generate vocabulary #233
Comments
|
This seems like continuation of #54. I am not a native English speaker, but to my ear "simulate" is more associated with "imitate" and "pretend". So using it as one of main verbs is a little bit confusing for me. Also for this reason I don't really like it as one of
I have nothing against |
|
Indeed it is a continuation of #54, which I think is further evidence that the current vocabulary is confusing -- I've had a chance to teach it 3 more times after that with not much improvement on the student/teaching experience. Simulation is a concept students are exposed to in high school, at least in the US and I believe in the UK. And the term used is simulation. And a search for "simulation based inference" on Google Scholar yields many relevant results (and more results than "randomization based inference"). That being said, I think the more important issue has been
I am ok with keeping the word The reason for the suggestion for aliasing As for |
|
This is a fantastic discussion and I hope it's OK for me to poke my head back in here. I remember using the |
|
I'd love to get a sense of where others are on this issue so that we might have time to implement changes before the semester starts. I feel pretty strongly that the language could use a revisit, but it seems worthwhile to agree on a pathway for change (if any) here before anyone starts (re)development around it. |
Quick takes
Meaning of word simulationAllow me to further muddy the waters of what "simulate" means. My sense is when stat ed people hear the term "simulation-based inference", they immediately think "Don't do CLT, rather do bootstrapping and permutation tests instead" i.e. "inference via resampling from a single sample, either with or without replacement". However, say you are constructing a sampling distribution by sampling from a population, using pennies or M&M's say. This is also a form of simulation in the colloquial sense of the word, as you are "imitating/mimicking the act" of sampling several times. All this to say simulation can be used for both "sampling from a population" and not just "resampling from a sample." Alternative verb/function name for generateThis a tricky one. When I first started using infer, my mnemonic pathway has always been start with @andrewpbray's wonderful diagram and go from there. The verb I had the most trouble remembering at first was One way to frame this discussion is to find the So yes, IMO However, another verb that I prefer is |
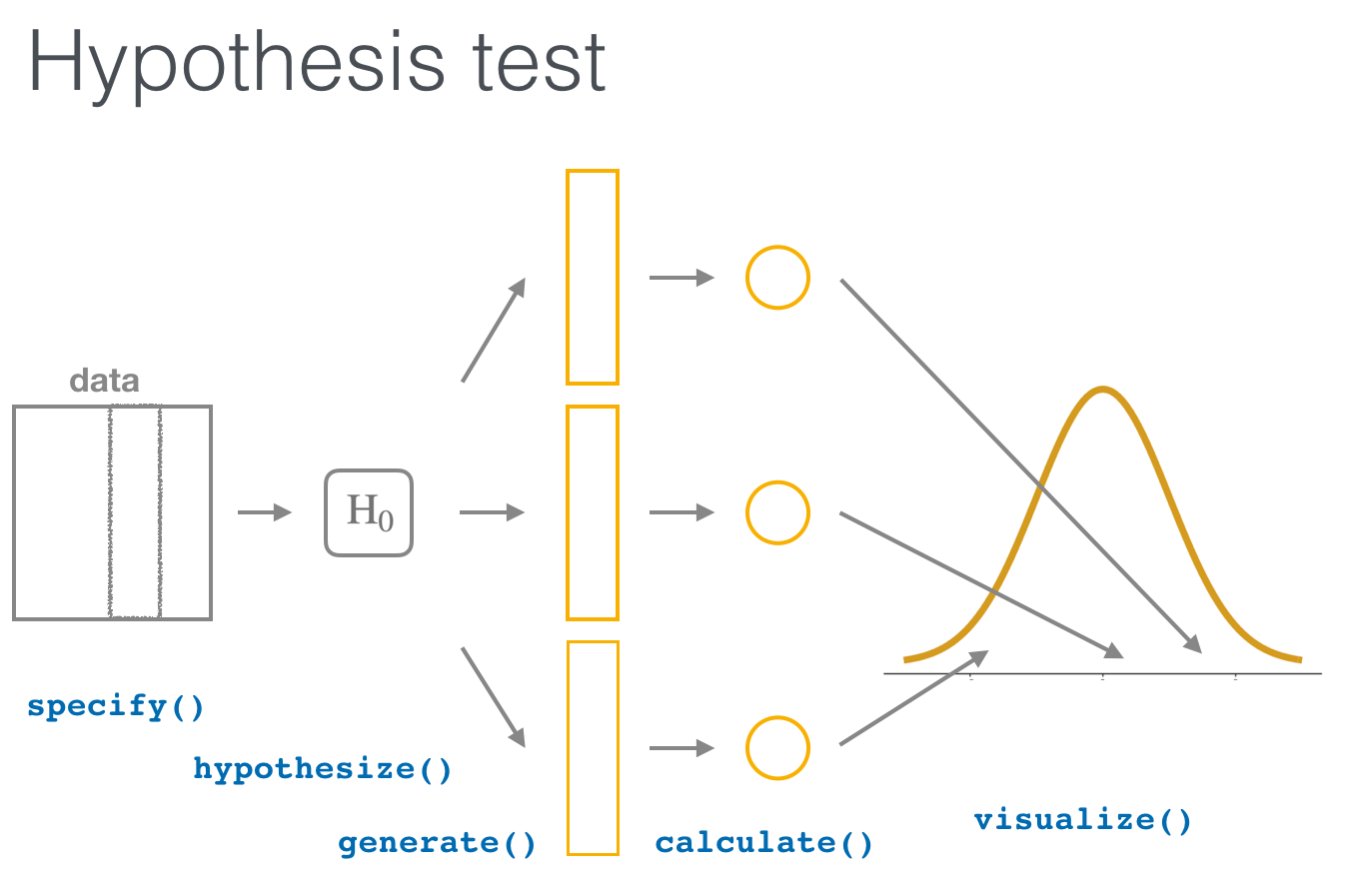
|
At the risk of throwing a monkey wrench, I still like the idea of The point is that using an approximation-based approach is still generating a null distribution. It's just that that null distribution is defined by a closed-form function, rather than generated from data. But we could realize that null distribution as a collection of outputs from that smooth function. So I also think @mine-cetinkaya-rundel 's ideas for shorthand are good. So
and then my proposal:
One downside to Using only |
|
Ah, gotcha! As for Also, please disregard my early suggestion of using If we want to clearly distinguish resampling with vs without replacement in the pipeline, then perhaps |
NamingThe phrase Simulation Based Inference is a good reason to take care in how we use the word One function or many?Ignoring for a moment the call to change some of these function names, there seems to be two modes for structuring this step of the infer pipeline. Currently, we have one function, I don't have a strong argument for why one method would be better than the other for elucidating for users what's going on under the hood. My initial favoring of the current implementation was due to wanting to emphasize the conceptual commonality of simulation, permutation, and bootstrapping as ways to generate more data. It's possible that obscures the actual mechanism of generation, though. Fwiw, the current SBI vs theoryI had forgotten about that suggestion that @beanumber had made regarding what a theoretical pipeline. The theoretical distributions have certainly been a neglected part of infer. Right now, here is a comparison of SBI vs theory. The rationale here was that, going up to the diagram, once you've specified the null hypothesis and are comfortable with your assumptions, you can just jump directly to the null distribution. Looking at it now, there is at least one pretty clear weakness. The information in If we were to return to Ben's suggestion, it would be: I see the appeal of this, but I'm unclear what the output would be at the Thoughts? I don't see any silver bullet here. I don't think we'll be able to come up with a syntax to cover all formulations in a fully cogent way. I like @rudeboybert 's advice to make decisions based primarily on the computational approach, the real strength of the package, and figure that folks can just do |
|
To weigh in (better late than never?) ... I really prefer |
|
I agree that @hardin47 do you have thoughts on the other suggestions from the original post on top, i.e. the arguments for |
|
I actually like the idea of using and I agree that the rest of the words aren't ideal. my inclination is to stick with permute / simulate because those words have meaning beyond the course. but i can see the advantage of shuffle / draw which are much more intuitive ideas. i don't have super strong feelings about the words. my bigger point is that i like one word (here: |
|
@hardin47 I agree with this argument if we were using the As for the argument names -- I agree that |
|
but we do say "now we need to |
|
So then is the story?
I like the first sentence, but I get stuck in the options because the options don't seem like apples to apples to me. I feel like Also, many students have used the term |
|
what is the word you use to describe the function I'd also like to add to your story:
|
|
Isn't the theoretical mathematical distribution as simulation as well? It's not reality, it's an idealized representation of reality, right? |
|
Apologies for dropping into this conversation at this point in time, but I just recently found the infer package. I'm rather fond of the verb I'm going to offer a revision to the story:
The questions in parentheses point to what additional arguments might need to be specified. I will note that I'm not overly committed to |
|
Hi All, I've just found this package, and think it is fantastic! Some thoughts on this thread:
If possible, I think an output of the null distribution for theoretical approximation of a dataset of quantiles and densities would be better. An additional function to use instead of
|


|
Will be making some moves related to this issue in the coming weeks, so wanted to nudge this conversation a bit and see if we can stumble on vocabulary that works well for folks! Some thoughts from reading above comments and chatting with @mine-cetinkaya-rundel and @topepo this last week… I think a strength of the {infer} framework is the emphasis on the statistical intuition arising from the juxtaposition of
For example, in the randomization-based side of the package # calculate observed mean
obs_stat <- gss %>%
specify(response = hours) %>%
hypothesize(null = "point", mu = 40) %>%
calculate(stat = "mean")
# generate a null distribution of means
null_dist <- gss %>%
specify(response = hours) %>%
hypothesize(null = "point", mu = 40) %>%
generate(reps = 1000, type = "bootstrap") %>%
calculate(stat = "mean")
# juxtapose them visually
visualize(null_dist) + shade_p_value(obs_stat, direction = "both")
# juxtapose them to calculate a p-value
get_p_value(x = null_dist, obs_stat = obs_stat, direction = "both")As the package stands, there is no thing in {infer} that is a theoretical null distribution. e.g. there is no “theoretical analogue” to I think whatever solution we come up with to this grammatical problem should result in a thing that a theorized statistic can be juxtaposed with. One suggested approach was a new # calculate observed t
obs_stat <- gss %>%
specify(response = hours) %>%
hypothesize(null = "point", mu = 40) %>%
calculate(stat = "t")
# generate a null t distribution
null_dist <- gss %>%
specify(response = hours) %>%
hypothesize(null = "point", mu = 40) %>%
generate(type = "theoretical") %>%
calculate(stat = "t")
# juxtapose them visually
visualize(null_dist) + shade_p_value(obs_stat, direction = "both")
# juxtapose them to calculate a p-value
get_p_value(x = null_dist, obs_stat = obs_stat, direction = "both")The lines used to generate
One approach that Mine and I have tossed around (and that I think also borrows from @davidhodge931's suggestion) would interface like this: # calculate observed t
obs_stat <- gss %>%
specify(response = hours) %>%
hypothesize(null = "point", mu = 40) %>%
calculate(stat = "t")
# generate a null T distribution
null_dist <- gss %>%
specify(response = hours) %>%
hypothesize(null = "point", mu = 40) %>%
theorize(distribution = "T", df = nrow(gss) - 1)
# juxtapose them visually
visualize(null_dist) + shade_p_value(obs_stat, direction = "both")
# juxtapose them to calculate a p-value
get_p_value(x = null_dist, obs_stat = obs_stat, direction = "both")…where This approach has a few benefits:
Some drawbacks:
A spec of how this could look once implemented, and how it compares to existing approaches, here. Would love to hear folks’ thoughts here. :-) Oh, and I'm on board for a switch of the |

|
I agree that I will admit that naming is incredibly hard so I am open to suggestions here on what to call things. |
|
I'm also fine with changing the |
|
there is a lot going on in this thread, i hope i don't make things worse...
|
|
Here is my summary of the discussion so far: 1. What (if anything) should we do about the vagueness of
|
|
I like using a function different from I think if I think a separate function would work better for building intuition that you can have a null distribution either through generating data and calculating statistics, or via a theoretical distribution. I think |
|
This is such a great discussion! Like @hardin47 and @mine-cetinkaya-rundel I like it better with If you do choose to go with a separate verb, how about |
|
For the record, I actually don't think I agree that So, I think the two options we have are:
OR
I think we have converged, at least, to there are no other viable options on the table (which I'm fine with). |
|
Very much in agreement with Mine's comment above and really appreciating the conversation generally. If In tossing around other options for that verb, I think |
|
@simonpcouch , thanks for bringing this discussion back around. When you first laid out a pipeline to make a theoretical object that includes So I guess that puts me in the I agree with @mine-cetinkaya-rundel about the can of worms if assumptions are only associated with mathematical approximations and not computational ones. I'm wondering, though, if this might be the least bad downside of any of our options. It could also be an opportunity to discuss in the documentation what we assume about the process when we do permutation and bootstrapping. |
|
not to add to the confusion (when it looks like possibly there is convergence?), but i want to point out two different issues here:
As seen in the parallel conversation we are having (about the word simulate, I don't love the word draw either, but i'm not going to complain because i don't have better suggestions), maybe we won't be able to come up with a word that does everything in every situation. if that is the case, then i'm fine going forward with @mine-cetinkaya-rundel 's option 2. i continue to prefer option 1, but i'm not going to die on this hill. |
|
@hardin47 I'll address the bit about "draw" since I've already said a bunch on the
We have at least reached an agreement that "simulate" is not ideal so offering an alternative seems desirable. And disentangling the threads will be the cherry on top. |
|
@mine-cetinkaya-rundel your proposal for "draw" makes sense to me! @hardin47 One of the reasons, I think, why option That's one of my favorite functionalities of |
|
|
|
I think I'm still with @hardin47 in camp 1. But I'm not going to die on that hill either. Could we do both and just have I do worry about What about |
|
I really, really like those two verbs read in the sense of situating/contextualizing the observed statistic in the null distribution, though that phrasing would imply that the inputs to I'd prefer not to do both as we will continue maintaining the current techniques to generate theoretical distributions for a good while (if not indefinitely) as well. |
|
i really like |
|
I hesitate to introduce vocabulary that is otherwise not used in this context. I've never said "situate" in place of "assume" in the sentence "we can assume the sampling distribution of the sample statistic is nearly normal". And I'll take a step back from my earlier worry re: I also continue to feel uneasy about "we can generate the sampling distribution of the sample statistic to be nearly normal". The word "generate" (defined as "produce or create" or "produce (a set or sequence of items) by performing specified mathematical or logical operations on an initial set") says we are creating something, which is true when we resample and create a randomization or a bootstrap distribution but not true when we use existing theory and assume a defined distribution (with a given parameter). So my proposal here @simonpcouch would be to implement |
|
i'm totally fine with you all ignoring me... but i like the action-ness of the verbs, and i like the generate feels like we are producing something. what about any of the following:
|
|
|
|
|
If people are worried that
|
|
A new |
|
This issue has been automatically locked. If you believe you have found a related problem, please file a new issue (with a reprex: https://reprex.tidyverse.org) and link to this issue. |
Currently the package does three types of
generate():bootstrap,permute, orsimulate. Every time I teach this I run info difficulties around this vocabulary.bootstrapis not problematic butpermuteandsimulateare hard to distinguish for students.One other issue is that much of Statistics Education literature refers to these methods as Simulation Based Inference, so having
simulateas a type of simulation seems odd to me.A third consideration is that a good portion of the consumers of this package are students in into stat / data science courses where probability is not a requirement. So the difference between permutation / combination may not be clear to them, nor in the learning goals for the course they're taking. Hence, introducing that term makes clearly teaching this material difficult in my experience.
I would like to propose a potentially radical change:
generate()becomessimulate()"simulate"becomes"draw"(or"flip", but I think"draw"is more general to both numerical and categorical data vs."flip"only makes sense for categorical data to me)"permute"becomes"shuffle"Discuss 😄
Obviously we would do this in a non-breaking way via aliasing as opposed to renaming and breaking old code. But I can see the vignettes and teaching materials reading A LOT smoother with these changes.
cc @rudeboybert @mcconvil (when I discussed this with @andrewpbray a while back -- sorry for the delay!! -- he recommended tagging you two as you might have thoughts and feelings on this issue
The text was updated successfully, but these errors were encountered: