in nmt_with_attention, the gru in decoder is not connected, last step state is not passed to this step #38248
Comments
|
Hello, I'd like to work on this issue. Can you plz give me some pointers on where I should start? |
|
I think you're right. @ManishAradwad if you want to take a shot at a fix, I think all it needs is a |
|
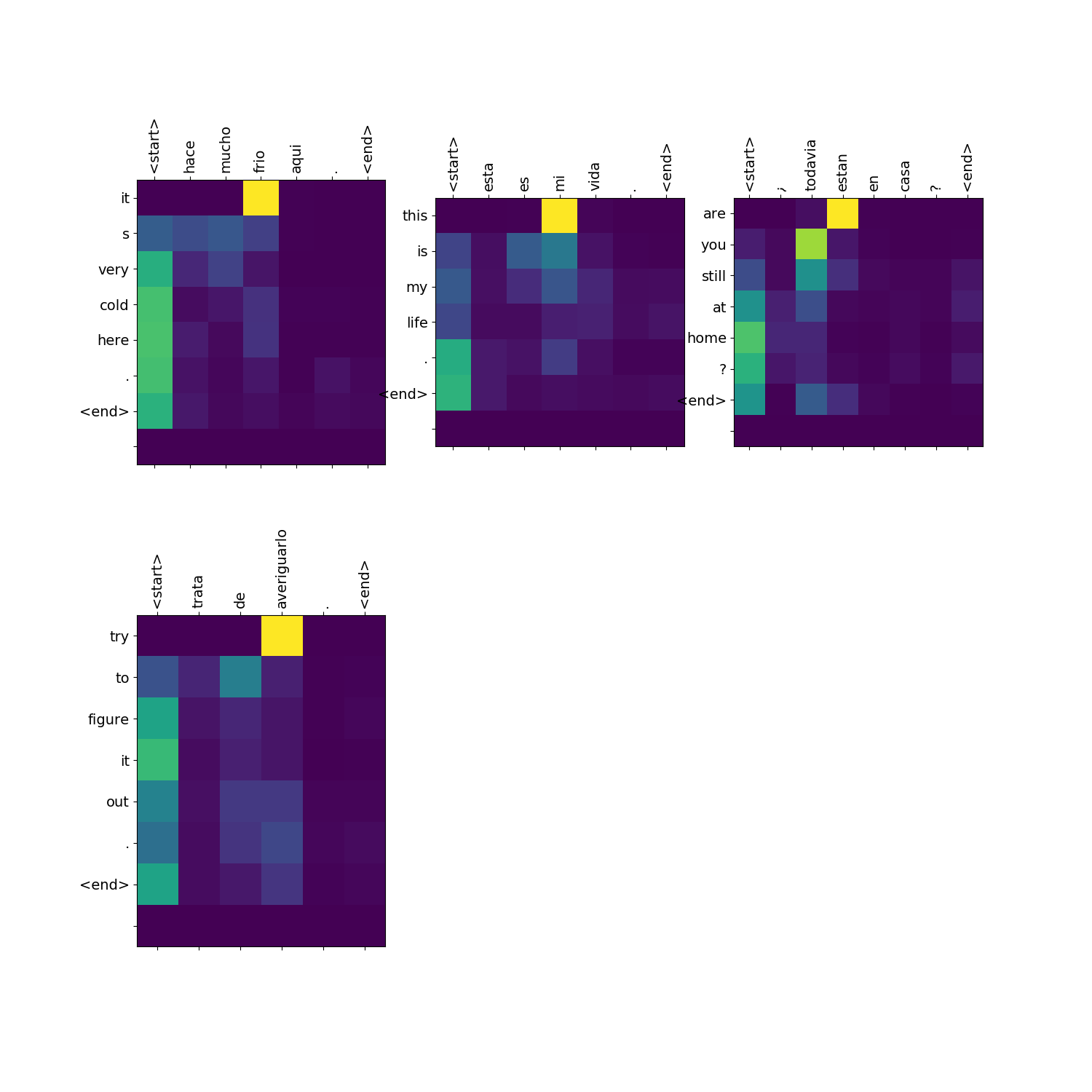
Be careful with that. The last time I did that, the attention plots didn't come out right. So please test and see if the attention plots remain similar to what they are now. The |
|
@MarkDaoust |
|
Thanks for taking a look @hihell
Can you be more specific? I'll dive in and try to figure out what's wrong. |
|
I tried re-running the notebook with |
|
@MarkDaoust
|

|
@MarkDaoust |
|
I'm working on this now. |
- Use the TextVectorization layer. - Use the AdditiveAttention layer. - tf.function the translate loop for text->text export. - Add more inline explanations, and sanity checks. - Add shape assertions throughout the code to make it easier to follow. Fixes tensorflow/tensorflow#38248 PiperOrigin-RevId: 370168273
|
Fixed in 9e18593 |
For TF2.5 - Use the TextVectorization layer. - Use the AdditiveAttention layer. - tf.function the translate loop for text->text export. - Add more inline explanations, and sanity checks. - Add shape assertions throughout the code to make it easier to follow. Fixes: tensorflow/tensorflow#38248 Fixes: tensorflow/tensorflow#39654 See also: tensorflow/tensorflow#49237 PiperOrigin-RevId: 370250185
For TF2.5 - Use the TextVectorization layer. - Use the AdditiveAttention layer. - tf.function the translate loop for text->text export. - Add more inline explanations, and sanity checks. - Add shape assertions throughout the code to make it easier to follow. Fixes: tensorflow/tensorflow#38248 Fixes: tensorflow/tensorflow#39654 See also: tensorflow/tensorflow#49237 PiperOrigin-RevId: 370250185
For TF2.5 - Use the TextVectorization layer. - Use the AdditiveAttention layer. - tf.function the translate loop for text->text export. - Add more inline explanations, and sanity checks. - Add shape assertions throughout the code to make it easier to follow. Fixes: tensorflow/tensorflow#38248 Fixes: tensorflow/tensorflow#39654 See also: tensorflow/tensorflow#49237 PiperOrigin-RevId: 370250185
For TF2.5 - Use the TextVectorization layer. - Use the AdditiveAttention layer. - tf.function the translate loop for text->text export. - Add more inline explanations, and sanity checks. - Add shape assertions throughout the code to make it easier to follow. Fixes: tensorflow/tensorflow#38248 Fixes: tensorflow/tensorflow#39654 See also: tensorflow/tensorflow#49237 PiperOrigin-RevId: 375597559
https://www.tensorflow.org/tutorials/text/nmt_with_attention
the decoder is trained step by step, and it's not passing last step state to this step
is this a feature or a bug? I checked a lot of NMT with attention paper, unlike the document those decoder are connected.
thanks in advance!
The text was updated successfully, but these errors were encountered: