What is the difference between 𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝗶𝗻𝗴 𝗮𝗻𝗱 𝗕𝘂𝗰𝗸𝗲𝘁𝗶𝗻𝗴 𝗶𝗻 𝗦𝗽𝗮𝗿𝗸?
When working with big data there are many important concepts we need to consider about how the data is stored both on disk and in memory, we should try to answer questions like:
➡️ Can we achieve desired parallelism?
➡️ Can we skip reading parts of the data? ✅ The question is addressed by partitioning and bucketing procedures
➡️ How is the data colocated on disk? ✅ The question is mostly addressed by bucketing.
So what are the procedures of Partitioning and Bucketing? 𝗟𝗲𝘁'𝘀 𝘇𝗼𝗼𝗺 𝗶𝗻.
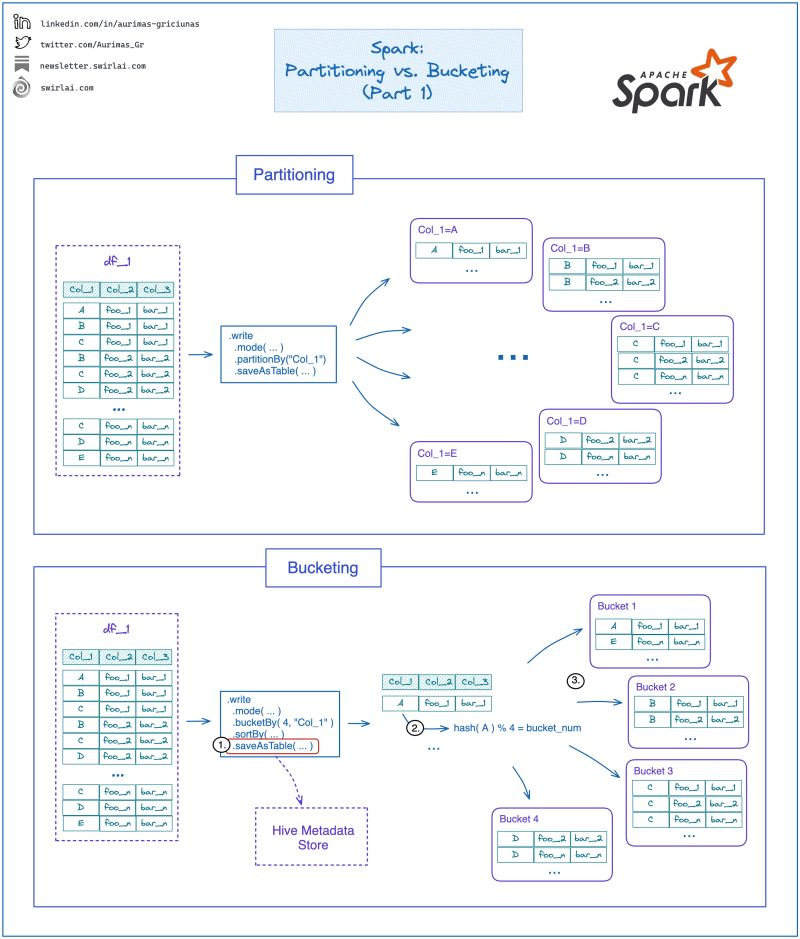
𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝗶𝗻𝗴.
➡️ Partitioning in Spark API is implemented by .partitionBy() method of the DataFrameWriter class. ➡️ You provide the method one or multiple columns to partition by. ➡️ The dataset is written to disk split by the partitioning column, each of the partitions is saved into a separate folder on disk. ➡️ Each folder can maintain multiple files, the amount of resulting files is controlled by the setting spark.sql.shuffle.partitions.
✅ Partitioning enables Partition Pruning. Given we filter on a column that we used to partition the dataframe by, Spark can plan to skip the reading of files that are not falling into the filter condition.
𝗕𝘂𝗰𝗸𝗲𝘁𝗶𝗻𝗴.
➡️ Bucketing in Spark API is implemented by .bucketBy() method of the DataFrameWriter class.
𝟭: We have to save the dataset as a table since the metadata of buckets has to be saved somewhere. Usually, you will find a Hive metadata store leveraged here. 𝟮: You will need to provide number of buckets you want to create. Bucket number for a given row is assigned by calculating a hash on the bucket column and performing modulo by the number of desired buckets operation on the resulting hash. 𝟯: Rows of a dataset being bucketed are assigned to a specific bucket and collocated when saving to disk.
✅ If Spark performs wide transformation between the two dataframes, it might not need to shuffle the data as it is already collocated in the executors correctly and Spark is able to plan for that.
❗️There are conditions that need to be met between two datasets in order for bucketing to have desired effect.
𝗪𝗵𝗲𝗻 𝘁𝗼 𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻 𝗮𝗻𝗱 𝘄𝗵𝗲𝗻 𝘁𝗼 𝗕𝘂𝗰𝗸𝗲𝘁?
✅ If you will often perform filtering on a given column and it is of low cardinality, partition on that column. ✅ If you will be performing complex operations like joins, groupBys and windowing and the column is of high cardinality, consider bucketing on that column.
❗️Bucketing is complicated to nail as there are many caveats and nuances you need to know when it comes to it. More on it in future posts.