Unsorted Playground for Machine Learning, Reinforcement Learning and other AI Experiments.
requirements.txt contains the dependencies of all ai-playground programs. You might
want to create a virtual environment for sparing your local Python installation. Switch
to the root folder of ai-playgound and enter the following commands:
python3 -m venv ai-p-env
source ai-p-env/bin/activate
pip install -r requirements.txt
When the virtual environment is activated, pip and python should now point to
a Python 3 installation and you should be able to run the programs using python. You
can activate the environment at any later moment in time using source ai-p-env/bin/activate
from the project's root folder.
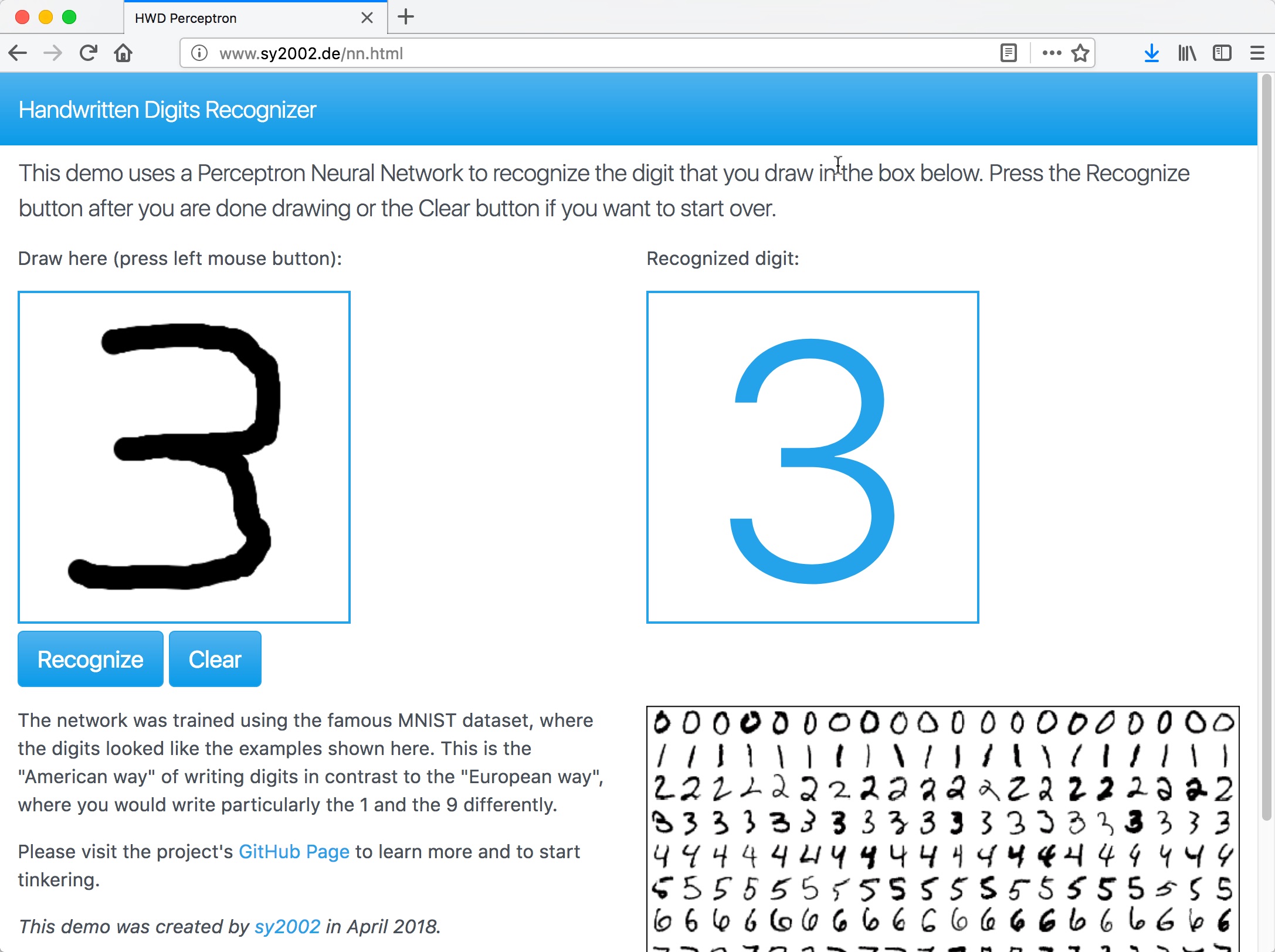
The HWD-Perceptron project was my first attempt to learn how a Perceptron works by implementing it from scratch. I used the very well known MIST dataset to do handwritten digits recognition.
The project is a ready-to-go Python app that lets you learn more about Neural Networks and Machine Learning in general and more about simple Perceptron based handwritten digits recognition in particular.
Go to the HWD-Perceptron Repository to learn more.

The programs maze_runner.py and maze_runner_q_mp.py in the folder maze are
using Reinforcement Learning to solve mazes of arbitrary sizes.
Have a look at these Demos to get an idea.
OpenAI Gym is a fantastic place to practice Reinforment Learning. The classical CartPole balancing challenge has kind of a "Hello World" status. Here is an animation of how the challenge looks like. My solution rl-q-rbf-cartpole.py uses a Radial Basis Function network to transform the four features of the Cart (Cart Position, Cart Velocity, Pole Angle and Pole Velocity At Tip) into a large amount of distances from the centers of RBF "Exemplars" and then use Linear Regression to learn the Value Function using Q-Learning.
As a naive beginner, I thought that scikit-learn's RBFSampler is basically a convenient way to create a collection (or "network") of multiple Radial Basis Functions with random centers. Well, I was wrong as RBFSampler-Experiment.ipynb shows, but in the end, everything is still kind of as you would expect from the name RBFSampler.
You can also try the experiment live and interactively on Kaggle using this Kaggle Kernel. Here is an Article on Medium that nicely explains the whole topic.

This is a hybrid computing experiment: Use the analog computer "Model-1" by Analog Paradigm (http://analogparadigm.com) to simulate an inverse pendulum. In parallel, use a digital computer to execute a digital Reinforcement Learning algorithm that controls the analog computer.
Switch to the folder analog to learn more or watch a short introduction to this experiment on YouTube.