Lesson 5: Moving the camera
Today we are finishing with the part that i like a lot, but many readers find boring. Once you have mastered today's material, you can move to the next lesson and there we will actually do renders. To brighten you up here is the head we already know rendered using Gouraud shading:

I removed all the textures. Gouraud shading is really simple. Our kind 3d artists gave us normal vectors to each vertex of the model, they can be found in "vn x y z" lines of the .obj file. We compute the intensity per vertex (and not per triangle as before for the flat shading) and then simply interpolate the intensity inside each triangle as we already did for z or uv coordinates.
By the way, in the case when 3d artists are not so kind, you can recompute the normal vectors as an average of normals to all facets incident to the vertex. Current code i used to generate this image can be found here.
In Euclidean space, coordinates can be given by a point (the origin) and a basis. What does it mean that point P has coordinates (x,y,z) in the frame (O, i,j,k)? It means that the vector OP can be expressed as follows:

Now image that we have another frame (O', i',j',k'). How do we transform coordinates given in one frame to another? First of all let us note that since (i,j,k) and (i',j',k') are bases of 3D, there exists a (non degenerate) matrix M such that:

Let us draw an illustration:

Then let us re-express the vector OP:

Now let us substitute (i',j',k') in the right part with the change of basis matrix:

And it gives us the formula to transform coordinates from one frame to another:

OpenGL and, as a consequence, our tiny renderer are able to draw scenes only with the camera located on the z-axis. If we want to move the camera, no problem, we can move all the scene, leaving the camera immobile.
Let us put the problem this way: we want to draw a scene with a camera situated in point e (eye), the camera should be pointed to the point c (center) in such way that a given vector u (up) is to be vertical in the final render.
Here is an illustration:

It means that we want to do the rendering in the frame (c, x',y',z'). But then our model is given in the frame (O, x,y,z)... No problem, all we need is to compute the transformation of the coordinates. Here is a C++ code computing the necessary 4x4 matrix ModelView:
void lookat(Vec3f eye, Vec3f center, Vec3f up) {
Vec3f z = (eye-center).normalize();
Vec3f x = cross(up,z).normalize();
Vec3f y = cross(z,x).normalize();
Matrix Minv = Matrix::identity();
Matrix Tr = Matrix::identity();
for (int i=0; i<3; i++) {
Minv[0][i] = x[i];
Minv[1][i] = y[i];
Minv[2][i] = z[i];
Tr[i][3] = -eye[i];
}
ModelView = Minv*Tr;
}Note that z' is given by the vector ce (do not forget to normalize it, it helps later). How do we compute x'? Simply by a cross product between u and z'. Then we compute y', such that it is orthogonal to already calculated x' and z' (let me remind you that in our problem settings ce and u are not necessarily orthogonal). The very last step is a translation of the origin to the point of viewer e and our transformation matrix is ready. Now it suffices to get any point with coordinates (x,y,z,1) in the model frame, multiply it by the matrix ModelView and we get the coordinates in the camera frame! By the way, the name ModelView comes from OpenGL terminology.
If you followed this course from the beginning, you should remember strange lines like this one:
screen_coords[j] = Vec2i((v.x+1.)*width/2., (v.y+1.)*height/2.);What does it mean? It means that i have a point Vec2f v, it belongs to the square [-1,1]*[-1,1]. I want to draw it in the image of (width, height) dimensions. Value (v.x+1) is varying between 0 and 2, (v.x+1)/2 between 0 and 1, and (v.x+1)*width/2 sweeps all the image. Thus we effectively mapped the bi-unit square onto the image.
But now we are getting rid of these ugly constructs, and i want to rewrite all the computations in the matrix form. Let us consider the following C++ code:
Matrix viewport(int x, int y, int w, int h) {
Matrix m = Matrix::identity(4);
m[0][3] = x+w/2.f;
m[1][3] = y+h/2.f;
m[2][3] = depth/2.f;
m[0][0] = w/2.f;
m[1][1] = h/2.f;
m[2][2] = depth/2.f;
return m;
}This code creates this matrix:
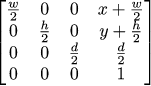
It means that the bi-unit cube [-1,1]*[-1,1]*[-1,1] is mapped onto the screen cube [x,x+w]*[y,y+h]*[0,d]. Right, cube, and not a rectangle, this is because of the depth computations with the z-buffer. Here d is the resolution of the z-buffer. I like to have it equal to 255 because of simplicity of dumping black-and-white images of the z-buffer for debugging.
In the OpenGL terminology this matrix is called viewport matrix.
So, let us sum up. Our models (characters, for example) are created in their own local frame (object coordinates). They are inserted into a scene expressed in world coordinates. The transformation from one to another is made with matrix Model. Then, we want to express it in the camera frame (eye coordinates), the transformation is called View. Then, we deform the scene to create a perspective deformation with Projection matrix (lesson 4), this matrix transforms the scene to so-called clip coordinates. Finally, we draw the scene, and the matrix transforming clip coordinates to the screen coordinates is called Viewport.
Again, if we read a point v from the .obj file, then to draw it on the screen it undergoes the following chain of transformations:
Viewport * Projection * View * Model * v.If you look to this commit, then you will see the following lines:
Vec3f v = model->vert(face[j]);
screen_coords[j] = Vec3f(ViewPort*Projection*ModelView*Matrix(v));As i draw a single object only, the matrix Model is equal to identity, and i merged it with the matrix View.
There is a widely-known fact:
- If we have a model and its normal vectors are given by the artist AND this model is transformed with an affine mapping, then normal vectors are to be transformed with a mapping, equal to the transposition of the inverse matrix of the original mapping matrix
What-what-what?! I met quite a few programmers who know this fact, but it remains a black magic for them. In fact, it is not so complicated. Take a pencil and draw a 2D triangle (0,0), (0,1), (1,0) and a vector n, normal to the hypothenuse. Naturally, n is equal to (1,1). Then let us stretch all the y-coordinates by a factor of 2, leaving x-coordinates intact. Thus, our triangle becomes (0,0), (0,2), (1,0). If we transform the vector n in the same way, it becomes (1, 2) and it is no longer orthogonal to the transformed edge of the triangle.
Thus, to remove all the black magic fog, we need to understand one simple thing: we do not need to simply transform normal vectors (as they can become not normal anymore), we need to compute (new) normal vectors to the transformed model.
Back to 3D, we have a vector n = (A,B,C). We know that the plane passing through the origin and having n for its normal, has an equation Ax+By+Cz=0. Let us write it in the matrix form (i do it in homogeneous coordinates from the beginning):

Recall that (A,B,C) - is a vector, so we augment it with 0 when embedding into the 4D, and (x,y,z) is augmented with 1 since it is a point.
Let us insert an identity matrix in between (inverse to M multiplied by M is equal to identity):

The expression in right parentheses - are for the transformed points of the object. In the left - are for normal vectors to the transformed object! In standard convention we usually write coordinates as columns (please let us not raise all the stuff about contra- and co-variant vectors), so we can rewrite the previous expression as follows:

And the left parentheses tell us that a normal to the transformed object can be computed from the old normal by applying the inverse transpose matrix of the affine mapping.
Please note that if our transformation matrix M is a composition of uniform scalings, rotations and translations (an isometry of euclidean space), then M is equal to its inverse transpose, since inverse and transpose are cancelling each other in this case. But since our matrices include perspective deformations, usually this trick does not help.
In the current code we do not use the transformation of normal vectors, but in the next lesson it will be very, very handy.
Happy coding!