This project compose of two parts: 1) write, spark job to write to hbase using bulk load to; 2)read, rest api reading from hbase base on spring boot frame
JDK: 1.8(or1.7)
Hadoop: 2.5-2.7
HBase: 0.98
Spark: 2.0-2.1
Sqoop: 1.4.6
sqoop import --connect jdbc:oracle:thin:@dbhost:port:instance --username xx --password xx --table CHECK --split-by ID --fields-terminated-by '\0x01' --lines-terminated-by '\0x10' --delete-target-dir --target-dir /user/tina/check/20171012
create 'tinawang:check',{NAME => 'f' , DATA_BLOCK_ENCODING => 'FAST_DIFF', BLOOMFILTER => 'ROW',COMPRESSION => 'SNAPPY'},{SPLITS=>['1','2','3','4','5','6','7','8','9']}
SparkHbase->conf->table.conf(eg: my table is check, check.conf, the spark resources config depends on your cluster)
spark.executor.cores=4
spark.executor.instances=3
spark.executor.memory=6G
SparkHbase->conf->table.properties(eg:check.properties)
tableName=check
namespace=tinawang
cf=f
preRegions=10
uniqCol=id
queryKey=check_id
inputPathPrefix=/user/tina/check
hfilePathPrefix=/user/tina/hfile/check
cols=id,check_id,rule_no,rule_type,rule_desc
SparkHbase->conf->kerberos.conf(if your hadoop cluster opend security authentication with kerberos)
hbase.keyuser=tina@GNUHPC.ORG
hbase.keytab=tina.keytab
application.yml
spring:
profiles:
active: sit
jackson:
property-naming-strategy: SNAKE_CASE
hbaseenv:
security: kerberos
zkparent: /hbase-secure (zookeeper.znode.parent in hbase-site.xml, hdp with security )
server:
port: 8091
application-sit.yml
hbaseenv:
krb5conf: /etc/krb5.conf
coresite: /usr/hdp/2.6.1.0-129/hadoop/conf/core-site.xml
hbasesite: /usr/hdp/2.6.1.0-129/hbase/conf/hbase-site.xml
user: tina@GNUHPC.ORG
keypath: /home/tina/project/kerberos/tina.keytab
you can exe mvn command or package in the IDE
mvn clean package
you will get an zip package under dir target
|--
|--bin
|--conf
|--jar
|--lib
copy the zip to your test or product host, then
cd ${APPDIR}/bin
./spark-hbase-cluster.sh 20171012 SparkWriteHbaseJob check
after the job finished, you can check the hbase table to observe the data
scan 'tinawang:check',{LIMIT => 6}
scan 'tinawang:check',{STARTROW => '01dbdebfbc84bad48d92aa7c045019e8d',STOPROW => '01dbdebfbc84bad48d92aa7c045019e8e',COLUMNS=>'f:id'}
ps: the STARTROW and STOPROW can be set according to the previous scan cmd and truncate the rowkey prefix
mvn clean package
you will get a fat jar package, and copy it somewhere, then exe the following command
java -jar hbase-web-1.0-SNAPSHOT.jar
if you want to deploy the service to ignore the HUP (hangup) signal ,you can also do
nohup java -jar hbase-web-1.0-SNAPSHOT.jar &
after you deploy the SparkHbase and HbaseWeb, you can access the url where hadoop is you deploy host
http://hadoop:8091/swagger-ui.html
if you run the HbaseWeb project under dev env, you only need replace the 'hadoop' to localhost.
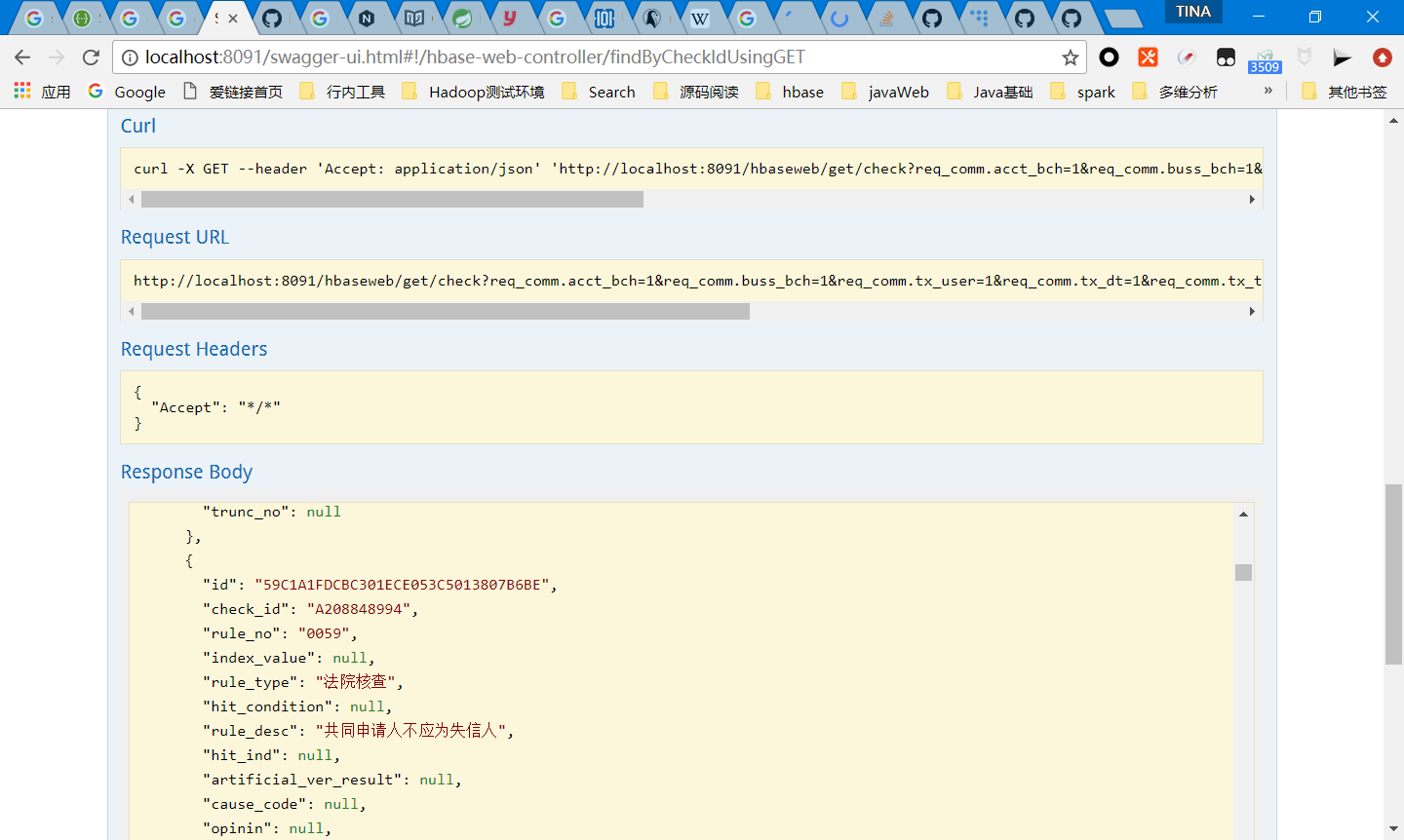
an test example
open the url in the explorer
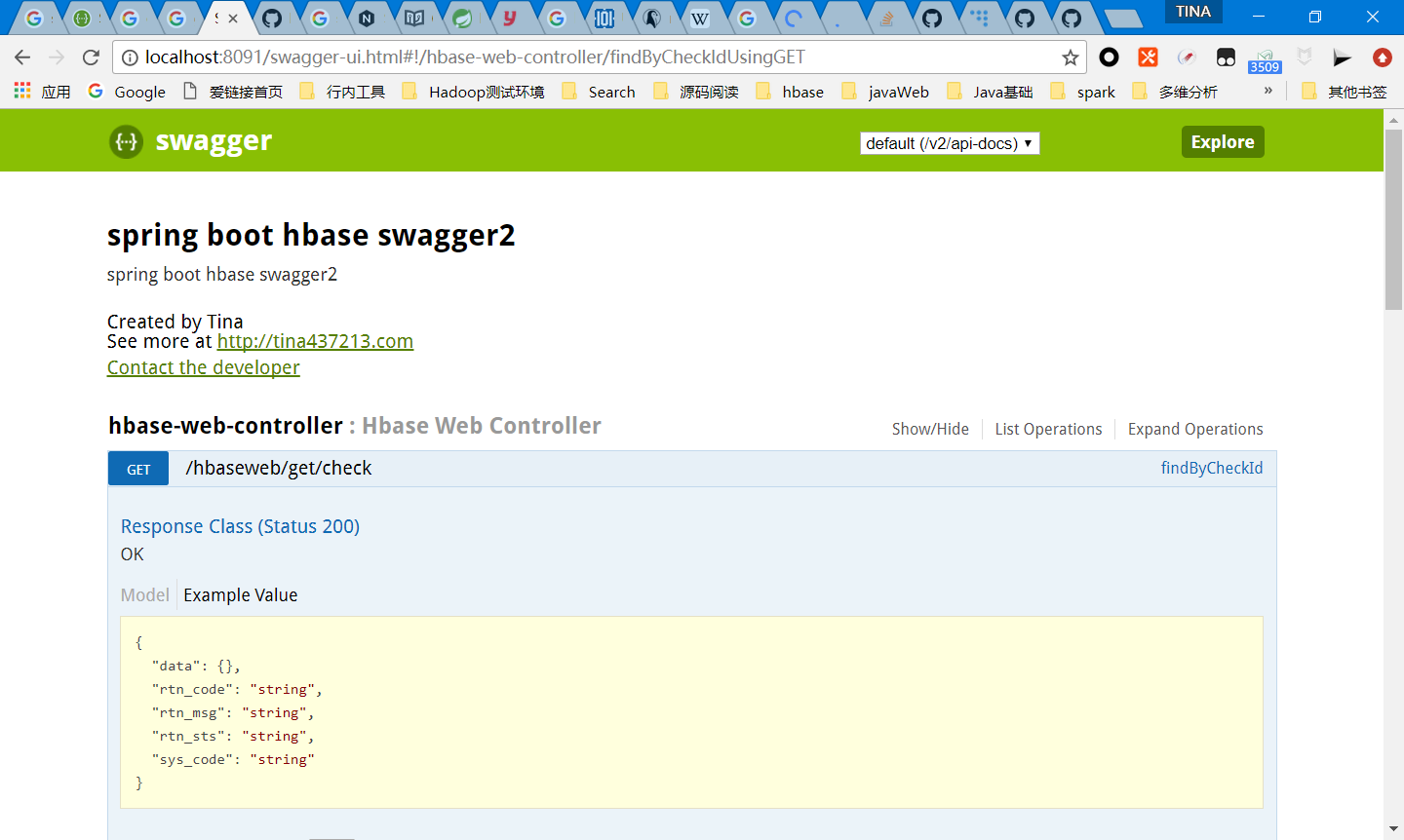
input query data
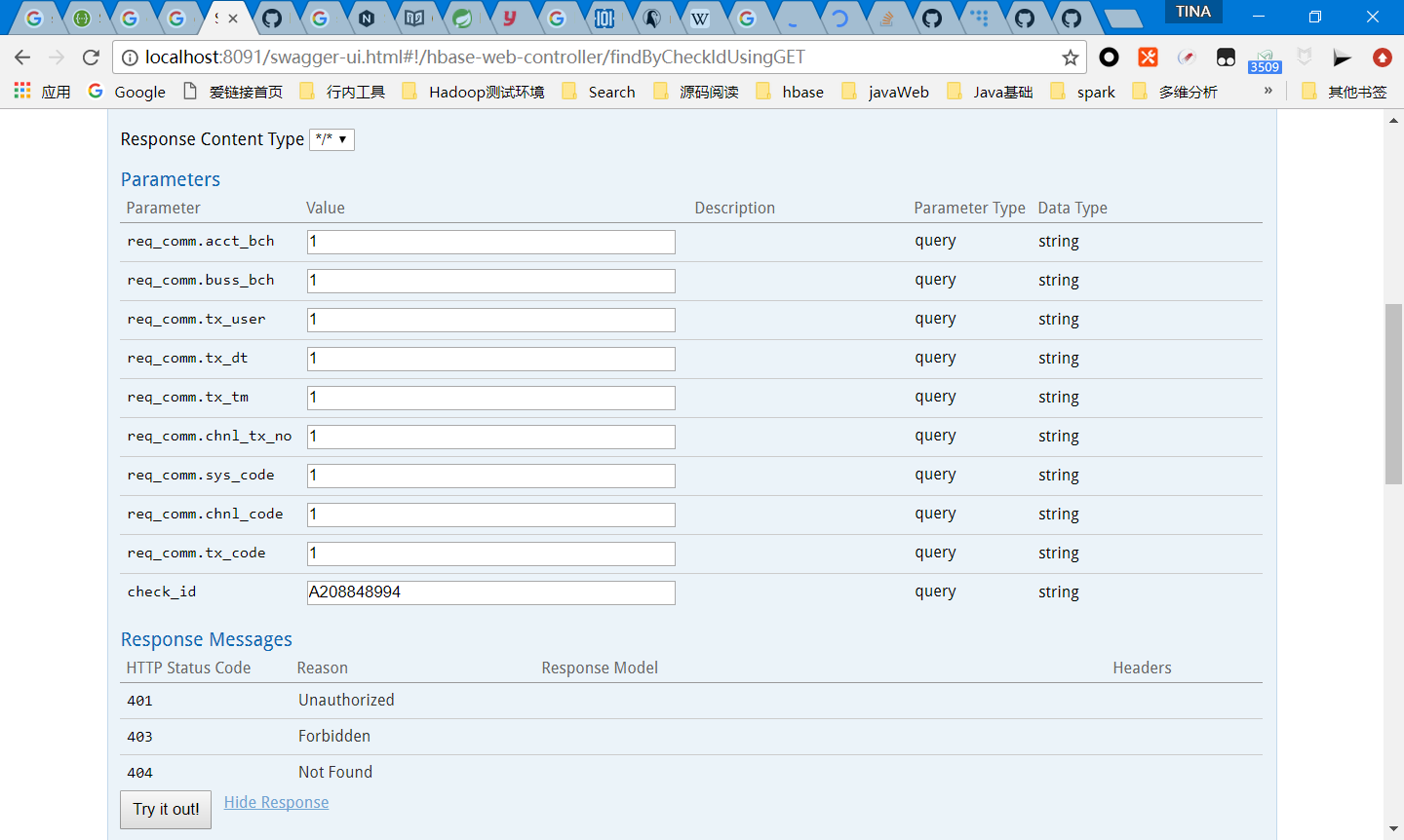
try it