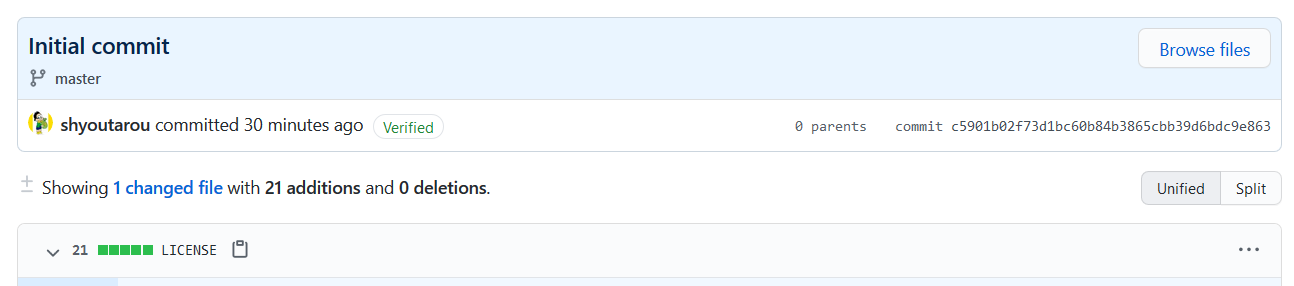
Assim, caso você deseje não clonar o repositório primeiro, mas sim, subir um projeto existente adicionando os arquivos, confirmando e definindo o local remoto com o comando:
git remote add origin https://github.com/shyoutarou/NLW2_Server.git Ao tentar enviar as infomarções ao repositório local ocorrerá um conflito, pois já existe um commit no repositório:
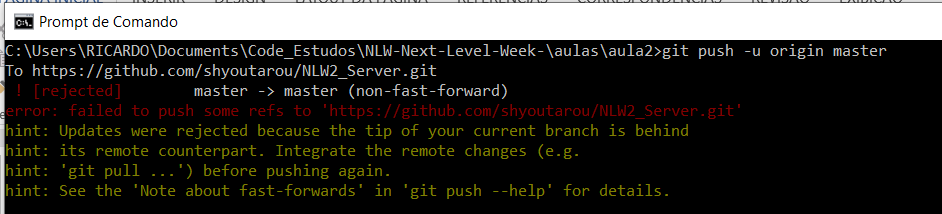
Não conseguimos fazer pull simples e nem merge, pois a informação do branch não foram criada ainda no repositório remoto:
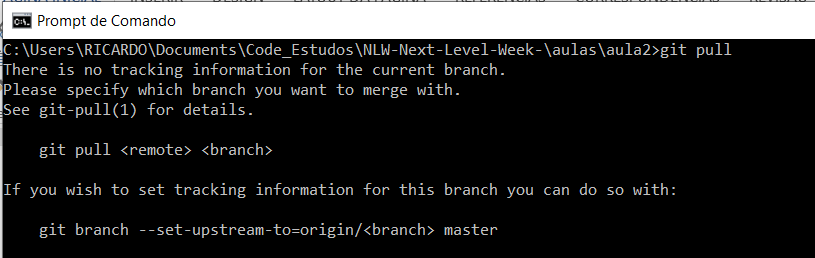

Nem com pull definindo a branch:

As opções que temos seria reverter o commit com um reset, mas como estamos no primeiro commit não temos nenhuma referência anterior (HEAD ou SHA-1) para voltar. Então não conseguimos fazer o stash. E fazer o checkout, além de poder apagar todos nossos arquivos, não resolveria nada pois o conflito está em relação ao repositório remoto. O Que Fazer??? Uma opção é fazer o:
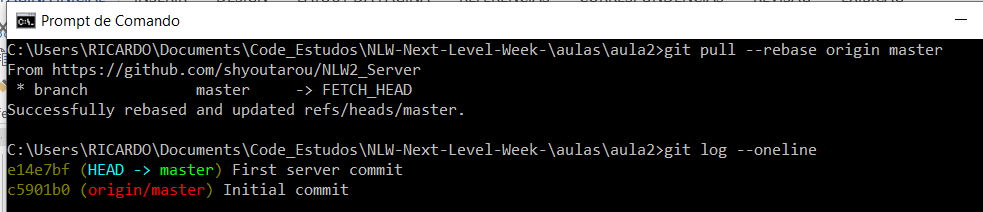
git pull –rebase origin master
Caso tenha optado por não criar um arquivo gitignore, mas deseje cria-lo manualmente, siga a seguintes etapas:
- Abra o bloco de notas.
- Adicione o conteúdo do seu arquivo gitignore.
- Clique em "Salvar como" e selecione "todos os arquivos".
- Salve como .gitignore
Quando você faz confirmações em um repositório git, escolhe quais arquivos preparar e confirmar usando git add FILENAME e, em seguida, git commit. Mas e se houver alguns arquivos que você nunca deseja confirmar? É muito fácil comprometê-los acidentalmente (especialmente se você usar o git add. Para preparar todos os arquivos no diretório atual). É aí que um arquivo .gitignore é útil. Ele permite ao Git saber que deve ignorar certos arquivos e não rastreá-los. Os arquivos você deve ignorar geralmente são:
- Arquivos de log
- Arquivos com chaves / segredos de API, credenciais ou informações confidenciais
- Arquivos de sistema inúteis, como .DS_Store no macOS
- Arquivos gerados como pastas dist
- Dependências que podem ser baixadas de um gerenciador de pacotes
- E pode haver outros motivos (talvez você faça pequenos arquivos todo.md)
Um arquivo .gitignore é um arquivo de texto sem formatação, em que cada linha contém um padrão para os arquivos/diretórios ignorarem. Geralmente, isso é colocado na pasta raiz do repositório, e é isso que eu recomendo. No entanto, você pode colocá-lo em qualquer pasta do repositório e também pode ter vários arquivos .gitignore. Os padrões nos arquivos são relativos ao local desse arquivo .gitignore.
Como o arquivo .gitignore é verificado no repositório, há algumas opções se você deseja ignorar alguns arquivos sem adicioná-lo às regras .gitignore do repositório. Por exemplo, você pode ter alguns arquivos especiais com os quais está trabalhando em um projeto específico ou pode usar um editor diferente dos seus colegas de equipe e sempre deseja ignorar esses tipos de arquivos. Se houver alguns arquivos que você deseja ignorar apenas para este repositório, você pode colocá-los em
.git/info/exclude.Se houver alguns arquivos que você deseja ignorar em todos os repositórios do seu computador, você pode colocá-los em um arquivo .gitignore global. Primeiro, você deve adicionar uma configuração ao Git com este comando:
git config --global core.excludesFile ~/.gitignoreEm seguida, você pode adicionar quaisquer regras globais ao ~/.gitignore.
O Git não ignorará o arquivo se você já o tiver confirmado. Você precisará deixar de rastrear o arquivo primeiro e, em seguida, ele começará a ignorá-lo. Você pode deixar de rastrear o arquivo com este comando:
git rm --cached FILENAMESe você estiver com problemas, poderá descobrir por que certos arquivos estão sendo ignorados usando o comando git check-ignore com a opção detalhada.
git check-ignore -v example.logA saída será mais ou menos assim:
.gitignore: 1: *. log example.logNeste exemplo, o arquivo .gitignore na raiz do projeto está fazendo com que o exemplo.log seja ignorado, e o padrão que está causando o fato de ser ignorado é * .log na primeira linha.
O padrão mais fácil é um nome de arquivo literal, no exemplo abaixo ignorará qualquer arquivo chamado .DS_Store, que é um arquivo comum no macOS.
.DS_StoreVocê pode ignorar diretórios inteiros, apenas incluindo seus caminhos e colocando um / no final. Se você não colocar a barra no final, ela corresponderá aos arquivos e diretórios com esse nome.
node_modules/
Histórico/O * corresponde a 0 ou mais caracteres (exceto o /). Por exemplo, * .log corresponde a qualquer arquivo que termine com a extensão .log. Outro exemplo é *~, que corresponde a qualquer arquivo que termina com , como index.html. Você também pode usar ?, Que corresponde a qualquer caractere, exceto o /.
Você pode usar um prefixo de! negar um arquivo que seria ignorado. No exemplo abaixo, example.log não é ignorado, mesmo que todos os outros arquivos que terminem com .log sejam ignorados.
*.log
!example.logMas lembre-se, você não pode negar um arquivo dentro de um diretório ignorado. No exemplo abaixo, devido a razões de desempenho, o git ainda ignorará logs/example.log porque todo o diretório de logs é ignorado.
logs/
!logs/example.log| Sintaxe | Ignore |
|---|---|
| ** | pode ser usado para corresponder a qualquer número de diretórios. |
| **/logs | corresponde a todos os arquivos ou diretórios denominados logs (o mesmo que os logs padrão) |
| **/logs/*.log | corresponde a todos os arquivos que terminam com .log em um diretório de logs |
| logs/** | corresponde a todos os arquivos em um diretório de logs. |
| logs/**/*.log | corresponde a todos os arquivos que terminam com .log no diretório logs e em qualquer um de seus subdiretórios |
Quaisquer linhas que começam com # são comentários:
# macOS Files
.DS_StoreAo clicar Create repository, vamos para uma página que fornece alguns cenários diferentes e as etapas sobre como atualizar nossos repositórios.
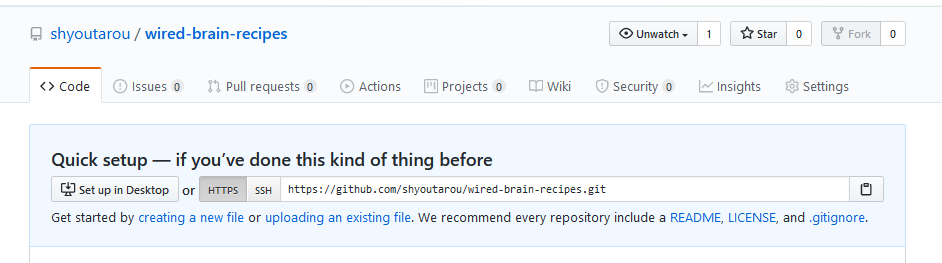
Temos a opção de utilizar URL https ou SSH, que funcionarão em qualquer lugar, mesmo se você estiver atrás de um firewall ou proxy usando https URL para enviar ou receber alterações do repositório o GitHub solicitará seu nome de usuário e endereço de e-mail para verificação.

Há também uma opção para usar SSH URL para fornecer acesso aos seus repositórios git através do protocolo SSH Secure. Para usar SSH URL, você precisa primeiro gerar um par de chaves SSH e, em seguida, adicionar essa chave pública à sua conta Git nas configurações de perfil usando SSH URL para enviar ou receber alterações nos seus repositórios. O Github solicitará uma senha e você precisará digitar sua palacra-chave SSH.
Já que já temos um repositório Git, usaremos a segunda opção para enviar repositórios já existentes da linha de comando para o GitHub.

Mas usaremos algumas das etapas no primeiro cenário para criar um arquivo leia-me ao enviar nosso primeiro commit para atualizar nosso repositório remotamente.

Antes de instalar o Git, precisamos nos familiarizar um pouco com a linha de comando. É importante observar que muitos desses comandos dependem do local do diretório atual; portanto, você deve certificar-se de estar no diretório de projetos antes de executar seus comandos.
| Windows | Linux / Mac | Descrição |
|---|---|---|
| date | date | Exibir a data atual. |
| time | cal | Exibir a hora atual. / Exibir um calendário. |
| echo %cd% | pwd | Exibir qual é o diretório atual. |
| dir /s /b | ls / ls –l / ls -la | Exibir arquivos/diretórios do diretório atual. |
| cd | cd | Mudar o diretório atual. |
| cd .. | cd .. | Voltar para o diretório acima. |
| mkdir | mkdir | Criar uma pasta. |
| copy | cp | Copiar (duplicar) um arquivo. |
| move OU ren | mv | Mover (ou renomear) um arquivo ou pasta. |
| del | rm | Deletar um arquivo |
| rmdir | rm -rf | Deletar uma pasta vazia. |
| rmdir /s | Deletar uma pasta que não esteja vazia. | |
| type | cat | Exibir o conteúdo de um arquivo. |
| cls | clear | Limpar o terminal. |
| copy NUL | touch | Criar um arquivo em branco (vazio) |
| echo >> FILE | ||
| tree /f /a | tree | Mostra estrutura em árvore de arquivos e subdiretórios de um diretório especificado |
| start | open | Abre em visualização gráfica o diretório especificado |
| -h ou --help | -h ou --help | Ajuda com um determinado comando |
Para instalar o Git no Windows faça o download no link
O Git para Windows fornece uma emulação BASH chamada Git BASH usada para executar o Git a partir da linha de comando. Os usuários do NIX devem se sentir em casa, pois a emulação BASH se comporta exatamente como o comando "git" nos ambientes LINUX e UNIX. Como os usuários do Windows normalmente esperam interfaces gráficas, o Git for Windows também fornece a GUI do Git, uma alternativa poderosa ao Git BASH, oferecendo uma versão gráfica de quase todas as funções da linha de comando do Git, além de ferramentas visuais de diferenças.
Depois de concluir a instalação, você pode verificar se a instalação foi bem-sucedida digite git --version para obter a versão do Git:
Agora que verificamos que o Git foi instalado, a primeira coisa que devemos fazer é definir nosso nome de usuário e endereço de email quando usamos o Git para fazer alterações em nossos arquivos do projeto. O Git usa essas informações para identificar quem fez essas alterações. O Git possui uma ferramenta chamada git config que permite definir configurações.
O git config é a função conveniente usada para definir os valores de configuração do Git em projetos de nível global ou local. Esses níveis de configuração correspondem aos arquivos de texto do .git/config.
Executar o git config modifica arquivos de texto de configuração. A gente vai falar das configurações comuns, como e-mail, nome de usuário e editor. Também vamos falar sobre aliases do Git, que permitem a criação de atalhos para operações usadas com frequência. Saber mais sobre o git config e sobre as diversas configurações do Git ajudam a criar fluxos de trabalho Git poderosos e personalizados.
Se você quiser verificar suas configurações, digite git config --list, e ele listará todas as configurações que Git possui. Se você deseja verificar uma configuração específica, é invocar o comando com o nome de configuração. Isso vai exibir o valor definido desse nome. Nomes de configuração são cadeias de caracteres delimitadas por pontos compostas de "seções" e "chaves" baseadas na hierarquia. Por exemplo: user.email
git config user.email

Nesse exemplo, o e-mail é propriedade filho do bloco de configuração do usuário. Isso retorna o endereço de e-mail configurado que o Git associa com commits criados no local.
Antes de falar mais sobre o uso do git config, a gente vai discutir os níveis de configuração. O comando git config pode aceitar argumentos para especificar o nível de configuração no qual operar. Os seguintes níveis de configuração estão disponíveis:
| Nível | Descrição |
|---|---|
| --local | Por padrão, o git config grava em nível local se não houver nenhuma opção de configuração. A configuração de nível local é aplicada no repositório do contexto que o git config for invocado. Os valores de configuração local são armazenados no arquivo que pode ser encontrado no diretório .git do repositório: .git/config |
| --global | A configuração de nível global é específica do usuário. Isso quer dizer que ela é aplicada a usuários do sistema operacional. Os valores de configuração global são armazenados no arquivo localizado no diretório base do usuário. ~ /.gitconfig em sistemas Unix e C:<username>.gitconfig no Windows |
| --system | A configuração de nível do sistema é aplicada em toda a máquina. Ela abrange todos os usuários do sistema operacional e todos os repositórios. O arquivo da configuração de nível do sistema está no arquivo gitconfig localizado fora do caminho raiz do sistema. $(prefix)/etc/gitconfig nos sistemas Unix. No Windows, esse arquivo pode ser encontrado em C:\Program Files\Git\etc no Windows Vista e versões mais recentes. |
Portanto, a ordem de prioridade para os níveis de configuração é: local, global, sistema. Quando o Git procurar valores de configuração, ele vai começar no nível local e ir até o nível de sistema. A seguir estão alguns exemplos de comandos utilizados:
| Comando | Descrição |
|---|---|
| git config --global user.name "Your Name" | Adicione seu nome à configuração global |
| git config --global user.email "Your email" | Adicione seu email à configuração global |
| git config --list | Exibir todas as configurações do git |
| git config user.name | Exibe o valor de configuração user.name |
| git config user.email | Exibe o valor da configuração user.email |
| git config --local --list | Lista a configuração local do git |
| git config --global --list | Lista a configuração global do git |
| git config --system --list | Lista a configuração do sistema git |
| git config --local log.date relative | Salve o formato de data relativo na configuração local do Git |
| git config --local --edit | Edita a configuração local do Git |
| git config --global --edit | Edita a configuração global do Git |
| git config --system --edit | Edita a configuração do sistema Git |
| git -c core.editor=echo config --local --edit | Imprime o nome do arquivo de configuração git |
| git -c core.editor=nano config --local --edit | Edite o arquivo de configuração git local usando o nano |
| git config core.excludesfile | Imprima o valor das configurações do git core.excludesfile |
| git flow | um comando git que fica disponível após a instalação do gitflow |
Para ampliar o conhecimento sobre git config, a gente vai analisar o exemplo no qual o seguinte valor foi gravado:
git config --global user.name "yourname"
git config --global user.email "youremail@gmail.com"Nesse exemplo, o valor "Rish Rick" para user.name e o valor "shyoutarou@gmail.com" são definidos como o nome e e-mail. Ele usa o sinalizador --global, então esse valor é definido para o usuário atual do sistema operacional. Se você deseja alterar essa configuração global com um nome de usuário ou endereço de email diferente, mas apenas para um projeto específico, você pode executar os mesmos comandos, mas sem a opção --global.
Muitos comandos Git iniciam o editor de texto para solicitar mais entradas. Um dos casos de uso mais comuns para git config é configurar qual editor o Git deve usar. A tabela de editores populares e comandos git config correspondentes é apresentada abaixo:
| Editor | Comando |
|---|---|
| Atom | git config --global core.editor "atom --wait"~ |
| Emacs | git config --global core.editor "emacs"~ |
| Nano | git config --global core.editor "nano -w"~ |
| Vim | git config --global core.editor "vim"~ |
| Sublime Text (Mac) | git config --global core.editor "subl -n -w"~ |
| Sublime Text (Win, instalação 32-bit) | git config --global core.editor "'c:/program files (x86)/sublime text 3/sublimetext.exe' -w"~ |
| Sublime Text (Win, instalação 64 bit) | git config --global core.editor "'c:/program files/sublime text 3/sublimetext.exe' -w"~ |
| Textmate | git config --global core.editor "mate -w"~ |
| Visual Studio Code (VS Code) | git config --global core.editor "code --wait" |
| Notepad++ | git config core.editor "notepad++ -multiInst -nosession" |
Para obter ajuda sobre um comando Git específico, como o comando "git add", esta sintaxe pode ser:
| Comando | Descrição |
|---|---|
| git help help | Peça ao git para ajudar sobre seu sistema de ajuda |
| git help -a | Imprima todos os comandos disponíveis do git |
| git help -g | Imprima todos os guias disponíveis do git |
| git help glossary | Exibir o glossário git |
| git grep string | encontre todos os arquivos com o string fornecido |
Para mover a tela quando a quantidade de informações é muito grande (Ex.: comando help ou log), utilize o guia abaixo de comandos LESS:
| Comando | No | Descrição |
|---|---|---|
| e ^E j ^N CR | * | Avançar uma linha (ou N linhas) |
| y ^Y k ^K ^P | * | Retrocede uma linha (ou N linhas) |
| f ^F ^V SPACE | * | Avança uma janela (ou N linhas) |
| b ^B ESC-v | * | Retrocede uma janela (ou N linhas) |
| z | * | Avance uma janela (e defina a janela como N) |
| w | * | Retroceda uma janela (e defina a janela como N) |
| ESC-SPACE | * | Encaminha uma janela, mas não para no final do arquivo. |
| d ^D | * | Avance uma meia janela (e defina meia janela como N). |
| u ^U | * | Retroceda uma meia janela (e defina meia janela como N). |
| ESC-) RightArrow | * | Meia largura da tela à direita (ou posições N) |
| ESC-( LeftArrow | * | Esquerda e meia largura da tela (ou posições N) |
| ESC-} ^RightArrow | Direita para a última coluna exibida | |
| ESC-{ ^LeftArrow | Esquerda para a primeira coluna | |
| F | Avante para sempre; como "tail -f" | |
| ESC-F | Como F, mas para quando o padrão de pesquisa é encontrado. | |
| r ^R ^L | Repita a tela | |
| R | Repita a tela, descartando a entrada em buffer. | |
| Q | Sai da tela |
- Os comandos marcados com * podem ser precedidos por um número, N.
- As notas entre parênteses indicam o comportamento se N for fornecido. Uma chave precedida por um sinal de intercalação indica a tecla Ctrl; assim ^K é ctrl-K.
O Git era inicialmente um kit de ferramentas para um sistema de controle de versão e, por isso, possui vários subcomandos que executam trabalhos de baixo nível e foram projetados para serem encadeados no estilo UNIX ou chamados de scripts. Existem dois tipos de comandos no Git:
- Plumbing: comandos que dão acesso ao funcionamento interno do Git. Muitos desses comandos não devem ser usados manualmente na linha de comando, mas como blocos de construção de novas ferramentas e scripts personalizados.
- Porcelain: comandos mais amigáveis (checkout, branch, remote) que tornam o Git um VCS fácil de usar.
Quando você faz algo no Git, quase sempre dados são adicionados no banco de dados do Git - e não removidos. É difícil fazer algo no sistema que não seja reversível ou para fazê-lo apagar dados de forma alguma. Como em qualquer VCS, você pode perder alterações que ainda não tenham sido adicionadas em um commit; mas depois de fazer o commit no Git do estado atual das alterações, é muito difícil que haja alguma perda, especialmente se você enviar regularmente o seu banco de dados para outro repositório. Isso faz com que o uso do Git seja somente alegria, porque sabemos que podemos experimentar sem o perigo de estragar algo.
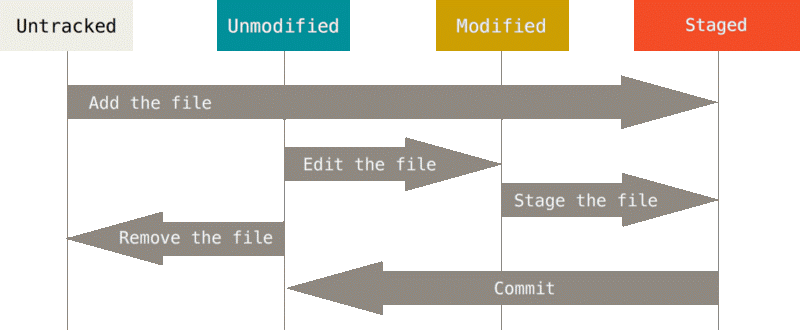
Cada um dos arquivos no diretório de trabalho está em um dos dois estados de alto nível:
- Arquivos rastreados (tracked files) - são arquivos que estavam no último instantâneo (snapshot); eles podem estar em um dos seguintes sub-estados:
- Não modificado (unmodified/commited) - são todos os arquivos que não foram modificados desde a última confirmação. Eles ainda serão incluídos no próximo commit, mas permanecerão como estão.
- Modificados (modified) - Estes são os arquivos que foram modificados desde a última confirmação (provavelmente os modificamos como parte das correções). Esses arquivos serão incluídos no próximo commit, mas serão incluídos no respectivo novo formulário.
- Preparado (staged) - Esses são arquivos que não estão presentes no último commit (por exemplo, arquivos recém-criados) ou são arquivos "modificados" que dizemos ao git para incluir no próximo commit. Os arquivos são adicionados à preparação usando o comando "add" do git.
- Arquivos não rastreados (untracked files) - todos os arquivos que não estão sendo rastreados, ou seja, o Git não existe. Você pode alterar o estado desses arquivos para "rastreado - preparado" usando o comando "add" do Git.
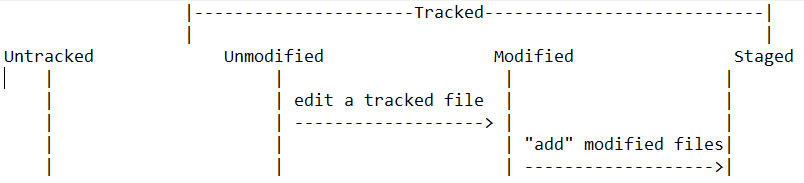
Se você clonar um repositório git, todos os arquivos do projeto serão iniciados no estado "não modificado".

Se você editar qualquer um desses arquivos (por exemplo, usando um editor de texto como o vim), o estado desses arquivos será alterado para "modificado"

Nesse estágio, se você fizer um git "commit", o arquivo editado não será confirmado, porque os arquivos modificados precisam primeiro ser "testados" para serem incluídos no próximo commit. Isso é feito usando o comando "add" do git:
Você também usa o comando "add" do git para ter novos arquivos "staged" para que eles sejam incluídos no próximo commit:

Depois disso, quando estiver satisfeito com tudo, você tira uma foto instantânea usando o comando "commit" do git. Isso resulta na sobreposição dos arquivos do commit anterior com os arquivos recentemente preparados, a fim de criar um novo instantâneo (também conhecido como commit). Você então repete o ciclo novamente.
Outra coisa que você pode querer fazer é remover um arquivo rastreado do projeto. Isso é feito usando o comando rm do git:

Um projeto git é composto de 3 partes principais:
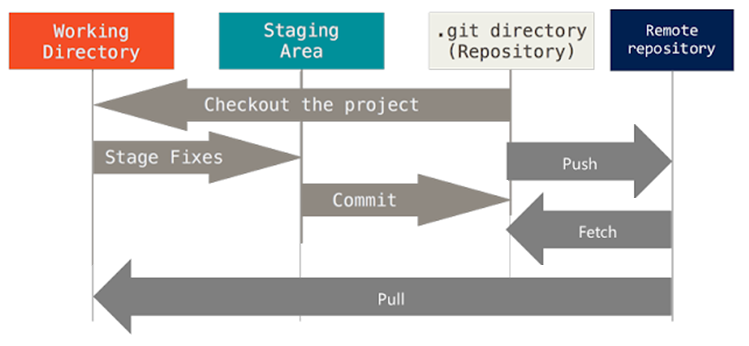
- Diretório de trabalho - Este é o diretório em que todos os arquivos e pastas do projeto residem (junto com a pasta .git). Cada um dos seus arquivos neste diretório está em um dos possíveis estados, não rastreados, não modificados, modificados, em etapas. É aqui que você trabalha, edita seus arquivos, testa seu código. O Git geralmente respeitará a área de trabalho para evitar a destruição de dados, mas existem alguns comandos que destroem os dados na área de trabalho. Portanto, em geral, não assuma que seus dados estão seguros até que você os tenha confirmado. Depois de confirmar seus dados, o Git os armazena no que considera a área realmente importante, o repositório.
- Área de preparação (Staging Area/Index) - Essa é uma camada hipotética que fica no topo da camada da última confirmação. Quando você executa o comando "git commit", as duas camadas são mescladas. Todos os arquivos que estão na camada de confirmação, que possuem um arquivo mais novo diretamente acima (na "camada intermediária"), serão sobrescritos pelo arquivo mais recente (preparado). Observe que o conteúdo de um arquivo é rastreado para que você possa reverter a aparência do arquivo nos instantâneos anteriores (confirmações). Observe que a área de preparação também é conhecida como "índice". Praticamente todos os sistemas de controle de versão existentes têm uma área de trabalho e um repositório, mas o índice é exclusivo do Git, ou pelo menos o Git é o único sistema de controle de versão que permite modificar o índice diretamente. Você pode visualizar o índice como algo que fica entre a área de trabalho e o repositório. Você geralmente não move os dados da área de trabalho diretamente para o repositório, mas percorre o índice.
- Diretório. git - este é basicamente o banco de dados do seu repositório git. Este é provavelmente o principal motivo pelo qual você usa o Git. O repositório contém todo o histórico do projeto. Quando você faz o commit, ele vai aqui.
- O Stash (esconderijo): é como uma área de transferência que você pode usar para armazenar dados temporariamente enquanto manipula as outras áreas.
A maioria dos comandos no Git pode ser entendida em termos de dois elementos:
- Como esse comando move os dados pelas quatro áreas? Ele copia dados do índice para o repositório? Do repositório para a área de trabalho? Exclui dados de qualquer uma das áreas?
- O que esse comando faz ao repositório? O repositório é a mais importante das quatro áreas. Então, como esse comando altera os dados lá? Ele cria novas confirmações, move ramificações, move a referência do cabeçalho?
Não importa o quão confuso um comando pareça. Se você puder responder a essas duas perguntas, poderá obtê-lo, pelo menos amplamente. Se você deseja obter um novo arquivo rastreado pelo repositório git, use o comando “git checkout” para efetuar o checkout do projeto. Isso extrairá o commit mais recente (instantâneo) do banco de dados do repositório .git (para uma ramificação específica) e o colocará no diretório de trabalho. Todos os arquivos recém-retirados têm o estado do arquivo “não modificado” (mais sobre os estados dos arquivos posteriormente).

Adicione/crie o arquivo em algum lugar dentro do diretório de trabalho. Isso tornará o git ciente da existência desse arquivo e não o acompanhará. ou seja, o estado do arquivo é "não rastreado". Use o comando "git add" para colocar esse arquivo na área de preparação, esperando para ser mesclado na confirmação anterior (captura instantânea). Isso mudará o estado do arquivo para "staged".
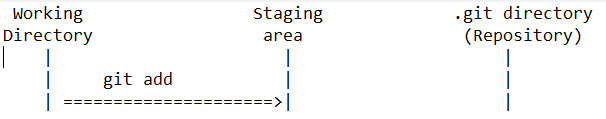
Use o comando "git commit" para adicionar o arquivo e criar uma nova captura instantânea composta da "layer" de confirmação anterior, juntamente com os arquivos na "staged layer". Isso mudará o estado do arquivo para "não modificado".

Em sua essência, o Git é apenas um mapa, uma estrutura simples que mapeia chaves para valores, e essa estrutura é persistente, está armazenada no seu disco. Os valores são apenas sequências de bytes. Por exemplo, o conteúdo de um arquivo de texto ou mesmo um arquivo binário. Qualquer sequência de bytes pode ser um valor. Você pode atribuir um valor ao Git e ele calculará uma chave para ele, um hash. O Git calcula hashes com o algoritmo SHA-1, conhecido de maneira informal também como "Shawn". A seguir a descrição de alguns comandos Git que podem ser utilizados:
| Comando | Descrição |
|---|---|
| echo "Apple Pie" | git hash-object --stdin | Imprime e gera um SHA-1 da string. Se adicionar o parâmetro –w é gravado a string dentro do diretório .git/object |
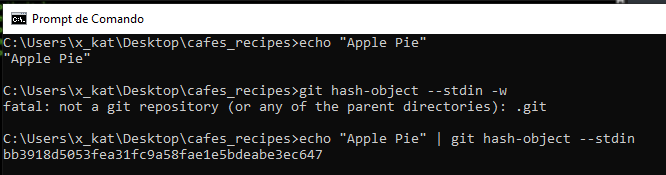
Cada parte do conteúdo possui seu próprio SHA ‑ 1. Por exemplo, vamos pegar um conteúdo, a sequência "Apple Pie". Se você pedir ao Git para gerar um SHA-1 a partir dessa string, você obterá esse hash.
Apple Pie = bb3918d5053fea31fc9a58fae1e5bdeabe3ec647Existe apenas um hash para essa sequência. Os SHA-1s são 20 bytes no formato hexadecimal, portanto, são uma sequência de 40 dígitos hexadecimais. Essa será a chave do Git para armazenar esse conteúdo no mapa. Também podemos calcular o SHA-1 na linha de comando com o comando git hash-object. Primeiro, devemos usar o comando echo para gerar esse conteúdo e canalizar o resultado em um objeto hash. Se digitarmos o comando diretamente o Git pensará que "Apple Pie" é o nome de um arquivo e emitirá erro.
Se você alterar alguma coisa no conteúdo, uma única letra, você obterá um SHA-1 completamente diferente. Todo objeto em um repositório Git tem um SHA1. Se você colocar a sequência "Apple Pie" no arquivo e armazená-lo no Git, o SHA-1 que acabamos de gerar identificará o arquivo. Os diretórios também têm seu próprio SHA-1, assim como confirmações e assim por diante. Para todos os fins práticos, os SHA1-s são únicos. Não apenas o único em seu projeto, você pode pensar neles como se fossem únicos no universo. Você pode colocar todos os dados que você escreverá em sua vida no mesmo repositório Git, e o Git atribuirá um SHA-1 diferente para cada versão de cada arquivo em cada pasta.
Se quiser que o conteúdo "Apple Pie" seja persistente, posso adicionar o argumento -w a este comando. -W significa gravação. Então agora, além de gerar o hash, o Git também salvará esse conteúdo em seu repositório. No entanto, agora ainda não temos um repositório, se eu tentar esse comentário imediatamente, o Git reclama.

Com o Git instalado, é hora de adicionar o Git ao seu projeto. Isso é feito inicializando um novo repositório git, que são um armazenamento virtual do seu projeto. Em outras palavras, cada projeto no Git é referenciado como repositório para inicializar um novo projeto ou um projeto que já existe. Primeiro você precisa navegar até essa pasta do projeto usando o comando cd.
C:\Users\x_kat\Desktop\cafes_recipesA seguir a descrição de alguns comandos Git que podem ser utilizados:
| Comando | Descrição |
|---|---|
| git init | Inicialize um repositório git no repositório atual |
| git ls-files | Listar os arquivos no repositório |
| git ls-files | xargs cat | wc -l git ls-files | xargs wc -l |
No PowerShel, conta o total de linhas do arquivos do repositório, recursivamente. |
| start PATH | Abre o Windows Explorer no caminho espicificado |
Agora que estamos na pasta, a inicialização de repositórios Git é feita digitando o comando Git init. Depois de executado, você verá uma mensagem de resposta que diz inicializada.

Quando você executa o git init em um diretório novo ou existente, o Git cria o diretório .git, que é onde quase tudo o que o Git armazena e manipula está localizado. Se você deseja fazer backup ou clonar seu repositório, copiar esse diretório único em outro lugar oferece quase tudo o que você precisa. O subdiretório .git que marcou essa pasta do projeto e todo o seu conteúdo para ser controlado por versão; esse subdiretório .git está oculto por padrão.
Mas você pode entrar nessa pasta digitando “cd .git” e, em seguida, você pode usar o comando dir para fornecer uma lista dos arquivos nessa pasta.
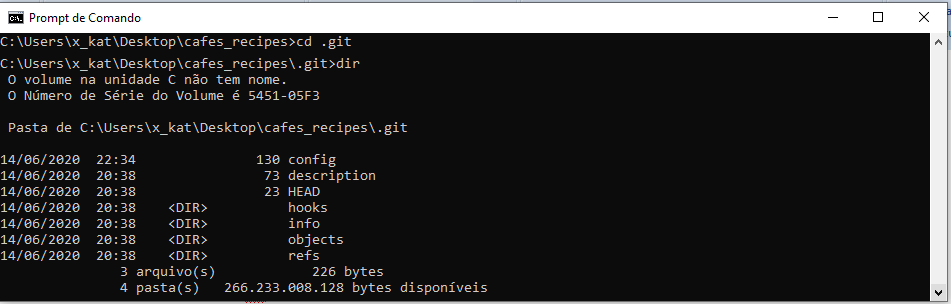
O diretório .git contém todos os metadados importantes para obter esses novos repositórios. Para abrir o diretório no Windows Explorer, digite no Windows:
start .gitVocê pode ver outros arquivos lá, mas este é um repositório git init novo, é o que você vê por padrão.
| Entrada | Descrição |
|---|---|
| arquivo description | é usado apenas pelo programa GitWeb |

| Entrada | Descrição |
|---|---|
| arquivo config | opções de configuração específicas do projeto |
| diretório info | mantém um arquivo de exclusão global para padrões ignorados que você não deseja rastrear em um arquivo .gitignore |
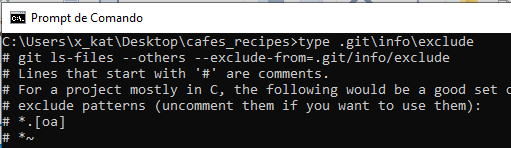
| Entrada | Descrição |
|---|---|
| diretório hooks | contém os scripts hook do lado do cliente ou do servidor |
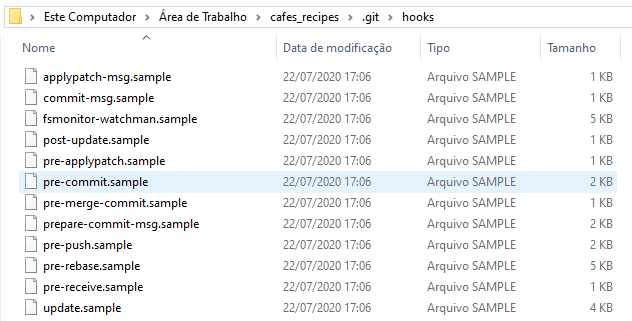
Isso deixa quatro partes principais do Git que iremos ver com mais detalhes:
| Entrada | Descrição |
|---|---|
| diretórios objects | armazena todo o conteúdo do seu banco de dados (blob, tree, commits e tags) |
| diretórios refs | armazena ponteiros em objetos commit nesses dados (ramificações) |
| arquivo HEAD | aponta para a ramificação que você fez check-out |
| arquivos de índice | armazena sua área de armazenamento temporário em formação |
Git é um sistema de arquivos endereçável por conteúdo, isso significa que, no centro do Git, há um simples armazenamento de dados de valores-chave. Você pode inserir qualquer tipo de conteúdo e fornecerá uma chave que você pode usar para recuperar o conteúdo novamente a qualquer momento. Para demonstrar, você pode usar o comando de plumbing hash-object, que pega alguns dados, armazena-os no diretório .git e devolve a chave em que os dados estão armazenados. Primeiro, você inicializa um novo repositório Git e verifica se não há nada no diretório de objetos:
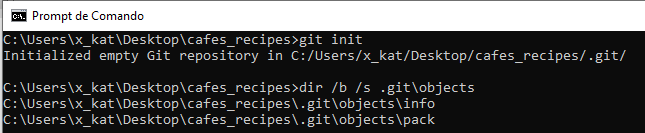
O Git inicializou o diretório de objetos e criou subdiretórios de pacote e informações, mas não há arquivos regulares. E se executarmos novamente o comando git hash-object para a string "Apple Pie" com –w, obteremos o hash e também salvaremos o conteúdo no diretório, objetos dentro do diretório .git.
echo "Apple Pie" | git hash-object –w --stdin

O -w diz ao objeto hash para armazenar o objeto; caso contrário, o comando simplesmente informa qual seria a chave. --stdin diz ao comando para ler o conteúdo do stdin; se você não especificar isso, o hash-object espera um caminho de arquivo no final. A saída do comando é um hash de soma de verificação de 40 caracteres. Esse é o hash SHA-1 - uma soma de verificação do conteúdo que você está armazenando e um cabeçalho. Agora você pode ver como o Git armazenou seus dados:


No subdiretório bb, que são os dois primeiros dígitos hexadecimais do SHA-1 da string que acabamos de salvar. E se olharmos dentro de bb, há um arquivo aqui e o nome desse arquivo são os 38 caracteres restantes do SHA-1. O Git usa esse esquema para organizar o conteúdo e distribuí-lo por vários diretórios. É apenas um truque para evitar acumular todo o conteúdo em um único diretório desordenado. Além disso dependendo dos sistemas de arquivos o número máximo de arquivos em uma única pasta varia e, ao criar subdiretórios, ajuda a balancear a carga de arquivos por diretório.
| Sistema | Máximo de arquivos |
|---|---|
| FAT/FAT16 | 512 |
| FAT32 | 65,534 |
| NTFS | 4,294,967,295 |
| exFAT | 2,796,202 |
Os dados mais importantes estão no diretório chamado banco de dados de objetos. Existem alguns tipos diferentes de objetos no banco de dados;
- objetos blobs: representam o conteúdo de um arquivo em algum momento da história do projeto.
- objetos tree (árvores): que representam pastas no projeto. É um ponteiro SHA-1 para um blob ou subárvore com seu modo, tipo e nome de arquivo associados.
- objetos commit: Sempre que você faz um commit do git, o Git cria um commit.
Todos esses objetos são imutáveis, podem ser criados e excluídos, mas nunca podem ser alterados. Esses objetos são vinculados em uma estrutura que representa o histórico do seu projeto.
Nossa sequência original, "Apple Pie", está dentro desse arquivo. Isso é o que o Git chama de blob de dados. Um blob é uma parte genérica do conteúdo, onde o Git adicionou um cabeçalho pequeno e compactou o conteúdo para economizar espaço. Portanto, não podemos simplesmente abrir o arquivo e lê-lo. Para examinar o conteúdo podemos usar outro comando chamado git cat-file.
| Comando | Descrição |
|---|---|
| git cat‑file SHA1 | Pega o SHA‑1 de um objeto e um argumento. Se o argumento for -t, retorna o tipo de arquivo, se o argumento for –p realiza impressão elegante. |
| echo 'version 1' > test.txt | Gera/Altera arquivo com conteúdo 'version 1' |
| git hash-object -w text.txt | Gera SHA‑1 de arquivo no banco de dados |
O comando git cat-file pega o SHA‑1 de um objeto e um argumento. Se o executarmos com o argumento -t, significa type, que no caso aqui é um blob. E se o executarmos novamente com –p para uma impressão elegante, o Git descompacta o objeto, remove o cabeçalho e imprime o conteúdo real do blob.

Até agora, vimos que o Git é capaz de pegar qualquer parte do conteúdo, gerar a chave para ele, um SHA-1, e depois persistir o conteúdo no repositório como um blob, um mapa persistente. Agora, você pode adicionar conteúdo ao Git e retirá-lo novamente. Você também pode fazer isso com o conteúdo dos arquivos. Por exemplo, você pode fazer algum controle de versão simples em um arquivo. Primeiro, crie um novo arquivo e salve seu conteúdo no seu banco de dados: echo 'version 1' > test.txt
Em seguida, escreva um novo conteúdo no arquivo e salve-o novamente:
Seu banco de dados contém as duas novas versões do arquivo, bem como o primeiro conteúdo armazenado lá:
Agora você pode reverter o arquivo para a primeira versão git cat-file -p d2a4cbf60df98ddfaaea1facf3ce68f66ef7e566 > test.txt
ou a segunda versão: git cat-file -p 9829369082a0c64c09551dbc07bf8f799a533245 > test.txt
Mas lembrar a chave SHA-1 para cada versão do seu arquivo não é prático; além disso, você não está armazenando o nome do arquivo no seu sistema, apenas o conteúdo. Mas é apenas uma demonstração de que poderíamos até apagar o arquivo que conseguiríamos recuperar o conteúdo no arquivo a partir do versionamento de repositório é assim que comandos como o git check-out funcionam.
Outra coisa é que se tentar acessar diretamente o conteúdo de qualquer objeto SHA-1:
Isso ocorre pois o Git compacta todos objetos com o zlib, o que você pode fazer no Ruby com a biblioteca zlib e executando Zlib :: Deflate.deflate () no conteúdo.
Objetos Tree
O próximo tipo que veremos é a árvore, que resolve o problema de armazenar o nome do arquivo e também permite que você armazene um grupo de arquivos juntos. O Git armazena conteúdo de maneira semelhante a um sistema de arquivos UNIX, mas um pouco simplificado. Todo o conteúdo é armazenado como objetos de árvore e blob, com árvores correspondentes às entradas do diretório UNIX e blobs correspondendo mais ou menos a inodes ou conteúdo de arquivo. Um único objeto de árvore contém uma ou mais entradas de árvore, cada uma contendo um ponteiro SHA-1 para um blob ou subárvore com seu modo, tipo e nome de arquivo associados.
Você pode criar facilmente sua própria árvore. O Git normalmente cria uma árvore, tomando o estado da sua área de preparação ou índice e gravando uma série de objetos da árvore. Então, para criar um objeto de árvore, você primeiro precisa configurar um índice, preparando alguns arquivos. Para criar um índice com uma única entrada - a primeira versão do seu arquivo test.txt - você pode usar o comando plumbing update-index. Você usa este comando para adicionar artificialmente a versão anterior do arquivo test.txt a uma nova área de preparação. Você deve passar a opção --add porque o arquivo ainda não existe na sua área de preparação (você ainda nem tem uma área de preparação configurada) e --cacheinfo porque o arquivo que você está adicionando não está no seu diretório, mas está no seu banco de dados. Em seguida, você especifica o modo, SHA-1 e nome do arquivo: C:\Users\x_kat\Desktop\cafes_recipes>git update-index --add --cacheinfo 100644 d2a4cbf60df98ddfaaea1facf3ce68f66ef7e566 test.txt
Nesse caso, você está especificando um modo de 100644, o que significa que é um arquivo normal. Outras opções são 100755, o que significa que é um arquivo executável; e 120000, que especifica um link simbólico. O modo é retirado dos modos normais do UNIX, mas é muito menos flexível - esses três modos são os únicos válidos para arquivos (blobs) no Git (embora outros modos sejam usados para diretórios e submódulos). No Linux esta coinvecção aparece no comando chmod(CHange MODe) onde 644 é um arquivo normal, 755 arquivo executável ou sendo mais exato o primeiro número é um modo para o usuário dono do arquivo, o segundo número é um modo para o grupo, e o terceiro é o modo para qualquer outros usuário. 7 é ler/ escrever/executar cinco é ler/executar quatro é só leitura e assim por diante conforme tabela abaixo:
Ao rodar esse comando ele cria o arquivo .git/index que não existia na inicialização do projeto, ele tem agora o conteúdo:
Agora, você pode usar o comando write-tree para gravar a área intermediária em um objeto em árvore. A opção no -w é necessária. A chamada write-tree cria automaticamente um objeto em árvore a partir do estado do índice se essa árvore ainda não existir: git write-tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
Você também pode verificar se este é um objeto de árvore
Agora você criará uma nova árvore com a segunda versão do test.txt e também um novo arquivo:
Sua área de preparação agora tem a nova versão do test.txt, bem como o novo arquivo new.txt. Escreva essa árvore (registrando o estado da área intermediária ou o índice em um objeto em árvore) e veja como ela se parece:
Observe que essa árvore possui as duas entradas de arquivo e também que o test.txt SHA-1 é o "versão 2" SHA-1 da versão anterior (1f7a7a). Apenas por diversão, você adicionará a primeira árvore como um subdiretório a essa. Você pode ler árvores na sua área de preparação chamando a árvore de leitura. Nesse caso, você pode ler uma árvore existente em sua área intermediária como uma subárvore usando a opção --prefix para ler a árvore:
Se você criou um diretório de trabalho a partir da nova árvore que você acabou de escrever, obteria os dois arquivos no nível superior do diretório de trabalho e um subdiretório chamado bak, que continha a primeira versão do arquivo test.txt. Você pode pensar nos dados que o Git contém para essas estruturas como este:
Objetos Commit
Você tem três árvores que especificam os diferentes instantâneos do seu projeto que deseja rastrear, mas o problema anterior permanece: você deve lembrar dos três valores do SHA-1 para recuperar os instantâneos. Você também não tem informações sobre quem salvou os instantâneos, quando eles foram salvos ou por que eles foram salvos. Essas são as informações básicas que o objeto de confirmação armazena para você.
Para criar um objeto de consolidação, chame commit-tree e especifique uma única árvore SHA-1 e quais objetos de consolidação, se houver, a precederam diretamente. Comece com a primeira árvore que você escreveu: echo 'first commit' | git commit-tree 7d8e5ff0
Agora você pode olhar para o seu novo objeto de confirmação com o arquivo cat-file que tem um valor de hash diferente devido a diferentes horários de criação e dados do autor.
O formato para um objeto de confirmação é simples: especifica a árvore de nível superior para a captura instantânea do projeto naquele momento; as informações do autor/responsável (que usa as definições de configuração user.name e user.email e um carimbo de data/hora); uma linha em branco e, em seguida, a mensagem de confirmação.
Em seguida, você escreverá os outros dois objetos de confirmação, cada um referenciando o commit que veio diretamente antes dele:
Cada um dos três objetos de confirmação aponta para uma das três árvores de captura instantânea que você criou. Curiosamente, você tem um histórico real do Git agora que pode ver com o comando git log, se o executar no último commit SHA-1:
Você acabou de executar as operações de baixo nível para criar um histórico do Git sem usar nenhum dos comandos de porcelana. Isso é essencialmente o que o Git faz quando você executa os comandos git add e git commit - ele armazena blobs para os arquivos que foram alterados, atualiza o índice, grava árvores e grava objetos de commit que fazem referência às árvores de nível superior e aos commit que veio imediatamente antes deles. Esses três objetos principais do Git - o blob, a árvore e o commit - são inicialmente armazenados como arquivos separados no diretório .git/objects. Aqui estão todos os objetos no diretório de exemplo agora, comentados com o que eles armazenam: dir .git\objects /b /s
copy NUL arquivo OU echo >> arquivo
Por exemplo, ao adicionar um novo arquivo em seus repositórios chamado vendors com o comando: copy NUL vendors.txt OU echo >> vendors.txt
Ao executarmos novamente o comando Git status, veremos agora que o Git destaca os arquivos não rastreados e Git fornece algumas informações úteis sobre como adicionar esse arquivo não rastreado.
Ao rastrear esse arquivo digitando o comando: git add vendors.txt e executarmos, git status.
start notepad++ arquivo OU start code arquivo
Vemos que novo arquivo txt está sendo rastreado e que é há uma nova alteração aguardando confirmação. Os arquivos modificados que foram adicionados agora estão na fase de preparação aguardando a serem confirmadas. O Git status nos fornece outra mensagem que diz como redefinir ou remover arquivos da área de preparação. Antes de confirmar este arquivo, vamos adicionar algumas alterações neste arquivo que já está sendo rastreado. Abra o arquivo chamando seu editor padrão com o comando: start notepad++ vendors.txt
Adicione um novo vendedor que acabou de ser contratado, salve esse arquivo e volte à janela do terminal. Se digitarmos Git status novamente, veremos que o arquivo vendors.txt agora está na seção de mudanças, não para a confirmação.
Isso significa que o arquivo está sendo rastreado por Git e foi modificado em nosso diretório de trabalho, mas ainda não foi adicionado à nossa área de preparação para o commit. Para isso, é usado novamente o git add que serve tanto para rastrear novos arquivos, bem como arquivos modificados. Se alterarmos novamente um arquivo que já estivesse na área de preparados como, por exemplo employees.txt, teríamos o seguinte:
Agora se inserirmos este arquivo na aréa de preparados com o comando add mas, após isso, editarmos o arquivo novamente teríamos:
Observe que agora o arquivo employees.txt está em dois estágios ao mesmo tempo, no estágio pronto para serem confirmado, bem como no estágio de alterações modificadas ainda não preparadas. Quando preparamos pela primeira vez nossos funcionários, essas alterações foram adicionadas naquele momento para serem preparadas mas, quando alteramos o arquivo em seguida, o Git entende isso como uma nova alteração que não foi adicionado para área de preparação. Isso significa se confirmarmos com o comando comitt antes de adicionar o arquivo employees na área de preparados, as alterações do arquivo não serão inclusas na confirmação.
Como já foi mencionado cada arquivo em nosso projeto pode estar em um dos dois estados: rastreado ou não rastreado. Os arquivos rastreados são aqueles que estavam nos arquivos rastreados anteriores do snapshot anterior e podem estar em um dos três estados, que são: Não modificado (unmodified/commited), Modificados (modified) e Preparado (staged). Quando fazemos uma alteração em nosso arquivo confirmado ou não modificado, ele passa de um estágio confirmado para o estágio modificado. Quando estamos satisfeitos com nossas alterações e queremos prepará-las para confirmação, as adicionamos à nossa área de preparação. Em seguida, pegamos as alterações na área preparada e as confirmamos em nossos repositórios.
Preparando (Stage)
Antes de passarmos para a linha de comando, será necessário copiar a URL https, no topo da página: https://github.com/shyoutarou/wired-brain-recipes.git
Para adicionar o arquivo README.md digite o seguinte comando: echo "# wired-brain-recipes" >> README.md
Agora que adicionamos o arquivo README.md ao nosso projeto, precisamos adicionar esse arquivo à nossa área de preparação para que eles possam ser confirmados e, portanto, rastreados por Git, podemos adicionar todos esses arquivos à nossa área de preparação digitando o comando: git add .
Comando Descrição git status Exibir status do diretório atual, no que se refere ao Git git add FILE Comece a rastrear FILE no Git; adiciona FILE à área de preparação git add –dry-run Mostrar o que o git add faria git add . Adicione todos os novos arquivos ao repositório git git add -i Com a opção -i ou --interactive, o Git entrará em um modo de shell interativo git add -p Permite selecionar pedaços (hunk) de um arquivo para serem preparados git add -patch git reset -- FILE Tira só um arquivo do stage
Interactive Staging
O Git vem com alguns scripts que facilitam algumas tarefas da linha de comando. Aqui, você verá alguns comandos interativos que podem ajudá-lo a criar facilmente seus commits para incluir apenas determinadas combinações e partes de arquivos. Essas ferramentas são muito úteis se você modificar um monte de arquivos e decidir que deseja que essas alterações estejam em várias confirmações focadas, em vez de uma grande confirmação confusa. Dessa forma, você pode garantir que seus commits sejam conjuntos de alterações logicamente separados e possam ser facilmente revisados pelos desenvolvedores que trabalham com você.
Uma coisa muito comum é você criar arquivos relacionados a uma coisa e depois resolve codar outra coisa não relacionada, só que agora você ficou com duas coisas não relacionadas que precisa comitar. A maioria das pessoas faz um git add . e comita tudo junto. O correto seria que cada commit contenha apenas uma uma pequena funcionalidade de cada vez. Um commit pra correção de bugs. Um commit pra documentação. Por exemplo, não faz sentido você misturar um arquivo CSS de uma tela com uma linha nova de README descrevendo infra.
A coisa mais simples é dar git add e o nome do css e fazer o commit só do css. Depois fazer git add separado do readme e um commit só pra ele.
Quando você tem poucos arquivos esse é o jeito mais simples. Mas normalmente você se empolga, ou tá usando algum gerador de código de algum framework e fica com vários arquivos. Digamos que você digitou git add . agora todos os arquivos estão misturados no stage e se você der git commit vai tudo pro mesmo commit. Se for só um arquivo que você quer tirar do stage basta fazer: git reset -- FILE
Mas como eu falei, faz de conta que são uma dúzia de arquivos e você deu git add . de tudo. Se você executar o git add com a opção -i ou --interactive, o Git entrará em um modo de shell interativo.
Você pode ver que este comando mostra uma visão muito diferente da sua área de preparação - basicamente as mesmas informações que você obtém com o status git, mas um pouco mais sucinto e informativo. Ele lista as alterações que você realizou à esquerda e as alterações sem etapas à direita. Depois disso, vem uma seção de comandos. Aqui você pode fazer várias coisas, incluindo arquivos preparados, arquivos não-preparados, partes preparadas de arquivos, adiçionar arquivos não rastreados e visualização de diferenças do que foi preparado. Ao optar por 3 que é revert.
Ele vai listar os arquivos que estão no stage e você pode só digitar o número dos arquivos que não quer comitar agora. No final dá enter pra voltar pro menu anterior.
O * ao lado de cada arquivo significa que o arquivo está selecionado para ser preparado. Digamos que você olha e tinha um arquivo que eu tirei que era pra estar lá mesmo na real. Então você tem a opção 2 de update(para arquivos já rastreados) ou 4 de add untracked .
É o oposto, agora você digita o número do arquivo que quer colocar no stage. Dá enter no final, e no menu principal digita q pra dar quit e sair. Vamos dar git status, é como se tivéssemos dado git add manualmente arquivo por arquivo. Agora sim podemos fazer o commit correto e fazer git add -i de novo pra ir adicionando arquivos pro próximo commit.
Para ver o diff do que você preparou, você pode usar o comando 6 ou d (para diff). Ele mostra uma lista dos seus arquivos temporários e você pode selecionar aqueles para os quais gostaria de ver o diff. É como especificar git diff --cached na linha de comando:
Com esses comandos básicos, você pode usar o modo de adição interativo para lidar com sua área de preparação um pouco mais facilmente.
Aliás, como o Git rastreia conteúdo e não diretórios, por isso que diretórios vazios nunca entram num repositório Git e por isso muitos frameworks reservam diretórios vazios colocando um arquivo vazio escondido como .gitkeep só pro diretório ter alguma coisa e com isso conseguir adicionar no Git.
Podemos adicionar todas as modificações de um ou mais arquivos com os comandos git add ou git add interativo -i ou adicionar um hunk de cada arquivo de cada vez usando git add -p. Uma vez que eu tenho tudo que eu quero no stage, posso empacotar com o comando git commit, onde você cadastra uma mensagem e o git vai terminar adicionando o resto dos metadados pra grudar seu commit como a nova cabeça do grafo, com a etiqueta de HEAD.
Preparando patches
Também é possível para o Git organizar determinadas partes dos arquivos e não o restante. Se no mesmo arquivo temos modificações em que parte é pra ir num commit e outra parte é pra ir em outro commit. Por exemplo, se você fizer três alterações no seu arquivo README que preparamos e confirmamos. Depois faemos 3 modificações no arquivo. Vamos digitar git diff pra ver o patch completo.
Agora eu queria que a primeira modificação e a terceira fossem um commit só. E a segunda modificação fosse um commit separado. Se der git add e comitar vai tudo no mesmo commit. Pra isso no prompt interativo, digite 5 ou p (para correção).
Você também não precisa estar no modo de adição interativo para fazer a preparação parcial do arquivo - é possível iniciar o mesmo script usando git add -p ou git add --patch na linha de comando.
git add –p OU git add --patch
O Git perguntará quais arquivos você gostaria de montar parcialmente; então, para cada seção dos arquivos selecionados, ele exibirá pedaços (hunk) do arquivo diff e perguntará se você gostaria de prepará-los, um por um:
Opção Descrição
y encenar este pedaço
n não encenar este pedaço
a encenar este e todos os pedaços restantes no arquivo
d não encenar este pedaço nem nenhum dos pedaços restantes no arquivo
g selecione um pedaço para ir
/ procure um pedaço correspondente ao regex especificado
j deixe este pedaço indeciso, veja o próximo pedaço indeciso
J deixe este pedaço indeciso, veja o próximo pedaço
k deixe esse pedaço indeciso, veja o pedaço indeciso anterior
K deixe este pedaço indeciso, veja o pedaço anterior
s dividir o pedaço atual em pedaços menores e - editar manualmente o pedaço atual
? imprimir ajuda
A idéia é que o git vai perguntar um hunk de modificação de cada vez. Veja só, como as modificações estão próximas ele me pergunta se quer adicionar elas juntas para o stage. Se eu quisesse bastaria digitar y de yes, ou se eu quiser pular eu digito n pra não e esse tanto de opção aqui embaixo se eu der enter ou interrogação, ele vai explicar todas as opções que eu tenho. No caso, não queremos adicionar tudo junto e queremos dividir. Pra isso eu digito s de split, e veja só ele dividiu o hunk mais uma vez e me deu só a primeira parte! Então vamos dar yes.
O próximo hunk é o que eu quero separado, então digito “no” pra pular.
E a última eu também quero no mesmo commit, então dou yes. Se eu quisesse parar no meio, só digitar q de quit.
Nesse ponto, você pode sair do script de adição interativo. Se eu der git status vemos que parte do arquivo README está no stage e parte não está. Isso mostra que algumas linhas são preparadas e outras não. Você preparou parcialmente esse arquivo.
Se eu der git diff –staged ou --cached pra ver só o que vai no próximo commit, veja que está só o hunk que eu escolhi.
Nesse ponto, você pode executar o git commit para confirmar os arquivos parcialmente preparados. A segunda modificação tem que adicionar no stage e criar o segundo commit.
Mas resumindo, eu tinha modificações num mesmo arquivo que eu queria separar em commits diferentes. Pra isso usamos git add -p. Além disso, você pode usar o modo de correção para redefinir parcialmente os arquivos com o comando git checkout, git stash e até git reset. Em todos esses casos, você pode dizer –patch, e isso significa que eu deixe essa operação não arquivo por arquivo, mas por pedaço por pedaço. Assim, você pode decidir quais alterações dentro de cada arquivo.
Confirmando (Commit) alterações
A seguir estão alguns exemplos de comandos utilizados: Comando Descrição git commit -m MSG Confirme as alterações no repositório git, com uma mensagem entre aspas git commit -a -m MSG Adiciona os arquivos não preparados e cria um novo objeto de confirmação git commit –allow-empty -m "Initial commit" Crie um commit sem adicionar nenhum arquivo git count-objects Retorna o numero de objetos gerados em .git/objects
E para confirmarmos as alterações, digitamos o comando commit com o parâmetro –m para adicionarmos uma mensagem: git commit –m “first commit”
git commit -a -m "add new vendors"
Ao adicionar o parâmetro “-a” ao comando commit elimina a necessidade de aplicar o comando de adicionar (add) no estágio de preparados e adiciona-os diretamente ao estágio de confirmados. Mas isso acontece apenas aos arquivos que estejam sendo rastreados, arquivos novos (com a marcação ??), precisam ser aplicados o comando add antes de ser confirmados.
Sempre quando confirmarmos alterações elas resultam em novo SHA-1 de confirmação, como o seguinte:
commit 8f7c0eba8ae478a62622398165156b9391628963
Ao navegarmos para pasta .git/object podemos ver que foi gerado o objeto de confirmação compactada como um blob:
Ao usar o git cat-file para imprimir o conteúdo do commit, podemos observar que ele é um texto simples e muito curto, nada mais. O Git gera esse texto e o armazena da mesma maneira que armazena um blob. Ele gera seu SHA‑1, adiciona uma pequena letra ao texto para dizer que é uma confirmação, compacta o texto e armazena o resultado em um arquivo no banco de dados do objeto. O texto de confirmação contém todos os metadados sobre a confirmação, o nome do autor, o confirmador, data da confirmação e a mensagem e, em seguida, contém algo mais: o SHA-1 de uma árvore. Com exceção primeiro commit, a maioria dos commits são vinculados por um pai (parent).
Assim como um blob é o conteúdo de um arquivo armazenado no Git, uma árvore é um diretório armazenado no Git. A confirmação está apontando para o diretório raiz do projeto. É isso que é essa árvore, a raiz do projeto. Se você procurar no banco de dados de objetos, verá um diretório nomeado com os dois primeiros dígitos do hash da árvore e, dentro dele, a árvore, um arquivo nomeado com os dígitos restantes do hash, como de costume.
É como uma confirmação, uma parte do conteúdo que é gerada pelo Git e, em seguida, processada e armazenada no banco de dados do objeto. Cada confirmação aponta para um gráfico de blobs e árvores que representam seus arquivos e pastas no momento da confirmação. Por exemplo, o commit 1 está apontando para certos blobs e árvores, e o commit 2 está apontando para outros blobs e árvores.
Portanto, cada confirmação é como uma foto instantânea (snapshot) da sua área de trabalho em um determinado momento. Além disso, duas confirmações podem compartilhar o mesmo objeto. Isso significa que os objetos em destaque, neste caso são dois arquivos no diretório, não foram alterados entre esses dois commits, e é dessa maneira que o Git armazena alterações nos seus arquivos e diretórios.
Assim como um commit, uma árvore é um pequeno pedaço de texto, é tudo o que existe e contém uma lista do conteúdo do diretório, uma lista dos SHA-1s na verdade.
Os 6 digito iniciais são dados adicionais para as permissões de acesso do arquivo e do diretório. O nome do arquivo e as permissões do arquivo não são armazenados no blob, eles são armazenados na árvore que aponta para o blob.
A árvore recipes está apontando para o blob com o conteúdo de apple_pie.txt, que é o mesmo conteúdo que o arquivo menu.txt, portanto, na verdade, é o mesmo blob. Como esses dois arquivos têm exatamente o mesmo conteúdo, o Git não criará dois objetos separados para eles, apenas reutilizará o objeto existente que já está no banco de dados. Portanto, um blob não é realmente um arquivo, um blob é apenas o conteúdo de um arquivo.
Se você tentar criar exatamente o mesmo projeto e fornece os mesmos comandos que outra pessoa fornece ao Git, verá que obtém exatamente os mesmos SHA-1s para todas as árvores e todos os blobs. O importante a entender aqui é que não há mágica por trás do SHA-1. Se você tem o mesmo conteúdo que outra pessoa, obtém os mesmos hashes. No entanto, o SHA‑1 do commit será diferente, porque você tem dados diferentes no commit, um autor diferente e uma data de commit diferente. Uma confirmação também é apenas uma parte do conteúdo, e sua confirmação tem um conteúdo diferente do meu, então você obterá um hash diferente.
Vamos fazer uma alteração no arquivo menu.txt chamando o editor VS Code assim: start code menu.txt
Depois de salvarmos o arquivo, preparamos e confirmamos as alterações:
Analisando o conteúdo dos commits podemos ver que o segundo commit possui o campo parent com o SHA-1 do primeiro commit vinculando os dois.
Se você observar o hash da árvore que este segundo commit está apontando, verá que essa é uma árvore totalmente nova. Não é a mesma árvore que o primeiro commit estava apontando. É como uma raiz diferente. Também podemos usar apenas os primeiros dígitos do SHA 1 e o Git recuperará automaticamente todo o SHA 1 do banco de dados, a menos que haja vários SHA 1s iniciando com esses primeiros dígitos.
Agora, menu.txt é um blob totalmente novo, porque esse arquivo foi alterado, incluindo o Apple Pie e o Cheesecake. No entanto, o conteúdo do diretório de receitas é o mesmo objeto que já tínhamos no banco de dados desde o primeiro commit. Como o conteúdo deste diretório não foi alterado, não há razão para criar um novo objeto. O Git pode apenas usar o objeto que já estava no banco de dados.
Essa é uma das razões pelas quais o Git é tão eficiente; não armazena as coisas mais de uma vez. Como alteramos um único arquivo, o Git armazenou um novo blob e, no nosso caso, uma nova árvore e uma nova confirmação. Como eles estão apontando para o novo arquivo, eles são alterados. As árvores e os commits são realmente pequenos, então isso ainda é extremamente eficiente.
Falando em eficiência, você pode se surpreender ao ver que o Git armazena um novo blob toda vez que você altera um arquivo. E se eu tiver um arquivo enorme e alterar apenas uma única linha? O Git armazenará um novo blob inteiro nesse caso e duplicará o restante do arquivo? Bem, na verdade não. O Git também faz outra camada de otimizações para economizar mais espaço. Por exemplo, à medida que você continua trabalhando e adicionando conteúdo ao repositório, o Git pode decidir armazenar apenas as diferenças entre os dois arquivos ou até compactar vários objetos no mesmo arquivo físico. A propósito, esse tipo de coisa é a razão desses misteriosos diretórios info e pack no banco de dados.
No entanto, esses são realmente detalhes de implementação. Você pode ignorá-los com segurança. Para entender o modelo Git, basta pensar em cada commit, blob ou árvore como apenas arquivos, arquivos separados, que são divididos em hash e armazenados no banco de dados. No nível dos comandos, é assim que o Git realmente funciona.
Se você contar o número de objetos no diagrama acima, serão duas confirmações, mais 3 árvores e 3 blobs. total de oito objetos. Este é o número atual de objetos no banco de dados de objetos.
O próprio banco de dados está ficando um pouco cheio, então, em vez de contar os arquivos, vamos usar um desses comandos de encanamento raramente usados, o git count-objects. E aí estão oito objetos, e eles ocupam uma quantidade muito pequena de espaço em disco.
Observe o modelo inteiro de um ponto de vista abstrato. Temos os blobs, que contêm dados e existem outras coisas chamadas árvores que contêm blobs e outras árvores, criando uma estrutura recursiva. Os nomes dos blobs e árvores não estão armazenados nos objetos si mesmos mas na árvore que o contém. Portanto, você pode ter o mesmo objeto, digamos, o mesmo blob ou a mesma árvore apontada por diferentes árvores com nomes diferentes. Lembrando muito um sistema de arquivos.
Assim como em um sistema de arquivos, você tem conteúdo, arquivos ou blobs, e contêineres, diretórios ou árvores aninhadas nesse caso, e você pode ter links. O mesmo arquivo ou diretório pode ser acessado de diferentes locais com nomes diferentes. Afinal, como o Git foi escrito por Linus Torvalds', que escreveu o Linux, você pode argumentar que é isso que o Git é um sistema de arquivos de alto nível, construído sobre o sistema de arquivos nativo, como links no Linux ou atalhos no Windows.
GIT RESET
Entendendo a reset
Os 4 comandos Git que movem implicitamente uma ramificação, como um efeito colateral da criação de novas confirmações ou da retirada remota são:
- Commit: cria uma nova confirmação e move a ramificação atual para apontar para a nova confirmação.
- Merge: cria um commit na maioria dos casos, e também move o branch atual para parte do novo commit.
- Rebase: cria novas confirmações copiando confirmações existentes nesse caso e move a ramificação atual para apontar para uma das novas confirmações.
- Pull: obtém novas confirmações de um controle remoto e atualiza as ramificações local e remota.
No entanto, apenas comando reset é uma operação especializada para mover uma ramificação. A coisa mais importante que um reset faz é apenas isso: move uma ramificação. Geralmente o ramo atual, o ramo para o qual a cabeça está apontada. Você escolhe um commit, e o reset move o ramo atual para esse commit, para que a commit agora seja a commit atual. Observe que a reset não move o HEAD. A cabeça ainda está apontando para o mesmo ramo em que estava apontando antes, mas o próprio ramo está se movendo, de modo que a cabeça está seguindo o caminho. Se você olhar apenas para o repositório, é tudo o que a reset faz; move uma ramificação para apontar para o commit específico.
A parte que você pode achar confusa, no entanto, não é o que um reset faz no repositório é o que um reset faz nas outras duas áreas principais: a área de trabalho e o índice. Então, é isso que a reset faz:
- Move a ramificação atual, alterando também a confirmação atual.
- Opcionalmente, copia os arquivos e diretórios do novo commit atual para a área de trabalho e o índice.
O reset faz coisas diferentes, dependendo de suas opções.
- A opção --hard, copiará os dados do novo commit atual para a área de trabalho e o índice.
- A opção --mixed, copia dados do novo commit atual para o índice, mas deixa a área de trabalho em paz. Esta é a opção padrão, se você não der nenhuma opção para redefinir, será uma redefinição mista.
- A opção --soft significa não tocar em nenhuma das áreas, basta mover o ramo e pular completamente a etapa dois.
A opção –hard
Por exemplo, suponhamos que estamos no ramo mestre no status limpo, portanto as três áreas contêm os mesmos dados. Temos um arquivo menu.txt e o diretório de receitas mas queremos adicionar um novo prato ao menu.
Veja o que acontece no repositório depois de prepará-lo e confirmar. Git cria um novo commit. Ele move a ramificação principal para este novo commit, que contém a nova versão do arquivo de menu e a mesma versão do diretório de receitas. Depois disso queremos adicionar na pasta de receitas os ingredientes e os outros detalhes sobre a receita.
E, novamente, o Git cria uma nova confirmação, atualiza a ramificação principal e a nova confirmação faz referência à versão mais recente do menu.txt e do diretório de receitas. Agora imagine que mudei de idéia e queremos descartar essas alterações. Gostaria que os dois últimos commits nunca tivessem acontecido.
É aí que um reset se torna útil. Posso anotar o hash desse commit e pedir ao Git para redefinir o ramo atual. Isso moveria o ramo de volta no tempo. Após o reset, queremos estar alinhado e ter as versões anteriores dos arquivos, não apenas no repositório, mas também no índice e na área de trabalho. Escolhemos então a opção –hard, um reset definitivo, que copia os arquivos do repositório para as outras duas áreas.
- O Git move o ramo atual para o commit anterior, que agora se torna o novo commit atual. E a cabeça segue adiante.
- Como essa é uma redefinição definitiva, o Git copia o conteúdo da nova confirmação atual, as versões amarelas dos arquivos, para o diretório ativo e o índice.
- Como os dois commits relacionados ao squid estão inacessíveis agora, eles não têm nenhum ramo apontando para eles. Eles serão coletados como lixo.
O Git é um banco de dados de grafos, isso significa que, quando demos o reset só mudamos a etiqueta, ou referência do branch master dois commits pra trás. Os commits em si não foram apagados, eles foram só marcados pra serem apagados. Sempre evite apagar dados, melhor sempre marcar como apagado, pois quase tudo pode ser recuperado com o reflog e criação de um branch temporário, como veremos a sguir. De temos em tempos o Git roda um garbage collector, que você pode executar manualmente com o comando git gc, que seria o equivalente a esvaziar a lixeira no Windows. O procedimento completo é primeiro rodar um git reflog pra expirar tudo que você não vai precisar e depois rodar o git gc.
Recuperando da lixeira
Mas digamos que tinha um arquivo que eu não podia perder. Para voltar os commits, utilizamos novamente o SHA-1 do commit que queremos ir e podemos fazer o equivalente a um undelete. Mesmo se eu não tivesse o o SHA-1 ainda ia dar, só ia dar um pouquinho mais de trabalho pra achar o commit certo. Para tirar nossos commits da lixeira, rode o comando: git checkout -b (pra criar um novo branch) teste e o SHA-1.
Se eu quiser recuperar de volta pro master, basta dar git checkout master pra voltar pro master. Se dermos git log veja que o master continua apontando 2 commits pra trás, mas acabamos de anexar a etiqueta de teste pro commit antigo.
Como estamos trabalhando só localmente sem dar push ou pull de servidor, podemos fazer um git rebase teste. E se dermos git log de novo veja que o branch master está apontando pro mesmo commit que o branch teste, pronto, tá tudo recuperado. E podemos apagar o branch temporário com git branch -d teste para deixar tudo limpo tudo limpo.
Retirando um arquivo do Stage
O comando git status que você usa para verificar o estado dessas duas áreas, também te relembra como desfazer as modificações aplicadas na área stage e working diretory. Por exemplo, vamos supor que você alterou dois arquivos, e deseja realizar o commit deles separadamente, porém você acidentalmente digitou git add * adicionando ambos ao stage.
A ideia aqui é que queremos manter as alterações na minha área de trabalho, mas remover as alterações do índice, recuperando a mesma versão dos arquivos que estão no repositório. Anteriormente, vimos uma maneira de fazer isso, usando o comando: git rm --cached menu.txt
O comando git status lhe lembrará de como você pode retirar um deles do stage de forma mais segura:
Logo abaixo do texto “Changes to be committed”, o Git indica o caminho mais seguro para retirar o arquivo do stage. Então, para restaurar um arquivo README.md no índice para corresponder à versão em HEAD: git restore --staged README.md
O mesmo resultado pode ser obtido com o comando: git reset HEAD README.md
Ao dar um reset significa que estamos movendo a ramificação atual para a commit apontada pelo HEAD, mas a ramificação atual já está apontando para a commit, nesse caso, significa que ele não se move. É como pular completamente o primeiro passo reset. No segundo passo do reset, o Git move os dados do repositório para a área de trabalho, ou para o índice. Nesse caso, como não especificamos o tipo de reset que queremos, o Git seguirá o padrão, que é um reset misto. Lembre-se do que um reset --mixed faz, move dados da commit atual para o índice, mas não para a área de trabalho.
O arquivo README.md volta ao estado modificado, porém está novamente fora do stage. É verdade que o comando git reset pode ser perigoso, especialmente se você usar a opção --hard. O objetivo do git-reset é "Redefinir o HEAD atual para o estado especificado", enquanto o git-restore "Restaurar arquivos da árvore de trabalho". Isso significa que muitas invocações de git-reset, se não forem cuidadosas, podem afetar outros arquivos à medida que são direcionados ao HEAD, em vez de arquivos individuais, como o git-restore.
Reset e Mensagens de Confirmação
Muitas vezes, ao trabalhar com o Git, você pode revisar seu histórico de commits por algum motivo. Uma das grandes coisas do Git é que ele permite que você tome decisões no último momento possível. Você pode decidir em quais arquivos serão confirmados imediatamente antes de fazer o commi com a área de preparação, você pode decidir que ainda não estava planejando trabalhar em algo com o comando stash.
Pode reescrever commits que já aconteceram, para que pareçam ter acontecido de maneira diferente. Isso pode envolver alterar a ordem das commits, alterar mensagens ou modificar arquivos em uma confirmação, agrupar ou separar commits ou remover commits por completo - tudo antes de você compartilhar seu trabalho com outras pessoas.
Comando Descrição
git commit --amend Abre o editor de texto padrão para alterar o último commit
git commit –m --amend “Mensagem Certa” Pega a área stage e a usa para realizar o commit. Se você não fez nenhuma alteração desde o último commit, então sua imagem dos arquivos irá ser exatamente a mesma, e tudo o que você alterará será a mensagem do commit e gerará um novo SHA-1.
git reset FILE Redefina sua área de preparação, removendo as alterações feitas com o git add
git reset --soft HEAD3 Navega por uma lista de commits e faz o HEAD apontar para três commits para trás. Se você deseja reagrupar essas alterações em confirmações diferentes ou adicionar mais alterações antes de confirmar.
git reset
git reset --mixed Definição padrão move de volta para o diretório de trabalho.
git reset --hard Move as alterações para a lixeira.
git reset –hard HEAD@{4} Redefina HEAD para apontar para o SHA1 ID representado por HEAD@{4}.
git rebase -i HEAD3 Abre janela interativa para alterar os 3 últimos commits
Um dos motivos mais comuns para desfazer um comando, aparece quando você executa um commit muito cedo e possivelmente esquecendo de adicionar alguns arquivos ou você escreveu a mensagem do commit de forma equivocada.
Se você quiser refazer este commit, execute o commit novamente usando a opção --amend: git commit --amend OU git commit –m --amend “Mensagem Certa”
Esse comando pega a área stage e a usa para realizar o commit. Se você não fez nenhuma alteração desde o último commit (por exemplo, se você executar o comando imediatamente depois do commit anterior), então sua imagem dos arquivos irá ser exatamente a mesma, e tudo o que você alterará será a mensagem do commit.
O mesmo editor de mensagens de commit é acionado, porém o commit anterior já possui uma mensagem. Você pode editar a mensagem como sempre, porém esta sobrescreve a mensagem do commit anterior. Por exemplo, se você fizer um commit e então lembrar que esqueceu de colocar no stage as modificações de um arquivo que você quer adicionar no commit, você pode fazer algo semelhante a isto:
No final das contas você termina com um único commit – O segundo commit substitui o resultante do primeiro.
Alterando várias mensagens de confirmação
Para modificar uma consolidação mais antiga do seu histórico, você deve passar para ferramentas mais complexas. O Git não possui uma ferramenta de histórico de modificações, mas você pode usar duas ferramentas para alterar uma série de commits:
- Ferramenta Reset
- Ferramenta Rebase
Alterar com Reset
Se tivéssemos a situação de termos vários commits de correções locais. Neste momento, poderíamos enviar essas alterações para o mestre de origem no Github e incluiria esses 4 commits em sua origem.
Mas e se não quisermos descartar algum desses commits ou todos eles ou alterar o histórico delas. Para isso há um comando chamada git reset que permite mover as alterações de volta à nossa área de trabalho ou de preparação. Também pode ser usado para jogar fora as alterações. Como é um comando destrutivo, é recomendável uma consideração cuidadosa ao usar. É uma prática recomendada não redefinir alterações que já tenham sido enviadas para uma origem remota, na qual outros colaboradores podem ter acessado as alterações.
Existem três opções diferentes ao usar git reset que decidem o que acontece com as confirmações que você deseja alterar: git reset --soft, git reset --mixed e git reset --hard. Se quisermos navegar por essa lista de commits podemos fazer o HEAD apontar para três commits para trás com o comando: git reset --soft HEAD~3
Essa sintaxe de HEAD e tilzinho pode ser mais complicado se você tiver merges no meio do caminho. Por exemplo, se você quiser reverter um commit de merge que aponta pra outros 10 commits, ele é virar um galho paralelo no histórico. Mas basta usar HEAD~1 que ele vai matar só o commit do merge que é quem liga os outros commits e você some com os 10. Isso não é tão intuitivo então é melhor você praticar. No caso de querer sincronizar o HEAD com algum branch pode ser feito como na situação abaixo:
Podemos ver para aonde estão os ponteiros do HEAD local, do origin/master e do new_branch. Nosso commit mais recente é o commit de quando mesclamos o new_branch ao ramo mestre. As digitarmos para voltarmos ao origin/master para o diretório de trabalho: git reset --mixed e17afca
Vemos que nossas alterações do mestre e do ramo new_branch, agora estão sendo exibidas em nosso diretório de trabalho. Ao adicionar essas alterações na área de preparação, vemos que todas as alterações serão feitas originalmente em nossa ramificação principal, e não mais separadas com alterações do ramo new_branch.
Ao executarmos o commit, acabamos de alterar nosso histórico de consolidação para agrupar essas confirmações em uma única confirmação. Por fim executamos o git push origin master para atualizar o repositório remoto.
Alterar com Rebase
É possível utilizar o rebase em uma série de confirmações no HEAD em que elas se baseavam originalmente, em vez de movê-las para outra. Com a ferramenta de rebase interativa, você pode parar após cada confirmação que deseja modificar e alterar a mensagem, adicionar arquivos ou fazer o que quiser. Você pode executar o rebase interativamente adicionando a opção -i ao git rebase. Você deve indicar a quanto tempo você deseja reescrever confirmações, informando o comando em que se comprometer a reestruturar. Por exemplo, se você deseja alterar as três últimas mensagens de confirmação ou qualquer uma das mensagens de confirmação.
Se você errar após completar as operações abaixo e deseja refazer as operações é só dar o comando reset até o commit que pretende voltar, assim: git reset --soft bd71910d04101c0
Por exemplo, se você deseja alterar as três últimas mensagens de confirmação ou qualquer uma das mensagens de confirmação desse grupo.
Você fornece como argumento para git rebase -i o pai do último commit que deseja editar, que é HEAD2^ ou HEAD3. Pode ser mais fácil lembrar dos 3 porque você está tentando editar os três últimos commits; mas lembre-se de que você está designando quatro confirmações atrás, o pai da última confirmação que deseja editar:
git rebase -i HEAD3
Lembre-se novamente de que este é um comando de rebasing - todos os commit incluídos no intervalo HEAD~3 até o HEAD serão reescritos(gera noco SHA-1), independentemente de você alterar ou não a mensagem. Não inclua nenhuma confirmação que você já enviou para um servidor central. Isso confundirá outros desenvolvedores ao fornecer uma versão alternativa da mesma alteração. A execução deste comando fornece uma lista de confirmações no seu editor de texto com a seguinte aparência:
Embaixo ele te ajuda dizendo quais opções você tem. É interessante testar todas as opções num repositório local. Comando Objeto Descrição p, pick use confirmação r, reword use confirmação, mas edite a mensagem de confirmação e, edit use confirmação, mas pare para alterar s, squash use a confirmação, mas mescla na confirmação anterior f, fixup como "squash", mas descarta a mensagem de log desta confirmação x, exec comando de execução (o resto da linha) usando shell b, break Pare aqui e continue a rebase mais tarde com 'git rebase --continue' d, drop remover confirmação l, label label HEAD atual com um nome t, reset redefinir HEAD para um rótulo m, merge [-C | -c ] [# ] crie uma confirmação de mesclagem usando a mensagem confirmação de mesclagem original (ou on-line, se nenhuma confirmação de mesclagem original foi especificada). Use -c para reformular a mensagem de confirmação.
É importante observar que esses commits estão listados na ordem oposta à que você normalmente os vê usando o comando log. Se você executar um log, verá algo assim:
Observe a ordem inversa. O rebase interativo fornece um script que será executado. Ele começará na confirmação especificada na linha de comando (HEAD~3) e repetirá as alterações introduzidas em cada uma dessas confirmações de cima para baixo. Ele lista o mais antigo no topo, e não o mais novo, porque esse é o primeiro que será reproduzido.
Você precisa editar o script para que ele pare no commit que deseja editar. Para fazer isso, altere a palavra pick para a palavra 'edit' para cada confirmação que você deseja que o script pare depois. Por exemplo, para modificar apenas a primeira e terceira mensagem de confirmação, altere o arquivo para ficar assim:
Quando você salva e sai do editor, o Git retrocede você até o último commit nessa lista e o coloca na linha de comando com a seguinte mensagem:
Estas instruções indicam exatamente o que fazer. Digite: git commit --amend
Altere a mensagem de confirmação e saia do editor. Como escolhemos para editar em mais linhas, devemos repetir essas etapas para cada confirmação alterada para editar. Sempre que o Git for interrompido, você poderá alterar o commit e continuar quando terminar.
Então digite, até completar a operação, o último: git rebase --continue
Reordenar Commits
Você também pode usar rebases interativos para reordenar ou remover completamente as confirmações. Se você deseja remover o commit "arquivo-gato adicionado" e alterar a ordem em que os outros dois commits são introduzidos, você pode alterar o script rebase apartir desse estado:
Para assim:
Quando você salva e sai do editor, o Git rebobina sua ramificação para o pai desses commits, aplica 0a47593 e, em seguida, eca1018 alterando a ordem desses commit e remove completamente o commit 407736a, " Add file 2".
Squashing Commits
Também é possível obter uma série de confirmações e compactá-las em uma única confirmação. Portanto, se você quiser fazer um único commit a partir desses três commits, faça com que o script fique assim:
Squash é amassar tudo junto. Não precisa ser todos, eu posso inclusive pular um no meio se não fizer sentido mesclar tudo junto. Repare na barra de status do Visual Code ele indica eu está fazendo rebase:
Ao fechar o editor a primeira vez, ele já abre automaticamente para edição da mensagem:
Ao editar, o Visual Code, gera um código indicando a alteração na barra de status:
Ao retornar a janela de comando já está feita as alterações:
Este comando aplicará os outros dois commit automaticamente, e então você estará pronto.
Divisão de um commit
Por exemplo, suponha que você queira dividir o commit intermediário dos seus três commits. Em vez de “Operacao 1 e Operacao 2”, você deseja dividi-la em dois commits: “Operacao 1” para a primeira e “Operacao 2” para a segunda.
Você pode fazer isso no script rebase -i alterando a instrução no commit que deseja dividir para “edit":
Em seguida, quando o script o coloca na linha de comando, você redefine essa confirmação, realiza as alterações que foram redefinidas e cria várias confirmações a partir delas. Quando você salva e sai do editor, o Git retrocede ao pai do primeiro commit na sua lista, aplica o primeiro commit (f7f3f6d), aplica o segundo (310154e) e o leva ao console. Lá, você pode fazer uma redefinição mista dessa confirmação com o git reset HEAD^^, que efetivamente desfaz a confirmação e deixa os arquivos modificados em estágios. Então, primeiro precisamos preparar e confirmar a inclusão do file2.txt confirmando com a mensagem “Operacao 1”;
Após isso, podemos incluir arquivos ou alterar este mesmo para incluiormos um segundo commit com a mensagem “Operacao 2”:
Agora você pode preparar e confirmar arquivos até ter várias confirmações e executar o git rebase - continue quando tiver terminado: git log -4 --pretty=format:"%h %s"
Mais uma vez, isso altera os SHA-1s de todas as confirmações na sua lista, portanto, verifique se nenhuma confirmação aparece nessa lista que você já enviou por push para um repositório compartilhado
7 Regras de mensagens
Existem algumas regras e diretrizes gerais ao escrever uma mensagem de confirmação descritas em detalhes em um ótimo post de Chris Beams (2014): https://chris.beams.io/posts/git-commit/
Obviamente, essas orientações são apenas diretrizes e podem mudar dependendo de como o projeto está estruturado para ser mantido. Mas, no entanto, essas diretrizes são seguidas que facilitam no momento de reverter uma confirmação que introduziu um bug e precisarmos encontrar essa confirmação específica ou se apenas revisarmos alterações específicas introduzidas em uma confirmação. Se a mensagem de confirmação não for suficientemente detalhada, não sabemos quais arquivos foram alterados ou o que foi alterado nesses arquivos.
Se você procurar o log de qualquer repositório aleatório do Git, provavelmente encontrará suas mensagens de confirmação mais ou menos uma bagunça. Por exemplo,
Compare isso com esses commits mais recentes do mesmo repositório:
Mas um registro log bem cuidado é uma coisa bonita e útil. git blame, revert, rebase, log, shortlog e outros subcomandos ganham vida. Comando Descrição git blame FILE Exibe a saída de culpa de um FILE git rebase master Rebase sua ramificação atual com o commit mais recente do master
Analisar solicitações de confirmação (commits) e recebimento (pull requests) de outras pessoas se torna algo que vale a pena ser feito e, de repente, pode ser feito de forma independente. Compreender por que algo aconteceu meses ou anos atrás se torna não apenas possível, mas eficiente. A abordagem de uma equipe ao log de confirmação não deve ser diferente. Para criar um histórico de revisão útil, as equipes devem primeiro concordar com uma convenção de mensagem de confirmação que defina pelo menos as três coisas a seguir:
- Estilo. Sintaxe de marcação, margens de quebra automática, gramática, capitalização, pontuação. Soletre essas coisas, remova as suposições e torne tudo o mais simples possível. O resultado final será um registro notavelmente consistente, que não é apenas um prazer de ler, mas que na verdade é lido regularmente.
- Conteúdo. Que tipo de informação o corpo da mensagem de confirmação (se houver) deve conter? O que não deve conter?
- Metadados. Como devem ser referenciados os IDs de rastreamento, os números de solicitação pull, etc.
Felizmente, existem convenções bem estabelecidas sobre o que faz um Git idiomático enviar uma mensagem. De fato, muitos deles são assumidos na maneira como certos comandos do Git funcionam. Não há nada que você precise reinventar. Basta seguir as sete regras abaixo e você estará no caminho de se comprometer como um profissional.
-
Separe o assunto do corpo com uma linha em branco
-
Limite a linha de assunto para 50 caracteres
-
Coloque em maiúscula a linha de assunto
-
Não termine o assunto com um período
-
Use o infinitivo na linha de assunto
-
Envolva o corpo com 72 caracteres
-
Use o corpo para explicar o que e por que versus como
-
Separe o assunto do corpo com uma linha em branco
Em primeiro lugar, nem todo comprometimento requer um sujeito e um corpo. Às vezes, uma única linha é boa, especialmente quando a mudança é tão simples que nenhum contexto adicional é necessário. Se você está enviando algo assim na linha de comando, é fácil usar a opção -m para git commit: git commit -m "Corrigir erro de digitação na introdução ao guia do usuário"
No entanto, quando um commit merece um pouco de explicação e contexto, você precisa escrever um corpo o que não é tão fácil de escrever com a opção -m. É possível escrever a mensagem em um editor de texto adequado digitando somente git commit sem parâmetros.
Ou você pode fazer isso facilmente na linha de comando. O truque é digitar assim: git commit -m "Title" -m "Description .........."
O GitHub exibirá corretamente a linha superior como sua mensagem básica e a linha inferior como a mensagem estendida. Aqui está a entrada completa do log:
E agora git log --oneline, que imprime apenas a linha de assunto:
Ou, git shortlog, que os grupos confirmam pelo usuário, mostrando novamente apenas o assunto da concisão:
Existem vários outros contextos no Git em que a distinção entre linha de assunto e corpo entra em ação - mas nenhum deles funciona corretamente sem a linha em branco no meio.
- Limite a linha de assunto para 50 caracteres
50 caracteres não é um limite rígido, apenas uma regra de ouro. Manter as linhas de assunto nesse comprimento garante que elas sejam legíveis e força o autor a pensar por um momento sobre a maneira mais concisa de explicar o que está acontecendo. A interface do usuário do GitHub está ciente dessas convenções. Ele avisará se você ultrapassar o limite de 50 caracteres:
E truncará qualquer linha de assunto com mais de 72 caracteres com reticências. Portanto, utilize 50 caracteres, mas considere 72 o limite máximo.
- Coloque em maiúscula a linha de assunto
Isto é tão simples quanto parece. Comece todas as linhas de assunto com uma letra maiúscula.
- Certo: Acelerar para 88 milhas por hora
- Errado: acelerar para 88 milhas por hora
- Não termine o assunto com um período
A pontuação à direita é desnecessária nas linhas de assunto. Além disso, o espaço é precioso quando você tenta mantê-los com 50 caracteres ou menos.
- Certo: Abrir as portas do compartimento
- Errado: Abrir as portas do compartimento.
- Use o infinitivo na linha de assunto
O infinitivo pode parecer estranho, meio robótico, e talvez por isso que não costumamos usá-lo. Mas é perfeito para o Git confirmar linhas de assunto. Uma razão para isso é que o próprio Git usa o imperativo sempre que cria um commit em seu nome. Por exemplo, a mensagem padrão criada ao usar a mesclagem git diz: Merge branch 'myfeature'
E ao usar o git revert: Revert "Add the thing with the stuff"
Ou ao clicar no botão "Mesclar" em uma solicitação de recebimento do GitHub: Merge pull request #123 from someuser/somebranch
Uma linha de assunto de confirmação do Git formada corretamente deve sempre ser capaz de concluir a seguinte frase: Se aplicado, esse commit irá “descrever linha de assunto”
Por exemplo:
- Se aplicado, esse commit irá refatorar o subsistema X para facilitar a leitura
- Se aplicado, esse commit irá atualizar a documentação de introdução
- Se aplicado, esse commit irá remover métodos obsoletos
- Se aplicado, este commit irá lançar a versão 1.0.0
Como estamos mais acostumados a falar no indicativo ou por outras formas não infinitivas, que trata de relatar fatos ou descrever conteúdos e objetos, com esse padrão não funciona:
-
Se aplicado, esse commit irá Corrigido o erro com Y
-
Se aplicado, esse commit irá Mudando o comportamento de X
-
Se aplicado, esse commit irá Mais correções para coisas quebradas
-
Se aplicado, esse commit irá Novos métodos API agradáveis
Lembre-se: O uso do infinitivo é importante apenas na linha de assunto. Você pode relaxar essa restrição ao escrever o corpo.
- Envolva o corpo com 72 caracteres
O Git nunca quebra o texto automaticamente. Ao escrever o corpo de uma mensagem de confirmação, você deve observar a margem direita e quebrar o texto manualmente. A recomendação é fazer isso com 72 caracteres, para que o Git tenha espaço de sobra para recuar o texto, mantendo tudo com menos de 80 caracteres no geral.
Um bom editor de texto pode ajudar aqui. É fácil configurar o Vim, por exemplo, para agrupar texto com 72 caracteres quando você estiver escrevendo uma confirmação do Git. Tradicionalmente, no entanto, os IDEs têm sido péssimos em fornecer suporte inteligente para quebra de texto em mensagens de confirmação (embora em versões recentes, o IntelliJ IDEA finalmente tenha melhorado sobre isso).
- Use o corpo para explicar o que e por que versus como
Na maioria dos casos, você pode deixar de fora detalhes sobre como uma alteração foi feita. O código geralmente é auto-explicativo a esse respeito (e se o código é tão complexo que precisa ser explicado em prosa, é para isso que servem os comentários de origem). Apenas se concentre em esclarecer as razões pelas quais você fez a alteração em primeiro lugar - a maneira como as coisas funcionavam antes da mudança (e o que havia de errado nisso), a maneira como elas funcionam agora e por que você decidiu resolvê-la da maneira que fazia . Este commit do Bitcoin Core é um ótimo exemplo de explicação do que mudou e por quê:
Dê uma olhada no diff completo e pense em quanto tempo o autor está economizando tempo de futuros colaboradores do projeto, dedicando um tempo para fornecer esse contexto do que mudou e por quê.
TAGS
No banco de dados de objetos Git temos quatro tipos de objetos:
- Blobs (conteúdo arbitrário)
- Trees (equivale a diretórios)
- Commits
- Tags
Uma tag é como um rótulo para o estado atual do projeto, existem dois tipos de tags no Git:
- Tags anotadas: são as que acompanham uma mensagem. Essa tag contém muitas informações úteis, como a data em que a tag foi criada, quem a criou, uma descrição e assim por diante.
- Tags leve não-anotada: um rótulo simples para uso próprio.
Comando Descrição git rev-parse traduza um nome ou tag de branch para um SHA1 específico git tag tag_name -m "message" SHA1id crie uma tag chamada tag_name, apontando para seu SHA1id git tag listar todas as tags git show tag_name mostra informações sobre a tag denominada tag_name git tag -a tag_name -m tag_message SHA1 crie uma tag no SHA1 com o nome tag_name e a mensagem tag_message git tag -d tagname remova a tag denominada tagname do repositório local git tag tagname master adiciona a tag denominada tagname no master git push --tags envia todas as tags para o controle remoto padrão
Tags anotadas
Para criar uma tag anotada, você pode usar o comando git tag com o argumento –a, e precisa de um nome para a tag e também de algum tipo de mensagem aqui.
É semelhante à criação de uma confirmação e, de fato, uma tag anotada também é um objeto no banco de dados de objetos do Git, como a confirmação. 7cfdf850f4d99b964a9a22c1d79cc98fb6a14592
Vamos usar o cat-file para espiar dentro dele. No caso de tags, o arquivo cat pode usar o hash ou o nome da tag.
E aqui está a etiqueta. Ele contém metadados, como a mensagem da tag, o nome, o marcador, a data e, o mais importante, um objeto para o qual a tag está apontando. Nesse caso, é um commit.
Tags leve não-anotada
Esse tipo de tag não tem um nome específico mas as pessoas às vezes as chamam de tags não anotadas ou leves. Para criar um, digamos que queremos marcar o commit mais recente com um tag simples para meu próprio uso chamado dinner. Digitamos então o comando tag ignorando a opção –a: git tag dinner
Navegando agora para o diretório .git/refs, existem duas tags, que são dois arquivos simples que contêm o SHA‑1 de um objeto no banco de dados.
Veja, uma tag é uma referência a um objeto, neste caso, uma confirmação, como uma ramificação.
Na verdade, eu poderia transformar essa tag em um ramo apenas movendo-a para o diretório refs/head. Como é uma marca leve, ela contém o SHA‑1 de uma confirmação. Uma tag anotada é semelhante, mas contém o SHA-1 de um objeto de tag no banco de dados, e esse objeto, por sua vez, faz referência a uma confirmação, além de conter todas as informações extras, como a descrição da tag. A única diferença entre ramificação e tag é que ramos se movem, as tags não. Se eu criar um novo commit no momento, o master se moverá para rastreá-lo porque é o ramo atual, mas a tag permanecerá no mesmo objeto para sempre. Abaixo um exemplo de envio de tags ao repositório remoto.
Para excluir e enviar somente uma tag ao repositório remoto deve digitar os comandos:
GIT STATUS
Você pode verificar o status do seu projeto a qualquer momento usando o comando git status. Se digitarmos o status Git em nossa linha de comando, Git responderá com algumas linhas de informação.
A primeira linha indica o ramo em que estamos, que é o ramo mestre. Quando inicializamos os repositórios Git, criamos uma ramificação principal automaticamente chamada de Ramificação Mestre. Uma ramificação (branch) no Git é um ponteiro para o seu projeto em um ponto específico no tempo. Agora, como nossos dois repositórios estão sincronizados, nossa ramificação principal local é igual à ramificação Master de Origem. A segunda linha na resposta menciona que nossa ramificação está atualizada com o mestre de origem e a terceira e última linha está dizendo que não há nada a se atualizar e que não modificamos nenhum arquivo, portanto ainda não há alterações em nosso diretório de trabalho e nada ainda foi preparado que ainda está aguardando confirmação.
git status –-short OU git status -s
Para obter um status curto que fornece a mesma quantidade de informações, mas de uma maneira muito menor e concisa, digite os comandos: git status –-short OU git status -s
Depois de executar este comando Git, o nome dos arquivos será colocado na coluna da extrema direita. A primeira coluna (em verde) indica que o arquivo foi preparado e a coluna do meio (em vermelho) indica que o arquivo foi modificado, mas permanece no diretório de trabalho. A letra M significa modificado e a letra A significa novos arquivos que foram adicionados à área de teste e pontos de interrogação (??) significam que há um novo arquivo que não é rastreado pelo Git. Colunas Arquivo Situação M cold_brew Arquivo rastreado, modificado e preparado M M employees.txt Arquivo rastreado, modificado e preparado, novamente modificado e não preparado A M novoaltera.txt Arquivo novo rastreado, modificado e não preparado M vanilla_latte Arquivo rastreado, modificado e não preparado A vendors.txt Arquivo novo rastreado, não modificado e preparado ? ? novoarquivo.txt Arquivo novo não rastreado, não modificado e não preparado
GIT DIFF
Se o comando Git status for muito vago e você quiser ver as alterações reais sendo feitas nesses arquivos e não apenas saber quais arquivos foram alterados, você pode usar o comando git diff que pode ser usado para responder a duas perguntas. Comando Descrição git diff Mostrar qualquer diferença entre os arquivos rastreados no diretório atual/local e na área de preparação (índice sincronizado) git diff –staged Mostre qualquer diferença entre os arquivos na área de preparação (índice sincronizado) e o último commit(repositório); git diff –cached git diff HEAD Exibe todas as diferenças entre sua cópia local e o último commit realizado; git diff SHA1 SHA1 Exibe todas as diferenças entre commits;
-
Que mudanças eu realizei que estão preparadas para serem confirmadas? Na maioria das vezes, quero comparar as coisas que quero confirmar com as que já confirmei. Ou seja, eu quero comparar o índice com o repositório. Para isso, você pode usar o git diff com a opção –cached ou: git diff --staged OU git diff --staged --no-renames
-
Que mudanças eu realizei, mas não estão preparadas? git diff
Se você olhar o conteúdo da pasta .git, verá o índice. É um arquivo binário, então não podemos simplesmente abri-lo em um editor de texto. Que tipo de dados está nesse arquivo binário? Pense nisso como apenas outra área que contém tudo, assim como a área de trabalho e o repositório. Todos os seus arquivos e pastas. Portanto, quando dizemos git status e vemos que tudo está sincronizado, isso não significa que o índice esteja vazio, significa que o índice contém os mesmos arquivos e pastas que o repositório, que as três áreas estão todas alinhadas. Isso pode ser melhor observado aplicando o comando git diff
GIT PUSH
Publicando no repositório remoto
Podemos enviar nossas alterações para nosso projeto de origem usando o comando Git push, nosso nome remoto, que é origin e, em seguida, para onde iremos enviar, que é master. Vemos algumas informações de compactação, caminho URL do github, hashe, etc... que mostra que nosso envio foi foi enviado aos repositórios de origem sem erros. git push origin master
A seguir estão alguns exemplos de comandos utilizados: Comando Descrição git remote add origin https:/// Adicione um nome remoto origin que aponte para seu repositório remoto no Github git remote Exibe o nome do diretório remoto git remote -v show Exibe os nomes dos controles remotos junto com a URL correspondente git remote add bob Adicione um nome remoto bob que aponte para o repositório local ../math.bob git ls-remote bob Exibe as referências de um repositório remoto GIT_TRACE_PACKET git ls-remote REMOTE Exibir a interação de rede subjacente git push Empurre a ramificação atual para a ramificação de rastreamento remoto padrão configurada pelo git checkout ou git push –set-upstream git push origin master Empurre o ramo mestre para a origem do nome remoto git push -u origin master Empurre seu ramo mestre local para o remoto chamado origin. O parâmetro –u é colocado para que a cada ramificação atualizada ou enviada com êxito, adicione uma referência upstream (rastreamento). Com essa referência gravada ela pode usada posteriormente pelo git-pull sem argumentos e outros comandos. Se você empurrar múltiplos branches, todos que tiveram sucesso vão ter o upstream tracking atualizado. git push origin tagname empurre a tag denominada tagname para a origem nomeada remota git push origin :tagname exclua a tag denominada tagname na origem nomeada remota
Em seguida, precisamos conectar nossos repositórios locais ao que repositório remoto no Github, vinculando os dois. Isso pode ser feito com o comando: git remote add origin https://github.com/shyoutarou/wired-brain-recipes.git
Para verificar se foi criado a origin digite:
git remote
Mas repare que é exibido apenas o name dos repositórios remotos. Para que também seja exibida a url devemos adicionar o parâmetro -v ao comando: git remote -v
Observe que o repositório remoto foi listado duas vezes. Isso acontece pois o Git permite que tenhamos duas URLs distintas para o mesmo repositório remoto, sendo uma para leitura (fetch) e outra para escrita (push). Isto pode ser útil se precisarmos utilizar protocolos distintos para leitura e escrita.
É possível alterar o name deumrepositório remoto utilizando o comando git remote rename: git remote rename origin outronome
O que aconteceria se alguém alterasse o endereço IP do servidor de 192.168.1.1 para 192.168.1.2 ? Teríamos um problema, pois nosso repositório remoto estaria apontando para o endereço antigo. Devemos nesse caso alterar a url do repositório remoto, e isto é feito com outro comando, o git remote set-url, passando como parâmetro o name do repositório remoto e a nova url: git remote set-url servidor file://192.168.1.2/repo/moveis-ecologicos.git
A URL HTTPS que copiamos anteriormente como sendo origem do nosso repositório remoto, permite fazer push e pull de mudanças entre os dois. Por fim, vamos executar a operação de push com o comando: git push –u origin master
Neste comando é solicitado a inserir nosso nome de usuário e senha do Github que pode ser pelo console ou por uma caixa de diálogo:
Se aparecerem algumas informações, na parte inferior, indicando que o Branch Master está configurado para rastrear o Branch Master remoto desde a origem significa que tudo funcionou e que os repositórios estão configurados corretamente.
Agora, se voltarmos à página principal dos perfis do hub de obtenção, veremos agora que temos um repositório listado e se clicarmos nessa seção de repositórios e, em seguida, nos repositórios reais, podemos ver que as receitas de traço cerebral com traço com fio recebem repositórios que foi local agora está sendo hospedado e rastreado no Github.
GIT LOG
A vantagem de um sistema de controle de versão é que ele registra alterações. Esses registros nos permitem recuperar os dados como confirmações, descobrir bugs, atualizações. Mas toda essa história será inútil se não pudermos navegar nela. Neste ponto, precisamos do comando git log. O Git log é uma ferramenta utilitária para revisar e ler um histórico de tudo o que acontece com um repositório. Várias opções podem ser usadas com um log git para tornar o histórico mais específico.
Geralmente, o log do git é um registro de confirmações. Um log git contém os seguintes dados:
- Commit hash: que é um dado de soma de verificação de 40 caracteres gerado pelo algoritmo SHA (Secure Hash Algorithm). É um número único.
- Commit Author metadata: as informações de autores, como nome e email do autor.
- Commit Date metadata: é um registro de data e hora para a hora da confirmação.
- Commit title/message: é a visão geral do commit fornecido na mensagem de commit.
Para sair do comando git log basta pressionar a tecla Q (Quit). Ele sairá da situação e voltará para a linha de comando.
O comando log do Git é um dos comandos mais comuns do git. Toda vez que você precisar verificar o histórico, precisará usar o comando git log, que exibirá as confirmações mais recentes e o status do HEAD. Ele será usado como: git log
O comando acima está listando todas as confirmações recentes. Cada confirmação contém algum SHA-1 exclusivo. Ele também inclui a data, hora, autor e alguns detalhes adicionais.
Podemos executar algumas ações, como rolar, pular, mover e sair na linha de comando. Para rolar na linha de comando, utilize os comandos LESS descrito na sessão Git help visto anteriormente. A seguir estão um resumo de comandos log utilizados: Comando Descrição git log Exibir o histórico do log git log -3 Exibir um quantidade específica de logs, aqui exibirá 3 git log –parents Mostra o histórico, exibindo o ID SHA1 do commit pai para cada commit git log –parents –abbrev-commit Igual ao comando anterior, mas reduza o ID SHA1 git log –oneline Exibir histórico de forma concisa, usando uma linha por cada confirmação git log –patch Exibe o histórico, mostrando as diferenças de arquivo entre cada confirmação git log –stat Exibe o histórico, mostrando um resumo das alterações do arquivo entre cada confirmação git log –patch-with-stat Exibe o histórico combinando o patch e a saída stat git log –status Exibe o log com os arquivos que foram modificados git log –shortstat –oneline Mostrar histórico usando uma linha por confirmação e listando cada arquivo alterado por confirmação git log –merges Lista confirmações resultantes de mesclagens git log –oneline FILE List on-line que afetam FILE git log –oneline -all Exibe todas as entradas de log de confirmação de todas as branches git log –simplify-by-decoration –decorate –all –oneline Exibir o histórico de uma forma simplificada git log –grep=STRING Lista commits que possui STRING na mensagem de confirmação git log –since MM/DD/YYYY –until MM//DD/YYYY Lista commits entre duas datas git shortlog Resume commits de vários autores git shorlog -e Resume os commits de vários autores, incluindo email git log –author=AUTHOR Lista commits por autor git log -stat HEAD^..HEAD Lista a diferença entre o ramo com check-out atual e seu pai imediato git log –oneline master..new_feature Mostra as confirmações entre o ramo mestre e o ramo do recurso git log –graph –decorate –pretty=oneline –abbrev-commit Veja o histórico do repositório em todas as ramificações
git log --oneline
A opção on-line é usada para exibir a saída como uma confirmação por linha. Ele também mostra a saída resumidamente, como os sete primeiros caracteres do SHA de confirmação e a mensagem de confirmação.
git log --oneline
Portanto, geralmente podemos dizer que o sinalizador --oneline faz com que o git log seja exibido:
- Um commit por linha
- Os sete primeiros caracteres do SHA
- A mensagem de confirmação
Como podemos ver com mais precisão a partir da saída acima, todo commit é dado apenas em uma linha com um número sha de sete dígitos e uma mensagem de commit.
git log stat
O comando log exibe os arquivos que foram modificados. Também mostra o número de linhas e uma linha de resumo do total de registros que foram atualizados.
git log --stat
Geralmente, podemos dizer que a opção stat é usada para exibir
- os arquivos modificados,
- O número de linhas que foram adicionadas ou removidas
- Uma linha de resumo do número total de registros foi alterada
- As linhas que foram adicionadas ou removidas.
git log p
O comando git log patch exibe os arquivos que foram modificados. Ele também mostra o local das linhas adicionadas, removidas e atualizadas.
git log --patch Ou git log -p
Geralmente, podemos dizer que o sinalizador --patch é usado para exibir:
- Arquivos modificados
- O local das linhas que você adicionou ou removeu
- Alterações específicas que foram feitas.
A saída acima está exibindo os arquivos modificados com o local das linhas que foram adicionadas ou removidas.
git log graph
O comando Git log permite visualizar o seu git log como um gráfico. Para listar as confirmações na forma de um gráfico, execute o comando git log com a opção --graph. Ele será executado da seguinte maneira:
git log --graph
Para tornar a saída mais específica, você pode combinar este comando com a opção --oneline. Funcionará da seguinte maneira:
git log --graph --oneline
Intervalos de Commits
Agora que você pode especificar confirmações individuais, vamos ver como especificar intervalos de confirmações. Isso é particularmente útil para gerenciar suas ramificações - se você tiver muitas ramificações, poderá usar as especificações do intervalo 215 para responder a perguntas como: "Qual é o trabalho nessa ramificação que ainda não fundei em minha ramificação principal?"
Ponto duplo
A especificação de intervalo mais comum é a sintaxe de ponto duplo. Isso basicamente pede ao Git que resolva uma série de confirmações acessíveis a partir de uma confirmação, mas não acessíveis a partir de outra. Por exemplo, digamos que você tenha um histórico de consolidação que se parece com:
Você deseja ver o que há em seu ramo de experiência que ainda não foi mesclado ao seu ramo mestre. Você pode pedir ao Git para mostrar um registro apenas daqueles que confirmam com o mestre..branch - isso significa "todos os confirmados alcançáveis pelo experimento que não são alcançáveis pelo mestre".
git log master..new_branch
Por outro lado, você deseja ver o contrário - todos os commits no mestre que não estão em experimento - é possível reverter os nomes dos ramos. branch..master mostra tudo o que o mestre não está acessível a partir do experimento: git log new_branch..master
Isso é útil se você deseja manter o ramo do experimento atualizado e visualizar o que está prestes a mesclar. O uso dessa sintaxe é para ver o que você está prestes a enviar para um controle remoto: git log master..HEAD
Este comando mostra quaisquer confirmações em sua branch atual que não estão na branch principal em seu controle remoto de origem. Se você executar um push do git e sua ramificação atual estiver rastreando a origem/mestre, os commits listados por git log origin/master..HEAD são os commits que serão transferidos para o servidor. Você também pode deixar um lado da sintaxe para o Git assumir HEAD. Por exemplo, você pode obter os mesmos resultados que no exemplo anterior digitando: git log origin/master..
Vários pontos
A sintaxe de dois pontos é útil como uma abreviação; mas talvez você queira especificar mais de duas ramificações para indicar sua revisão, como ver quais confirmações existem em uma das várias ramificações que não estão na ramificação em que você está atualmente. O Git permite que você faça isso usando o caractere ^ ou --not antes de qualquer referência da qual você não deseja ver confirmações acessíveis. Portanto, esses três comandos são equivalentes: git log refA..refB git log ^refA refB git log refB --not refA
Isso é bom porque com esta sintaxe você pode especificar mais de duas referências em sua consulta, o que você não pode fazer com a sintaxe de ponto duplo. Por exemplo, se você deseja ver todos os commits acessíveis a partir de refA ou refB, mas não a partir de refC, você pode digitar um destes: git log refA refB ^refC git log refA refB --not refC
Isso oferece um poderoso sistema de consulta de revisão que deve ajudá-lo a descobrir o que há em seas branchs.
Ponto triplo
A última sintaxe principal de seleção de intervalo é a sintaxe de ponto triplo, que especifica todos os commits que são alcançáveis por uma das duas referências, mas não por ambas. Se você quiser ver o que há no branch mestre ou em outro branch, mas não em nenhuma referência comum, é possível executar: git log master ...new_branch
Novamente, isso é uma saída normal de log, mas mostra apenas as informações de confirmação desses commits, que aparecem na ordem tradicional da data de confirmação. Uma opção comum a ser usada com o comando log nesse caso é –left-right, que mostra em qual lado do intervalo cada confirmação está. Isso ajuda a tornar os dados mais úteis: git log --left-right master ...new_branch
Filtrando o histórico de Commits
Podemos filtrar a saída de acordo com nossas necessidades. É uma característica única do Git. Podemos aplicar muitos filtros como quantidade, data, autor e muito mais na saída. Cada filtro tem suas especificações. Eles podem ser usados para implementar algumas operações de navegação na saída.
-
Por quantidade: Para limitar a saída do log do git, incluindo a opção - . Se queremos apenas os três últimos commit, podemos passar o argumento -2 no comando git log. Considere a saída abaixo:
-
Por data e hora: Podemos filtrar a saída por data e hora. Temos que passar o argumento --after ou -before para especificar a data. Esses dois argumentos aceitam uma variedade de formatos de data.: git log --after="2020-06-17"
Também podemos passar uma referência aplicável como "yesterday," "1 week ago", "21 days ago,": git log --after="21 days ago"
Também podemos rastrear os commits entre duas datas. Para rastrear as confirmações criadas entre duas datas, passe uma referência de instrução --after e --before da data. Podemos usar também os sinônimos --since e –unty. git log --after="2020-06-14" --before="2020-06-17"
- Por autor: Podemos filtrar as confirmações por um usuário específico. Suponha, queremos listar os commits feitos apenas por um membro da equipe em particular. Podemos usar o sinalizador -author para filtrar os commit pelo nome do autor. Este comando usa uma expressão regular e retorna a lista de confirmações feitas por autores que correspondem a esse padrão. Você pode usar o nome exato em vez do padrão. O nome do autor não precisa ser uma correspondência exata; apenas possui a frase especificada. git log --author="Nome do autor"
Como sabemos, o email do autor também está envolvido com o nome do autor, para que possamos usar o email do autor como padrão ou pesquisa exata. Suponhamos que desejamos rastrear os commits pelos autores cujo serviço de email é o google. Para fazer isso, podemos usar curingas como "@gmail.com". git log --author="@gmail.com"
-
Por mensagem de confirmação: Para filtrar as confirmações pela mensagem de confirmação. Podemos usar a opção grep, e ela funcionará como a opção do autor. Podemos usar a forma abreviada de mensagem de confirmação em vez de uma mensagem completa. git log --grep = "Confirmar mensagem."
-
Por conteúdo do arquivo: Para filtrar as confirmações por conteúdo. O parâmetro –G + o ermo a pesquisar que az a filtragem. git log -Gmoon –patch
-
Por comparação de branches: Retorna os commits que foram feitos em um ramo e não estão no outro. Ùtil ao realizar merges.
GIT SHOW
Mostra um ou mais objetos (blobs, árvores, tags e confirmações). O comando utiliza as opções aplicáveis ao comando git diff-tree para controlar como as mudanças introduzidas pelo commit são mostradas.
Comando Descrição git show Mostra a mensagem de log e a diferença de texto. Ele também apresenta o commit de mesclagem em um formato especial, produzido pelo git diff-tree --cc. git show git show git show mostra a mensagem da tag e os objetos referenciados. git show mostra os nomes (equivalente a git ls-tree com --name-only). git show mostra o conteúdo simples.
git log --graph –decorate --oneline
Digamos que eu quero ver informações sobre o commit atual. Quero saber quais alterações foram introduzidas por esse commit, a data do commit e assim por diante. Podemos usar os seguintes comandos git show SHA-1.
No entanto, o uso de hashes nem sempre é a maneira mais fácil ou prática de se referir a uma confirmação. Outra maneira de fazer isso é dar ao Git o nome de uma referência que está apontando para o commit. Por exemplo, poderia ser o ramo nogood ou o HEAD que está apontando para o ramo que está apontando para o commit: git show nogood OU git show HEAD
Mas agora, e se quisermos referenciar esse outro commit, o penúltimo? Não há referência apontando para ele, então parece que nossa única opção é usar seu hash.
No entanto, existem outras maneiras. Posso começar em HEAD e adicionar um sinal de intercalação ^^. O sinal de intercalação significa o commit-pai, então agora estou pedindo o pai confirmar. Como no console do Windows este sinal representa escape, temos sempre que dobra o sinal como abaixo:
E se eu quiser me referir ao ante-penúltimo commit, precisamos usar 4 pontos de intercalação, e assim por diante. Digamos, que você queira o décimo commit antes da cabeça e não quiser digitar 20 pontos de intercalação, pode utilizar o sinal de til seguido de um número. Você pode lê-los como ir para a cabeça e depois voltar para confirmações. git show HEAD~10
Essa sintaxe é boa se cada confirmação tiver exatamente um pai, mas não funcionará se tiver um commit com vários pais, como é o caso de commit de mesclagem.
É o segundo pai do segundo commit antes do head. Nesse caso, eu posso direcioná-lo com esta sintaxe.
git show HEAD~2^2
Você também pode especificar um SHA-1 junto com o ^, por exemplo o segundo pai de ecbebe6: git show ecbebe6^2
Comece da cabeça, volte duas confirmações e escolha o segundo pai. Existem outras maneiras ainda mais sofisticadas de se referir a confirmações. Alguns deles são surpreendentemente sofisticados. Apenas para um exemplo rápido, pedi ao Git para me mostrar onde estava a cabeça há um mês.
git show HEAD@(“1 month ago”)
GIT BLAME E DIFF
Agora que você sabe como se referir a um commit, vamos finalmente falar sobre como você pode explorar como esses commits estão conectados, seu histórico. Existem alguns comandos úteis para isso, um deles mostra de onde as linhas do arquivo são provenientes para saber quem mudou o arquivo apple_pie e quando:
git blame FILE
Aqui estão todas as linhas no arquivo. Para cada linha, você pode ver a confirmação mais recente em que essa linha foi alterada. O sinal de intercalação aqui significa que este é o primeiro commit que adicionou esta linha ao repositório. Portanto, essas linhas estão no arquivo desde a primeira vez que o arquivo foi adicionado ao projeto e todas as outras linhas foram alteradas ou adicionadas em algumas outros commits.
Outro comando útil é o git diff. Já usamos o git diff neste treinamento para comparar o conteúdo de duas áreas, como o repositório e o índice, mas você também pode usá-lo para comparar outros objetos. Por exemplo, dois commits. Vamos ver as diferenças entre o commit atual e os dois commit anteriores.
git diff HEAD1 HEAD2
O único arquivo que foi alterado entre os dois commits foi o menu.txt. Você pode usar também ramificações para referenciar confirmações. Uma técnica comum é usar git diff para comparar duas ramificações, especialmente antes de mesclar coisas. Isso mostra todas as alterações entre os dois ramos.
GIT RESET E CHECKOUT
Trabalhando com caminhos (path)
Você também pode fornecer um caminho para aplicar o reset. Se você especificar um caminho, o reset ignorará a etapa 1 e limitará o restante de suas ações a um arquivo ou conjunto de arquivos específico. Já o git checkout faz duas coisas essencialmente.
- No repositório, ele move a referência do HEAD, geralmente para outra ramificação, para alterar a confirmação atual.
- Obter dados do novo commit atual e copiar esses dados do repositório para a área de trabalho e o índice
Repare que a mesma definição foi dada ao comando git reset anteriormente. Como reset, o checkout manipula as três árvores com a diferença de que o segundo passo temos maior controle no comando reset pois temos os parâmetros soft, mixed e hard que definem o que será copiado. Porém, existem diferenças internas entre eles, especialmente se você atribui ao comando um caminho de arquivo ou não.
Sem definir o caminho
A execução de git checkout [branch] é bastante semelhante à execução de git reset --hard [branch], pois atualiza todas as três árvores para você parecer com [branch], mas há duas diferenças importantes.
- Segurança para diretório de trabalho: Ao contrário do reset --hard; o checkout verifica se não está descartando arquivos com alterações neles. Na verdade, é um pouco mais inteligente que isso - ele tenta fazer uma mesclagem trivial no diretório de trabalho, para que todos os arquivos que você não alterou sejam atualizados. reset --hard, por outro lado, simplesmente substituirá tudo em geral sem verificar.
- Atualização do HEAD: O reset irá mover o ramo que o HEAD aponta, o checkout moverá o próprio HEAD para apontar para outro ramo.
Por exemplo, digamos que temos os branches master e develop que apontam para commits diferentes e atualmente estamos no branch develop (então HEAD aponta para isso). Se rodarmos o git reset master, o branch develop agora apontará para o mesmo commit que o mestre. Se, em vez disso, rodarmos o git checkout master, o develop não se moverá, o próprio HEAD o fará. HEAD agora apontará para o mestre.
Então, nos dois casos, estamos movendo HEAD para apontar para o commit A. Mas como fazemos isso é muito diferente, com o reset o branch que HEAD aponta se move, com o checkout move o próprio HEAD.
Com caminhos definidos
A outra maneira de executar o checkout é com um caminho de arquivo que, como reset, não move HEAD. É como o git reset [branch] FILE, pois atualiza o índice com esse arquivo naquele commit, mas também sobrescreve o arquivo no diretório de trabalho. Seria exatamente como o comando git reset --hard [branch] FILE (se o reset permitir que você execute isso) - não é um diretório de trabalho seguro e não move HEAD.
Além disso, como git reset e git add, o checkout aceita uma opção --patch para permitir a reversão seletiva do conteúdo do arquivo, pedaço por pedaço.
Espero que agora você entenda e se sinta mais à vontade com o comando reset. Caso ainda esteja um pouco confuso sobre como exatamente difere do checkout e não consiga se lembrar de todas as regras das diferentes invocações. Aqui está uma folha de dicas para quais comandos afetam quais árvores. A coluna "HEAD" lê "REF" se esse comando move a referência (ramificação) para a qual HEAD aponta, e "HEAD" se move o próprio HEAD. Preste atenção especial a coluna WD Safe? - se ele disser NÃO, pense um pouco antes de executar esse comando. HEAD Index Workdir WD Safe? Commit Level reset --soft [commit] REF NO NO YES reset [commit] REF YES NO YES reset --hard [commit] REF YES YES NO checkout [commit] HEAD YES YES YES File Level reset (commit) [file] NO YES NO YES checkout (commit) [file] NO YES YES NO
Vamos dar uma redorçada com esse exemplo a seguir. Imagine que temos a seguinte situação:
Normalmente, o comando reset copia todos os dados da confirmação atual para o índice, mas, neste caso, estamos dizendo que queremos redefinir apenas o arquivo menu.txt.
git reset HEAD menu.txt
De fato o README ficou preparado e somente o arquivo de menu, não foi preparado. Agora, se quisessemos também remover as alterações de menu.txt da área de trabalho. Se tentarmos usar a mesma instrução, só que desta vez o reset com o parâmetro –hard, não funciona. Isso por que já foram feitas alterações na versão WD e o Git proteje para que você não perca essas alterações.
Neste caso a maneira indicada de reverter um único arquivo ou diretório em uma área de trabalho sem tocar em outros arquivos é usar o checkout.
Normalmente, o checkout move o Referência HEAD no repositório, geralmente para uma ramificação e, em seguida, copia todos os arquivos do repositório para a área de trabalho e o índice. Nesse caso, nosso checkout não moverá HEAD. O checkout copiará apenas as coisas do commit atual no repositório para a área de trabalho e o índice. E isso será feito apenas para o arquivo que especificamos. Então, perdemos todas as alterações nesse arquivo. O menu volta ao local onde estava na confirmação mais recente, exatamente o que queríamos.
É importante reforçar que o git checkout -- é um a comando perigoso. Você pode perder toda modificação feita em um arquivo. O Git apenas substitui o arquivo pela última versão (mais recente) que sofreu commit sem emitir um aviso. Nós destruímos todas as nossas alterações no arquivo de menu de maneira rápida e irrecuperável. Nunca use este comando a não ser que você saiba com certeza que não quer salvar as modificações do arquivo.
GIT SWITCH E RESTORE
Desfazendo as Modificações de um Arquivo de forma segura
Existem dois comandos que ainda são experimentais no Git. Eles são chamados de git switch e git restore. Eles estão disponíveis nas versões mais recentes do Git mas sendo experimentais, eles podem mudar, desaparecer mas provavelmente ficarão mais importantes no futuro. Comando Descrição git switch Para lidar com ramificações, como mover para uma ramificação diferente ou até mesmo criar a ramificação no processo, se não existir git restore Trata-se de restaurar arquivos na árvore de trabalho a partir do índice ou de outro commit. Este comando não atualiza sua ramificação. O comando também pode ser usado para restaurar arquivos no índice de outra confirmação. git checkout file Confira a última versão confirmada do arquivo no seu diretório de trabalho git checkout your_SHA1id Altere seu diretório de trabalho para corresponder a um SHA1id especificado
Ambos substituem algumas funcionalidades do comando git checkout. O git checkout é um dos comandos Git que fazem várias coisas, e pode ser usado de diferentes maneiras. Em particular, para entender melhor o comando git restore e switch, ajuda a separar git checkout. Em dois comandos:
-
Um para ramificações (git switch), que lida apenas com ramificações, não com arquivos. Você pode usá-lo para mover para uma ramificação git checkout master OU git checkout branch
-
Um para arquivos (git restore), que pode cobrir casos de git reset. Se você não quiser manter as modificações de um arquivo. Como você pode reverter as modificações, voltando a ser como era quando foi realizado o último commit (ou clone inicial, ou seja como for que você chegou ao seu working directory): git checkout -- teste.txt
E você sabe que, internamente, essas duas coisas são essencialmente as mesmas. Ambos são sobre mover a referência HEAD, então faz sentido que o Git tenha um único comando para as duas operações. Mas, do lado de fora, essas duas operações parecem dois recursos diferentes, especialmente para um iniciante. Então, para resolver essa confusão, os mantenedores do Git estão experimentando uma divisão do checkout em dois comandos diferentes, switch para lidar com ramificações, como mover para uma ramificação diferente ou até mesmo criar a ramificação no processo, se não existir, e restore para lidar com arquivos especificamente. Assim, você pode restaurar o índice e a árvore de trabalho (é o mesmo que usar git-checkout) git restore --source=HEAD --staged --worktree test.txt
Ou a forma abreviada que é mais prática, mas menos legível: git restore -s@ -SW teste.txt
Lembre-se, qualquer coisa que está sobre commit com Git pode quase sempre ser recuperada. Até mesmo commits que estava em algum branches que foram deletados ou commits que forma sobre escritos através de um --amend podem ser recuperados. Contudo, qualquer coisa que você perder que nunca sofreu commit pode ser considerada praticamente perdida.
GIT REFLOG
Sempre que você faz algo que muda o histórico, como um rebase interativo ou um amend em uma confirmação, o Git precisa copiar informações de confirmações antigas para novas confirmações. Os novos commits podem parecer com os antigos, mas não são os mesmos objetos. E os antigos commits são deixados para trás. Geralmente, eles são inacessíveis. Não há mais ramificação ou tag apontando para eles, portanto eles permanecerão no banco de dados de objetos por um tempo até que o Git finalmente decida coletar lixo.
Uma situação não muito comum, mas às vezes pode acontecer, é se precisar recuperar um desses objetos. Por exemplo, e se eu fizer uma nova recuperação interativa e excluir uma confirmação por engano? Agora, esse commit e seus dados associados não estão mais no histórico. Sei que eles ainda estão em algum lugar no banco de dados de objetos, mas não conheço mais os hashes deles, então não posso recuperá-los.
A boa notícia é que existe uma maneira muito fácil de recuperar os hashes de objetos abandonados. Toda vez que a referência é movida em um repositório, o Git registra essa movimentação. Por exemplo, quando você faz checkout de uma ramificação, está movendo a referência HEAD, então o Git está registrando isso. Vamos dar um checkout no ramo new_branch. E então vamos fazer o checkout master novamente.
Mudei a referência HEAD duas vezes. O Git registra todos esses movimentos nos últimos meses em algo que é chamado de log de referência ou reflog. E eu posso olhar para o reflog com o comando: git reflog
Vamos olhar para o HEAD. Veja as duas primeiras linhas do reflog. Ele nos diz que as duas últimas alterações no HEAD foram do new_branch para o master e depois do master para o new_branch novamente. E, se você continuar lendo, poderá ver todas as alterações no HEAD que aconteceram. E essa informação vem com os hashes dos objetos que o HEAD estava apontando.
Até que o lixo seja coletado, seu hash permanece no reflog, portanto ainda podemos analisá-lo referenciando o hash diretamente ou usando esta sintaxe que significa a 15ª posição anterior do HEAD: git show HEAD@{15}
Você também pode usar esta sintaxe para ver onde um ramo foi há algum tempo específico atrás. Por exemplo, para ver onde estava sua branch principal ontem, você pode digitar: git show master@{yesterday}
Isso mostra onde a dica da branch estava ontem. Essa técnica funciona apenas para dados que ainda estão no seu reflog, portanto você não pode usá-los para procurar confirmações anteriores a alguns meses. Para ver informações de reflog formatadas como a saída do log git, você pode executar git log –g master
Por exemplo, você pode colocar um ramo nele e não será mais um commit abandonado. Apenas para esclarecer, as informações no reflog são estritamente locais. Esse reflog pertence a este repositório e somente a ele. Se eu clonar este repositório novamente em outro diretório, obteria um reflog diferente. Mas quando se trata deste repositório, toda vez que o HEAD se move, o Git o registra aqui o momento em foi clonado o repositório do GitHub. E o mesmo vale para outras referências, como o ramo principal.
Espero que isso faça você se sentir um pouco mais seguro quando estiver usando o Git. Nos módulos anteriores, vimos algumas operações que são verdadeiramente irreversíveis e destroem dados, mas essas operações geralmente destroem dados na sua área de trabalho e talvez no índice. Quando se trata do repositório, geralmente você pode recuperar todos os objetos que você deixou para trás graças ao reflog. GIT CHERRY-PICK
O comando git cherry-pick é usado para aceitar as alterações introduzidas em um único commit do Git e tentar reintroduzi-lo como um novo commit no ramo em que você está atualmente. Um git cherry-pick é como um rebase de um único commit. Ele pega o patch que foi introduzido em um commit e tenta reaplicá-lo no ramo em que você está atualmente.
Isso é útil se você tiver várias confirmações em uma ramificação e desejar integrar apenas uma delas, ou se tiver apenas uma confirmação em uma ramificação de tópico e preferir selecioná-la em vez de executar um rebase. Por exemplo, suponha que você tenha um projeto parecido com este:
Se você deseja inserir o commit e43a6 em sua ramificação principal, pode executar git cherry-pick e43a6
Isso gera a mesma alteração introduzida no e43a6, mas você obtém um novo valor de confirmação SHA-1, porque a data aplicada é diferente. Agora seu histórico se parece com o seguinte:
Agora você pode remover sua ramificação de tópico e eliminar as confirmações que não desejava obter.
RERERE
Se você estiver fazendo várias mesclagens e reestruturações ou mantendo uma ramificação de tópicos de longa duração, o Git tem um recurso chamado "rerere” que pode ajudar.
Rerere significa "reutilizar a resolução gravada" - é uma maneira de atalho para a resolução manual de conflitos. Quando rerere está ativado, o Git manterá um conjunto de imagens pré e pós de mesclagens bem-sucedidas e, se perceber que há um conflito parecido com o que você já corrigiu, usará a correção da última vez, sem incomodá-lo com isso. Esse recurso vem em duas partes: uma configuração e um comando. A configuração é rerere.enabled e é útil o suficiente para colocar em sua configuração global:
git config --global rerere.enabled true
Agora, sempre que você faz uma mesclagem que resolve conflitos, a resolução será registrada no cache, caso você precisa disso no futuro. Se necessário, você pode interagir com o cache rerere usando o comando git rerere. Quando invocado sozinho, o Git verifica seu banco de dados de resoluções e tenta encontrar uma correspondência com qualquer conflito de mesclagem atual e resolvê-los (embora isso seja feito automaticamente se rerere.enabled estiver definido como true). Também existem subcomandos para ver o que será gravado, apagar resolução específica do cache e limpar o cache inteiro. Abordaremos rerere com mais detalhes em Rerere.
GIT REVERT
Ao mudar a história de commits é algo com o qual você deve ter cuidado, para não mudar uma história compartilhada e assim por diante. O git revert um comando que é completamente seguro a esse respeito. Não destrói dados, não altera o histórico existente. Ele fixa o histórico, sem alterar nenhum commit, apenas cria novos commits
O comando git revert é essencialmente um pick-cherry reverso do git. Ele cria um novo commit que aplica exatamente o oposto da alteração introduzida no commit que você está direcionando, essencialmente desfazendo ou revertendo. Comando Descrição git revert Cria um novo commit que reverte as alterações feitas por outras confirmações.
Se quisermos voltar atrás, desfazendo as alterações no repositório, podemos utilizar o comando: git revert --no-edit 5fe86e1
Nesse comando, o 5fe86e1 representa o último commit efetuado. Se omitirmos a opção --no-edit, será aberto um editor de texto para editarmos a mensagem do novo commit. Em vez de passar o código do último commit como parâmetro para o git revert, poderíamos ter utilizado HEAD que, no nosso caso, aponta para o último commit.
Note que o comando git revert efetuou um novo commit com a versão anterior dos arquivos. Foi utilizada a mensagem Revert seguida da mensagem do commit anterior (no exemplo, Revert "Update file 1").
No caso de passarmos um código de commit antigo, apenas as alterações feitas naquele commit serão desfeitas. Isso é algo bastante poderoso! Imagine que você descubra que um bug veio de uma alteração de determinado commit em um conjunto de arquivos. Apenas com um git revert é possível desfazer as alterações que inseriram o bug. Por isso, vale reiterar que commits pequenos e bem montados são importantes para podermos utilizar o real poder do Git.
Ocasionalmente, você encontrará conflitos ao executar uma reversão. Não há razão para entrar em pânico. Simplesmente trate-o como qualquer outro conflito de mesclagem e siga as instruções na tela do Git:
Quando ocorrer um erro - verifique a mensagem de status para ver quais arquivos precisam ser revisados:
Não use a opção -m. A opção -m nesse caso tem a ver com um caso especial de reverter uma mesclagem. Há também uma opção --no-commit (-n). Isso permite reverter as coisas, mas apenas no diretório de trabalho e na área de preparação. O usuário ainda precisa fazer uma operação de confirmação separada para fazer a alteração no repositório local.
REMOVER E MOVER ARQUIVOS
Remover completamente um arquivo de seu projeto Git é algo que precisa de consideração especial, especialmente se tivermos modificado o arquivo em um projeto e sua versão do arquivo está sendo rastreada pelo Git. No Git, remover sem argumentos não é o oposto de git add. Adicionar apenas altera seu índice, enquanto a remoção simples altera seu índice e sua área de trabalho. Você precisa usar a opção --cached para fazer o trabalho de remoção ser o oposto de adicionar.
Comando Descrição
git rm file Remover arquivo da área de preparação. Para diretório adicionar o parâmetro –r para executar o comando recursivamente.
git rm --cached file Deixa de rastrear o arquivo, mas não o remove do projeto. Para diretório adicionar o parâmetro –r para executar o comando recursivamente.
git mv file1 file2 Renomeie o arquivo1 para o arquivo2 na área de preparação
git ls-tree HEAD Exibe todos os arquivos do HEAD
Por exemplo, se tentarmos remover um arquivo que está sendo rastreado, foi modificado e está preparado, dá a seguinte mensagem:
O que aconteceu é que o git percebeu que o arquivo que estou removendo não está no repositório. E isso me dá algumas opções. Eu posso forçar a remoção, o que é como dizer sim, eu sei o que estou fazendo, basta excluir este arquivo e esquecê-lo. E eles também têm a opção de remover o arquivo apenas do índice, mas não a área de trabalho com --cached.
-
Digite “git ls-files” na linha de comando para exibir o arquivo.
-
Informar Git para parar de rastrear o arquivo. Podemos fazer isso usando o comando git rm “nomearquivo”
-
Para deixar de rastrear o arquivo, mas não remover-lo do projeto: git rm --cached “nomearquivo”
-
Digite o git status para veficar que o arquivo está sendo exibido como um arquivo excluído em nossa área de preparação. Na próxima vez que for executado o commit, esse arquivo não será mais rastreado pelo Git e será removido do nosso projeto.
Renomear arquivos
Ao renomear um arquivo pelo comando de console move ou ren:
Ao solicitar o git status, o Git pode ver que há um arquivo na área de trabalho que não está no índice, não é rastreado, que é o arquivo com o nome. E também, o Git pode ver outro arquivo que está no índice, mas não na área de trabalho, então ele marca como deletado.
Podemos então copiar as alterações do arquivo com novo nome da área de trabalho para o índice.
Apesar de ser estranho, podemos incluir também ao índice, o item file.txt (antigo nome) que nem está na área de trabalho. Isso acontece, pois, a operação adicionar significa copiar esses dados da área de trabalho para o índice. Portanto, se esses dados não forem nada, como neste caso, o Git simplesmente substituirá os dados no índice com nada, o que significa que removerá esses dados do índice.
Agora que temos os mesmos dados na área de trabalho e no índice. Repare que o Git já entendeu o que está acontecendo. Ele comparou o conteúdo do arquivo na área de trabalho e o índice com o conteúdo dos arquivos no repositório. E percebeu que os arquivos têm o mesmo conteúdo, portanto, eles devem ter o mesmo arquivo com um nome diferente. Isso é bastante inteligente e funciona tanto para renomear quanto para mover. Na maioria dos casos, entende até quando está renomeando ou movendo um arquivo, mesmo que você altere o conteúdo do arquivo ao mesmo tempo.
Um comando mais conveniente do git que realiza todas essas etapas, de renomear, mover o arquivo na área de trabalho e atualiza o índice em apenas o faz em uma única captura é o: git mv file1 file2
INTRODUÇÃO A BRANCHES
Os branches são úteis nas situações em que temos alguns arquivos em nossa área de preparação aguardando confirmação (ramo mestre) mas deseja criar e modificar alguns outros arquivos (ramo secundário) que não serão confirmados juntamente com os arquivos do ramo principal. Para mais detalhes sobre os tipos de branches mais comuns leia a seção mais abaixo sobre fluxo de trabalho.
Comando Descrição git branch Listar todos os branches git branch dev Crie um novo ramo chamado dev git checkout dev Altere seu diretório de trabalho para o ramo chamado dev git checkout -f master Efetua checkout no ramo principal, descarta quaisquer alterações no ramo atual git checkout -b new_branch Cria um branch e efetua checkout para esse ramo. git checkout -b another_fix_branch fixing_readme Torna o nome de uma ramificação outro fix_branch usando a ramificação fixa_readme como ponto de partida git branch new_branch Cria um branch chamado new_branch git branch -d master Exclua o ramo chamado master git branch -v Lista todos os branches com informações do SHA1 git branch -all Mostra ramificações de rastreamento remoto além das ramificações locais git branch –column Lista os ramos pelo nome da coluna git name-rev SHA1 Dado um SHA1, ele fornece o nome da ramificação git branch fixing_readme YOUR_SHA1ID Criando um branch usando YOUR_SHA1ID como ponto de partida git diff BRANCH1…BRANCH2 Indica a diferença entre BRANCH1 e BRANCH2 em relação a quando se tornaram diferentes git diff –name-status BRANCH1…BRANCH2 Resuma a diferença entre BRANCH1 e BRANCH2 git push –set-upstream origin new_branch Cria uma ramificação de rastreamento remoto para new_branch na origem nomeada remota git config –get-regexp branch Lista todas as definições de configuração do git que possuem a palavra branch no nome da variável git branch -d local branch Remova a ramificação local denominada ramificação local git push origin :remotebranch Remova a ramificação chamada remotebranch da origem nomeada remota git cherry-pick SHA1 ID Copie o commit no ramo atual em que você está
Uma maneira realmente entender melhor o funcionamento dos branches é através do endereço: http://git-school.github.io/visualizing-git/
Aqui vemos um ponto verde que representa o ramo mestre dos projetos e no canto inferior esquerdo é possível inserir comandos do Git. Ao adicionar git commit ao visual, vemos que o HEAD, que é para onde estamos apontando no nosso projeto, está se movendo junto com o master. Tudo foi feito no ramo mestre até este ponto.
Um branch and Git é simplesmente um ponteiro leve e móvel para uma confirmação feita em um projeto. Vamos criar uma nova ramificação fora da ramificação principal digitando: git checkout -b new_branch
O comando Git checkout permite que você faça checkout para uma ramificação diferente, e a opção “-b” está dizendo ao git que queremos criar um novo ponteiro chamado new_branch e depois dar o checkout. Observe que nosso novo ramo, mestre e chefe apontam (HEAD) para o mesmo commit em nosso projeto. Mas como fizemos check-out em nossa nova branch e não estamos mais em nosso mestre esse ponteiro agora está em new_branch. Se dermos alguns commit no new_branch:
Observe que o master fica para trás e o new_branch se move junto com o ponteiro HEAD, pois estamos fazendo commits no new_branch e não mais no master. E podemos voltar ao nosso ramo principal digitando: git checkout master.
Note que o ponteiro HEAD agora foi de volta para o ramo principal. Se você confirmar em uma ramificação, a menos que sejam explicitamente alteradas, serão vinculadas a essa ramificação. Se fizermos alterações no ramo mestre, essas alterações estarão apenas no ramo mestre, elas não serão incluídos no novo ramo e vice-versa.
A ramificação do mestre nos permite criar um ambiente paralelo onde podemos experimentar novas idéias e fazer alterações ou ao trabalhar com vários colaboradores sem afetar o ramo mestre.
Quando criamos um projeto Git, e fazemos nosso primeiro commit, o Git cria uma ramificação para nós. Para consultar a lista de ramificações no projeto digite sem nenhum argumento: git branch
Se quisermos listar as branches existentes no nosso repositório com os commits associados, poderíamos utilizar a opção -v do comando git branch: git branch -v
E aí está, nossa ramificação padrão, a ramificação mestre. O Git normalmente coloca ramificações aqui no diretório chamado refs e em um subdiretório chamado heads.
Observe que o ramo mestre realmente não possui status especial no Git, é apenas um ramo como qualquer outro. E tudo o que existe é esse pequeno arquivo. Na verdade, eu poderia excluir ou renomear o ramo mestre apenas excluindo ou renomeando este arquivo. Eu poderia até criar uma nova ramificação apenas escrevendo um novo arquivo nessa pasta contendo o SHA-1 de uma confirmação.
Como não está compactado, então não precisamos utilizar o comando cat-file e podemos utilizar o comando type para que imprimir seu conteúdo na tela.
O arquivo contém uma única linha, um SHA‑1. E como você provavelmente espera, é o SHA‑1 do útimo commit. E o ramo nada mais é do que uma simples referência, um ponteiro para um commit. É por isso que o diretório que contém ramificações é chamado refs. Em vez disso, vamos criar uma nova ramificação da maneira correta, usando git branch com o nome da ramificação. Para criar um branch sem fazer checkout digite: git branch new_branch
Ao executar o comando git status verá que ele indica “On branch master”. Temos um novo ramo. Podemos vê-lo listado entre os branches e ao lado de master na pasta refs/heads. E se olharmos para ele, vemos que ele tem exatamente o mesmo conteúdo que o mestre, o mesmo commit. Então é isso que temos agora, dois commits, dois branches e os branches estão apontando para o mesmo commit.
Agora que temos dois ramos, se olharmos para a lista de ramos novamente, vemos que um ramo está marcado com um asterisco porque é o ramo atual. Se você olhar para a pasta .git novamente, verá um arquivo chamado HEAD. E se você olhar dentro do HEAD, verá que ele contém uma referência a um arquivo refs/heads/master, que indica qual ramificação é a ramificação atual. É isso que HEAD é, uma referência a um ramo, um ponteiro para um ponteiro.
Para deletar uma branch, devemos utilizar a opção -d do comando git branch. Se já tivéssemos feito algum commit na branch loja, ao executarmos git branch -d loja teríamos como resposta: git branch -d new_branch
Não é possível deletar com a opção -d uma branch que possui commits ainda não aplicados em outras branches (veremos como mesclar branches mais adiante). Para removermos a branch loja se tivermos feito algum commit, devemos utilizar a opção -D: git branch -D new_branch
Então agora vamos alterar o arquivo apple_pie.txt com o edit VS Code: start code recipes/apple_pie.txt
Vou adicionar a lista de ingredientes para a torta de maçã.
Vamos prepara as alterações e confirmá-la. O Git criou um novo objeto commit no banco de dados de objetos, e esse commit tem o commit anterior como pai. Em seguida, o Git olhou dentro do arquivo HEAD para descobrir qual é o ramo atual e moveu esse ramo para apontar para o novo commit.
Portanto, o ramo mestre se moveu e observe que o HEAD estava apontado para o mestre antes do commit e continua pontando para o mestre.
Até agora, não tocamos no novo ramo new_branch, que está apontando para o commit anterior onde estava quando o criamos. Agora vamos fazer do new_branch o ramo atual com a operação chamada git checkout.
Quando eu faço check-out lisa, duas coisas acontecem. A primeira coisa que acontece é que o Git muda HEAD para apontar para new_branch. Lá, agora o HEAD está apontando para refs/heads/new_branch.
A segunda coisa que acontece é mais sutil. O Git acabou de substituir os arquivos e pastas em nossa área de trabalho, o diretório de trabalho, pelos arquivos e pastas neste commit. Portanto, após o checkout, nossa área de trabalho mudou para o conteúdo do commit apontado por new_branch. Se eu olhar o conteúdo do arquivo da torta de maçã aqui, os ingredientes sumiram. Esta é a versão anterior do arquivo.
Isso que o checkout significa. Significa mover HEAD e atualizar a área de trabalho. Agora vamos modificar a receita da torta de maçã novamente. Estou usando quase a mesma lista de ingredientes que temos no ramo principal, mas new_branch também usa canela em sua versão da torta e ela usa mais maçãs, 88 maçãs.
Vamos confirmar essas alterações. O Git solicitou a confirmação no banco de dados do objeto e move a ramificação atual, new_branch, para apontar para a nova confirmação. HEAD não mudou. Mestre não mudou, é claro, mas new_branch mudou. Agora ele aponta para o novo commit.
Agora, isso se parece um pouco mais com nossa noção intuitiva de ramificações, mas lembre-se de que ramificações ainda são apenas referências a confirmações.
Mas repare que quando fizemos o comando git checkout new_branch:
Vemos que as alterações em nossa branch principal são transferidas para o novo ramo, pois quando removemos e renomeamos esses arquivos em nossa branch principal, eles permaneceram em nossa área de preparação. Ainda não confirmamos essas alterações e, como criamos uma nova ramificação fora do master nesse momento, as alterações na área de preparação permaneceram. Vamos confirmar esses arquivos através do novo ramo:
E executando o status Git vemos que agora não temos nada a confirmar, mas ainda temos o arquivo não rastreado. Se executarmos o comando “git ls-files”, veremos que ou alterações neste ramo estão presentes. No entanto, se retornarmos ao nosso ramo mestre digitando git checkout master, ocorreremos um erro:
Isso ocorre pois confirmamos a exclusão do arquivo receita_cafe.txt do controle de versão com um ramo, antes de incluir-lo na área de preparação no ramo principal. Como ele ainda está em um estado não rastreado, nós não o removemos ou excluímos do nosso sistema de arquivos. Quando tentamos fazer o checkout para obter um ramo diferente, estamos dizendo que precisamos fazer algo com esse arquivo, ou seja, removê-lo ou adicioná-lo novamente para ser rastreado.
GIT STASH
Existe apenas um comando que afeta o stash que é o git stash. Os demais comandos do Git têm algum tipo de efeito na área de trabalho, no índice e no repositório, mas nenhum deles afeta o stash. Os dados no stash não mudam, a menos que você realmente queira. É todo seu, ainda mais do que a área de trabalho.
Agora, vamos criar a nova receita no arquivo guacamole.txt. Devemos adicioná-la ao arquivo de menu. Assim agora temos um menu atualizado na área de trabalho e o novo arquivo na área de trabalho e no índice.
Agora, imagine que enquanto estou trabalhando nesta nova receita, sou interrompido por qualquer motivo. Posso guardar todas as minhas alterações no stash e elas permanecerão lá com segurança até que eu decida voltar à receita de guacamole com os comandos: Comando Descrição git stash Defina o trabalho atual em andamento como stash, para que você possa executar um check-out do git. A opção --include-untracked esconde também arquivos não rastreados git stash save
O Git pega todos os dados da área de trabalho e o índice que não está no commit atual no repositório e prepara todos esses dados no stash. E então, também verifica o commit atual.
Então, agora estamos alinhados com o commit atual. Estamos no estado limpo novamente. Nossos arquivos foram retirados da área de trabalho e do índice e estão no esconderijo. Você pode ter quantos elementos quiser. Cada elemento é rotulado com informações sobre a confirmação mais recente para facilitar a identificação e também obtém um ID de série. No momento, só há um elemento, por isso é chamado stash@ 0. O próximo seria stash@ 1. Agora que minhas coisas estão escondidas, eu poderia mudar para o outro ramo e fazer coisas nele, criar novas confirmações, qualquer coisa.
Comando Descrição git stash list Lista de trabalhos em andamento que você escondeu git stash show Para ter uma visão melhor detalhada de qual arquivo foi escondido em uma visão geral git stash pop Aplique o stash salvo mais recentemente no diretório de trabalho atual, remova-o do stash. git stash apply && git stash drop git stash apply Aplique o stash salvo mais recentemente ou o identificado (git stash apply stash@{1}) no diretório de trabalho atual, o deixa na lista de stash para possível reutilização posterior. git stash drop remova o stash mais recentemente ou o identificado (git stash drop stash@{1}) git stash clear remova todos os stash
Se digitarmos git stash list, Git nos fornecerá uma lista de alterações em andamento que armazenamos junto com a ramificação e alguns dados de confirmação.
Também podemos digitar git stash show para ter uma visão melhor detalhada de qual arquivo foi escondido em uma visão geral de alto nível das alterações.
E depois de fazer todo esse trabalho, posso recuperar as coisas que escondi. Você usa o stash apply para mover dados do stash para a área de trabalho ou no índice. git stash apply stash@{1}
E você pode definir o nome de um elemento stash, caso contrário, ele aplica ao elemento mais recente por padrão, que é stash @ 0. Repare que o comando apply não remove o stash da list de stashes. Isso pode levar a alguns conflitos que poderão ser resolvidos aplicando manualmente a remoção com o comando: git stash drop stash@{1}
Para limpar todos os stashes de uma vez só digite:
git stash clear
GIT MERGE
Em sistemas antigos com CVS, um branch é mais ou menos como duplicar o diretório inteiro do projeto e o merge é fazer diff no diretório duplicado gerar os patch de cada arquivo e aplicar de volta no diretório original. O CVS e o Subverssion antes da versão 1.5 não tinha essa informação do estado inicial do branch depois que você fazia o merge. Então não era possível mais continuar trabalhando no branch porque o próximo merge vai ter muitos mais conflitos. Esse tipo de merge é o que se chama de “Two Way”.
Two-Way Merge
Suponha que estamos modificando o mesmo arquivo simultaneamente. Você faz algumas alterações no arquivo e depois faço mais algumas alterações. Em algum momento, uma "terceira pessoa" olha para as duas cópias do arquivo.
Essa "terceira pessoa" vê que há uma diferença na linha 30, mas como ele não sabe qual versão está incorreta e terá que ligar para os dois programadores e confiar em suas memórias para descobrir quem modificou o quê. É provável que essa "terceira pessoa" seja o sistema de controle de versão que tenta fazer uma mesclagem bidirecional simples, que apenas compara duas versões de um arquivo e tenta mesclá-las. Mas aqui, o VCS exigirá intervenção do usuário porque não será capaz de descobrir o que fazer.
É melhor evitar modificações simultâneas em um arquivo se você precisar confiar na mesclagem bidirecional, pois será um processo manual lento. Imagine 300 arquivos que requerem uma mesclagem simples .
Three-Way Merge
Vamos esquecer por um segundo sobre o controle de versão e voltar para essa "terceira pessoa", examinando os dois arquivos que modificamos: Para ela descobrir quem editou o arquivo, ela pode olhar para a versão original do arquivo que usamos como ponto de partida.
Então, olhando como o arquivo era originalmente ("ancestral comum de base" ou simplesmente "base"), ele pode descobrir o que fazer. Com base na Figura 2, apenas um desenvolvedor realmente alterou a linha 30, para que o conflito possa ser resolvido manualmente agora basta ligar para "Yours" pra resolver se essa alteração é válida e commitar ou inválida e desfazer.
É assim que o Three-Way Merge ajuda: Transforma um conflito manual em uma resolução automática. Parte da mágica aqui depende do VCS localizar a versão original do arquivo. Esta versão original é mais conhecida como "o ancestral comum mais próximo". O VCS passa o ancestral comum e os dois contribuidores para a ferramenta de mesclagem de três vias que usará os três para calcular o resultado.
Usando apenas a fusão bidirecional, as linhas modificadas por dois desenvolvedores exigirão intervenção manual, enquanto todo o resto será mesclado automaticamente. Com a mesclagem tripla, é possível executar uma mesclagem indolor envolvendo centenas de arquivos. Vamos agora verificar um caso um pouco mais complexo, como mostra a Figura abaixo.
Comparando os dois arquivos lado a lado, podemos ver que há três linhas com diferenças:
- Linha 30: com o mesmo conflito que tivemos antes.
- Linha 51: com um loop for sendo modificado.
- Linha 70: onde não sabemos se o "seu" removeu algum código ou o "meu" o adicionou.
Vamos agora olhar para o ancestral comum para poder resolver adequadamente os conflitos.
- O conflito na linha 30 pode ser resolvido automaticamente e o "Yours" (colaborador de origem)
- O conflito na linha 70 também pode ser resolvido automaticamente para "Mine" (colaborador de destino)
- O conflito na linha 51 precisa de resolução manual: você precisa decidir se deseja manter um dos contribuidores, o outro, ou mesmo modificá-lo manualmente.
O Git não prioriza a estrutura de diretórios, mas um grafo, um DAG (Direct Acyclic Graf). O DAG é um grafo de commits. É isso que o comando git commit sempre faz, cria um commit ligado ao anterior. É denominado Acíclico porque os nós desse grafo não apontam de volta um para o outro causando um loop infinito.
Um branch é nada mais nada menos que um desvio nesse gráfico com uma etiqueta com o nome do branch. A vantagem no Git é que todo branch tem a informação do ponto de origem a partir de qual branch começa o branch.
Mesclar branch no mestre
Mesclar uma ramificação em outra ramificação é um conceito-chave com ramificação e realmente o objetivo de criar uma ramificação. Comando Descrição git merge branch2 mesclar branch2 no ramo atual em que você está git mergetool abre uma ferramenta para ajudar a executar uma mesclagem entre dois ramos conflitantes git merge –abort abandona uma mesclagem entre dois ramos conflitantes git merge-base branch1 branch2 mostra a confirmação básica entre branch1 e branch2 git merge –no-ff branch mesclar branch na ramificação atual, criando um commit de mesclagem, mesmo que seja um commit de avanço rápido
Primeiro, vamos voltar para a ramificação principal com o comando checkout. Se olharmos a receita apple_pie.txt, encontraremos a versão de receita do master, não a versão de new_branch.
Agora, digamos que gosto mais da versão de new_branch. Então, eu quero mesclar as alterações de new_branch no ramo mestre com o comando git merge new_branch e temos um conflito. git merge new_branch
O comando mesclar cria alguns arquivos no diretório .git aqui que sinalizam que há uma operação de mesclagem em andamento. E eles também contêm informações sobre o que está sendo mesclado entre outras coisas.
Por exemplo, o arquivo MERGE_HEAD é uma referência como HEAD, apenas MERGE_HEAD é uma referência temporária. Ele dura apenas o tempo necessário para concluir a mesclagem.
E está apontando para a ponta do ramo que estamos fundindo.
Precisamos resolver o conflito manualmente, se olharmos para dentro do arquivo da torta de maçã, veremos que esta linha foi alterada de maneira divergente em nossa receita e na receita de new_branch, então agora precisamos nos posicionar e decidir quantas maçãs usar na torta.
Agora, se obtivermos status, veremos que esse arquivo não está preparado para a próxima confirmação, precisamos adicioná-lo explicitamente. Esta é a nossa maneira de dizer ao Git que o conflito foi corrigido.
E agora podemos concluir a mesclagem. Se não tivéssemos conflitos, o Git teria feito esse último passo automaticamente, mas, como tivemos conflitos, temos que dizer, ok, terminamos de corrigir todos os conflitos no Git e fazemos isso com uma confirmação. Nem precisamos enviar uma mensagem de confirmação. O Git sabe que estamos no meio de uma mesclagem, por isso criará uma mensagem adequada automaticamente.
Poderíamos mudar a mensagem, mas não vou, apenas a aprovarei saindo do editor. Se você olhar para o log agora, verá um novo commit e, se olhar dentro desse commit com o comando de cat-file:
É como qualquer outro commit que vimos até agora. Uma mesclagem é apenas um commit que tem dois pais, é isso que a torna mesclada. Um commit no Git geralmente tem um pai, mas pode ter quantos pais você quiser, na verdade. A seguir temos um resumo das operações realizadas no ramo “new_branch” e posteriormente no ramo principal que terminou com o checkout master e criação de um novo arquivo chamado merge_file.
Se não houvesse conflitos e desejássemos mesclar alterações no ramo principal bastaria digitar: git merge new_branch
Podemos ver que as alterações do new_branch foram agora adicionadas ao nosso ramo principal.
Mesclar mestre no branch - Fast Forward
Vimos como as ramificações e mesclagens funcionam, mas há alguns casos interessantes que não consideramos. O primeiro é um caso especial de mesclagem. Vamos iniciar dando um checkout no ramo new_branch. Agora 0 HEAD está em new_branch novamente.
Anteriormente, fundimos new_branch no mestre. Agora queremos mesclar o mestre no new_branch. Isso poderia ser feito da maneira usual, exatamente como fizemos quando nos fundimos na outra direção. Ele pode criar um novo commit que tem dois pais, esses dois commit aqui seriam os pais e depois mover new_branch para apontar para o novo commit. Esse novo commit seria garantido por não ter conflitos, porque já os resolvemos quando nos fundimos na outra direção. Portanto, seria fácil para o Git criar esse commit, mas também seria um desperdício.
Aprendemos até agora que o Git não gosta de desperdício. Portanto, você pode poupar um commit e apenas fazer isso. Move Lisa para apontar para o mesmo commit que Master. Portanto, o Git não precisou criar um novo commit. Esse truque acontece o tempo todo na prática. É chamado de avanço rápido (Fast Forward) .
Sempre que você vê essa mensagem na tela, é o Git se gabando de poder poupar alguns objetos no banco de dados de objetos e tornar o histórico do seu projeto menos complicado. Bom Git.
HEAD desanexada (Detached HEAD)
O segundo caso é um recurso que se mostra bastante útil na prática. Vou começar dando um checkout no mestre e esquecer o ramo new_branch por um tempo.
Até agora, eu sempre lhe disse que HEAD é uma referência a um ramo, que por sua vez é uma referência a um commit. Quando você faz check-out de uma ramificação, isso significa que você está alterando HEAD. No entanto, você também pode fazer algo diferente. Você pode fazer checkout diretamente um commit em vez de um branch. Vou fazer checkout este commit utilizando o SHA 1 do commit.
Agora, se você olhar dentro do HEAD, ele não está apontando para uma ramificação, está apontando diretamente para uma confirmação e, de fato, não há nenhuma ramificação atual. Essa é uma situação chamada HEAD desanexada.
Agora, vamos fazer algumas alterações na receita de torta de maçã, algo que não tenho certeza se quero manter. Reduzimmos o número de maçãs e confirmamos. Depois altermos novamente a receita agora fazer a torta sem açúcar e outro commit.
Como não há ramificação atual, ele rastreará a confirmação mais recente movendo HEAD diretamente. HEAD está funcionando exatamente como um ramo aqui.
Ao abandonar o experimento e fazer checkout no mestre novamente, o HEAD volta ao seu lugar no ramo principal. O mesmo acontece com nossos arquivos. Mas o que acontece com esses commits?
Bem, eles ainda estão no banco de dados de objetos em algum lugar junto com todas as suas árvores e blobs, mas, a menos que eu tenha anotado seus SHA-1s, esses commits e seus objetos conectados agora estão inacessíveis. Eles não podem ser alcançados iniciando-se por uma ramificação ou tag e caminhando pelos objetos no banco de dados. Só posso alcançá-los diretamente pelos seus SHA-1s e sou obrigado a esquecê-los em breve.
De vez em quando, no decorrer de outras operações, o Git decide que vale a pena executar uma coleta de lixo. O coletor de lixo procurará objetos no banco de dados que não possam ser alcançados por meio de uma ramificação, HEAD ou marca e os removerá para economizar espaço em disco. Lembre-se, cada objeto é apenas um arquivo no banco de dados, portanto, removê-los é tão fácil quanto excluir esses arquivos. Portanto, esses commits que eu criei provavelmente permanecerão no banco de dados por algum tempo e desaparecerão.
Se eu quiser salvá-los, uma coisa que posso fazer é voltar para os commits perdidos. Ainda posso fazer isso porque tenho seus SHA-1s aqui e o coletor de lixo ainda não foi executado. Primeiro, podemos fazer o checkout do commit utilizando o SHA-1 e mover o HEAD até o commit. E agora que estamos no commit, podemos colocar um banch nele, poe exemplo, um chamado nogood. Por fim, podemos fazer o checkout do mestre novamente, e desta vez os commits estão seguros.
Agora existe uma ramificação que atua como ponto de entrada para esta seção do gráfico de objetos, portanto esses objetos nunca serão coletados como lixo. E eu posso facilmente voltar a eles através do ramo criado nogood. Essa é uma maneira comum de usar um HEAD desanexado. Você pode desanexar HEAD, fazer seu experimento, ainda confirmar o experimento o quanto quiser e, para não perder dados, lembre-se de colocar um ramo no que você gosta antes de deixá-lo para trás.
Agora temos uma imagem melhor da natureza do Git, vamos recapitular. Um repositório Git é um monte de objetos vinculados entre si em um gráfico. Como você sabe, eles podem ser confirmações, blobs, árvores ou tags. Depois, existem ramificações que são referências a uma confirmação. E, finalmente, há HEAD. Isso também é uma referência, mas existe apenas uma e marca nossa posição atual no gráfico. Geralmente está apontando para um ramo, mas também pode ser desanexado e apontando diretamente para um commit.
Existem algumas regras.
- A ramificação atual controla novas confirmações. Portanto, se você criar um novo commit dizendo, git commit ou git merge, por exemplo, o ramo atual será movido para o novo commit. Se você estiver no estado HEAD desanexado, o próprio HEAD será movido para o novo commit.
- Seu diretório de trabalho é atualizado automaticamente. Quando você muda para uma confirmação, por exemplo, com git checkout, o Git substitui o conteúdo do seu diretório de trabalho pelo conteúdo que pode ser alcançado a partir dessa confirmação.
- Qualquer confirmação, blob ou árvore que não possa ser alcançada a partir de um ramo, HEAD ou uma marca, é considerada morta e pode ser coletada como lixo.
GIT REBASE
Suponhamos que existem dois ramos, o ramo principal e o ramo new_branch recebeu 2 novos commits cada um como abaixo:
Temos dois ramos que divergiram mas queremos juntar o conteúdo dos dois ramos. Poderímos mesclar os dois ramos onde teríamos um novo commit e os pais desse novo commit seriam as os doid commits anteriores dos dois ramos. Além disso, o ramo atual passaria para esse novo commit mesclado.
Em vez disso, usarei outra maneira de juntar os dois ramos. Vou refazer a ramificação atual sobre a outra ramificação. Se refazermos o new_branch no mestre, eis o que acontece. O Git procura o primeiro commit no new_branch, que também é um commit no master. O commit que é a base do ramo de new_branch.
Todo o histórico antes desse commit já é compartilhado entre os dois ramos. Agora, o Git desanexa todo o ramo de new_branch desse commit e o move sobre o master para que ele mude a base desse ramo. É por isso que é chamado de rebase. Como em uma mesclagem, talvez tenhamos que resolver conflitos para concluir a reformulação, mas nesse caso, não há conflitos. As duas ramificações alteram arquivos diferentes, então já terminamos. Agora, o ramo de new_branch contém todos os commits do ramo mestre mais o material de new_branch, que é o que queríamos.
Quando você faz rebase, o Git desanexa o ramo atual de sua base e o move para o topo do ramo de destino. O Git faz cópias das confirmações. Ele cria novos commit com os mesmos dados, na verdade exatamente os mesmos dados, exceto para os pais. Portanto, essas novas confirmações se parecem quase exatamente com as confirmações originais, mas são novos objetos com novos SHA-1s. Portanto, eles são novos arquivos com novos nomes no diretório do banco de dados.
E, finalmente, o Git move o ramo rebased para os novos commits, deixando os antigos commits para trás. Algumas vezes as rebase podem ser complicadas e você pode evitar confusão se lembrar que rebasear é uma operação que cria novas confirmações.
O que acontece se queremos que funcione da outra maneira e queremos que as coisas sejam new_branch no ramo principal. Assim como em uma mesclagem, podemos fazer o checkout do mestre e refazer o caminho para o outro lado.
E agora vamos nos refazer. Na verdade, nesse caso em particular, eu poderia me refazer ou mesclar e isso não faria diferença alguma. Nos dois casos, o Git pode fazer o fast foward da ramificação. Uma rebase pode ser fast foward como uma mesclagem.
Então é isso que temos agora. Assim como em uma mesclagem, temos todos os commits que lidam com o new_branch e todos os commits que lidam com a torta na mesma história. No entanto, diferente de uma mesclagem, obtivemos esse resultado não permitindo que vários ramos fiquem em paralelo, mas reorganizando os ramos para que pareçam um único ramo.
Revendo Rebase
Existem alguns casos em que os rebasing não funcionam muito bem. Digamos que este repositório tenha sido clonado recentemente com dois ramos que estão rastreando ramos na origem. Estamos trabalhando no ramo lisa e decidimos fazer as alterações do mestre para o lisa. Você sabe que podemos fazer isso com uma mesclagem ou rebase. Então, vamos tentar a rebase desta vez. O Git copia o commit de lisa para que seu pai agora seja o último commit do master. No entanto, lembre-se de que esse novo commit amarelo (com um ponto de exclamação) que temos aqui não é o mesmo que o commit amarelo anterior. Em vez disso, é uma cópia, um objeto de banco de dados diferente.
O commit original será coletado em algum momento. Então agora temos um conflito novamente. Não podemos simplesmente fazer push porque temos histórias diferentes em nosso repositório local e na origem. Esse conflito em particular, podemos corrigi-lo facilmente com um force push ou um pull, seguido de um push. E então temos as mesmas coisas de origem que temos no local.
No entanto, outro colaborador, Annie, também está trabalhando no mesmo repositório e ainda tem o commit amarelo original sem marca de exclamação em nosso repositório. Não só isso, ela também continuou trabalhando no ramo lisa. Ela adicionou um commit lá. Então agora Annie tem um conflito bastante desagradável para resolver da próxima vez que sincronizar com a origem.
Ela precisa entender o que aconteceu primeiro e depois resolver os conflitos, mesmo que não os tenha causado. Há boas chances de que, mesmo depois de resolver os conflitos, ela tenha um histórico confuso que inclua os dois commits em amarelo, mesmo que pareçam exatamente iguais. Portanto, este é o ponto principal quando se trata de rebasear: como regra geral, nunca rebase coisas que foram compartilhadas com algum outro repositório. Não há problema em fazer rebase nas confirmações que você ainda não compartilhou, em seu repositório local. Mas lembre-se de que é fácil fazer rebase em confirmações compartilhadas por engano e ocorrer problemas.
Os Trade-offs do Merges e Rebases
Agora, sabemos como é uma rebase e como ela realmente funciona. No entanto, a rebasing e a merging parecem fazer algo muito semelhante. Ambos registram confirmações existentes no histórico de um branch, ma ambos têm diferentes vantagens e desvantagens. O ponto principal do merge é que preserva a história exatamente como aconteceu. Por exemplo, você pode ver claramente que as confirmações sendo criadas independentemente, possivelmente em paralelo, e depois foram mescladas em uma única linha do tempo. Se houver algum conflito durante a mesclagem, essa consolidação incluirá correções nos conflitos.
Mas o merge se torna um pouco menos simples quando você está olhando para um grande projeto em que é muito usado. Por exemplo, neste projeto Git para uma popular biblioteca de código aberto no Ruby abaixo.
Estou usando uma ferramenta chamada Source Tree para visualizar o histórico do Git. Como você pode ver, há muitas ramificações e merges acontecendo, portanto pode ser muito difícil seguir o caminho em que todos esses ramos divergiram e depois convergiram novamente. Comparando esta ferramenta gráfica com o comando git log, em um projeto como este, o log do git pode ser enganoso, pois mostra o histórico como se fosse uma única linha do tempo, uma sequência de confirmação após a outra, mas não é assim que o histórico do projeto realmente se parece. O log está esmagando a história real de alguma forma, intercalando commits não relacionados de diferentes ramos, como se estivessem conectados um ao outro enquanto não estão. Portanto, os merges preservam o histórico do projeto e, em geral, isso é bom, exceto que o histórico do projeto pode ser feio e confuso. Mas uma coisa é certa: a merge nunca mente.
No rebasing as confirmações já estão organizadas em uma única linha do tempo. Portanto, um projeto que utiliza muitas reformulações geralmente parece mais otimizado e limpo do que um projeto que utiliza muitas mesclagens no histórico. No entanto, essa história bem projetada não é real. Foi forjada por um rebasing, que é uma operação destrutiva. Pode dar a falsa impressão de que os commits foram criados primeiro em relação a outros commits. Mas na realidade foram criados em paralelo em diferentes ramos. Existem alguns comandos git avançados, por exemplo, que se tornam menos úteis se você violar o histórico do projeto. Em caso de dúvida, basta mesclar. rebasing é bastante útil, mas você só deve usá-lo só no seu repositório local onde dá para controlar o que está fazendo e entender as consequências.
Os Trade-offs do Pull
Usar git pull ou git pull --rebase ao mesclar com mudanças remotas é uma questão parecida com a de se devemos usar git merge ou git rebase para mesclagens locais. O comando git pull, não passa de um git fetch seguido de um git merge. Por isso, temos as mesmas vantagens e desvantagens do merge, mas agora considerando repositórios remotos. Como vantagem, temos um registro fiel do que aconteceu em cada repositório da nossa equipe, com os commits exatos. Mas, como desvantagem, os vários commits de merge complicam o entendimento do histórico do projeto, afetando tarefas como navegar por código antigo e revisar código novo. Em times grandes, um histórico complicado pode tornar o trabalho bastante desafiador.
Já o comando git pull --rebase é um git fetch seguido de um git rebase. O histórico é linearizado, simplificando nosso trabalho. Porém, a cada rebase alguns commits são reescritos e, nofimdas contas, estamos perdendo informações sobre nosso repositório. Quando acontecem conflitos, corrigi-los pode ser bastante complicado.
O rebase pode ser especialmente problemático se acabarmos mudando um commit já compartilhado com outros membros da nossa equipe. Nossos colegas podem sofrer na hora de obter os commits modificados, já que o Git pode se perder. Não parece uma boa solução usar sempre o merge ou sempre o rebase. Um meio termo parece algo mais sensato:
- Utilizar um git pull --rebase para obter mudanças remotas. É uma prática segura porque nossos novos commits locais ainda não foramcompartilhados, ou seja, outrosmembros nemsabem da existência desses commits. Por isso, alterá-los não traz grandes problemas.
- Ao trabalharmos emuma nova funcionalidade utilizando uma branch, marcamos sua entrega fazendo um merge. Assim, conseguimos ter uma boa ideia de quando a funcionalidade começou a ser desenvolvida e quando foi reintegrada à branch master.
- Se estivermos trabalhando sozinhos na nova funcionalidade, podemos fazer rebases periódicos da master na nossa branch para obter código novo, porém deixando o histórico da branch bem limpo.
- É interessante fazer o push da nossa branch solitária emumrepositório remoto, para backup. Mas é importante evitar que alguém faça checkout.
CLONAR DA ORIGEM REMOTA
Comando Descrição git clone http: /// Clone seu repositório do github git clone source destination_dir Clona o repositório Git na origem para o destination_dir git clone –bare source destination_dir "message" SHA1id Clona o diretório bare do diretório de origem no destination_dir
A próxima coisa que precisamos fazer é baixar essas alterações nos outros computadores para que ele possa trabalhar nesse projeto usando seus computadores pessoais e de trabalho. Se navegarmos para a guia repositórios no GitHub clicarmos no projeto wired-brain-recipes, veremos uma lista de arquivos e conteúdo dentro do projeto. Para clonar esses repositórios em outro computador, você pode clicar no botão clone verde localizado no canto superior direito da página.
Podemos copiar esse https vinculado clicando n o ícone da área de transferência ao lado da Web URL https://github.com/wired-brain-coffee/wired-brain-recipes.git
Com essa URL, podemos clonar o projeto simplesmente navegando para o diretório que iremos armazenar o projeto e, em seguida, cloná-lo nesse diretório. Vamos cloná-lo então para nossa pasta de Downloads, digite: git clone https://github.com/shyoutarou/wired-brain-recipes.git
Ao navegarmos para este novo diretório vamos e digitar git status para ver se estamos atualizados com o origin master e, em seguida, digitar o comando “git ls-files” nos mostra a lista completa de arquivos em nosso projeto que foi retirado do origin master. Ele não copia literalmente todos os arquivos. Por exemplo, nas versões recentes do Git, o git clone copia apenas uma ramificação, a ramificação principal. Se eu quiser trabalhar com as outras ramificações no repositório remoto, preciso fornecer comandos específicos para isso.
O Git não é como o Subversion ou outros sistemas tradicionais de controle de revisão que precisam de um servidor centralizado e todo mundo está apenas conversando com esse servidor. Em vez disso, agora os dois computadores contêm todo o projeto e seu histórico. Poderíamos ter quantos desses clones quisermos sincronizando uns com os outros. Obviamente, você ainda pode decidir que um clone específico é o mais importante. Por exemplo, se você tiver vários desenvolvedores trabalhando no mesmo projeto de software, provavelmente decidirá que o repositório no GitHub é o repositório de referência, o qual você constrói os lançamentos e todos devem sincronizar com esse. Por isso, desenhei o repositório GitHub no topo. Ainda é possível sincronizar os repositórios de desenvolvedores diretamente entre si, mas mesmo assim você provavelmente deseja nomear uma cópia de referência conhecida com a qual todos sincronizam. No entanto, no Git, isso não é um problema técnico. Agora, podemos seguir as mesmas etapas para clonar seu projeto em outros computadores.
Local and Remote
Agora, temos o mesmo projeto em dois repositórios separados. Quando emitimos o comando git clone, o Git adicionou algumas linhas à configuração do nosso repositório. Cada repositório Git pode lembrar informações sobre outras cópias do mesmo repositório. Cada outra cópia é chamada de controle remoto. Você pode definir quantos controles remotos quiser, mas quando você clona o projeto, o Git define imediatamente um controle remoto padrão e o chama com um nome convencional: origin. Aqui está a configuração de origem e aponta para a URL da qual clonamos o projeto. Apenas saiba que a configuração padrão diz que temos uma ramificação principal que mapeia a ramificação principal do controle remoto. type .git\config
Então agora o Git se lembra de quais outros repositórios ou repositórios queremos sincronizar. Mas, para sincronizar, o Git também precisa saber o estado atual de origem, quais ramificações existem no controle remoto, que confirma essas ramificações atualmente apontadas, e assim por diante. E, de fato, o Git armazena essas informações. Se solicitarmos branches, ele mostrará apenas as branches locais. Agora só temos mestre. Mas se você listar as ramificações com a opção –all, verá todas as referências, incluindo as do controle remoto, as ramificações remotas e a posição atual da cabeça. git branch --all
O Git rastreia ramificações remotas exatamente como rastreia ramificações locais, escrevendo essas ramificações como referências na pasta refs. Se você olhar dentro dessa pasta, verá uma pasta de origem aqui que contém as referências a ramificações, tags e o ponteiro de origem atual.
O Git atualizará automaticamente essas informações quando nos conectarmos a um controle remoto. Há uma ruga aqui. Se você olhar dentro desta pasta, poderá achar que alguns dos ramos estão ausentes. Nesse caso, só consigo ver os controles remotos HEAD aqui, não os ramos. Isso é devido a uma otimização de baixo nível no Git. Para evitar manter um arquivo pequeno para cada ramificação, o Git às vezes compacta alguns deles em um único arquivo chamado packed-refs.
Não há um comando simples para descompactar esses arquivos; portanto, você terá que acreditar que os ramos que não estão no diretório refs devem estar nesse arquivo. Isso pode acontecer para ramificações locais e remotas, mas em ambos os casos, se as ramificações ainda são arquivos individuais ou empacotadas em pacotes-refs, elas ainda são conceitualmente a mesma coisa. Todas as ramificações, locais ou remotas, ainda são referências a uma confirmação e o Git rastreia todas elas. Como não podemos espiar dentro dos arquivos algumas dessas ramificações porque elas foram compactadas, vamos usar este comando de canalização, git show-ref, para ver quais confirmações estão apontando. git show-ref master
O git show-ref master lista todos os ramos que possuem mestre em seus nomes, o que significa o ramo mestre local e o ramo mestre remoto. E, como você pode ver, eles estão apontando para o mesmo commit. Portanto, você sabe que a ramificação local no Git é apenas uma referência a uma confirmação. Bem, um ramo remoto é exatamente a mesma coisa. Sempre que você sincroniza com um controle remoto, o Git atualiza ramificações remotas.
Então, vamos sincronizar, enviando os novos objetos e a ramificação atualizada para a origem com o comando git push.
Aqui estamos, agora nossos novos objetos foram transferidos para o controle remoto e as ramificações na origem foram movidas para apontar para o último commit. Podemos verificar isso facilmente porque o Git atualizou nossas ramificações remotas para se alinhar ao estado de origem atual.
É possível clonar através de um outro diretório local na mesma máquina o que é útil para fazer teste ou simplesmente treinar comandos do Git: git clone .\cafes_recipes.git teste2
Se dermos um git log o origin/master significa o outro diretório local de qual clonamos o projeto:
git log --oneline --graph
E se fizermos um:
git push origin master
As alterações e arquivo foram para esse repositório “remoto” que está local/privado:
E se voltarmos ao nosso repositório clonado estará clonado com o origin/master:
Se preferir que terceiros não tem acesso ao seu código fonte e dos clientes é possível montar uma instalação privada de GitLab.
Pulling
Agora não podemos apenas escrever alterações no controle remoto, também devemos ler as alterações no controle remoto. Imagine que temos um repositório remoto com um único commit. Quando clonamos esse repositório, obtemos os mesmos objetos em nosso cliente local, e aqui estão os ramos (em vermelho).
Agora, digamos que adicionamos um commit (em roxo) e fazemos push. Se não houver alterações na ramificação principal do controle remoto, as coisas serão fáceis. O Git copia nossa nova confirmação e os objetos associados para o controle remoto e atualiza a ramificação mestre do controle remoto para apontar para a nova confirmação, e também reflete a alteração nas ramificações na origem, atualizando a ramificação mestre de origem no repositório local.
Agora imagine que tenhamos adicionado uma confirmação e nos preparamos para enviar, mas desta vez outra pessoa tenha enviado antes e colocado outro commit no controle remoto. Agora não podemos simplesmente fazer o push, pois temos um conflito que precisam ser corrigido.
Nesse caso, basicamente temos duas opções. Uma opção, que eu não recomendaria, exceto em casos muito especiais, é forçar um push. Podemos fazer isso com a opção de linha de comando: git push –f
Isso significa que estamos forçando o controle remoto a pegar nossos novos objetos e alterar seu histórico para corresponder ao histórico local. Então, provavelmente estamos perdendo dados de origem. Aqui estamos perdendo o commit verde. Nenhum ramo está apontando mais para esse commit, portanto ele será coletado como lixo eventualmente. Também estamos criando uma situação muito confusa para todas as outras pessoas sincronizando com o mesmo controle remoto, porque agora o histórico local estará em conflito com o histórico de origem, portanto, provavelmente forçar um push não é uma boa ideia.
GIT FETCH
A outra opçãp é corrigir o conflito em nossa própria máquina antes de avançarmos. Para fazer isso, precisamos primeiro buscar os dados do controle remoto. Existe um comando para fazer isso chamado git fetch. git fetch
Obtemos os novos objetos do controle remoto e também atualizamos a posição atual das ramificações remotas, como de costume. Entenda que o git fetch busca as atualizações do repositório remoto e atualiza o repositório local. Ele não altera nada nas áreas Working ou Stage. Para aplicarmos as alterações nessas áreas utilizamos o Merge ou o REbase. Agora que temos o novo commit e os objetos relacionados, vamos mesclar nossas alterações locais com o histórico remoto. Então, fizemos a busca, agora fazemos uma mesclagem. git merge
É claro que, durante o merge, talvez tenhamos que corrigir conflitos de merge e similares, mas o ponto importante aqui é que não estamos reescrevendo a história. Mesclagens nunca fazem isso. Em vez disso, eles apenas adicionam novos objetos. Então, quando fazemos a mesclagem, nossa história é a história do controle remoto e mais algumas coisas, e podemos enviar essas coisas novas para o controle remoto sem reescrever o histórico do controle remoto.
É isso que você faz na maioria das vezes. Você obtém as alterações no controle remoto, as mescla em seu próprio repositório e pressiona o resultado. Essa sequência de git fetch, seguida de git merge, é tão comum que existe um único comando que faz as duas coisas chamado, git pull.
Se tentarmos fazer um push com um arquivo que foi alterado remotamente e alterado e confirmado localmente acontece um erro:
Observe que o Git recomenda dar um fetch antes, mas vamos dar um pull (fetch + merge).
Se não houver conflitos entre linhas o Git já realiza automaticamente o Merge entre o arquivos diferentes. Nós poderíamos agora fazer um push e enviar o merge ao repositório remoto, mas vamos resetar o commit e alterar a mesma linha nos dois arquivo para dar conflito.
Agora ocorreu um conflito e a mensagem mudou:
Ao invém de fazer o merge, que é o procedimento padrão do comando pull, e se abortarssemos o merge e tentássemos um pull com rebase: git pull –rebase
De novo ocorre problema de conflito, vamos resolve-lo e vermos como fica o pull com rebase em conflito. Vamos aceitar a alteração que está no remoto (Current Change).
start code README-JA.md
Dando sequência a resolução de conflito precisamos dar um add para confirmar a correção e um –continue para continuar a operação tanto do Merge quanto do Rebase.
git add README-JA.md git rebase --continue
Revert fetch
Vamos assumir que você tem sua origem remota e seu branch de desenvolvimento local é baseado no master, mas seu master local está atrás de origin/master (mas você não o vê ainda, porque você não buscou a origem ainda). Portanto, executar git fetch adicionará novos commits de origin/master e tags ao seu repositório local. Em alguns casos, você não deseja ver esses novos commits e eles reduzirão a legibilidade do seu histórico. Dito isso, você pode "desfazer" o git fetch fazendo: git update-ref refs/remotes/origin/master refs/remotes/origin/master@{1}
Tudo o que isso faz é mudar o ponteiro de origem/mestre para o estado anterior. Talvez você precise brincar com {n} um pouco para obter o estado exato, mas em geral isso pode ajudar. Para essa operação talvez é necessário utilizar reflogs remotos para encontrar branches de rastreamento remoto atualizados na busca mais recente — esta mesma informação também pode estar disponível no arquivo FETCH_HEAD. Só então use git update-ref para apontar essas referências de volta para suas entradas reflog anteriores. Mas isso ainda deixará os objetos buscados em seu repositório, então para realmente limpá-los, você deve também excluir as entradas intermediárias do reflog e, em seguida, executar o Garbage Colletor: git gc --prune = now
Isso que requer muito cuidado e descartará todos objetos não referenciados, não apenas aqueles trazidos pela busca mais recente. Por isso, pode-ser mais indicado tentar desfazer o fetch do remoto A simplesmente removendo este remoto: git remote remove A
Agora, basta adicioná-lo novamente e buscar apenas um único branch: git remote add A <caminho / para / repositório> git fetch A
No entanto, se o problema era que você precisava de um branch específico do repo A e preciso ir para uma pasta específica no repo B mas obteve todos os branches do repo A. Você pode excluir quaisquer branches que acidentalmente recuperou e que não deseja manter com o seguinte comando: git update-ref -d refs / remotes / YOUR_REMOTE_NAME / BRANCH_NAME_TO_DELETE
Para evitar que eles sejam buscados novamente, configure seu git remote para buscar apenas branches especificados: git remote set-branches YOUR_REMOTE_NAME needed_branch1 [desejado_branch2, desejado_branch3, etc], por exemplo: git remote set-branches origin master.
O comportamento padrão de set-branches é sempre substituir a lista. Se você quiser acrescentar, use a opção --add: git remote set-branches --add origin another_branch
É difícil ter uma necessidade de desfazer um git fetch, mas nunca há qualquer razão para precisar desfazer um git fetch. Porém, lembre-se, o que git fetch faz é chamar o remoto, obter uma lista de branch-name para mapeamentos SHA-1, trazer commits e outros objetos que você precisa para armazená-los em seu repositório e, em seguida, atualizar seus branches de rastreamento remoto de modo que eles apontem para as ramificação atuais do controle remoto. Isso não tem efeito em nenhum dos seus arquivos de árvore de trabalho, e se você executar git fetch novamente amanhã, qualquer trabalho feito hoje poderá ser ignorado amanhã. Se você conseguir desfazer a busca, o que for executado amanhã terá que refazer o trabalho feito hoje, então isso é uma perda líquida: você acabou de gastar algum esforço para que seu git tenha que trazer mais código pela rede amanhã.
Multiple Remotes (Forks e Pull Request)
Imagine que existe este projeto no GitHub com o qual queremos contribuir. Pertence a um usuário chamado Pluralsight. Poderíamos simplesmente clonar esse projeto, mas ele ficaria preso em nossa máquina local porque não temos acesso de gravação ao repositório do Pluralsight, portanto não podemos avançar nele. O que podemos fazer a partir da interface da web do GitHub é criar nossa própria cópia do projeto no GitHub. Isso é chamado de fork. Um fork é como um clone, mas é um clone remoto. Estamos clonando o projeto da conta do GitHub de outra pessoa para a nossa própria conta do GitHub.
Portanto, agora temos um novo projeto na nuvem e podemos cloná-lo em nossa máquina local. Quando fazemos isso, o Git cria um controle remoto em nosso repositório local apontando a origem. A origem está apontando para o nosso próprio projeto GitHub, não o projeto original. Na verdade, do ponto de vista do Git, não há nenhuma conexão entre o nosso projeto e o projeto original do qual partimos. O GitHub sabe que os dois projetos estão conectados, mas o Git não. Portanto, se quisermos acompanhar as alterações no projeto original, precisamos adicionar outro controle remoto apontando para ele.
Isso não é algo que o Git faz automaticamente. Nós temos que fazer isso sozinhos. Uma convenção comum é chamar esse remoto upstream. Agora temos nosso projeto local com vários controles remotos. Podemos trabalhar nisso e podemos sincronizar todas as nossas alterações locais com a origem. Se confirmarmos alterações locais, podemos simplesmente enviar essas alterações para a origem. Se houver mudanças no upstream, podemos atraí-las para o nosso projeto local, resolver qualquer conflito e enviá-las à origem. Uma coisa que ainda não podemos fazer, no entanto, é levar as mudanças a montante. Por exemplo, gostaríamos de contribuir com nosso commit laranja para o projeto original, mas ainda não temos acesso de gravação ao upstream, portanto o GitHub nos oferece uma alternativa. Podemos enviar uma mensagem aos mantenedores do upstream e pedir que eles façam nossas alterações.
É uma pull request. Mais uma vez, as solicitações pull não são um recurso do Git. Nem sequer são um recurso de controle de versão. De certa forma, eles são um recurso de rede social. Você está apenas enviando uma mensagem para as pessoas. Se essas pessoas gostam de suas alterações, o GitHub facilita a execução remota e a obtenção das alterações desde a origem. E isso é tudo sobre forks e solicitações pull, duas das ferramentas mais importantes no desenvolvimento moderno de código aberto.
PULL REQUEST
A primeira etapa para criar uma solicitação Pull-Request de um repositório do GitHub é criar um Fork do repositório. Caso já esteja logado em sua conta no GitHub é só cliclar no botão mostrado abaixo no repositório a ser forkado:
O número 1 mostrado no fork significa que eu já havia forkado este projeto. Aparecerá uma tela como abaixo:
Repare que abaixo do nome do projeto há uma indicaçl~´ao que de se trata de um projeto forkado:
Depois precisamos clonar o projeto na máquina com o: git clone https://github.com/seuusuariogit/projeto.git
Verifique no README do projeto se é necessário a instalação de dependências para execução do projeto. Se não houver execute e veja se o projeto está funcionando conforme a descrição de funcionamento.
Se tudo estiver OK, crie uma branch. Sempre que você trabalha em um projeto colaborativo, você e outros programadores que contribuem para o repositório terão ideias diferentes para novos recursos ou correções de uma só vez. Alguns desses novos recursos não levarão tempo significativo para serem implementados, mas alguns deles estarão em andamento. Por isso, é importante ramificar o repositório para que você possa gerenciar o fluxo de trabalho, isolar seu código e controlar quais recursos serão retornados à branch principal do repositório do projeto.
A branch principal padrão de um repositório de projeto é geralmente chamada de master branch. Uma prática comum recomendada é considerar qualquer coisa na branch master como sendo passível de se fazer o deploy para outras pessoas usarem a qualquer momento. Ao criar uma nova branch, é muito importante que você a crie fora da branch master. Você também deve se certificar de que o nome da sua branch é descritivo. Em vez de chamá-la de minha-branch, você deve usar frontend-hook-migration ou Corrigir erros de digitação na documentação. git branch nova-branch git checkout nova-branch
Depois disso, você pode começar a alterar o projeto para incluir as correções. Quando tudo estiver OK, o procedimento padrão de publicar no Git (git add, commit e push). Repare que ao fazer o: git push origin master
Não precisamos fazer a definição de onde que é a origin pois o Git já definide automaticamente no git clone. Se não estiver logado em sua conta, ao fazer o push é necessário fornecer suas credenciais. Ao entrar na nossa conta o Git avisa se quer fazer um Pull Request:
Se não tiver criado um branch, ele compara o seu repositório com o repositório original para ver se não há conflitos e se é possível fazer o merge.
Na próxima tela, é possível inserir uma mensagem ou imagens para justificar o seu Pul Request:
No repositório original fica pendente o pull-request para analise:
GIT LFS E ARQUIVOS BINÁRIOS
Uma dica importante que muitos iniciantes fazem errado. Digamos que você é um desenvolvedor front-end que você receba novas versões de arquivos de Photoshop dos designers. Uma hora vocês perdem noção de qual era a versão mais nova. E ninguém chega num consenso de qual era a versão do design certo.
Ferramentas como diff, patch e o próprio Git tem algoritmos muito bons pra lidar com hunks e patches de texto. Porém, photoshop é um arquivo binário. Não existe nenhuma forma eficiente de se fazer patches de arquivos binários. Se você tentar mergear binários sem saber a estrutura interna delas, a chance de dar problemas é praticamente garantida. Portanto o Git não faz deltas de binários, ele grava o arquivo inteiro pra cada modificação. Digamos que o photoshop original tinha 200 Mb. Em cada commit vai os 200Mb inteiro de cada versão, porque não tem como tirar delta de binário. Ao final de 5 dias seu repositório tem 1 Gb. Agora todo novo desenvolvedor que fizer um git clone vai ter que puxar 1 Gb. E normalmente você só precisaria do último photoshop do designer não de todo histórico de arquivos.
Se for arquivos pequenos como jpgs ou pngs tudo bem, mas para armazenar grandes binários, como photoshops, videos, audio, instaladores precisa ser tratado diferente.
Git LFS (Large File Storage)
O Git LFS (Large File Storage) é uma extensão do Git desenvolvida pela Atlassian, GitHub e alguns outros colaboradores de código aberto, que reduzem o impacto de arquivos grandes no seu repositório fazendo o download das versões relevantes preguiçosamente. Especificamente, os arquivos grandes são baixados durante o processo de checkout, e não durante a clonagem ou busca.
No PowerShell, depois de instalar o gerenciador de pacotes Scoop, instale a ferramente Git LFS com o comando: scopp install git-lfs.
Pronto, agora no diretório do projeto você inicializa com git lfs install.
Finalmente você tem que dizer pro Git que tipos de arquivos você quer jogar no LFS. Pra isso você faz: git lfs track ".jpg" ".png" ".psd" ".pdf"
Isso vai criar um arquivo chamado .gitattributes com essa condição.
Agora você pode começar a dar git add de arquivos com extensão .psd. Vamos adicionar alguns psds, dar git add, criar um commit e até aqui, tudo igualzinho com era antes. Para o desenvolvedor, parece que nada mudou.
O Git LFS faz isso substituindo arquivos grandes no seu repositório por pequenos arquivos de ponteiro. Durante o uso normal, você nunca verá esses arquivos de ponteiro, pois eles são tratados automaticamente pelo Git LFS: Quando você adiciona um arquivo ao seu repositório, o Git LFS substitui seu conteúdo por um ponteiro e armazena o conteúdo do arquivo em um cache local do Git LFS.
O que está acontecendo agora é que no commit não vai mais anexado o arquivo binário inteiro. Em vez de jogar o binário no diretório .git/objects, ele vai jogar em outro diretório, o .git/lfs.
E no commit em si, em vez de ir armazenado o binário inteiro, vai só um texto indicando onde está o arquivo. Assim o commit fica superleve, sem o binário enorme pesando nele. A vantagem disso é que agora quando você fizer um novo git clone do zero, não vai mais vir todo o 1 GB com todas as versões de photoshop que o designer comitou. Vai vir só o último e você pode pedir versões antigas só se precisar.
Quando você envia novas confirmações ao servidor, todos os arquivos Git LFS referenciados pelas confirmações enviadas recentemente são transferidos do cache local do Git LFS para o armazenamento remoto do Git LFS vinculado ao seu repositório Git.
Quando você faz o check-out de uma confirmação que contém ponteiros do Git LFS, eles são substituídos por arquivos do cache local do Git LFS ou baixados do repositório remoto do Git LFS. A desvantagem disso é que instalar e configurar o suporte de LFS num servidor de Git seu pode ser difícil de gerenciar. Se você estiver usando GitHub ou GitLab ou outra plataforma web, esse trabalho deve ser mais transparente. Na dúvida, sempre use git lfs se tiver arquivos binários grandes no seu projeto.
Pra poucos binários como designs de photoshop, video em mp4 de tutorial do seu produto, manuais em PDF e coisas assim, use o git lfs. No caso do seu projeto ser basicamente só binários grandes e pouco ou nenhum texto, eu diria que o Git não é a melhor solução. Não só git, nenhum versionador feito pra código. Imagina uma agência de design ou uma produtora de vídeo. Ninguém usa Git num lugar desses. Se você precisa lidar com binário, o fluxo de trabalho é completamente diferente. Não tem como dois designers trabalharem ao mesmo tempo, em máquinas separadas, no mesmo arquivo de Illustrator. Não existe pull request de edição de vídeo de Premiere Pro. Não tem como fazer patches num arquivo de áudio de LogicPro. Trabalho de mídia, pela própria natureza, sempre vai ser um fluxo em cascata, onde a próxima etapa só pode ser iniciada quando a anterior já terminou.
Por isso mesmo, não é incomum ver servidores de arquivos em rede de alta velocidade, rede de 10 gigabit, com servidores mais parrudos, com gigabytes de RAM pra fazer buffer, e soluções bem caras como os famosos Jellyfish da LumaForge, cujos modelos mais baratos como o de 32TB móvel, começa em mais de 9 mil dólares. O modelo servidor, que começa com 80TB não sai por menos de 30 mil dólares.
Reescrevendo Grandes Pedaços da História Há outra opção de reescrita de histórico que você pode usar se precisar reescrever um número maior de confirmações de alguma maneira programável - por exemplo, alterando seu endereço de email globalmente ou removendo um arquivo de cada confirmação. O comando é filter-branch e pode reescrever grandes partes do seu histórico; portanto, você provavelmente não deve usá-lo, a menos que seu projeto ainda não seja público e outras pessoas não tenham trabalhado com base nos commits que você está prestes a reescrever. No entanto, pode ser muito útil. Você aprenderá alguns dos usos comuns para ter uma idéia de algumas das coisas de que é capaz.
Removendo um arquivo de cada confirmação
Uma situação bastante comum é fazer commit em um arquivo binário grande no repositório. Se o repositório for atualizado regularmente, pode acabar com várias versões desse grande arquivo em alguns commits. Se for excluído após algumas semanas, devido à maneira como o Git funciona, você terá ainda várias versões desse arquivo enorme no histórico do meu projeto, ocupando espaço no repositório de todos os desenvolvedores e diminuindo o desempenho das operações como, por exemplo, clonar esse projeto do git. Portanto, esse é um caso em que você pode revisar todo o histórico do projeto e eliminar esse arquivo grande de todas as confirmações do histórico, não apenas as mais recentes.
O problema de um repositório de versionamento é que por princípio, o binário agora está anexado num commit e esse binário é usado também para gerar o SHA-1 que identifica o commit. Se tirar o binário vai necessariamente mudar o SHA-1. Lembra que o Git é um DAG, ou seja um grafo, onde os nós são cada commit apontando pro commit anterior. Ou seja, se o SHA-1 do commit anterior mudar, o SHA-1 de Todos os outros commits que apontam pra ele mudam também.
Outro caso comum em que você deseja fazer mudanças radicais ao longo do histórico acontece quando informações críticas entram no repositório e você não as deseja. O exemplo típico é uma senha. Imagine uma equipe que armazene a senha do banco de dados da empresa em um arquivo de configuração no repositório do projeto e, em algum momento, eles decidiram tornar seu projeto de código aberto e colocá-lo no GitHub. Antes de fazer isso, eles podem querer percorrer seu histórico e remover todos os vestígios dessa senha de cada confirmação que já aconteceu. Eles não querem tornar essa senha pública.
Opção 1: filter-branch - Obsoleto
O filter-branch era chamado de opção nuclear do Git porque pode mudar cada commit único em seu histórico com um comando. Ao tentar usar o comando temos:
Portanto, esse aviso basicamente me diz: não use mais o filter-branch. Isso porque recentemente, o filter-branch ficou absoleto/depreciado por várias razões.
- É extremamente lenta inusoravelmente (várias ordens de magnitude mais lentas do que deveria ser) para repositórios não triviais.
- Está cheio de truques que podem corromper silenciosamente sua reescrita ou pelo menos impedir seus esforços de "limpeza", oferecendo a você algo mais problemático e confuso do que o que você começou.
- É muito onerosa para qualquer reescrita que seja um pouco trivial.
- O projeto git declarou que os problemas acima com branch-filter não podem ser corrigidos de forma compatível com versões anteriores; eles recomendam que você pare de usar filter-branch
Em vez disso, use esse outro comando chamado filter-repo. No momento, o filter-repo ainda não faz parte oficialmente do Git. É distribuído como algo que separa, uma extensão opcional.
O filter-branch é a ferramenta que você provavelmente deseja usar para limpar todo o seu histórico. Para remover um arquivo chamado passwords.txt de todo o seu histórico, você pode usar a opção --tree-filter para filter-branch: git filter-branch --tree-filter 'rm -f passwords.txt' HEAD
A opção --tree-filter executa o comando especificado após cada checkout do projeto e, em seguida, faz o commit novamente dos resultados. Nesse caso, você remove um arquivo chamado passwords.txt de todos os instantâneos, existindo ou não. Se você deseja remover todos os arquivos de backup do editor confirmados acidentalmente, é possível executar algo como: git filter-branch --tree-filter 'rm -f *~' HEAD.
Você poderá assistir ao Git reescrevendo árvores e confirmações e depois movendo o ponteiro do ramo no final. Geralmente, é uma boa ideia fazer isso em uma ramificação de testes e fazer o –hard reset sua ramificação principal depois de determinar o resultado que você realmente deseja. Para executar filter-branch em todos os seus branches, você pode passar --all para o comando
Tornando um subdiretório a nova raiz
Suponha que você tenha feito uma importação de outro sistema de controle de origem e tenha subdiretórios que não fazem sentido (trunk, tags e assim por diante). Se você deseja que o subdiretório de trunk seja a nova raiz do projeto para cada consolidação, o filter-branch também pode ajudá-lo a fazer isso: git filter-branch --subdirectory-filter trunk HEAD
Agora, sua nova raiz do projeto é o que estava no subdiretório de tronco a cada vez. O Git também removerá automaticamente confirmações que não afetaram o subdiretório.
Alterando endereços de e-mail globalmente
Outro caso comum é que você esqueceu de executar o git config para definir seu nome e endereço de e-mail antes de começar a trabalhar, ou talvez queira abrir um projeto de código-fonte no trabalho e alterar todos os seus endereços de e-mail do trabalho para seu endereço pessoal. Em qualquer caso, você pode alterar os endereços de email em várias confirmações em um lote com filter-branch também. Você precisa ter cuidado para alterar apenas os endereços de e-mail que são seus, para usar --commit-filter: git filter-branch --commit-filter '
Isso repõe e reescreve todos os commit para ter seu novo endereço. Como as confirmações contêm os valores SHA-1 de seus pais, esse comando altera todos os SHA-1 de confirmação no seu histórico, não apenas aqueles que têm o endereço de email correspondente.
Opção 2: BFG Repo Cleaner
Uma opção ao filter-branch do Git é a ferramenta feita em java chamada BFG.
- Ótima ferramenta para o seu tempo, mas, embora simplifique algumas coisas, está limitada a alguns tipos de reescritas.
- Arquitetura não é passível de lidar com mais tipos de reescritas.
- Arquitetura apresenta algumas deficiências e bugs, mesmo para o uso pretendido.
Mas resumindo, primeiro você instala Java na sua distro. Como cada um tem seu jeito, veja nas documentações pra cada sistema operacional. Num ubuntu seria um apt install openjdk. Agora você baixa o .jar neste link. Para executar um java, se você não sabe é rodar o comando java -jar com o caminho pra onde você baixou o .jar.
Agora você precisa fazer um git clone --mirror do repositório gigante. Tem que ser com --mirror porque quando você acabar e der git push ele vai reescrever todo o repositório. Mais ou menos como se você fizesse um git push com force.
Com o BFG você pode escolher remover arquivos específicos pelo próprio nome. Mas se forem muitos, você pode escolher remover todos os blobs maiores que um certo tamanho por exemplo. Digamos que todos os seus videos tenham 100mb ou mais, então use esta opção pra remover por esse critério. O BFG vai gerar novos commits e reapontar todas as referências de branchs e tudo mais corretamente, mas os commits antigos vão continuar na lixeira. Pra apagar definitivamente você vai usar o comando git gc. O procedimento completo é primeiro rodar um git reflog pra expirar tudo que você não vai precisar e depois rodar o git gc assim. (imagem) Feito isso, é só dar um git push digamos pro repositório principal no Github. Agora você pode apagar essa cópia local onde rodou o BFG e todo mundo pode dar git clone de novo do novo histórico.
Opção 3: O filter- repo - Recomendada
Use o scoop para instalar o git-filter-repo. A maneira recomendada de instalar o Scoop é baixando e executando o instalador automatizado, que é distribuído como um script do PowerShell. Inicie o PowerShell e execute o seguinte comando: Set-ExecutionPolicy RemoteSigned -scope CurrentUser
Como é visto acima sem executar esse comando, não é possível instalar diretamente o Scoop. Isso permite que o usuário atual execute scripts originados de uma fonte remota. Em seguida, use o seguinte comando para baixar e instalar o Scoop. Você também pode verificar o site do Scoop para garantir que está usando a versão mais recente do comando. iex (novo objeto net.webclient) .downloadstring ('https://get.scoop.sh')
Com o Scoop instalado, você pode prosseguir e usar a ferramenta para instalar o software em sua máquina. Um utilitário popular é o gerenciador de arquivos 7zip. Com o Scoop, você pode instalá-lo executando "scoop install 7zip" no prompt de comando.
Instale o git-filter-repo em qualquer lugar no $PATH:
Ou no diretório que o git --exec-path relata.
Você pode criar documentos copiando Documentation/git-filter-repo.txt para um clone de git.git no subdiretório Documentation/ e executando um build de documentos, ou pode trapacear e copiá-los da ramificação 'docs' do diretório repo. Por exemplo. "git show docs: man1/ git-filter-repo.1> /usr/share/man/man1/git-filter-repo.1". A ramificação do docs também possui um html / git-filter-repo.html que pode ser interessante.
Os programas do scoop ficam instalados em: C:\Users\x_kat\scoop\apps
Então, agora vou dar um exemplo baseado em filter-repo. Primeiramente, clone o projeto em outro diretório para fazer os experimentos. Ou, geralmente, é uma boa ideia fazer isso em uma ramificação de testes e fazer o –hard reset sua ramificação principal depois de determinar o resultado que você realmente deseja.
E digamos que, por qualquer motivo, desejo remover esse arquivo menu.txt do projeto. Eu não quero apenas removê-lo das confirmações mais recentes, quero eliminar todos os vestígios de sua existência agora e no passado.
git filter-repo --path menu.txt --invert-paths
Portanto, este comando significa manter todos os arquivos em todos os commit no histórico do projeto, exceto menu.txt. Se eu olhar para o log –oneline e verificar em commits mais antigos, não haverá mais vestígios de menu.txt. Como agora todo o histórico do projeto foi reescrito, outros repositóios provavelmente precisam excluir completamente o repositório local e cloná-lo novamente para obter o histórico atualizado do projeto. Mas às vezes você precisa recorrer a essas medidas extremas.
Excluir Repositório
-
No GitHub Enterprise, navegue até a página principal do repositório.
-
Sob o nome do seu repositório, clique em Configurações.
-
Em Zona de perigo, clique em Excluir este repositório.
-
Leia os avisos. Para verificar se você está excluindo o repositório correto, digite o nome do repositório que deseja excluir. Por fim, clique em Eu entendo as consequências, exclua este repositório.
Ao tentar enviar alterações ao repositório remoto agora: