The SLAC Earliest Websites collection contains three "Web Archive Seed" items:
- SLAC World Wide Web Information
- SLAC (Stanford Linear Accelerator Center)
- SLACVM Information Service
These items point to web content that has been archived as part of the SDR "Web Archive Crawl" object druid:wx794kg1767. As we move this WARC content from OpenWayback to pywb we need to reindex it so that it continues to be available. The problem is that entries were manually added to the CDX index so that content that was archived in 2014 from an archival section of the SLAC website appeared to be archived at their original times and locations on the web. If we simply reindex the WARC content as is we will lose these access points.
Some details about how this archived content was assembled can be found in this presentation by Ahmed AlSum in 2015, which is also available as a short paper Reconstruction of the first US Website. In addition Jean Marie Deken, the SLAC Archivist, gave a presentation at the Society of American Archivists in 1997, First in the Web, But Where are the Pieces which provides details of how the web directories that Ahmed crawled were collected.
Ahmed's slides indicate that wget was used to collect the content from the SLAC website, and we can find evidence of this in the WARC files themselves, since wget writes resource records that document how the crawl was performed. For example:
$ warcio extract SLAC_1992.warc 3502455
WARC/1.0
WARC-Type: resource
WARC-Record-ID: <urn:uuid:d01f1321-8ff2-4086-a3ef-874e595dbcf3>
WARC-Warcinfo-ID: <urn:uuid:d3b1201f-ca68-416f-a7b6-356e6c85c2f1>
WARC-Target-URI: metadata://gnu.org/software/wget/warc/wget_arguments.txt
WARC-Date: 2014-09-24T20:13:44Z
WARC-Block-Digest: sha1:K5UC3N3JFSQFQGRNB7HIGVQBMG456QOB
Content-Type: text/plain
Content-Length: 110
"--warc-cdx=on" "--no-warc-compression" "-P" "wget" "--warc-file=SLAC_1992" "--input-file=uri_1992_list.txt
And you can see the log, which was written to the WARC file as well:
warcio extract SLAC_1992.warc 3502947 | head -50
WARC/1.0
WARC-Type: resource
WARC-Record-ID: <urn:uuid:d6c32419-a961-49a7-ac8c-39e12f8e537e>
WARC-Warcinfo-ID: <urn:uuid:d3b1201f-ca68-416f-a7b6-356e6c85c2f1>
WARC-Concurrent-To: <urn:uuid:d01f1321-8ff2-4086-a3ef-874e595dbcf3>
WARC-Target-URI: metadata://gnu.org/software/wget/warc/wget.log
WARC-Date: 2014-09-24T20:13:44Z
WARC-Block-Digest: sha1:PVZVWZ53HLEKLQN573VKBGWB7UNZXJB2
Content-Type: text/plain
Content-Length: 279063
Opening WARC file ‘SLAC_1992.warc’.
--2014-09-24 13:13:39-- http://www.slac.stanford.edu/archive/1992/SLACVM/
Resolving www.slac.stanford.edu... 134.79.197.200, 2620:114:d000:2716::200
Connecting to www.slac.stanford.edu|134.79.197.200|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1101 (1.1K) [text/html]
Saving to: ‘wget/index.html’
0K . 100% 87.5M=0s
2014-09-24 13:13:39 (87.5 MB/s) - ‘wget/index.html’ saved [1101/1101]
--2014-09-24 13:13:39-- http://www.slac.stanford.edu/archive/1992/SLACVM/spicell/
Reusing existing connection to www.slac.stanford.edu:80.
HTTP request sent, awaiting response... 200 OK
Length: 766 [text/html]
Saving to: ‘wget/index.html.1’
0K 100% 73.1M=0s
2014-09-24 13:13:39 (73.1 MB/s) - ‘wget/index.html.1’ saved [766/766]
--2014-09-24 13:13:39-- http://www.slac.stanford.edu/archive/1992/SLACVM/www/
Reusing existing connection to www.slac.stanford.edu:80.
HTTP request sent, awaiting response... 200 OK
Length: 758 [text/html]
Saving to: ‘wget/index.html.2’
0K 100% 55.6M=0s
2014-09-24 13:13:39 (55.6 MB/s) - ‘wget/index.html.2’ saved [758/758]
--2014-09-24 13:13:39-- http://www.slac.stanford.edu/archive/1992/SLACVM/www.console
Reusing existing connection to www.slac.stanford.edu:80.
HTTP request sent, awaiting response... 200 OK
Length: 50452 (49K) [text/plain]
Saving to: ‘wget/www.console
...
Ahmed's slides make it clear that significant research using directory listings, search engine results, and interviews guided them in determining when particular pages were created and where they originally lived on the web. They used this research to create custom CDX entries to make the pages available at particular times and locations in the OpenWayback Machine.
For example this entry in the CDX file:
slacvm.slac.stanford.edu/find/01010008.corpse 19950105000000 http://slacvm.slac.stanford.edu/FIND/01010008.corpse text/html 200 24NCU52QG67HBV3ZVXDFDIFIXBTZ64TQ - - 777386 SLAC_1996.warc
points at this WARC record:
WARC/1.0
WARC-Type: response
WARC-Record-ID: <urn:uuid:21ccba39-c891-453d-8695-22d775abc358>
WARC-Warcinfo-ID: <urn:uuid:c0673e53-b026-423e-95d0-428f66e76a34>
WARC-Concurrent-To: <urn:uuid:218d1c7e-c4b0-4f88-8f4f-cefacc344c13>
WARC-Target-URI: http://www.slac.stanford.edu/archive/1996/SLACVM/www/192/rl1162/01010008.corpse
WARC-Date: 2014-09-24T20:13:56Z
WARC-IP-Address: 134.79.197.200
WARC-Block-Digest: sha1:ZQOCCTNFZ7HXDFKLIG47QCV5YZLXODZ6
WARC-Payload-Digest: sha1:24NCU52QG67HBV3ZVXDFDIFIXBTZ64TQ
Content-Type: application/http;msgtype=response
Content-Length: 4274
HTTP/1.1 200 OK
Date: Wed, 24 Sep 2014 20:13:56 GMT
Server: Apache
Last-Modified: Thu, 05 Jan 1995 10:53:28 GMT
ETag: "2580014a-f9b-2cdddf9553a02"
Accept-Ranges: bytes
Content-Length: 3995
Keep-Alive: timeout=15, max=83
Connection: Keep-Alive
Content-Type: text/html
<title>Papers That Shaped Modern HEP</title>
<h1>Papers That Shaped Modern High-Energy Physics</h1>
<h2>(Based on Data From SPIRES-HEP Database at SLAC)</h2>
...
The key things to note here are:
- The CDX file allows for the lookup of the URL http://slacvm.slac.stanford.edu/FIND/01010008.corpse whereas the WARC record's WARC-Target-URI indicates it was actually obtained from http://www.slac.stanford.edu/archive/1996/SLACVM/www/192/rl1162/01010008.corpse (a different URL).
- The CDX file allows for the lookup at a particular date/time 1995-01-05 00:00:00 but the WARC-Date header indicates it was obtained at 2014-09-24 20:13:56. It's interesting that the Last-Modified HTTP header that was acquired from the server wasn't used here (1995-01-05 10:53:28).
Also on inspecting the CDX file there are entries for the 2014 crawl:
slac.stanford.edu/archive/1992/slacvm/spicell/192/rl1414/terryh.tyh239 20140924201340 http://www.slac.stanford.edu/archive/1992/SLACVM/spicell/192/rl1414/terryh.tyh239 text/plain 200 JMVR4AX4XU2B3J2L6MYGBOUP6QJ4GCLZ - - 513081 SLAC_1992.warc
Perhaps these were records were left because they weren't sure how modify the WARC records that wget generated? Analysis shows that some WARC records can have up to 3 CDX entries. It's hard to say now 8 years later what the motivation for this was, but to retain backwards compatibility with the access points that are currently provided we will want to create WARC records for all of the access points in the CDX file.
Moving these WARC records into the new pywb environment requires them to be reindexed. The decisions that Ahmed made in constructing these CDX entries need to be preserved, but instead of putting them into the CDX index by hand we want to persist them in the WARC data so that they can be reindexed now, and in the future, without disturbing their URL and date/time access points. Other parts of the Stanford website and the larger web have linked to these pages in the archive, and we want those to continue to work.
If we simply convert these CDX entries to CDXJ then future archivists will need to remember to do the same thing if they move the WARC data to a new system. For Stanford the current practice is to treat CDX files as derivatives of the WARC data. Apart from system level backups these CDX files are not stored in the Stanford Digital Repository.
To support our work to persist this provenance data in the SLAC WARC files we decided to use the Rhizome's proposed addition of WARC-Source-URI and WARC-Creation-Date to the WARC Standard. These headers allow for WARC records to retain information about when and from where the web content was crawled, but also to allow the WARC-Target-URI and WARC-Date to reflect how the record should be indexed and made accessible. It doesn't look like these headers have made it into the v1.1 specification, but seeing as how they shouldn't disturb indexing or playback they can be used without causing problems. Admittedly this is a corner case that not many people would encounter unless they are reconstructing parts of the web based on materials that are no longer available on the web. But maybe it's something that would be done more often if there were tools that supported it?
There is one final aspect of Ahmed's 2014 reconstruction that is important to mention here. wget was used to archive the content from the SLAC homepage, and CDX entries were created by hand for some of the content so that they appeared to be available at the slacvm.slac.stanford.edu host name. However there are many internal links on pages that point at slacvm.slac.stanford.edu that did not get corresponding CDX entries. For example the OpenWayback page https://swap.stanford.edu/19941004000000/http://slacvm.slac.stanford.edu/FIND/slac.html contains links to things like Library News http://slacvm.slac.stanford.edu/FIND/libnews.html which work, but other links People at SLAC http://slacvm.slac.stanford.edu/FIND/binlist which do not. This appears to be because CDX entries were not created for all links.

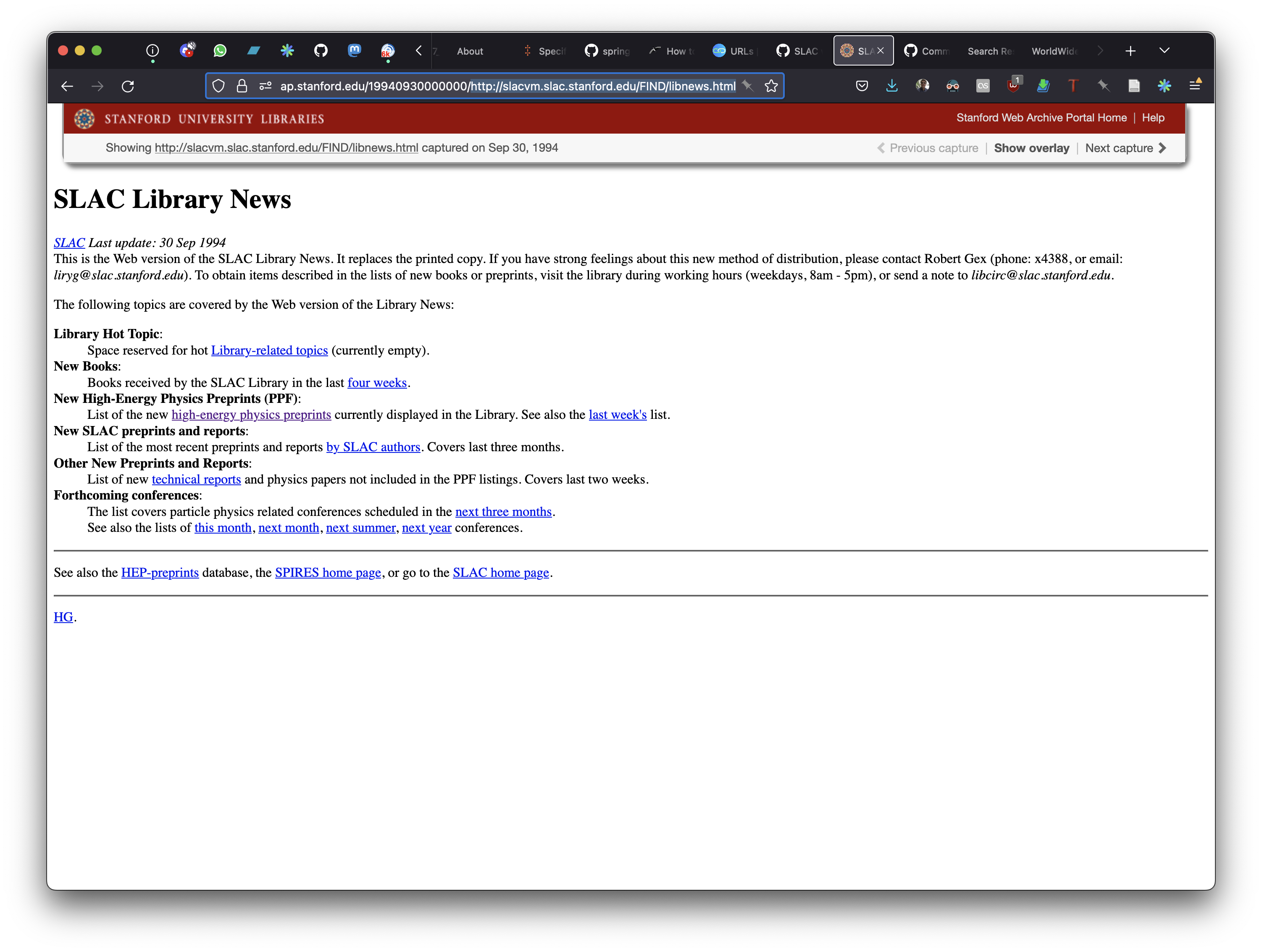
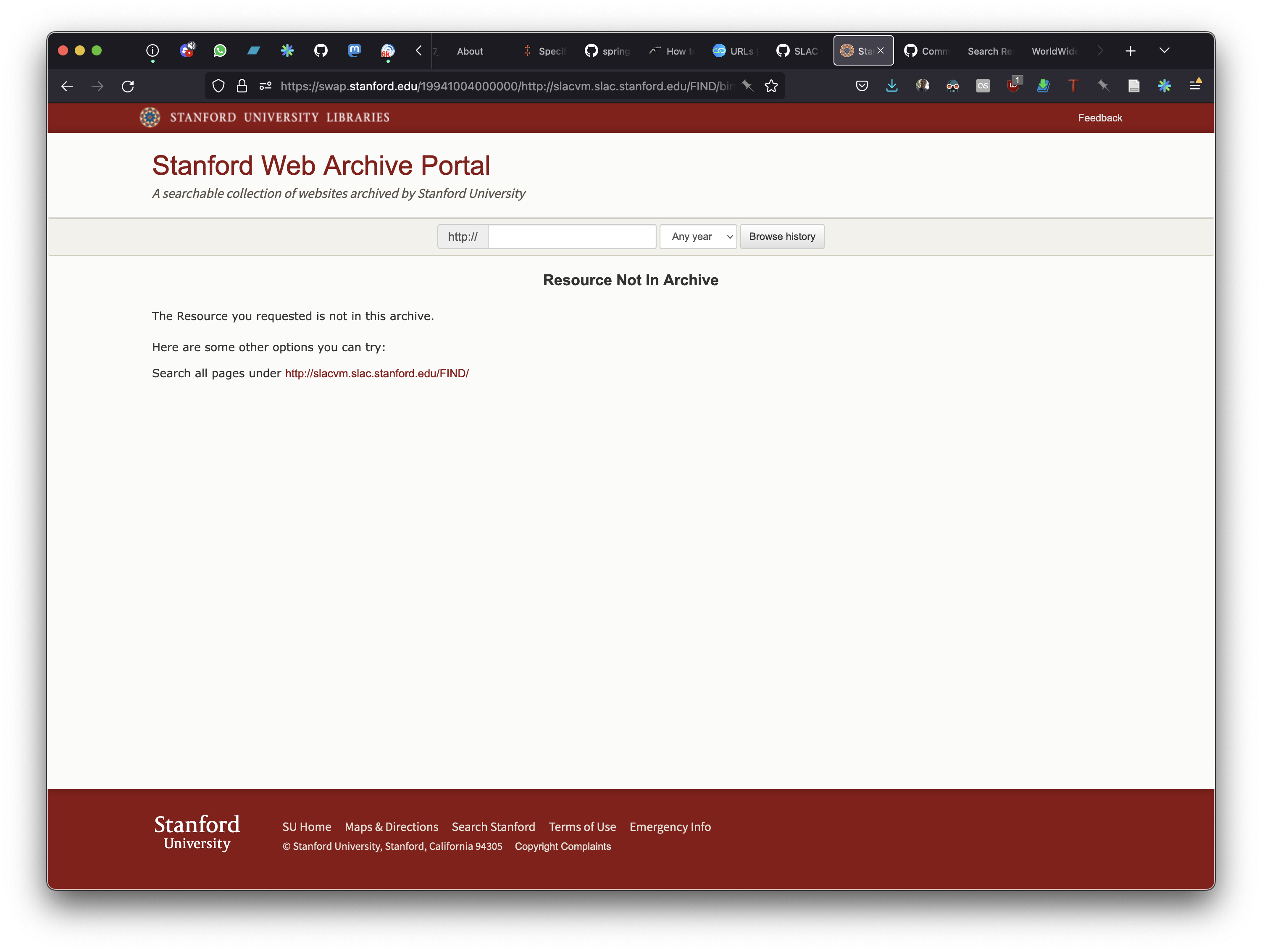
The new pywb index and WARC data do not fix these pre-existing problems with the reconstructed website.
The process for rewriting our WARC data for this SLAC material is to use
the existing CDX index (256 GB) , which was filtered to only include lines that reference a SLAC WARC file, and is stored in data/SLAC.cdx.
- read each SLAC CDX entry from the existing index
- get the desired URL (WARC-Target-URI and datetime (WARC-Date).
- read the corresponding WARC record
- if the WARC record's datetime and URL are the same as what is in the CDX entry go back to 1
- copy the WARC record's current WARC-Target-URI to WARC-Source-URI
- copy the WARC record's current WARC-Date to WARC-Creation-Date
- replace the WARC-Target-URI with the one obtained from the CDX entry
- replace the WARC-Date with the one obtained from the CDX entry
- write the WARC record to a new file
Once the new WARC data has been generated the original WARC data and the new
SLAC_2022.warc file can be accessioned as a new SDR item (hopefully how you
found this documentation), and there is a record of what actually happened for
anyone that looks at the WARC data again. It would be great if playback
interfaces displayed the information in the WARC-Creation-Date and
WARC-Source-URI headers, but that's left as an exercise for another time.
To run rewrite.py you'll need to get the data from the SDR and put the files in the data directory. You can get them from Argo at:
https://argo.stanford.edu/view/druid:wx794kg1767
Then you will need to have a Python3 environment and install some dependencies:
pip install -r requirements.txt
If you want you can run the tests:
pyptest test.py
Then run the conversion:
./rewrite.py
Here are some bookmarks to use to confirm that the content has been rewritten correctly.
- https://swap.stanford.edu/19920818000000/http://slacvm.slac.stanford.edu/FIND/slac.html
- https://swap.stanford.edu/19960105000000/http://slacvm.slac.stanford.edu/FIND/slac.html