Why add positional embedding instead of concatenate? #1591
Comments
|
Interesting questions with no simple answers. Just a few comments:
|
|
Hey, thanks for the detailed reply. When WE are learnable parameters, I agree that the transformer training might model them such that the information of WE and PE is preserved (recoverable by transformer) even after addition. Like you suggested, maybe the transformer might also learn useful features from the addition of WE and PE. However, my original doubt still persists. Why not just concatenate? Like you suggested, we can add a projection layer to bring the input dimension to transformer hidden size. The advantage of an additional layer is that is can model more complicated relationships b/w WE and PE (including simple addition obviously). However, this advantage comes at the cost of additional parameters, which in most cases is a trivial increment to memory consumption, given the size of a (practical) transformer. |
|
If you find a good answer for not contaminating can you please refer to it in here. |
|
While we're discussing the relative merits of "concat then project to D" or "project to D and sum", couldn't we go one step further and decide the mixture of WE and PE via attention? Each projects keys and values, query is projected from global context or from WE. |
|
Perhaps because theses sums form a cloud around a point in word embedding carrying information about position occurrences. Think, for example, of the an word in a 1D embedding and suppose that words are evenly spaced: 1.0, 2.0, 3.0, ... If you sum a sequence of equally spaced small numbers that represent distances from sequence beginning to one of them, let's say, 0.01, 0.02, 0.03, ..., you'll have a cluster of position information around the number that encodes the word. For instance, 1.01, 1.02, 1.05, ..., encode the same word in different positions. If the granularity of the encodings is different you can get such result. |
|
Is anyone aware of any papers where they concatenated positional embeddings instead of adding them? I'm wondering if anyone has even tried it. |
|
Check out DeBERTA which disentangle the position and content embeddings. This seems like an explicit inductive bias that content and (relative) position should be treated differently--have explicitly separate weight matrices for projection. |
|
This is a really good description IMO |
|
Just wanted to put this content here for some mathematical context also: https://enccs.github.io/gnn_transformers/notebooks/session_1/1b_vector_sums_vs_concatenation/ |
|
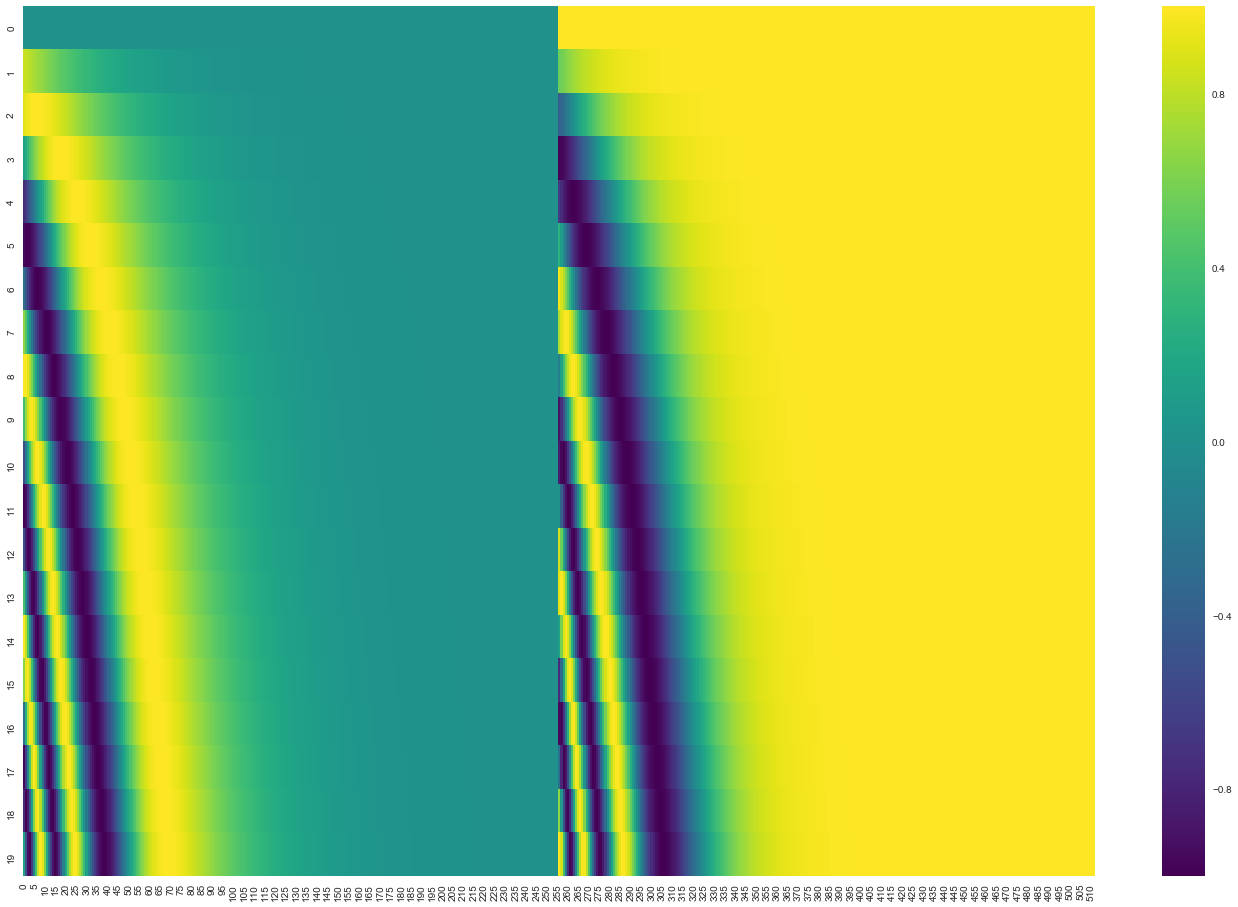
The following is informed conjecture, not proven fact. If you look at how much each scalar in the the positional embedding vector changes as a function of position... you'll find that many of the scalars barely change at all. You can visualize this with any positional embedding plot, where the x axis is usually the [512] length of the scalar, and the y axis is the position. For example, this image is from Jay Alammar's well regarded "The Illustrated Transformer"
Let's try to do this mathematically as well. The implementation of PE's that Jay references is at this Google GitHub repo: https://github.com/tensorflow/tensor2tensor/tree/23bd23b9830059fbc349381b70d9429b5c40a139 Running the function on a PE/WE of length 512 and max sentence length of 128, let's look at how much the final value in the vector actually changes from the first position, to the 64th position, to the final position. Answer: not much. Ditto for a value 16 steps away from the final location: I saw elsewhere that BERT's WEs are typically roughly the range of [-2, 2], so adding a 0.007 delta from the PE would not move the WE very much at the -16th position. So what I think is probably happening is that only ~256 of the PE vector's values are actually moving around as a function of the position... the rest are ~constant. Then the learned WE (Transformers don't use prelearned WE like word2vec or glove), figures out to only use the other ~256 elements. So really... it's conceptually a concat. notebook here https://colab.research.google.com/drive/14RGALTsPIYGAuIByXGutK-aYN-PikWzF |

Apart from saving some memory, is there any reason we are adding the positional embeddings instead of concatenating them. It seems more intuitive concatenate useful input features, instead of adding them.
From another perspective, how can we be sure that the Transformer network can separate the densely informative word embeddings and the position information of pos encoding?
The text was updated successfully, but these errors were encountered: