In the world of programming, optimizing performance is a continuous pursuit, particularly when dealing with compute-intensive tasks. Developers often turn to Just-In-Time (JIT) compilation and Ahead-Of-Time (AOT) compilation techniques to achieve substantial performance gains.
In this case Selective Compilation Approach was used for using Numba with Nuitka
Selective Compilation approach is to use Numba JIT selectively, only applying it to the parts of the codebase that are not compiled with Nuitka. This allows developers to reap the benefits of Numba's performance enhancements for specific sections while still leveraging Nuitka's AOT compilation for the rest of the codebase.
To circumvent the compatibility roadblocks, we've ventured into a workaround centered on selective compilation. This
innovative approach treats Numba-optimized functions as script code, which can be executed using Python's exec()
function. By mapping the executed functions to Python objects, I've managed to bridge the gap between Numba JIT and
Nuitka AOT, effectively harmonizing their strengths.
-
Function Definitions: Craft the Numba-optimized functions within dedicated
.pyfiles. These functions encapsulate intricate calculations or data manipulations that stand to benefit from Numba's performance enhancements. -
Script Execution: Within the Nuitka-compiled codebase, employ
exec()to execute the Python code stored in the separate.pyfiles. This triggers Numba JIT compilation at runtime, dynamically optimizing the functions. -
Function Mapping: Create a mapping object that associates function names with the dynamically optimized functions. This object serves as the bridge between the Numba JIT-optimized functions and the Nuitka AOT-compiled code.
-
Function Invocation: With Numba's JIT compilation applied, you can effortlessly invoke the Numba-optimized functions using the function objects stored in the mapping object. The performance gains from Numba's enhancements are now fully accessible.
To further enhance the integration of Numba JIT and Nuitka AOT, we introduce the concept of code obfuscation. Code obfuscation involves the transformation of human-readable code into a less understandable form while retaining its functionality. This process can help safeguard your intellectual property by making it more challenging for unauthorized users to reverse-engineer or understand your code.
-
Function Definitions and Code Obfuscation: Begin by defining your Numba-optimized functions within dedicated
.pyfiles. To obfuscate this code, compile these.pyfiles into.pycfiles using the marshal module. This step transforms the human-readable code into a bytecode representation that is less intuitive to interpret. -
Script Execution with Obfuscated Code: Within the Nuitka-compiled codebase, use
exec()to execute the obfuscated code stored in the.pycfiles. This activates the Numba JIT compilation dynamically, enhancing the performance of the functions. -
Function Mapping and Invocation: As before, create a mapping object linking function names to the dynamically optimized functions. You can then seamlessly invoke these functions using the function objects from the mapping object.
To complete our approach, we incorporate benchmarking by performing calculation on following function.
def sum_of_squares_py(n):
result = 0
for i in range(1, n + 1):
result += i * i
return result
By comparing different scenarios from pure Python approach, Numpy approach, and Numba approach as following parameters.
-
Pure Python Interpreter Benchmark: Measure the execution time of critical sections using the pure Python interpreter as a baseline.
-
Numba with Python Interpreter Benchmark: Benchmark the execution time after applying Numba JIT optimization in combination with the Python interpreter.
-
Numba with Python Interpreter Benchmark with Code Obfuscation: Benchmark execution time after applying Numba JIT optimization with the Python interpreter and code obfuscation
.pyc. -
Numba with Nuitka Benchmark: Measure the execution time after implementing Numba JIT optimization and Nuitka AOT compilation.
-
Numba with Nuitka Benchmark with Code Obfuscation: Measure execution time after implementing Numba JIT optimization, Nuitka AOT compilation, and code obfuscation
.pyc. -
Optimized Functions with NumPy Benchmark: Extend the benchmarking to include optimized functions utilizing NumPy for enhanced performance.
In this step, we employ the timeit.timeit module to measure elapsed time, iterating the process 10 times for enhanced
accuracy.
We evaluate the performance of various optimization scenarios to gain insights into the effectiveness of our approach.
Among these scenarios, the Pure Python Interpreter stands out as the baseline, revealing intriguing performance trends
that shed light on the impact of our strategy.
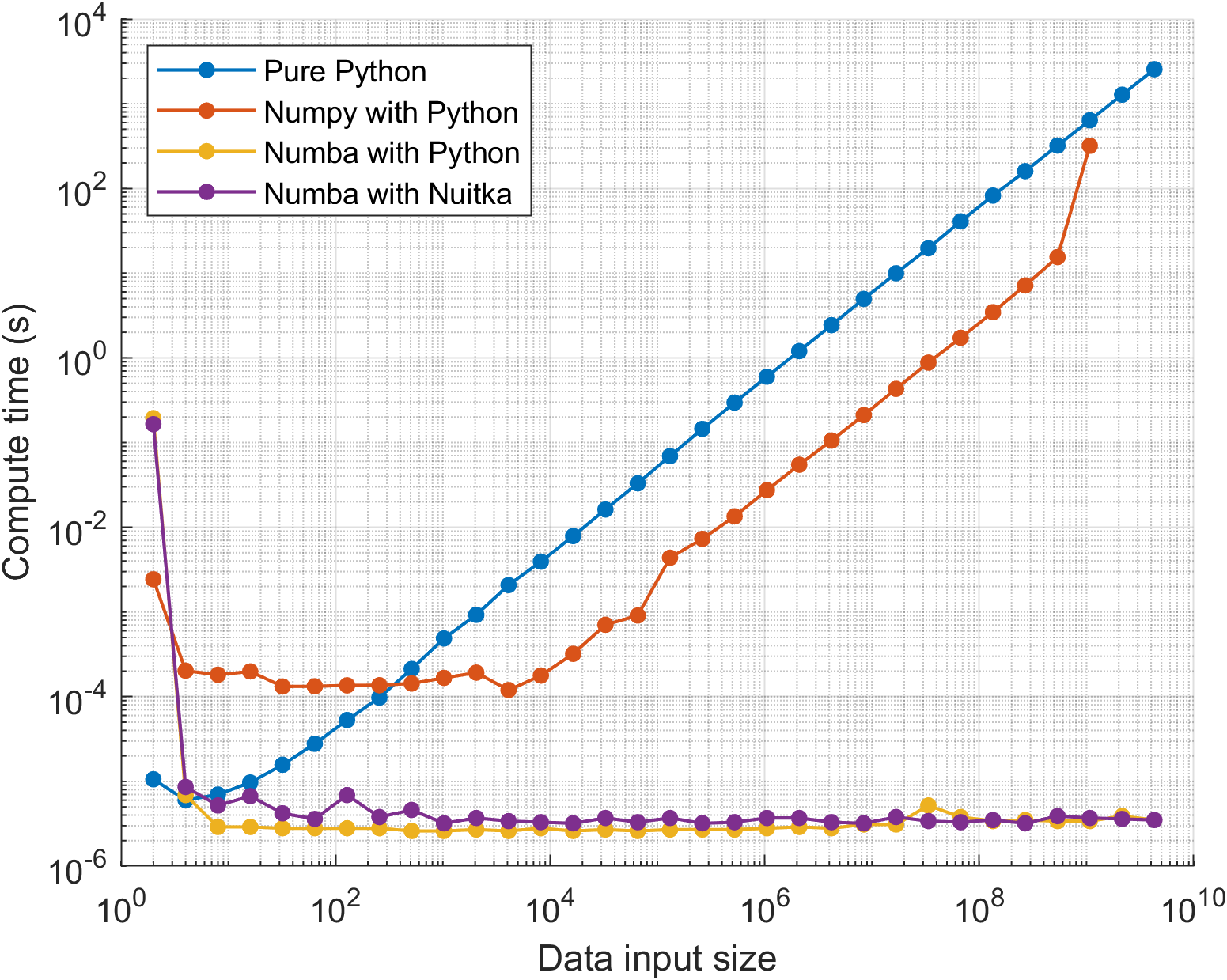
| Data Input | Pure Python | Numpy with Python | Numba with Python | Numba with Nuitka |
|---|---|---|---|---|
| 21*→28 | 44.76 µs | 161.94 µs | 4.46 µs | 5.29 µs |
| 29→216 | 3.65 ms | 0.26 ms | 3.83 µs | 4.20 µs |
| 217 < | 73.85 s | 24.46 s** | 3.40 µs | 4.11 µs |
* Showed data not include the initial "warm-up" time
** Numpy unable to allocate memory for an array with data type int64
-
Pure Python Interpreter: When using the pure Python interpreter, the execution time tends to increase linearly as the workload intensifies. This behavior is expected, as the interpreter handles code execution in a straightforward, sequential manner. As the workload grows, the interpreter's inherent overhead becomes more pronounced, resulting in a predictable increase in execution time.
-
Numpy Performance Anomaly: Interestingly, the benchmarking results indicate that the performance of NumPy is worse than that of the pure Python interpreter for small workloads. This initial dip in performance might stem from the additional overhead introduced by NumPy array manipulation operations, which could outweigh any performance benefits gained from optimized array computations. However, as the workload increases, NumPy performance stabilizes and remains consistently better than the pure Python interpreter for input sizes up to 216. During this phase, NumPy leverages its optimized array manipulation operations to provide notable performance gains. However, beyond the input size of 216, a shift in behavior is observed. At this point, NumPy performance starts to degrade, and the execution time begins to increase linearly, mirroring the behavior exhibited by the pure Python interpreter. This shift could be attributed to various factors, including the inherent overhead of NumPy sophisticated array operations and increased memory usage as the input size grows.
-
Numba Consistently Lower Execution Time: Across all scenarios, Numba demonstrates significantly lower execution times compared to both the pure Python interpreter and NumPy. This performance improvement is consistent and becomes particularly pronounced as the workload increases. The initial "warm-up" time observed in the first Numba execution is due to the lazy compilation approach of Numba. Once the functions are compiled and cached, subsequent executions benefit from the compiled machine code, leading to reduced execution times.
-
Numba with Nuitka and Code Obfuscation: When combining Numba with Nuitka and code obfuscation in Python optimization strikes a delicate balance between performance, compatibility, and portability. While a minor performance trade-off may occur due to Nuitka and code obfuscation, the benefits in terms of enhanced code security, improved compatibility through stand-alone executables, and broader portability make this approach compelling, especially in scenarios where critical performance is vital.
This workaround not only enhances code performance through dynamic and ahead-of-time compilation but also fortifies code security and expands compatibility and portability. While a marginal performance trade-off may occur, the broader benefits of safeguarding intellectual property, enabling compatibility across environments, and facilitating deployment on diverse platforms make this approach compelling, particularly when critical performance remains a priority.