High CPU consumption on Raspberry Pi 1B even while idle #5958
Comments
|
Without a bug report or profile or even version number there's little we can do here. "Tailscale latest version" doesn't age well in bug reports. |
|
1.32.0 |
|
|
|
Please run "tailscale bugreport" on the Raspberry Pi and paste it here. |
Ok brother, previous tailscaled just consume 4-8% when in use. |
|
root@DietPi:~# tailscale bugreport |
|
On the Raspberry Pi can you run: and attach the /tmp/cpu.out file here? |
|
I see no smoking gun. I do see a lot of DNS errors, though. And on start it complains that systemd-resolved isn't configured correctly:
So that's not great, but shouldn't be consuming lots of CPU. I'd also be interested in seeing that CPU profile. |
Don't know why but after latest android update it seems cpu usage decrease a bit. I have attached the cpu. Out file. See the first report |
|
Where's the CPU profile? I see no attachment here. |
|
There are two cpu.out.txt links edited into the original report, the first comment. |
|
The two profile files appear to be the same. pprof output: |
Yes, same. |
|
I guess portlist.GetList could use another round of garbage reductions: |
It's an internal implementation detail, and I plan to refactor it for performance (garbage) reasons anyway, so start by hiding it. Updates #5958 Change-Id: I2c0d1f743d3495c5f798d1d8afc364692cd9d290 Signed-off-by: Brad Fitzpatrick <bradfitz@tailscale.com>
It's an internal implementation detail, and I plan to refactor it for performance (garbage) reasons anyway, so start by hiding it. Updates #5958 Change-Id: I2c0d1f743d3495c5f798d1d8afc364692cd9d290 Signed-off-by: Brad Fitzpatrick <bradfitz@tailscale.com>
In prep for reducing garbage, being able to reuse memory. So far this
doesn't actually reuse much. This is just changing signatures around.
But some improvement in any case:
bradfitz@tsdev:~/src/tailscale.com$ ~/go/bin/benchstat before after
name old time/op new time/op delta
GetList-8 11.8ms ± 9% 9.9ms ± 3% -15.98% (p=0.000 n=10+10)
name old alloc/op new alloc/op delta
GetList-8 99.5kB ± 2% 91.9kB ± 0% -7.62% (p=0.000 n=9+9)
name old allocs/op new allocs/op delta
GetList-8 3.05k ± 1% 2.93k ± 0% -3.83% (p=0.000 n=8+9)
More later, once parsers can reuse strings from previous parses.
Updates #5958
Change-Id: I76cd5048246dd24d11c4e263d8bb8041747fb2b0
Signed-off-by: Brad Fitzpatrick <bradfitz@tailscale.com>
In prep for reducing garbage, being able to reuse memory. So far this
doesn't actually reuse much. This is just changing signatures around.
But some improvement in any case:
bradfitz@tsdev:~/src/tailscale.com$ ~/go/bin/benchstat before after
name old time/op new time/op delta
GetList-8 11.8ms ± 9% 9.9ms ± 3% -15.98% (p=0.000 n=10+10)
name old alloc/op new alloc/op delta
GetList-8 99.5kB ± 2% 91.9kB ± 0% -7.62% (p=0.000 n=9+9)
name old allocs/op new allocs/op delta
GetList-8 3.05k ± 1% 2.93k ± 0% -3.83% (p=0.000 n=8+9)
More later, once parsers can reuse strings from previous parses.
Updates #5958
Change-Id: I76cd5048246dd24d11c4e263d8bb8041747fb2b0
Signed-off-by: Brad Fitzpatrick <bradfitz@tailscale.com>
In prep for reducing garbage, being able to reuse memory. So far this
doesn't actually reuse much. This is just changing signatures around.
But some improvement in any case:
bradfitz@tsdev:~/src/tailscale.com$ ~/go/bin/benchstat before after
name old time/op new time/op delta
GetList-8 11.8ms ± 9% 9.9ms ± 3% -15.98% (p=0.000 n=10+10)
name old alloc/op new alloc/op delta
GetList-8 99.5kB ± 2% 91.9kB ± 0% -7.62% (p=0.000 n=9+9)
name old allocs/op new allocs/op delta
GetList-8 3.05k ± 1% 2.93k ± 0% -3.83% (p=0.000 n=8+9)
More later, once parsers can reuse strings from previous parses.
Updates #5958
Change-Id: I76cd5048246dd24d11c4e263d8bb8041747fb2b0
Signed-off-by: Brad Fitzpatrick <bradfitz@tailscale.com>
|
cc @andrew-d for the interface enumeration bit in netcheck |
In prep for reducing garbage, being able to reuse memory. So far this
doesn't actually reuse much. This is just changing signatures around.
But some improvement in any case:
bradfitz@tsdev:~/src/tailscale.com$ ~/go/bin/benchstat before after
name old time/op new time/op delta
GetList-8 11.8ms ± 9% 9.9ms ± 3% -15.98% (p=0.000 n=10+10)
name old alloc/op new alloc/op delta
GetList-8 99.5kB ± 2% 91.9kB ± 0% -7.62% (p=0.000 n=9+9)
name old allocs/op new allocs/op delta
GetList-8 3.05k ± 1% 2.93k ± 0% -3.83% (p=0.000 n=8+9)
More later, once parsers can reuse strings from previous parses.
Updates #5958
Change-Id: I76cd5048246dd24d11c4e263d8bb8041747fb2b0
Signed-off-by: Brad Fitzpatrick <bradfitz@tailscale.com>
Make Linux parsePorts also an append-style API and attach it to
caller's provided append base memory.
And add a little string intern pool in front of the []byte to string
for inode names.
name old time/op new time/op delta
GetList-8 11.1ms ± 4% 9.8ms ± 6% -11.68% (p=0.000 n=9+10)
name old alloc/op new alloc/op delta
GetList-8 92.8kB ± 2% 79.7kB ± 0% -14.11% (p=0.000 n=10+9)
name old allocs/op new allocs/op delta
GetList-8 2.94k ± 1% 2.76k ± 0% -6.16% (p=0.000 n=10+10)
More coming. (the bulk of the allocations are in addProcesses and
filesystem operations, most of which we should usually be able to
skip)
Updates #5958
Change-Id: I3f0c03646d314a16fef7f8346aefa7d5c96701e7
Signed-off-by: Brad Fitzpatrick <bradfitz@tailscale.com>
Make Linux parsePorts also an append-style API and attach it to
caller's provided append base memory.
And add a little string intern pool in front of the []byte to string
for inode names.
name old time/op new time/op delta
GetList-8 11.1ms ± 4% 9.8ms ± 6% -11.68% (p=0.000 n=9+10)
name old alloc/op new alloc/op delta
GetList-8 92.8kB ± 2% 79.7kB ± 0% -14.11% (p=0.000 n=10+9)
name old allocs/op new allocs/op delta
GetList-8 2.94k ± 1% 2.76k ± 0% -6.16% (p=0.000 n=10+10)
More coming. (the bulk of the allocations are in addProcesses and
filesystem operations, most of which we should usually be able to
skip)
Updates #5958
Change-Id: I3f0c03646d314a16fef7f8346aefa7d5c96701e7
Signed-off-by: Brad Fitzpatrick <bradfitz@tailscale.com>
Make Linux parsePorts also an append-style API and attach it to
caller's provided append base memory.
And add a little string intern pool in front of the []byte to string
for inode names.
name old time/op new time/op delta
GetList-8 11.1ms ± 4% 9.8ms ± 6% -11.68% (p=0.000 n=9+10)
name old alloc/op new alloc/op delta
GetList-8 92.8kB ± 2% 79.7kB ± 0% -14.11% (p=0.000 n=10+9)
name old allocs/op new allocs/op delta
GetList-8 2.94k ± 1% 2.76k ± 0% -6.16% (p=0.000 n=10+10)
More coming. (the bulk of the allocations are in addProcesses and
filesystem operations, most of which we should usually be able to
skip)
Updates #5958
Change-Id: I3f0c03646d314a16fef7f8346aefa7d5c96701e7
Signed-off-by: Brad Fitzpatrick <bradfitz@tailscale.com>
name old time/op new time/op delta
GetList-8 11.2ms ± 5% 11.1ms ± 3% ~ (p=0.661 n=10+9)
name old alloc/op new alloc/op delta
GetList-8 83.3kB ± 1% 67.4kB ± 1% -19.05% (p=0.000 n=10+10)
name old allocs/op new allocs/op delta
GetList-8 2.89k ± 2% 2.19k ± 1% -24.24% (p=0.000 n=10+10)
(real issue is we're calling this code as much as we are, but easy
enough to make it efficient because it'll still need to be called
sometimes in any case)
Updates #5958
Change-Id: I90c20278d73e80315a840aed1397d24faa308d93
Signed-off-by: Brad Fitzpatrick <bradfitz@tailscale.com>
name old time/op new time/op delta
GetList-8 11.2ms ± 5% 11.1ms ± 3% ~ (p=0.661 n=10+9)
name old alloc/op new alloc/op delta
GetList-8 83.3kB ± 1% 67.4kB ± 1% -19.05% (p=0.000 n=10+10)
name old allocs/op new allocs/op delta
GetList-8 2.89k ± 2% 2.19k ± 1% -24.24% (p=0.000 n=10+10)
(real issue is we're calling this code as much as we are, but easy
enough to make it efficient because it'll still need to be called
sometimes in any case)
Updates #5958
Change-Id: I90c20278d73e80315a840aed1397d24faa308d93
Signed-off-by: Brad Fitzpatrick <bradfitz@tailscale.com>
name old time/op new time/op delta
GetList-8 11.2ms ± 5% 11.1ms ± 3% ~ (p=0.661 n=10+9)
name old alloc/op new alloc/op delta
GetList-8 83.3kB ± 1% 67.4kB ± 1% -19.05% (p=0.000 n=10+10)
name old allocs/op new allocs/op delta
GetList-8 2.89k ± 2% 2.19k ± 1% -24.24% (p=0.000 n=10+10)
(real issue is we're calling this code as much as we are, but easy
enough to make it efficient because it'll still need to be called
sometimes in any case)
Updates #5958
Change-Id: I90c20278d73e80315a840aed1397d24faa308d93
Signed-off-by: Brad Fitzpatrick <bradfitz@tailscale.com>
In contrast to BenchmarkGetList, this new BenchmarkGetListIncremental
acts like what happens in practice, remembering the previous run and
avoiding work that's already been done previously.
Currently:
BenchmarkGetList
BenchmarkGetList-8 100 11011100 ns/op 68411 B/op 2211 allocs/op
BenchmarkGetList-8 100 11443410 ns/op 69073 B/op 2223 allocs/op
BenchmarkGetList-8 100 11217311 ns/op 68421 B/op 2197 allocs/op
BenchmarkGetList-8 100 11035559 ns/op 68801 B/op 2220 allocs/op
BenchmarkGetList-8 100 10921596 ns/op 69226 B/op 2225 allocs/op
BenchmarkGetListIncremental
BenchmarkGetListIncremental-8 168 7187217 ns/op 1192 B/op 28 allocs/op
BenchmarkGetListIncremental-8 172 7004525 ns/op 1194 B/op 28 allocs/op
BenchmarkGetListIncremental-8 162 7235889 ns/op 1221 B/op 29 allocs/op
BenchmarkGetListIncremental-8 164 7035671 ns/op 1219 B/op 29 allocs/op
BenchmarkGetListIncremental-8 174 7095448 ns/op 1114 B/op 27 allocs/op
Updates #5958
Change-Id: I1bd5a4b206df4173e2cb8e8a780429d9daa6ef1d
Signed-off-by: Brad Fitzpatrick <bradfitz@tailscale.com>
In contrast to BenchmarkGetList, this new BenchmarkGetListIncremental
acts like what happens in practice, remembering the previous run and
avoiding work that's already been done previously.
Currently:
BenchmarkGetList
BenchmarkGetList-8 100 11011100 ns/op 68411 B/op 2211 allocs/op
BenchmarkGetList-8 100 11443410 ns/op 69073 B/op 2223 allocs/op
BenchmarkGetList-8 100 11217311 ns/op 68421 B/op 2197 allocs/op
BenchmarkGetList-8 100 11035559 ns/op 68801 B/op 2220 allocs/op
BenchmarkGetList-8 100 10921596 ns/op 69226 B/op 2225 allocs/op
BenchmarkGetListIncremental
BenchmarkGetListIncremental-8 168 7187217 ns/op 1192 B/op 28 allocs/op
BenchmarkGetListIncremental-8 172 7004525 ns/op 1194 B/op 28 allocs/op
BenchmarkGetListIncremental-8 162 7235889 ns/op 1221 B/op 29 allocs/op
BenchmarkGetListIncremental-8 164 7035671 ns/op 1219 B/op 29 allocs/op
BenchmarkGetListIncremental-8 174 7095448 ns/op 1114 B/op 27 allocs/op
Updates #5958
Change-Id: I1bd5a4b206df4173e2cb8e8a780429d9daa6ef1d
Signed-off-by: Brad Fitzpatrick <bradfitz@tailscale.com>
Add an osImpl interface that can be stateful and thus more efficient
between calls. It will later be implemented by all OSes but for now
this change only adds a Linux implementation.
Remove Port.inode. It was only used by Linux and moves into its osImpl.
Don't reopen /proc/net/* files on each run. Turns out you can just
keep then open and seek to the beginning and reread and the contents
are fresh.
name old time/op new time/op delta
GetListIncremental-8 7.29ms ± 2% 6.53ms ± 1% -10.50% (p=0.000 n=9+9)
name old alloc/op new alloc/op delta
GetListIncremental-8 1.30kB ±13% 0.70kB ± 5% -46.38% (p=0.000 n=9+10)
name old allocs/op new allocs/op delta
GetListIncremental-8 33.2 ±11% 18.0 ± 0% -45.82% (p=0.000 n=9+10)
Updates #5958
Change-Id: I4be83463cbd23c2e2fa5d0bdf38560004f53401b
Signed-off-by: Brad Fitzpatrick <bradfitz@tailscale.com>
Add an osImpl interface that can be stateful and thus more efficient
between calls. It will later be implemented by all OSes but for now
this change only adds a Linux implementation.
Remove Port.inode. It was only used by Linux and moves into its osImpl.
Don't reopen /proc/net/* files on each run. Turns out you can just
keep then open and seek to the beginning and reread and the contents
are fresh.
name old time/op new time/op delta
GetListIncremental-8 7.29ms ± 2% 6.53ms ± 1% -10.50% (p=0.000 n=9+9)
name old alloc/op new alloc/op delta
GetListIncremental-8 1.30kB ±13% 0.70kB ± 5% -46.38% (p=0.000 n=9+10)
name old allocs/op new allocs/op delta
GetListIncremental-8 33.2 ±11% 18.0 ± 0% -45.82% (p=0.000 n=9+10)
Updates #5958
Change-Id: I4be83463cbd23c2e2fa5d0bdf38560004f53401b
Signed-off-by: Brad Fitzpatrick <bradfitz@tailscale.com>
Add an osImpl interface that can be stateful and thus more efficient
between calls. It will later be implemented by all OSes but for now
this change only adds a Linux implementation.
Remove Port.inode. It was only used by Linux and moves into its osImpl.
Don't reopen /proc/net/* files on each run. Turns out you can just
keep then open and seek to the beginning and reread and the contents
are fresh.
name old time/op new time/op delta
GetListIncremental-8 7.29ms ± 2% 6.53ms ± 1% -10.50% (p=0.000 n=9+9)
name old alloc/op new alloc/op delta
GetListIncremental-8 1.30kB ±13% 0.70kB ± 5% -46.38% (p=0.000 n=9+10)
name old allocs/op new allocs/op delta
GetListIncremental-8 33.2 ±11% 18.0 ± 0% -45.82% (p=0.000 n=9+10)
Updates #5958
Change-Id: I4be83463cbd23c2e2fa5d0bdf38560004f53401b
Signed-off-by: Brad Fitzpatrick <bradfitz@tailscale.com>
|
cpu.out.txt |
|
The work done on portList earlier in the bug is not in 1.32.x, it will be in 1.34. |
It will be fix in next update? |
|
The portList fixes will not be in any 1.32.x update. Until then, I'd recommend using 1.30.2. |
|
#6032 was delivered in 1.34. Barring further comment, we'll expect to close this during the next regular bug scrub. |
|
I'm also experiencing this. I'm seeing tailscaled running on 25% CPU. Here is the BUGREPORT and a CPU profile: |
|
@Milo123459 That system is experiencing a different issue. It appears to have been set up with If this is still ongoing, please file a new issue for it. |
cpu.out.txt
cpu.out.txt
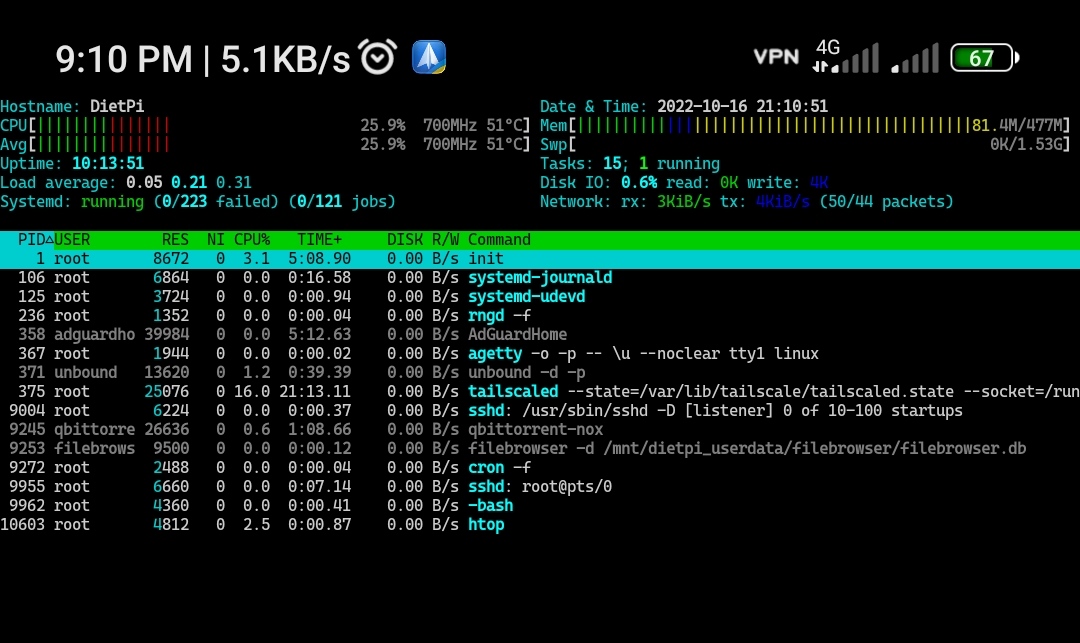
What is the issue?
Resources hungry! Usage lots of cpu in ideal mode on raspberry pi. Please update it and make it more light
Steps to reproduce
When using it raspberry pi 1b it consume 20% of cpu when in tailscale ideal mode.
Are there any recent changes that introduced the issue?
Yes, after recent update
OS
Linux
OS version
Bullsey
Tailscale version
Tailscale latest version
Bug report
No response
The text was updated successfully, but these errors were encountered: