Memory leak when using py_function inside tf.data.Dataset #35084
Comments
|
@ravikyram Yes, exactly, the memory is increasing quickly. |
|
@kkimdev this seems related to your work on properly garbage collecting traced functions that go out of scope ... could you please take a look? thank you |
|
List of leaking objects per 100 iterations: Leaking So seems like the problem is py_function getting created every loop and |
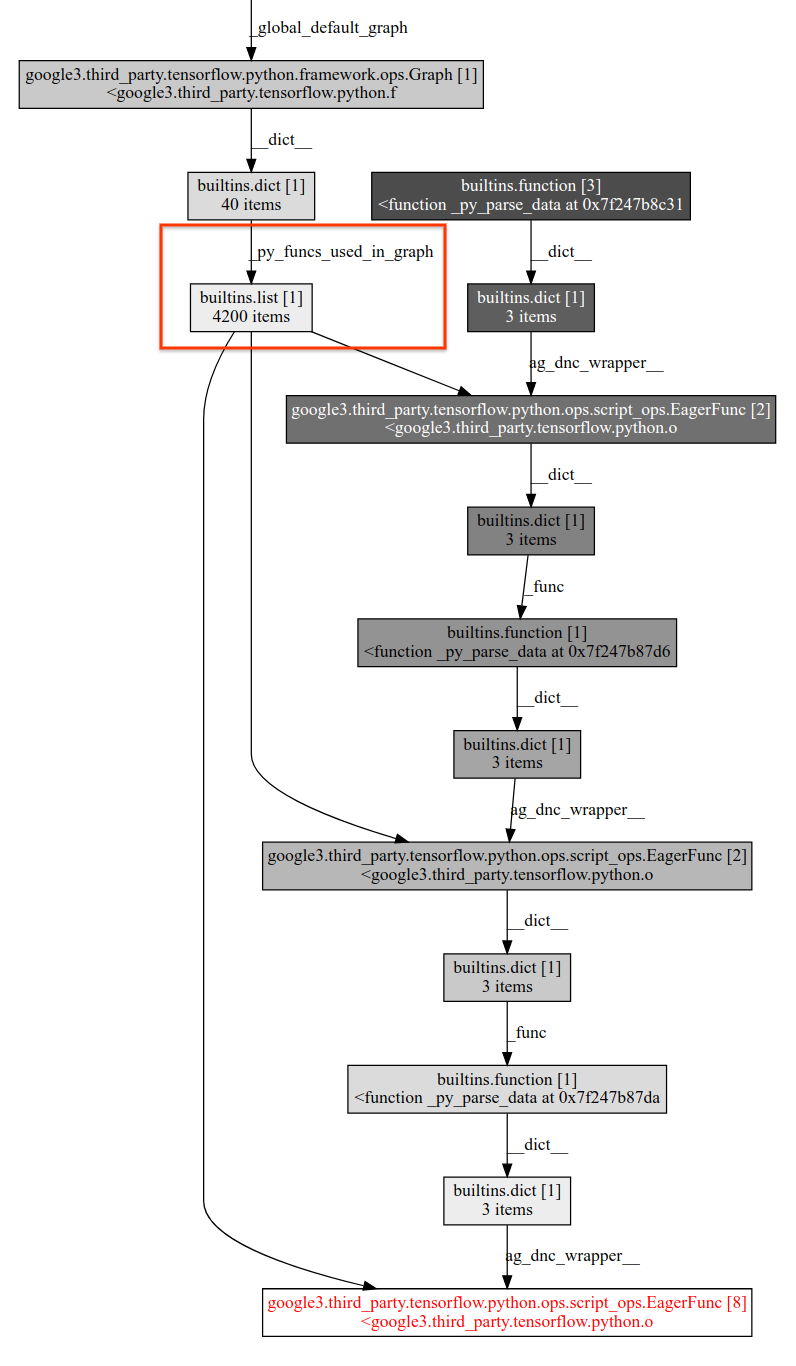
|
Thanks Kibeom. So the problem is that |
Eager mode can incorrectly have a global graph. Disabling global graph on eager mode breaks too many assumptions so first introduce a flag indicating it. Also, avoid attaching py_function to eager mode global graph, which is a leak. Though this CL doesn't fix the leak yet as there are two more references that leads to the leak, `tape_cache` and `ag_dnc_wrapper__` . #35084 PiperOrigin-RevId: 288415011 Change-Id: Ica53e29521320af22c10609857d0a0219a9596ce
|
Actually, there shouldn't be a global graph at the first place since this is eager mode. With 3b74a63 , it should be correctly attached to a func graph's Though still there are two more causes for this leak, @mdanatg fyi |
Eager mode can incorrectly have a global graph. Disabling global graph on eager mode breaks too many assumptions so first introduce a flag indicating it. Also, avoid attaching py_function to eager mode global graph, which is a leak. Though this CL doesn't fix the leak yet as there are two more references that leads to the leak, `tape_cache` and `ag_dnc_wrapper__` . #35084 PiperOrigin-RevId: 288728035 Change-Id: I27c254de4323e3fcac9966294e624dda61f91cd2
|
@kkimdev @jsimsa hello, we are having the same problem with TF 1.14. results = tf.py_function(
self.safe_load,
[audio_descriptor, offset, duration, sample_rate, dtype],
(tf.float32, tf.bool)),
waveform, error = results[0]putting this into a dataset = dataset.map(
lambda sample: dict(
sample,
**audio_adapter.load_tf_waveform(
sample['audio_id'],
session=session,
sample_rate=sample_rate,
offset=sample['start'],
duration=sample['end'] - sample['start'])),
num_parallel_calls=2)and getting a leak, where the memory leaked is the size of the wave file being loaded: after prediction traced memory: 28670 KiB peak: 28673 KiB overhead: 29677 KiB
after load traced memory: 28801 KiB peak: 28808 KiB overhead: 29755 KiB
after prediction traced memory: 53988 KiB peak: 55396 KiB overhead: 54529 KiB
after load traced memory: 54100 KiB peak: 55396 KiB overhead: 54604 KiB |
|
@loretoparisi do you also create the dataset in a for loop or do you instantiate it only once ? I am asking because I suspect a memory leak as well, but I am only creating one dataset object and then training on it using fit. I would also be interested in the script you used to get the last lines of your post. |
|
@zaccharieramzi yes sure. The source file, that you can even try yourself in the project is here: https://github.com/deezer/spleeter/blob/master/spleeter/dataset.py |
|
@loretoparisi I am sorry but I am not sure I understand how to use the file you linked to generate the memory leak evidence. I also don't see how it answers the question of whether you create datasets in a loop (i.e. call to |
The memory leak comes out when you run the framework over more samples, but yes it's complex to test it since it's a specific tool (audio separation). |
|
Ok gotcha, but so you don't instantiate the dataset in a loop? |
|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you. |
|
Closing as stale. Please reopen if you'd like to work on this further. |
…quested. The memory leak test added for #35084 in tf.data still passes. I renamed the confusing argument name eager= to use_eager_py_func=. The argument has little to do with eager mode; it only controls for which C++ op to use. There may be a better way of fixing this. A few things to consider on top of this CL: - can we record the data actually to the tape instead of in our own cache? it feels like it is doable, but it is not so clear to me how to do this. PiperOrigin-RevId: 398261944 Change-Id: I941bd9f7032ddfab209db161475c78068a17cc52
System information
Describe the current behavior
Describe the expected behavior
The tf.data.Dataset instance should be freed in every step.
Code to reproduce the issue
The text was updated successfully, but these errors were encountered: