Slow performance with dplyr #378
Labels
Comments
|
I think this may be a vroom performance bug related to how ALTREP views into the original data are materialized. I can reproduce without dplyr. The slice materializes very slowly, but the original input materializes quickly. library(vroom)
tmp <- tempdir()
tmp_file <- fs::path(tmp, "names.zip")
exdir <- fs::path(tmp, "names")
fs::dir_create(exdir)
download.file("https://www.ssa.gov/oact/babynames/names.zip", tmp_file)
unzip(tmp_file, exdir = exdir)
files <- dir(exdir, pattern = "*.txt", full.names = TRUE)
rawdat <- vroom(files, col_names=c("name", "sex", "count"), id = "path")
# make a big slice
sliced <- rawdat$name[1:1e6]
# this is an ALTREP view into the original data
.Internal(inspect(sliced))
#> @7fdfb18cb348 16 STRSXP g0c0 [REF(65535)] vroom_chr (len=1000000, materialized=F)
# takes forever to materialize
system.time({
vroom:::force_materialization(sliced)
})
#> user system elapsed
#> 70.576 0.208 70.994
# original data is still un-materialized
.Internal(inspect(rawdat$name))
#> @7fdff1d6da08 16 STRSXP g1c0 [MARK,REF(65535)] vroom_chr (len=2020863, materialized=F)
# but materializing it is quick
system.time({
vroom:::force_materialization(rawdat$name)
})
#> user system elapsed
#> 0.284 0.004 0.288Created on 2021-10-07 by the reprex package (v2.0.1) |
|
Instruments suggests it has something to do with the
|
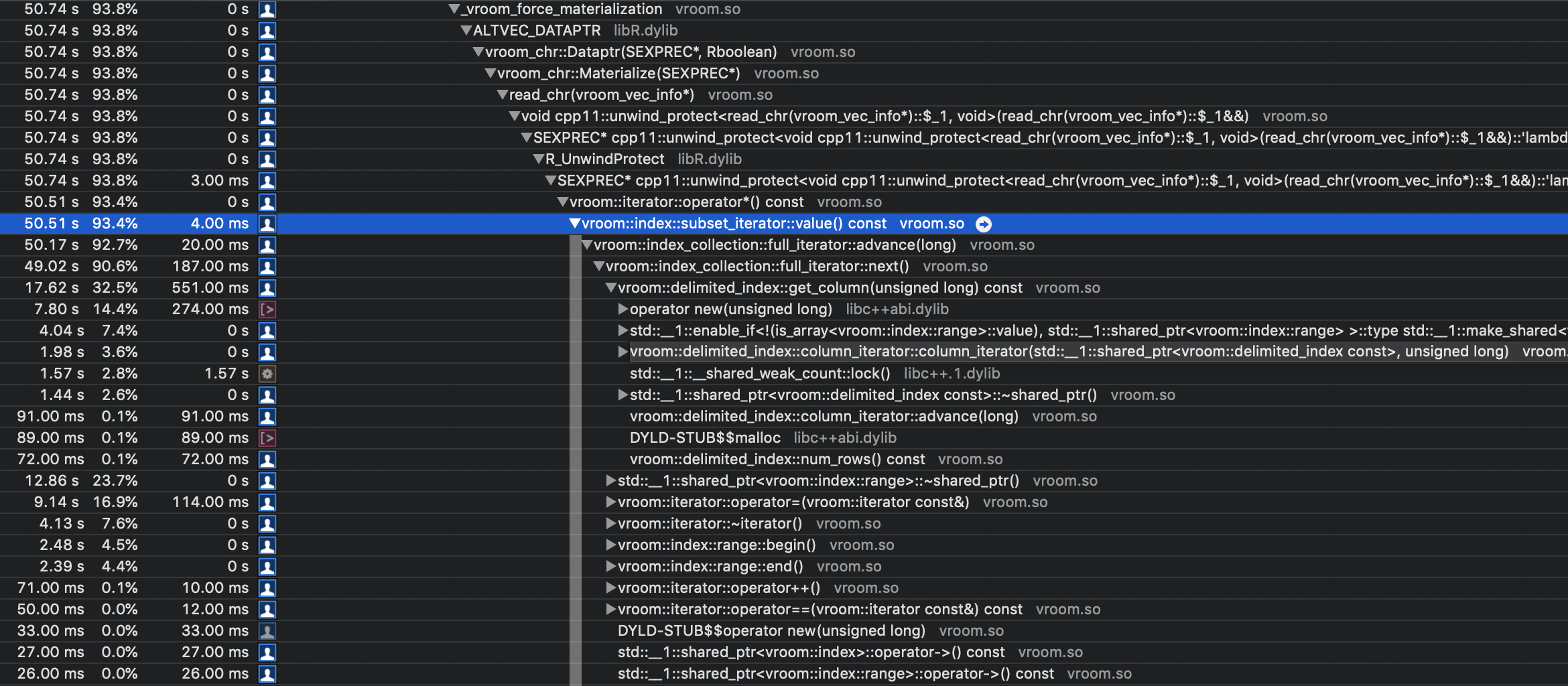
|
Ok I have resolved this issue, should be much better now. library(vroom)
tmp <- tempdir()
tmp_file <- fs::path(tmp, "names.zip")
exdir <- fs::path(tmp, "names")
fs::dir_create(exdir)
download.file("https://www.ssa.gov/oact/babynames/names.zip", tmp_file)
unzip(tmp_file, exdir = exdir)
files <- dir(exdir, pattern = "*.txt", full.names = TRUE)
rawdat <- vroom(files, col_names=c("name", "sex", "count"), id = "path")
#> Rows: 2020863 Columns: 4
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> chr (2): name, sex
#> dbl (1): count
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
# make a big slice
sliced <- rawdat$name[1:1e6]
# takes forever to materialize
system.time({
vroom:::force_materialization(sliced)
})
#> user system elapsed
#> 0.117 0.002 0.120
# but materializing it is quick
system.time({
vroom:::force_materialization(rawdat$name)
})
#> user system elapsed
#> 0.271 0.005 0.277Created on 2021-10-07 by the reprex package (v2.0.1) |
jimhester
added a commit
that referenced
this issue
Nov 9, 2021
Previously we were creating a new iterator each time we returned a value, now we store the previous index in the iterator and update the full iterator with the difference when needed. The performance issue was occurring due to transient object creation of the temporary iterators and moving them to the right location. Fixes #378
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
The text was updated successfully, but these errors were encountered: