ABCI++ RFC #254
ABCI++ RFC #254
Conversation
This commit adds an RFC for ABCI++, which is a collection of three new phases of communication between the consensus engine and the application. Co-authored-by: Sunny Aggarwal <sunnya97@protonmail.ch>
rfc/004-abci++.md
Outdated
|
|
||
| Once a validator knows that consensus has failed to be achieved for a given block, it must run `RevertProposal(block.height, block.round)`, in order to signal to the application to revert any potentially mutative state changes it may have made. In Tendermint, this occurs when incrementing rounds. | ||
|
|
||
| RFC: How do we handle the scenario where honest node A finalized on round x, and honest node B finalized on round x + 1? (e.g. when 2f precommits are publicly known, and a validator precommits themself but doesn't broadcast, but they increment rounds) Is this a real concern? The state root derived could change if everyone finalizes on round x+1, not round x, as the state machine can depend non-uniformly on timestamp. |
There was a problem hiding this comment.
RFC flag (How do we make all validators agree on what round they ran process proposal on. This primarily matters for immediate execution)
There was a problem hiding this comment.
You might bold "RFC" here, since these comment flags don't show up in certain view modes and they get kind of buried in all the other discussion.
By the way, the context for all my formatting comments is that we're planning on sending this around the community a bit, and I want to make sure everything as as easy to parse as possible! 😁
There was a problem hiding this comment.
I'm lost as to why this even matters. Why would a node have to revert if it finalized at a different round? Why is that part of the state root?
There was a problem hiding this comment.
It would matter if the round number is used in the execution of the block in an immediate execution scheme. Seems from later comments that this won't matter though
rfc/004-abci++.md
Outdated
|
|
||
| The `CanonicalVote` struct will acommodate the `UnsignedAppVoteData` field by adding another string to its encoding, after the `chain-id`. This should not interfere with existing hardware signing integrations, as it does not affect the constant offset for the `height` and `round`, and the vote size does not have an explicit upper bound. (So adding this unsigned app vote data field is equivalent from the HSM's perspective as having a superlong chain-ID) | ||
|
|
||
| RFC: Please comment if you think it will be fine to have elongate the message the HSM signs, or if we need to explore pre-hashing the app vote data. |
There was a problem hiding this comment.
RFC: (Essentially) can the HSM input be arbitrarily long, or do we require pre-hashing data.
|
|
||
| Prepare proposal allows the block proposer to perform application-dependent work in a block, to lower the amount of work the rest of the network must do. batch optimizations to a block, which is a key optimization for scaling. This introduces the following method | ||
| ```rust | ||
| fn PrepareProposal(Block) -> BlockData |
There was a problem hiding this comment.
Above in Prepare Proposal phase you state:
It will then return block data that is prepared for gossip on the network, and additional fields to include into the block header.
While it seems that this returns the prepared BlockData (which gives the app the power to modify BlockData as it pleases) there doesn't seem to be a way for the app to add additional data to the header?
There was a problem hiding this comment.
Thanks for pointing that out. The API for that is postponed to Vote Extensions, let me move that description accordingly. (This was separated to ease a potential implementation order, since its relatively straightforward without altering the header, but when altering the header many types change)
There was a problem hiding this comment.
its relatively straightforward without altering the header, but when altering the header many types change
This would be a great thing to note in the RFC body as well!
| fn PrepareProposal(Block, UnbatchedHeader) -> (BlockData, Header) | ||
| ``` | ||
|
|
||
| where `UnbatchedHeader` essentially contains a "RawCommit", the `Header` contains a batch-optimized `commit` and an additional "Application Data" field in its root. This will involve a number of changes to core data structures, which will be gone over in the ADR. |
There was a problem hiding this comment.
Just to verify my understanding here: the input currently UnbatchedHeader as well as the returned Header will be the actual type Header struct in block.go right?
If so, if you pass in the Block, why additionally pass in the UnbatchedHeader. Doesn't the Block contain the Header?
Also, I would suggest to rename the input to Header and the result to PreparedHeader. There might be cases where PrepareProposal doesn't do anything batching related. So the name should not suggest that this is (always) tied to batching.
There was a problem hiding this comment.
Re: Variable naming, I think thats a much better naming, will switch to that! Or perhaps would UnpreparedHeader, Header be a better choice, so that downstream folks don't have to be aware of preparing?
The UnpreparedHeader and PreparedHeader shouldn't be the same struct, as they have different fields for where application data goes. I guess its a design choice for whether to have one single struct with extra fields, but I'd rather opt for type safety for making us use the correct thing in the correct place.
Co-authored-by: Federico Kunze <31522760+fedekunze@users.noreply.github.com>
|
|
||
| Upon receiving an entire block proposal (in the current implementation, all "block parts"), every validator runs `ProcessProposal(block)`. If the returned `ResponseProcessProposal.accept_block` is false, then the validator must precommit nil on this block, and reject all other precommits on this block. `ResponseProcessProposal.evidence` is appended to the validators local `EvidencePool`. | ||
|
|
||
| Once a validator knows that consensus has failed to be achieved for a given block, it must run `RevertProposal(block.height, block.round)`, in order to signal to the application to revert any potentially mutative state changes it may have made. In Tendermint, this occurs when incrementing rounds. |
There was a problem hiding this comment.
Not sure we need this method. Can't application revert proposal if it doesn't receive FinalizeBlock, but instead gets VerifyHeader again (new round)?
There was a problem hiding this comment.
I agree. It is not clear when the revert should happen. If in the new round the same block (modulo time, round number) is proposed, we might not even need to revert. If the values of time and round are used to process a proposal then we have to redo.
However, if the round number is used in process proposal, this seems problematic anyway: we have the problem that in Tendermint two validators may decide in different rounds, and the "canonic" decision round is only fixed when the canonical commit is fixed in the next block. If the canonical commit is for a different round than my decision round, I might need to revert quite late. Not sure that this can be done in a sound way.
There was a problem hiding this comment.
This is a great point. A consequence of this is that immediate execution cannot happen safely if the execution depends on time or round number (/cc @liamsi )
I think it makes sense to remove RevertProposal for now then. Maybe it makes sense as an optimization under alternate consensus algorithms, but then it should be added in at that time.
There was a problem hiding this comment.
Can't application revert proposal if it doesn't receive FinalizeBlock, but instead gets VerifyHeader again (new round)?
Definitely agree.
immediate execution cannot happen safely if the execution depends on time or round number
Could you explain this a little more? Also, generally, immediate execution is not safe in the sense that your are applying state before consensus has been reached
There was a problem hiding this comment.
If the values of time and round are used to process a proposal then we have to redo.
Why would this be the case?
A consequence of this is that immediate execution cannot happen safely if the execution depends on time or round number
IMO, execution or rather computing the state root for inclusion in a proposed block, should only depend on included Tx.
Also, generally, immediate execution is not safe in the sense that your are applying state before consensus has been reached
It is not really applied (as in persisted in the state machine) when the block is proposed, the state root after applying the state transitions (txs) is included in the block with those Tx. The state machine actually applies and persisits the state after consensus still (it's only that the nodes reached consensus on the already updated state root as well).
Am I missing something obvious?
There was a problem hiding this comment.
I agree with @liamsi that the safe approach is that computing depend on Tx only. However, from discussions I had, my impression was that there are use-cases where round and/or time should also be used. I just wanted to raise that this adds complications.
We need to be precise and explicit about at what point processing is started/reverted/persisted. I don't think it is obvious, and different people might have slightly different ideas where/when this should happen.
There was a problem hiding this comment.
I am lost as to why round or time is needed here as well. It seems we can do away with the Revert API and solely rely on data that is not subject to subjectivity of validators (i.e. round and time).
There was a problem hiding this comment.
Right, but block execution can depend on the latest time, an example is timestamp based inflations, or smart contracts using the latest time.
I don't know of a use case for using the round number in the state machine though, so perhaps thats not needed.
There was a problem hiding this comment.
For these kinds of applications, would be the time of the previous block work as well?
There was a problem hiding this comment.
That should work if they adjust their time-based computation (e.g. inflation calculations) to occur at the beginning of the block rather than at the end.
| Upon receiving a block header, every validator runs `VerifyHeader(header, isValidator)`. The reason for why `VerifyHeader` is split from `ProcessProposal` is due to the later sections for Preprocess Proposal and Vote Extensions, where there may be application dependent data in the header that must be verified before accepting the header. | ||
| If the returned `ResponseVerifyHeader.accept_header` is false, then the validator must precommit nil on this block, and reject all other precommits on this block. `ResponseVerifyHeader.evidence` is appended to the validators local `EvidencePool`. | ||
|
|
||
| Upon receiving an entire block proposal (in the current implementation, all "block parts"), every validator runs `ProcessProposal(block)`. If the returned `ResponseProcessProposal.accept_block` is false, then the validator must precommit nil on this block, and reject all other precommits on this block. `ResponseProcessProposal.evidence` is appended to the validators local `EvidencePool`. |
There was a problem hiding this comment.
I though the idea was that ProcessProposal(block) runs concurrently with consensus? So I am not sure at what point the returned values interfere with consensus.
There was a problem hiding this comment.
It must return whether the block is valid or not before the final round of voting. (So it runs in parallel with prevoting, and must return prior to precommitting) This is to enable validity checks to occur on the tx data.
The application can have an async process that continues to run in parallel with consensus after this method has returned though.
|
|
||
| Upon receiving an entire block proposal (in the current implementation, all "block parts"), every validator runs `ProcessProposal(block)`. If the returned `ResponseProcessProposal.accept_block` is false, then the validator must precommit nil on this block, and reject all other precommits on this block. `ResponseProcessProposal.evidence` is appended to the validators local `EvidencePool`. | ||
|
|
||
| Once a validator knows that consensus has failed to be achieved for a given block, it must run `RevertProposal(block.height, block.round)`, in order to signal to the application to revert any potentially mutative state changes it may have made. In Tendermint, this occurs when incrementing rounds. |
There was a problem hiding this comment.
I agree. It is not clear when the revert should happen. If in the new round the same block (modulo time, round number) is proposed, we might not even need to revert. If the values of time and round are used to process a proposal then we have to redo.
However, if the round number is used in process proposal, this seems problematic anyway: we have the problem that in Tendermint two validators may decide in different rounds, and the "canonic" decision round is only fixed when the canonical commit is fixed in the next block. If the canonical commit is for a different round than my decision round, I might need to revert quite late. Not sure that this can be done in a sound way.
Co-authored-by: Ismail Khoffi <Ismail.Khoffi@gmail.com>
There was a problem hiding this comment.
Most of these comments are just to help my understanding. I find this work really interesting!!!
It seems that an overarching question I have about this is how it changes what Tendermint is responsible for verifying and what the application is responsible for verifying. I think this should be made very explicit.
| } | ||
| ``` | ||
|
|
||
| Upon receiving a block header, every validator runs `VerifyHeader(header, isValidator)`. The reason for why `VerifyHeader` is split from `ProcessProposal` is due to the later sections for Preprocess Proposal and Vote Extensions, where there may be application dependent data in the header that must be verified before accepting the header. |
There was a problem hiding this comment.
It's still not clear to me why you have split up these functions? When will VerifyHeader() be used (that's not when we do ProcessProposal() )
There was a problem hiding this comment.
The block header is received before the entirety of the block data. IIRC, the flow at the moment is you receive the block header, then you verify the commit, and then acquire block parts.
However verifying the commit's application data requires an ABCI request.
There was a problem hiding this comment.
At the moment, you receive the proposal which contains the BlockID.PartSetHeader containing all the information about the block parts. You set this and wait until you receive all the block parts. You build the block and validate all the contents all at once. It then gets stored as cs.ValidBlock and the state machine moves to enterPrevote to prevote on it.
I think we could sync up on this though. I've had the idea for some time that we should restructure how the block is sent across i.e. we can still break it down into parts but send the header (and possibly the commit and evidence) as one complete part (sent first) and the txs split across into the remaining parts.
Bucky first mentioned this in an issue somewhere. I believe it might have been when we talked about removing validator address from the commit sigs
This would allow us to deduplicate some of the bytes that get sent and saved as well as break up BlockID (into just the hash of the header).
There was a problem hiding this comment.
Oh so is the commit for the prior block not verified until you've already gotten the entire block? That seems like a potential DOS concern.
Happy to sync up on this! I've spent a bit of time analyzing the different erasure encoding schemes for block gossip protocols in the past, which may be useful to consider in any API redesigns here.
There was a problem hiding this comment.
Oh so is the commit for the prior block not verified until you've already gotten the entire block?
I believe so
| ``` | ||
|
|
||
| Upon receiving a block header, every validator runs `VerifyHeader(header, isValidator)`. The reason for why `VerifyHeader` is split from `ProcessProposal` is due to the later sections for Preprocess Proposal and Vote Extensions, where there may be application dependent data in the header that must be verified before accepting the header. | ||
| If the returned `ResponseVerifyHeader.accept_header` is false, then the validator must precommit nil on this block, and reject all other precommits on this block. `ResponseVerifyHeader.evidence` is appended to the validators local `EvidencePool`. |
There was a problem hiding this comment.
To me this implies that applications can now add evidence to the consensus engine which will then be committed in blocks. I think this should be made more explicit alongside with what are the advantages / use cases of it.
There was a problem hiding this comment.
Also, why can evidence be added in both VerifyHeader and ProcessProposal? Is one not sufficient? (Probably this demonstrates my lack of understanding about what exactly is happening 😄 )
There was a problem hiding this comment.
What is the evidence? An invalid header and invalid proposal?
There was a problem hiding this comment.
Oh, I see. There is no guarantee that it will get committed into blocks, I'll try to clarify the text for this.
The usecase is essentially if an application wants to slash a proposer who proposes something invalid that the network should never agree upon. (This makes sense when the application wants to guarantee extremely high throughput, and considers getting in the way of this a slashable offence)
The actual evidence is left for the application to construct, and theres multiple designs they could do. (If they had a VM execution model, then the standard watchtower like fault detection / proof suffices. Otherwise, they can fall back to more of an economic security type slash. E.g. have each validator produce a signature on this evidence claiming its bad along with the node whose at fault, and if theres a sufficient number of signatures, then slash the corresponding proposer)
There was a problem hiding this comment.
Opened a discussion here if we wish to continue: #263
|
|
||
| Upon receiving an entire block proposal (in the current implementation, all "block parts"), every validator runs `ProcessProposal(block)`. If the returned `ResponseProcessProposal.accept_block` is false, then the validator must precommit nil on this block, and reject all other precommits on this block. `ResponseProcessProposal.evidence` is appended to the validators local `EvidencePool`. | ||
|
|
||
| Once a validator knows that consensus has failed to be achieved for a given block, it must run `RevertProposal(block.height, block.round)`, in order to signal to the application to revert any potentially mutative state changes it may have made. In Tendermint, this occurs when incrementing rounds. |
There was a problem hiding this comment.
Can't application revert proposal if it doesn't receive FinalizeBlock, but instead gets VerifyHeader again (new round)?
Definitely agree.
immediate execution cannot happen safely if the execution depends on time or round number
Could you explain this a little more? Also, generally, immediate execution is not safe in the sense that your are applying state before consensus has been reached
rfc/004-abci++.md
Outdated
|
|
||
| The application is expected to cache the block data for later execution. | ||
|
|
||
| The `isValidator` flag is set according to whether the current node is a validator of a full node. This is intended to allow for beginning validator dependent computation that will be included later in vote extensions. (An example of this is threshold decryptions of ciphertexts) |
There was a problem hiding this comment.
Probably not too important, but I would imagine the application already knows who the validators are (and if it is a validator) as it needs to keep track for validator updates and staking and so forth
There was a problem hiding this comment.
At least at the moment, I don't think the application knows if this node is a validator, since I'm not aware of it being given the consensus public key over ABCI
There was a problem hiding this comment.
Right, well ABCI needs to have access to all the validators public keys else how does it update validator power in ResponseEndBlock
type ValidatorUpdate struct {
PubKey crypto.PublicKey `protobuf:"bytes,1,opt,name=pub_key,json=pubKey,proto3" json:"pub_key"`
Power int64 `protobuf:"varint,2,opt,name=power,proto3" json:"power,omitempty"`
}
I guess the application might hide whether the particular node corresponds to one of these validators
| where `ResponseFinalizeBlock` has the following API, in terms of what already exists | ||
|
|
||
| ```rust | ||
| struct ResponseFinalizeBlock { |
There was a problem hiding this comment.
We should also include retainHeight here (or add it to the ResponseEndBlock / ConsensusEngineUpdates)
There was a problem hiding this comment.
And perhaps also app hash for our folks who want to remain with delayed execution models 😄
There was a problem hiding this comment.
What is retainHeight?
Agreed for AppHash
There was a problem hiding this comment.
It's to tell tendermint which blocks to keep and which can be deleted:
retain_height: Blocks below this height may be removed. Defaults to 0 (retain all).
https://docs.tendermint.com/master/spec/abci/abci.html#commit
See also: https://github.com/tendermint/tendermint/blob/master/UPGRADING.md#block-retention
But I do not know much more either 😬
There was a problem hiding this comment.
yeah that's a pretty accurate description. Tendermint will just prune blocks below that height
There was a problem hiding this comment.
I'll add it accordingly! Is this node local (e.g. generated from their app.toml), or is part of the honesty assumption that a node satisfies this?
| fn PrepareProposal(Block, UnbatchedHeader) -> (BlockData, Header) | ||
| ``` | ||
|
|
||
| where `UnbatchedHeader` essentially contains a "RawCommit", the `Header` contains a batch-optimized `commit` and an additional "Application Data" field in its root. This will involve a number of changes to core data structures, which will be gone over in the ADR. |
There was a problem hiding this comment.
Who will validate the batch optimized commit? Tendermint or the application?
There was a problem hiding this comment.
Is the Application Data field just the app hash or does it allow for arbitrary inclusion of other information?
There was a problem hiding this comment.
The RawCommit is the equivalent to the LastCommit right?
There was a problem hiding this comment.
Both Tendermint and the application have to validate components of the batch-optimized commit.
Tendermint will verify each of the signatures on the votes, whereas the application will verify the validity of the vote extensions.
The application data allows for arbitrary inclusion of other application information in the header. (This is actually useful even without vote extensions, e.g. for LazyLedger intermediate state roots)
RawCommit will be equivalent to the the LastCommit
|
|
||
| ```rust | ||
| fn ExtendVote(height: u64, round: u64) -> (UnsignedAppVoteData, SelfAuthenticatingAppData) | ||
| fn VerifyVoteExtension(signed_app_vote_data: Vec<u8>, self_authenticating_app_vote_data: Vec<u8>) -> bool |
There was a problem hiding this comment.
Are vote extensions expected to affect application state?
There was a problem hiding this comment.
Not when they are created, but yes for when they are included in the header. E.g. if they are self-authenticating, an application may not want them in the header but instead within the block data. This is the case for threshold decryption.
There was a problem hiding this comment.
when they are included in the header
Right but this is will be included in the following header then?
There was a problem hiding this comment.
Yes they will be included in the following header. (But they may be batch optimized due to ProcessProposal)
rfc/004-abci++.md
Outdated
|
|
||
| ### Vote Extensions | ||
|
|
||
| Vote Extensions allow applications to force their validators to do more than just validate within consensus. This is done by allowing the application to add more data to their votes, in the final round of voting. (Namely the precommit) |
There was a problem hiding this comment.
We should be wary about how this may affect timeouts in consensus
There was a problem hiding this comment.
Agreed, I think this new delay is 1 IPC round trip delays + application vote extension time.
Should we add knobs for the application to indicate how long they expect the vote extensions should take in ms?
AFAIU, consensus timeouts aren't super tuned, like they are currently set as an estimate of whats reasonable, but aren't all consistently based on parameters like IPC overhead, gossip delay, application execution time. (Though we are probably going a bit in this direction for variable block time)
There was a problem hiding this comment.
Nice work! Thanks for working on this.
I left a bunch of comments inline, largely motivated by trying to make this as straight-forward as possible before we start sharing it with the broader community and asking for comment.
In that vein, it could also be nice to have a summary of all the calls in order, especially interspersed with which voting phase/part of the consensus round they're in.
Also - you mention a separate ADR for data structures - I think that should also go in this repo! We're trying to get data structure specifications in this shared repo as well
|
|
||
| We include a more detailed list of features / scaling improvements that are blocked, and which new phases resolve them at the end of this document. | ||
|
|
||
| <image src="images/abci.png" style="float: left; width: 40%;" /> <image src="images/abci++.png" style="float: right; width: 40%;" /> |
There was a problem hiding this comment.
Maybe a silly question, but why are there three new phases and four new arrows?
There was a problem hiding this comment.
Its because now Tendermint has to do a query to the application to verify the additional application data in a vote. However, its kind of odd to call that a new phase, since its a part of 'vote extension'
rfc/004-abci++.md
Outdated
|
|
||
| *Note, APIs in this section will change after Vote Extensions, we list the adjusted APIs further in the proposal.* | ||
|
|
||
| Prepare proposal allows the block proposer to perform application-dependent work in a block, to lower the amount of work the rest of the network must do. batch optimizations to a block, which is a key optimization for scaling. This introduces the following method |
There was a problem hiding this comment.
| Prepare proposal allows the block proposer to perform application-dependent work in a block, to lower the amount of work the rest of the network must do. batch optimizations to a block, which is a key optimization for scaling. This introduces the following method | |
| PrepareProposal allows the block proposer to perform application-dependent work in a block, to lower the amount of work the rest of the network must do. batch optimizations to a block, which is a key optimization for scaling. This introduces the following method |
(Or otherwise standardize the way that these function names are used in this section)
There was a problem hiding this comment.
Also, there's a sentence fragment in the middle of this paragraph
|
|
||
| Prepare proposal allows the block proposer to perform application-dependent work in a block, to lower the amount of work the rest of the network must do. batch optimizations to a block, which is a key optimization for scaling. This introduces the following method | ||
|
|
||
| ```rust |
There was a problem hiding this comment.
Sooooo... not to be That Person, but the rest of our RFCs use Go syntax for things like this. This particular example is pretty straightforward, but there's some stuff in Rust syntax that isn't obvious to non-Rust programmers (e.g., Vec or usize). How would you feel about either sticking to Go syntax or putting them side-by-side?
Or even in proto? I think all ABCI methods/types need to ultimately be specified in proto, right?
There was a problem hiding this comment.
Happy to switch this to go :)
|
|
||
| Prepare proposal allows the block proposer to perform application-dependent work in a block, to lower the amount of work the rest of the network must do. batch optimizations to a block, which is a key optimization for scaling. This introduces the following method | ||
| ```rust | ||
| fn PrepareProposal(Block) -> BlockData |
There was a problem hiding this comment.
its relatively straightforward without altering the header, but when altering the header many types change
This would be a great thing to note in the RFC body as well!
| For brevity in exposition above, we did not discuss the trade-offs that may occur in interprocess communication delays that these changs will introduce. | ||
| These new ABCI methods add more locations where the application must communicate with the consensus engine. | ||
| In most configurations, we expect that the consensus engine and the application will be either statically or dynamically linked, so all communication is a matter of at most adjusting the memory model the data is layed out within. | ||
| This memory model conversion is typically considered negligible, as delay here is measured on the order of microseconds at most, whereas we face milisecond delays due to cryptography and network overheads. |
There was a problem hiding this comment.
We should probably do some performance benchmarking here and make sure that the ABCI++ implementation will be comparably performant to the current implementation.
There was a problem hiding this comment.
We definitely should, though these IPC concerns at least don't come up in the current case where Tendermint and the SDK are ran in process.
I think they'd only come up and be of concern if people used non-golang state machines and did not want to deal with linking the binaries. (Or conversely, used tendermint-rs and didn't want to statically link the binary)
When statically /dynamically linked, the overheads are typically pretty negligible, though should be checked empirically. (e.g. slowest cgo function call overhead I could find was 200ns, can't find benchmarks for converting the memory models unfortunately)
| This requires a round of IPC communication, where both directions are quite large. Namely the proposer communicating an entire block to the application. | ||
| However, this can be mitigated by splitting up `PrepareProposal` into two distinct, async methods, one for the block IPC communication, and one for the Header IPC communication. | ||
|
|
||
| Then for chains where the block data does not depend on the header data, the block data IPC communication can proceed in parallel to the prior block's voting phase. (As a node can know whether or not its the leader in the next round) |
There was a problem hiding this comment.
This parallelism smells like a recipe for a race condition. We'll need to be careful here.
There was a problem hiding this comment.
Agreed, this being important only depends on IPC overhead being high. (I still don't really see a reason to ever run tendermint and the app out of process, since you can statically link them)
|
|
||
| - Enables a large number of new features for applications | ||
|
|
||
| ### Negative |
There was a problem hiding this comment.
I'd add one more negative here:
I anticipate that things like alternate execution models will lead to a proliferation of new ways for applications to mess things up. Consider how many times we already have users send us consensus errors that stem from non-deterministic applications, for example.
Creating more flexibility here will enable a large number of new features, but it will also enable a large number of new ways for things to go wrong.
I think that tradeoff is probably worth it, but we'll want to be able to help users debug issues in their applications. Specifically, we'll want an easy way to tell if a problem is a bug in Tendermint consensus or just an issue in the way that the application is using ABCI. We already have tooling like tendermint debug which is instrumental in diagnosing user issues; I wonder if ABCI++ will necessitate (or benefit from) expansions to that tooling.
There was a problem hiding this comment.
There were some discussions in the past around writing a test suite to ensure application compliance to ABCI expectations. (Especially around tx replay protection, which we kept on getting user issues about the time) I wonder if we something along those lines that tries to test expected guarantees would help
|
|
||
| - Enables a large number of new features for applications | ||
|
|
||
| ### Negative |
There was a problem hiding this comment.
Oh, and one more potential negative - requiring applications to revert state may require them to use data stores that have ACID guarantees/transactions/some way to rollback changes. I think many applications do not do this at the moment.
| - Dev (@valardragon) | ||
| - Sunny (@sunnya97) | ||
|
|
||
| ## Context |
There was a problem hiding this comment.
The context should make note of what the new (renamed?) Finalize Block step indicates. It should probably also make note of what happens to the old phases (prevote & precommit).
There was a problem hiding this comment.
Prevote and precommit aren't phases over ABCI. (ABCI doesn't know anything about them)
I'll add comments for Finalize block!
| Prepare proposal allows the block proposer to perform application-dependent work in a block, to lower the amount of work the rest of the network must do. batch optimizations to a block, which is a key optimization for scaling. This introduces the following method | ||
|
|
||
| ```rust | ||
| fn PrepareProposal(Block) -> BlockData |
There was a problem hiding this comment.
I'm a bit confused by this section. What is BlockData? Does it come from the app based on a given Block input? What does the structure look like? Is it extensible?
| ``` | ||
|
|
||
| Upon receiving a block header, every validator runs `VerifyHeader(header, isValidator)`. The reason for why `VerifyHeader` is split from `ProcessProposal` is due to the later sections for Preprocess Proposal and Vote Extensions, where there may be application dependent data in the header that must be verified before accepting the header. | ||
| If the returned `ResponseVerifyHeader.accept_header` is false, then the validator must precommit nil on this block, and reject all other precommits on this block. `ResponseVerifyHeader.evidence` is appended to the validators local `EvidencePool`. |
There was a problem hiding this comment.
What is the evidence? An invalid header and invalid proposal?
|
|
||
| Upon receiving an entire block proposal (in the current implementation, all "block parts"), every validator runs `ProcessProposal(block)`. If the returned `ResponseProcessProposal.accept_block` is false, then the validator must precommit nil on this block, and reject all other precommits on this block. `ResponseProcessProposal.evidence` is appended to the validators local `EvidencePool`. | ||
|
|
||
| Once a validator knows that consensus has failed to be achieved for a given block, it must run `RevertProposal(block.height, block.round)`, in order to signal to the application to revert any potentially mutative state changes it may have made. In Tendermint, this occurs when incrementing rounds. |
There was a problem hiding this comment.
I am lost as to why round or time is needed here as well. It seems we can do away with the Revert API and solely rely on data that is not subject to subjectivity of validators (i.e. round and time).
rfc/004-abci++.md
Outdated
|
|
||
| Once a validator knows that consensus has failed to be achieved for a given block, it must run `RevertProposal(block.height, block.round)`, in order to signal to the application to revert any potentially mutative state changes it may have made. In Tendermint, this occurs when incrementing rounds. | ||
|
|
||
| RFC: How do we handle the scenario where honest node A finalized on round x, and honest node B finalized on round x + 1? (e.g. when 2f precommits are publicly known, and a validator precommits themself but doesn't broadcast, but they increment rounds) Is this a real concern? The state root derived could change if everyone finalizes on round x+1, not round x, as the state machine can depend non-uniformly on timestamp. |
There was a problem hiding this comment.
I'm lost as to why this even matters. Why would a node have to revert if it finalized at a different round? Why is that part of the state root?
rfc/004-abci++.md
Outdated
| } | ||
| ``` | ||
|
|
||
| `ResponseEndBlock` should then be renamed to `ConsensusEngineUpdates` and `ResponseDeliverTx` should be renamed to `ResponseTx`. |
There was a problem hiding this comment.
I believe ResponseEndBlock already exists and would use those existing fields. Also, ConsensusEngineUpdates is a mouthful. Can we just use ConsensusUpdates?
rfc/004-abci++.md
Outdated
| ``` | ||
|
|
||
| There are two types of data that the application can enforce validators to include with their vote. | ||
| There is data that the app needs the validator to sign over in their vote, and there can be self-authenticating vote data. Self-authenticating here means that the application upon seeing these bytes, knows its valid, came from the validator and is non-malleable. |
|
|
||
| where `BlockData` is a type alias for however data is internally stored within the consensus engine. In Tendermint Core today, this is `[]Tx`. | ||
|
|
||
| The application may read the entire block proposal, and mutate the block data fields. Mutated transactions will still get removed from the mempool later on, as the mempool rechecks all transactions after a block is executed. |
There was a problem hiding this comment.
Do the mutated transactions replace the original transactions in the proposer's copy of mempool?
There was a problem hiding this comment.
Good question: would this also mean that txs need to be tracked with an id? (forgive me if they already do)
There was a problem hiding this comment.
If I am not wrong this function is supposed to change the representation of the []Tx, but not the semantic of it. So given []Tx as an input there are functions f and g, such that g(f([]Tx)) = []Tx, i.e., f will be executed by the proposer and g by other validators to verify it. Is this correct or there is something more?
There was a problem hiding this comment.
Its exactly how you are proposing it zarko!
The proposer's mempool removes those txs just as it does right now. (Nothing new is added to it)
There was a problem hiding this comment.
This is under the assumption that nodes have recheck enabled, right? If the tx is mutated it won't be evicted from the mempool when the block is finalized.
There was a problem hiding this comment.
Yes it does assume that, though our mempool's inclusion guarantees get pretty wonky for people sending multiple txs without that.
(Also its only just not going to be caught in the quick linear pass for eviction)
Eventually it may be worth having the checkTx response provide a tx hash thats only based upon the witness, and then tracking tx equivalency based upon that. (This is in line with rollups do AFAIK)
rfc/004-abci++.md
Outdated
|
|
||
| *Note, APIs in this section will change after Vote Extensions, we list the adjusted APIs further in the proposal.* | ||
|
|
||
| Prepare proposal allows the block proposer to perform application-dependent work in a block, to lower the amount of work the rest of the network must do. batch optimizations to a block, which is a key optimization for scaling. This introduces the following method |
There was a problem hiding this comment.
Although PrepareProposal looks relatively innocent, it looks like a faulty proposer may trigger all validators to do plenty of computations. So imagine that I am a faulty proposer and I extend the block data in a way that ProcessProposal fails in the end of processing. I don't have a concrete scenario here, maybe it is all resolved by signatures.
As a result, all validators have to go through the block processing cycle, only to find that the block cannot be accepted. In this case, the only validator to hold accountable is the faulty proposer. I hope that I have overlooked something here. Is there any protection mechanism against malicious proposers that misuse PrepareProposal?
There was a problem hiding this comment.
I think this is all resolved by signatures. The proposer today can already propose whatever bytes they want. It is up to other nodes in the network to parse that these bytes are valid. So PrepareProposal is effectively already available to an adversarial block proposer today. Its just not available for the honest case.
If you mean that if other nodes expect a batch optimization (e.g. signature aggregation) and the proposer doesn't do it, what do they do? In that case they should reject the proposal (and potentially slash that proposer depending on economics desired). They can reject pretty quickly, since this is a parsing / signature verification problem.
There was a problem hiding this comment.
The proposed RFC is good for understanding the motivation for the extensions. I feel that the document appeals to the intuition about the internals of the implementation, which I am lacking. I find it quite hard to understand the computation boundaries and synchronization points of different processes and threads. Given the other comments, it would be great to have more details about the envisioned protocol. To move the discussion forward, I feel that we need a bit more detailed state diagram than the diagram in the RFC.
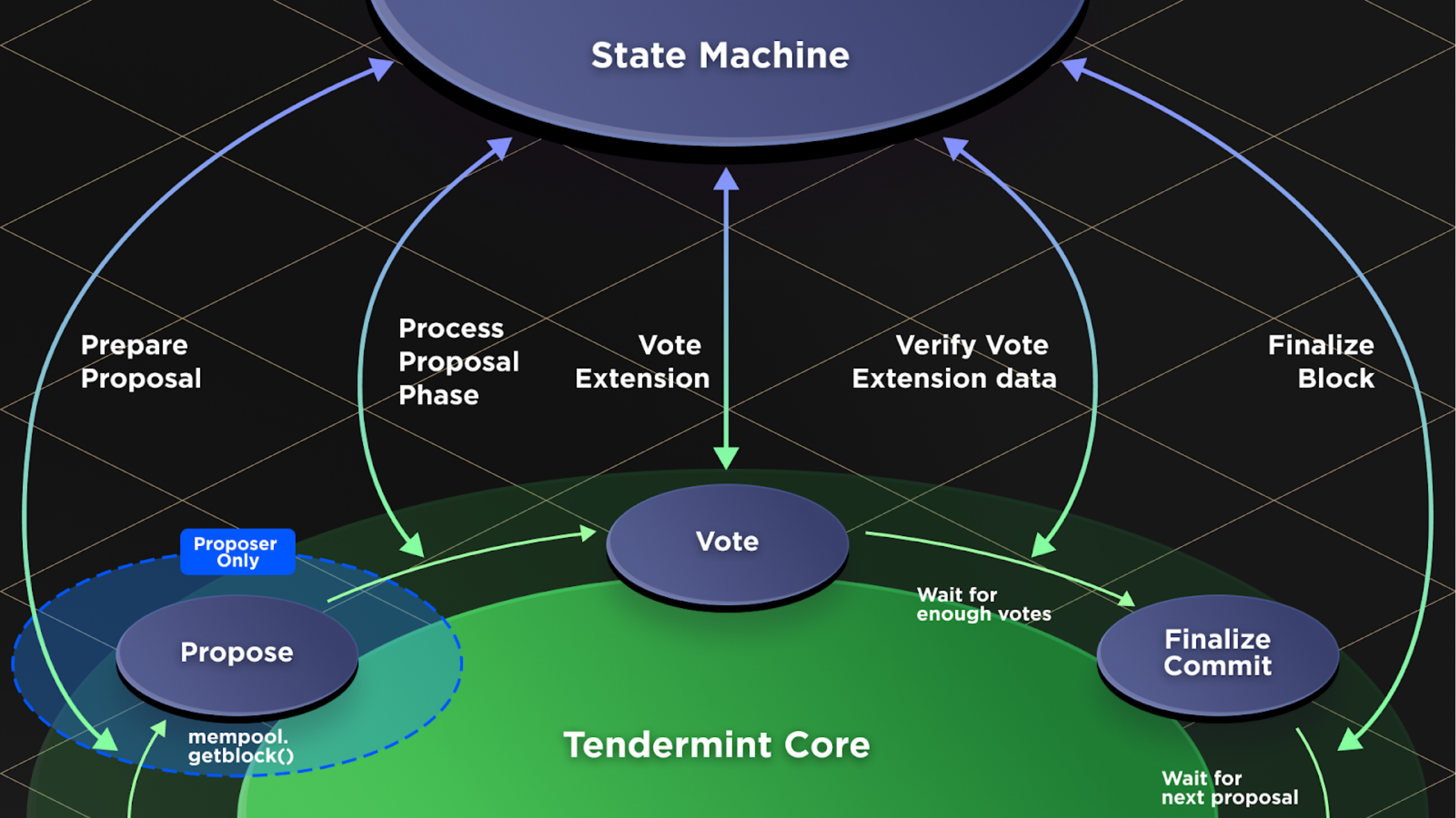{kind=link}
Is the following UML statechart any close to your idea of ABCI++? I did not use RevertProposal in this diagram, as it seems to cause too many problems. The horizontal bars mean thread forks and joins. I assumed that the ProcessProposal thread joins the main thread before PRECOMMIT is sent, which is my interpretation of:
{kind=link}
Process proposal sends the block data to the state machine, prior to running
the last round of votes on the state machine.
In this diagram, one validator avoids running several ProcessProposal threads for different rounds (the case of round catch up and timeouts is less clear). Does it reflect the intention behind your RFC?
|
Incredibly sorry about the delayed response all. I was very behind on notifications, and then had no power most of last week 😅 I now have much more time to be actively dedicating to ABCI++. |
Co-authored-by: Tess Rinearson <tess.rinearson@gmail.com>
Co-authored-by: Tess Rinearson <tess.rinearson@gmail.com>
|
Update per calls over the last two days The plan for the RFC is to keep updating this until all relevant parties (Informal, Interchain Gmbh, LazyLedger, Sikka) have a shared state on the ABCI++ and agree that it should suffice. For proceeding with ABCI++'s changes, Informal will be working on a spec, while Sikka in parallel will work on writing up the use cases in depth and how they interact with ABCI phases / existing Tendermint components. Sometime (likely after progress has happened on those two fronts), work on the ADR / implementation would begin. Onto changes for the actual RFC:
|
|
This pull request has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions. |
|
not stale |
|
@ValarDragon can we get this across the finish line? would like to unblock Informal and move to implementation. Tendermint mempool refactor also waiting on this. |
|
|
||
| The application may read the entire block proposal, and mutate the block data fields. Mutated transactions will still get removed from the mempool later on, as the mempool rechecks all transactions after a block is executed. | ||
|
|
||
| The `PrepareProposal` API will be modified in the vote extensions section, for allowing the application to modify the header. |
There was a problem hiding this comment.
I am not sure to understand this sentence.
|
In my view RFC’s purpose is to signal the need for some change/feature and this RFC does that job really well. Next step in my view is writing spec and ADR to discuss implementation details. Re spec, we have agreed with Dev to start from Tendermint protocol presented in arxiv paper and add incrementally changes needed. So we expect having several versions of the spec that will add features one by one. We expect @ValarDragon to come up with a first rough version and we will iterate from there. So I would suggest to merge this PR and move forward with the spec, and potentially ADR, although ADR might depend on the spec changes. |
This is an RFC for ABCI++, based upon the talk given at interchain conversations. It proposes 3 new phases, Prepare Proposal, Process Proposal, and Vote Extensions, along with a rename of BeginBlock, DeliverTx, EndBlock to FinalizeBlock.
There are a few RFC's in the file, I'll add GH comments to flag them.
I'm working on ADR in parallel for how Vote Extensions would change the core go-tendermint data structures